JPA 사용
도메인 데이터(aka.VO, aka.table)
앞선 포스팅에서 설명했듯 JPA에서 가장 중요한 부분은 객체와 테이블을 매핑하는 것이다.
JPA가 제공하는 애노테이션을 사용해서 Item 객체와 테이블을 매핑해보자.
@Data
@Entity
@Table(name="item")
public class Item {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "item_name", length = 10)
private String itemName;
private Integer price;
private Integer quantity;
public Item() {}
public Item(String itemName, Integer price, Integer quantity) {
this.itemName = itemName;
this.price = price;
this.quantity = quantity;
}
}@Entity : JPA가 사용하는 객체라는 뜻이다. 이 에노테이션이 있어야 JPA가 인식할 수 있다. 이렇게 @Entity 가 붙은 객체를 JPA에서는 엔티티라 한다.
@Id : 테이블의 PK와 해당 필드를 매핑한다.
@GeneratedValue(strategy = GenerationType.IDENTITY) : PK 생성 값을 데이터베이스에서 생성하는 IDENTITY 방식을 사용한다. 예) MySQL auto increment
@Column : 객체의 필드를 테이블의 컬럼과 매핑한다.
name = "item_name" : 객체는 itemName 이지만 테이블의 컬럼은 item_name 이므로 이렇게 매핑했다.
length = 10 : JPA의 매핑 정보로 DDL( create table )도 생성할 수 있는데, 그때 컬럼의 길이 값으로 활용된다. ( varchar 10 )
@Column 을 생략할 경우 필드의 이름을 테이블 컬럼 이름으로 사용한다. 참고로 지금처럼 스프링 부트와 통합해서 사용하면 필드 이름을 테이블 컬럼 명으로 변경할 때 객체 필드의 카멜 케이스를 테이블 컬럼의 언더스코어로 자동으로 변환해준다.
itemName -> item_name , 따라서 위 예제의 " @Column(name = "item_name") " 를 생략해도된다.
JPA는 public 또는 protected 의 기본 생성자가 필수이다. 기본 생성자를 꼭 넣어주자.
Repository(aka.DAO) 작성
@Slf4j
@Repository
@Transactional
public class JpaItemRepository implements ItemRepository {
private final EntityManager em;
public JpaItemRepository(EntityManager em) {
this.em = em;
}
@Override
public Item save(Item item) {
em.persist(item);
return item;
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = em.find(Item.class, itemId);
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
Item item = em.find(Item.class, id);
return Optional.ofNullable(item);
}
@Override
public List<Item> findAll(ItemSearchCond cond) {
String jpql = "select i from Item i";
Integer maxPrice = cond.getMaxPrice();
String itemName = cond.getItemName();
if (StringUtils.hasText(itemName) || maxPrice != null) {
jpql += " where";
}
boolean andFlag = false;
if (StringUtils.hasText(itemName)) {
jpql += " i.itemName like concat('%',:itemName,'%')";
andFlag = true;
}
if (maxPrice != null) {
if (andFlag) {
jpql += " and";
}
jpql += " i.price <= :maxPrice";
}
log.info("jpql={}", jpql);
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
if (StringUtils.hasText(itemName)) {
query.setParameter("itemName", itemName);
}
if (maxPrice != null) {
query.setParameter("maxPrice", maxPrice);
}
return query.getResultList();
}
}private final EntityManager em : 생성자를 보면 스프링을 통해 엔티티 매니저( EntityManager ) 라는 것을 주입받은 것을 확인할 수 있다.
JPA의 모든 동작은 엔티티 매니저를 통해서 이루어진다. 엔티티 매니저는 내부에 데이터소스를 가지고 있고, 데이터베이스에 접근할 수 있다.
@Transactional : JPA의 모든 데이터 변경(등록, 수정, 삭제)은 트랜잭션 안에서 이루어져야 한다. 조회는 트랜잭션이 없어도 가능하다. 변경의 경우 일반적으로 서비스 계층에서 트랜잭션을 시작하기 때문에 문제가 없다.
하지만 위 코드는 복잡한 비즈니스 로직이 없어서 서비스 계층에서 트랜잭션을 걸지 않았다.
JPA에서는 데이터 변경시 트랜잭션이 필수다. 따라서 리포지토리에 트랜잭션을 걸어주었다.
다시한번 강조하지만 일반적으로는 비즈니스 로직을 시작하는 서비스 계층에 트랜잭션을 걸어주는 것이 맞다.
update(): 보면 그냥 set만 해주는데 변경이 된다. why? -> 내부에 조회시점에서 미리 snapSHOT을 떠두고 해당 데이터와 어떤 데이터가 바뀌었는지 JPA가 알고있기 때문에 이걸 commit하는 시점에 이제 upate query를 날린다는 것이다.
즉, "JPA는 트랜잭션이 커밋되는 시점" 에, 변경된 엔티티 객체가 있는지 확인한다. 특정 엔티티 객체가 변경된 경우에는 UPDATE SQL을 실행한다.
JPA가 어떻게 변경된 엔티티 객체를 찾는지 명확하게 이해하려면 영속성 컨텍스트라는 JPA 내부 원리를 이해해야 한다.
이 부분은 추후 JPA 기본편에 관하여 포스팅 하겠다.
대충 트랜잭션 커밋 시점에 JPA가 변경된 엔티티 객체를 찾아서 UPDATE SQL을 수행한다고 이해하면 된다.
findAll():
String jpql = "select i from Item i";sql문과 95% 정도 비슷한 jpql을 사용한다. 보면 from 다음에 나오는 Item은 Domain에 명시되어있고 @Entity 어노테이션을 갖는 그 Item이고 그 뒤에는 alias로 i가 명시되어있고 select 문으로 i 자체를 반환하는 코드이다.em.createNamedQuery(jpql, Item.class).getResultList();첫번째 인자로는 jpql, 두번째 인자로 반환 타입이 들어간다.- 그리고 보면 알겠지만 동적 쿼리에 굉장히 취약하다. 마치 MyBatis를 사용하기 직전의 모습 같다.
jpql을 일일이 java 코드로 만들어줘야하는데 여기서 다른 점은 이제 변수명으로 작성해도 된다는 것이다.
-
findById():
JPA에서 엔티티 객체를 PK를 기준으로 조회할 때는 find() 를 사용하고 조회 타입과, PK 값을 주면 된다. 그
러면 JPA가 다음과 같은 조회 SQL을 만들어서 실행하고, 결과를 객체로 바로 변환해준다. -
참고: JPA를 설정하려면
EntityManagerFactory, JPA 트랜잭션 매니저( JpaTransactionManager ), 데이터소스 등등 다양한 설정을 해야 한다. 스프링 부트는 이 과정을 모두 자동화 해준다. 그리고 스프링 부트의 자동 설정은 JpaBaseConfiguration 를 검색하여 참고하자.
결과 분석
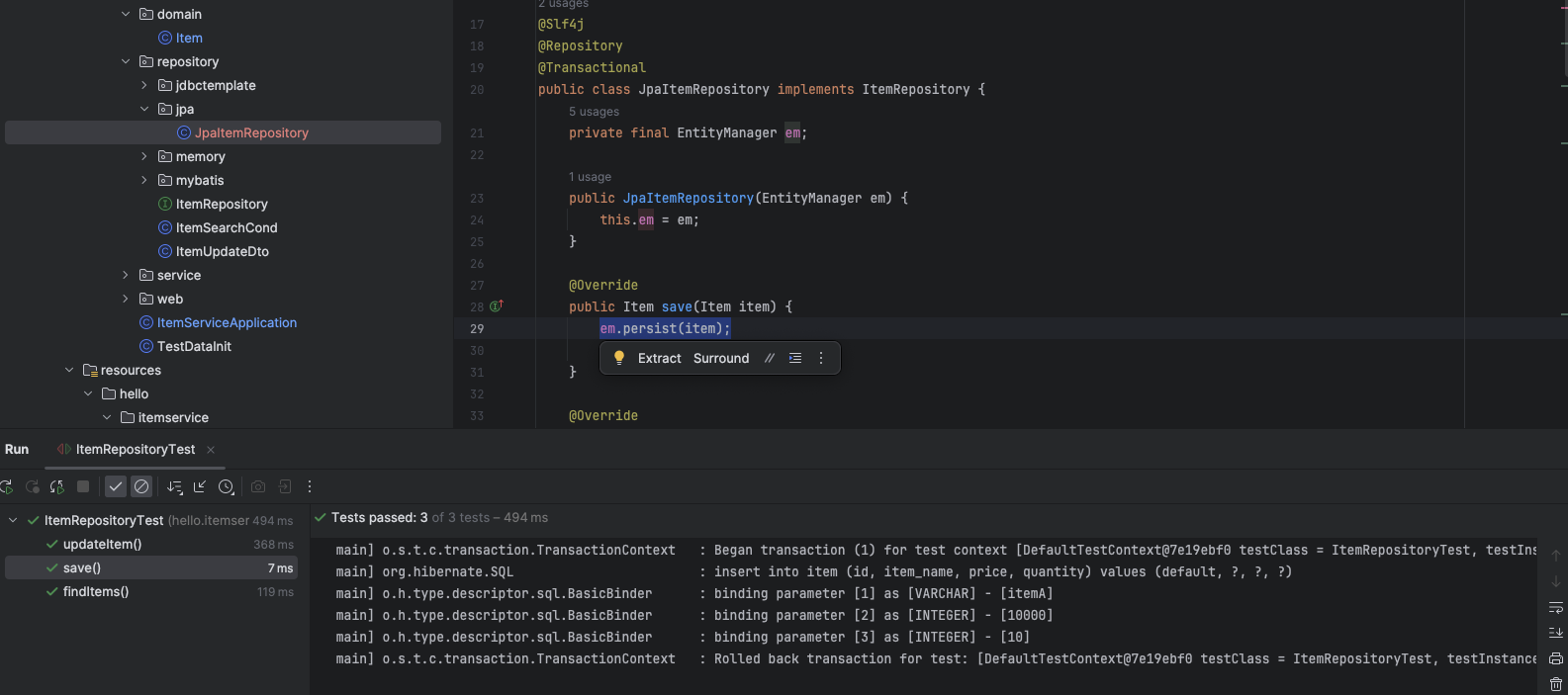 테스트 결과는 아주 훌륭하다 그냥 persist() 한 줄 적었는데 모든 것을 다 해준다.
테스트 결과는 아주 훌륭하다 그냥 persist() 한 줄 적었는데 모든 것을 다 해준다.
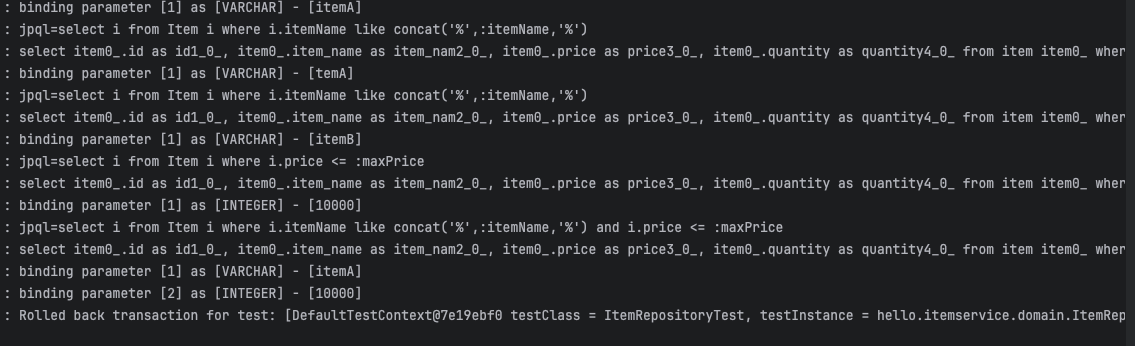 마찬가지로 jpql이 sql로 변환되어 다 나가는 것을 확인할 수 있다.
마찬가지로 jpql이 sql로 변환되어 다 나가는 것을 확인할 수 있다.
 그리고 update test 함수는 update query가 안 나가는 것을 볼 수 있는데 앞서 말 했듯 JPA는 캐싱을 지원하여 성능향상의 효과를 느낄 수 있다고 하였다.
그리고 update test 함수는 update query가 안 나가는 것을 볼 수 있는데 앞서 말 했듯 JPA는 캐싱을 지원하여 성능향상의 효과를 느낄 수 있다고 하였다.
그래서 모든게 캐시다. 따라서 뭐 굳이 테스트환경에서 쿼리문을 눈으로 보고싶다면 그냥 @Commit을 추가하여 커밋을 해버리면 된다.
또 눈썰미가 좋다면 insert문에 id 위치에 값이 빠져있는데(defualt) 이는 PK키 생성 전략을 IDENTITY로 가져갔기 때문에 JPA가 이런 쿼리를 만들어서 실행한 것이다.
물론 쿼리 실행 이후에 Item 객체의 Id 필드에 DB가 생성한 PK값이 들어가게 된다.
(JPA가 INSERT SQL실행 이후 생성된 ID 결과를 받아서 넣어준다.)
JPQL
JPA는 JPQL(Java Persistence Query Language)이라는 객체지향 쿼리 언어를 제공한다.
주로 여러 데이터를 복잡한 조건으로 조회( 동적 쿼리 )할 때 사용한다.
SQL이 테이블을 대상으로 한다면, JPQL은 엔티티 객체를 대상으로 SQL을 실행한다 생각하면 된다.
엔티티 객체를 대상으로 하기 때문에 from 다음에 Item 엔티티 객체 이름이 들어간다. 엔티티 객체와 속성의 대소문자는 구분해야 한다.
JPQL은 SQL과 문법이 거의 비슷하기 때문에 개발자들이 쉽게 적응할 수 있다.
결과적으로 JPQL을 실행하면 그 안에 포함된 엔티티 객체의 매핑 정보를 활용해서 SQL을 만들게 된다.
자바에서 작성한 jpql 코드
select i
from Item i
where i.itemName like concat('%',:itemName,'%')
and i.price <= :maxPricejpql을 통해 실행된 sql문
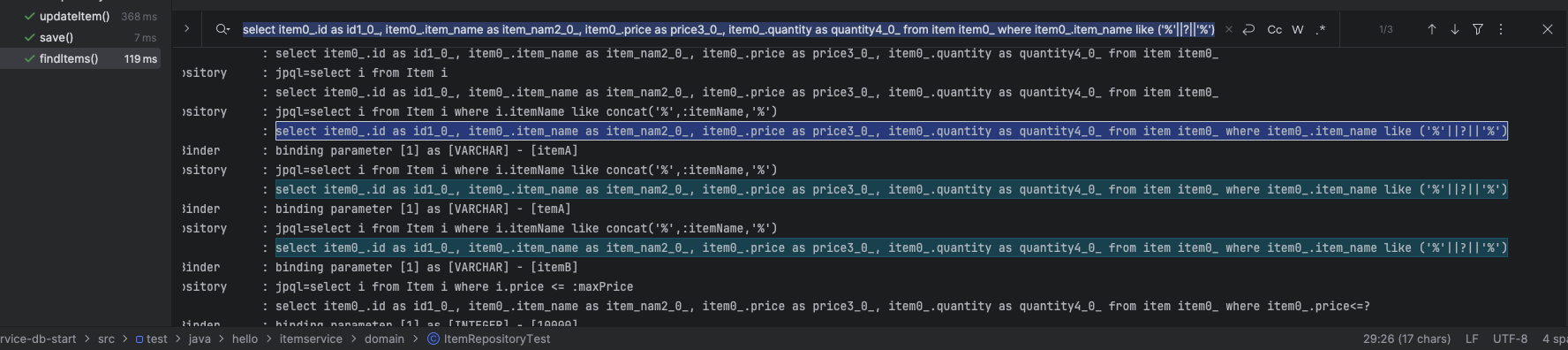
파라미터
JPQL에서 파라미터는 다음과 같이 입력한다.
where price <= :maxPrice
파라미터 바인딩은 다음과 같이 사용한다.
query.setParameter("maxPrice", maxPrice)
동적 쿼리 문제
JPA를 사용해도 동적 쿼리 문제가 남아있다. 동적 쿼리는 뒤에서 설명하는 Querydsl이라는 기술을 활용하면 매우 깔끔하게 사용할 수 있다. 실무에서는 동적 쿼리 문제 때문에, JPA 사용할 때 Querydsl도 함께 선택하게 된다.
