JPA 시작
스프링이 DI 컨테이너를 포함한 애플리케이션 전반의 다양한 기능을 제공한다면, JPA는 ORM 데이터 접근 기술을 제공한다.
대표적으로 JdbcTemplate이나 MyBatis 같은 SQL 매퍼 기술은 SQL을 개발자가 직접 작성해야 하지만,
JPA를 사용하면 SQL도 JPA가 대신 작성하고 처리해준다.
실무에서는 JPA를 더욱 편리하게 사용하기 위해 스프링 데이터 JPA와 Querydsl이라는 기술을 함께 사용한다.
스프링 데이터 JPA, Querydsl은 JPA를 편리하게 사용하도록 도와주는 도구라 생각하면 된다.
이번 포스팅에서는 간단하게 "JPA"와 "스프링 데이터 JPA", 그리고 "Querydsl"로 이어지는 전체 그림을 작성하겠다.
JPA란?
Java Persistence API의 준말이며 자바 진영의 ORM 기술 표준이다.
ORM이란?
Object-relational mapping (객체 관계 매핑)
객체는 객체대로 설계
관계형 DB는 RDB대로 설계
ORM Frame-work이 중간에서 mapping
대중적인 언어에는 대부분 ORM 기술이 존재
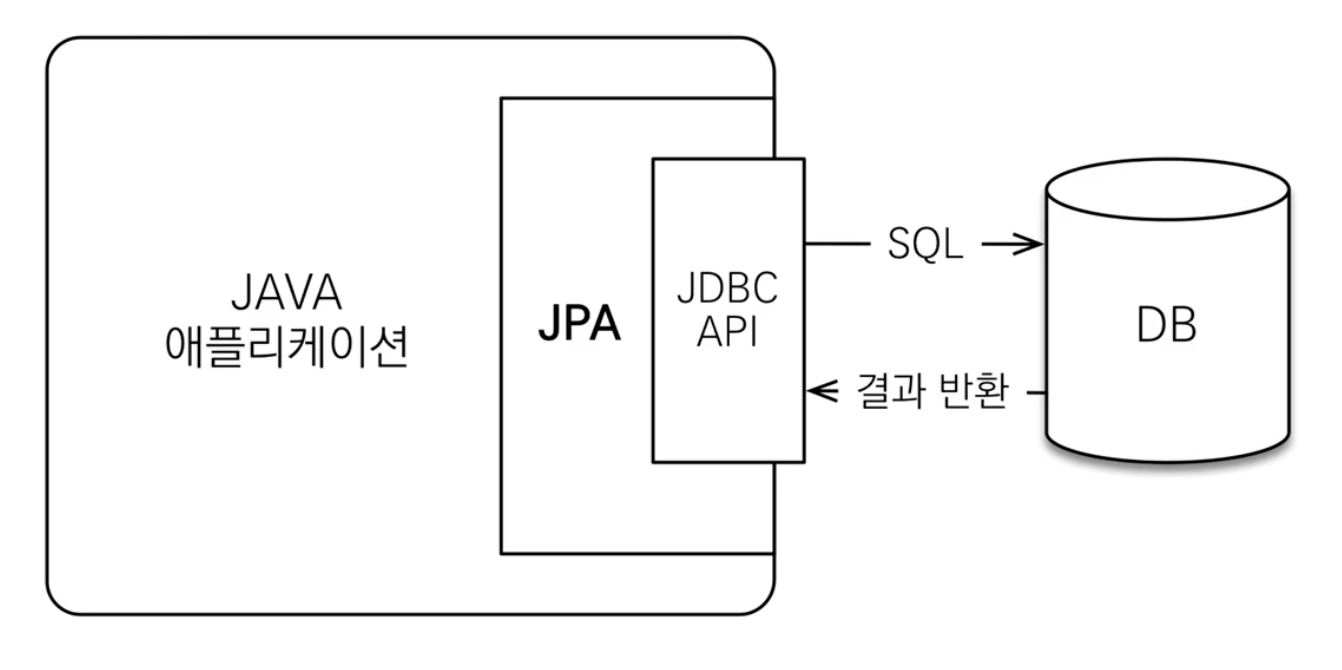 JPA는 백엔드 어플리케이션과 JDBC 사이에서 동작한다.
JPA는 백엔드 어플리케이션과 JDBC 사이에서 동작한다.
JPA 동작 그림
저장
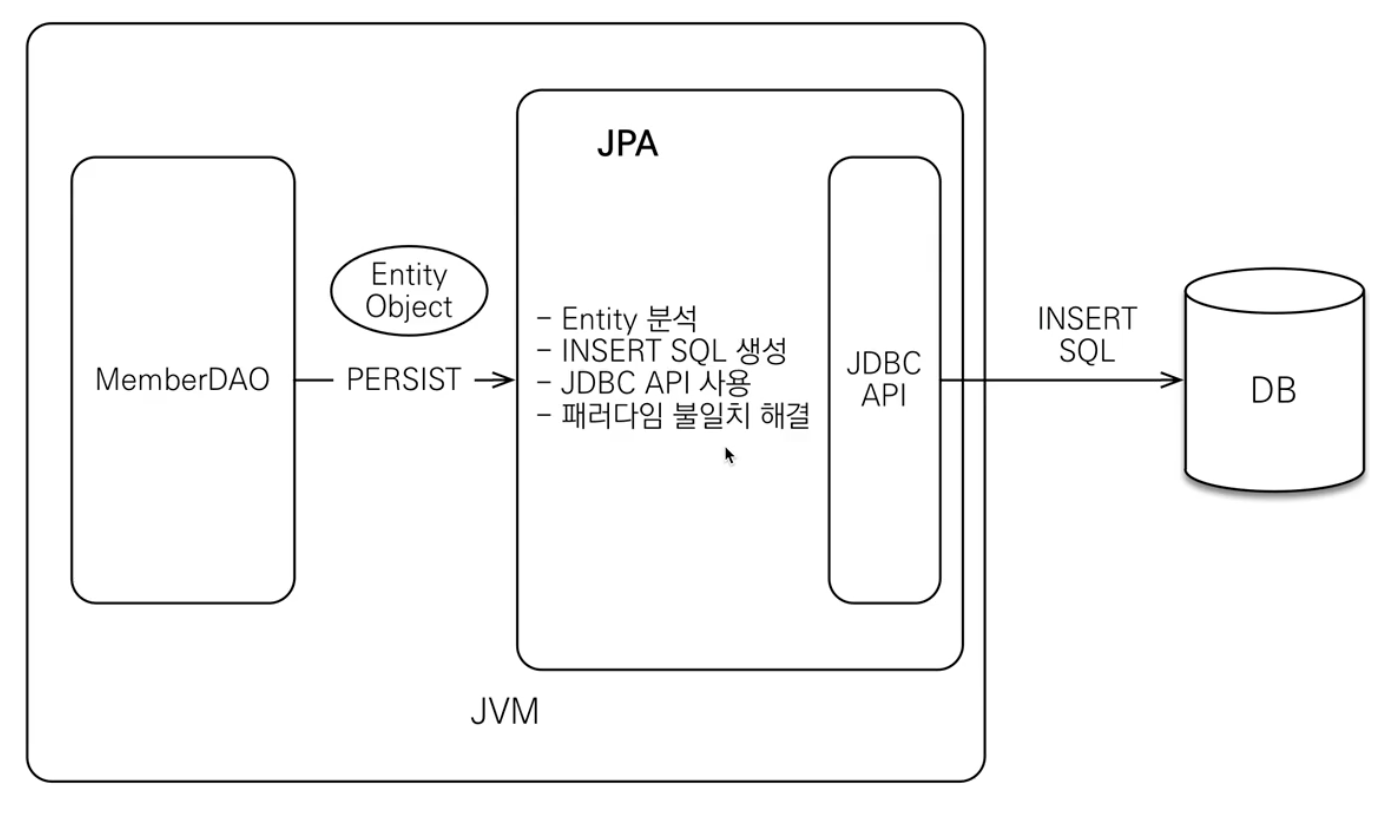 참고로 위 그림에서 DAO는 Repository이다.
참고로 위 그림에서 DAO는 Repository이다.
조회
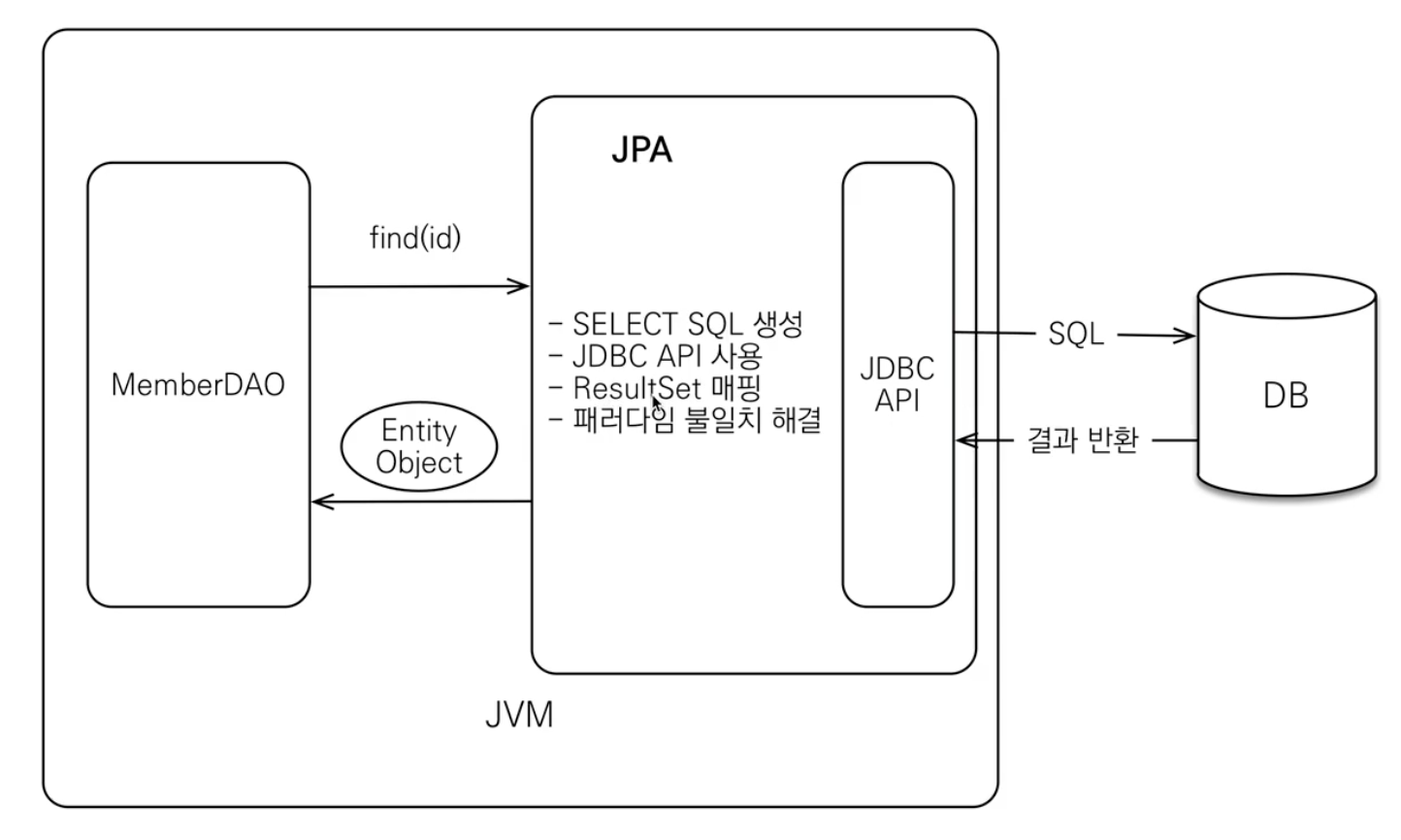 이렇게 JPA를 사용하면 앞서 계속 설명한 SQL 중심적인 개발의 문제점의 한계를 넘을 수 있다.
이렇게 JPA를 사용하면 앞서 계속 설명한 SQL 중심적인 개발의 문제점의 한계를 넘을 수 있다.
마치 Java Collection에서 조회하는 것 처럼 그냥 .getXXX 로 값을 RDB에서 가져올 수 있다는 것이다.
이는 JPA를 사용함으로써 SQL 중심 개발 -> 객체 중심 개발, 패러다임 불일치 해결, 데이터 접근 추상화와 벤더 독립성, 등의 이점을 가져올 수 있다.
JPA 장점
물론 수 가지가 있겠지만 그 중 몇개만 추가로 소개하자면
상속개념이 가능한 것 처럼 보이도록 하는 것은 물론이고 이로인해 저장, 조회를 매우 간단하게 해올 수 있다.
연관관계, 객체 그래프 탐색
연관관계 저장
member.setTeam(team);
jpa.persist(member);
객체 그래프 탐색
Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam();
비교
Member member1 = jpa.find(Memver.class, memberId);
Member member2 = jpa.find(Memver.class, memberId);
member1 == member2;값만 같은게 아니라 주소가 같은 같은 객체 인스턴스가 반환이 된다는 것이다. 다만, 동일한 트랜재션에서 조회한 엔티티는 같음을 보장한다.
즉, 마치 Java Collection 처럼 동작한다.
성능 최적화
1. 1차 캐시와 동일성(identity) 보장
- 같은 트랜잰셕 안에서는 같은 엔티티를 반환
- DB Isolation Level이 Read Commit이어도 어플리케이션에서 Repeatable Read 보장
Member member1 = jpa.find(Memver.class, memberId); // SQL
Member member2 = jpa.find(Memver.class, memberId); // 캐시
member1 == member2;2. 트랜잭션을 지원하는 쓰기 지연(transactional write-behind
- 트랜잭션을 커밋할 때까지 INSERT SQL을 모음 즉, buffering-write 라고 buffer를 모아서 한 큐에 write하는 방법이다.
- JDBS BATCH SQL 기능을 사용해서 한번에 SQL 전송
transaction.begin();
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
// 여까지 Insert SQL을 안 보냄.
// 이때 INSERT SQL을 모아서 보냄. -> 버퍼를 모아서 한 큐에 보냄
transaction.commit();3. Lazy loading, immediate loading
항상 두 계층 사이에 껴서 어떤 기능을 지원한다고 한다면 보통은 1. 캐싱 2. 버퍼링 라이트 를 지원한다.
- 지연 로딩: 객체가 실제 사용이 될 때 로딩
Member member = memberRepository.find(memberId); // SELECT * FROM MEBER
Team team = member.getTeam(); // 여기서 SELECT 문을 실행하지 않고 team 변수에서 값을 꺼내기 전까지 미룸.
String teamName = team.getName(); // SELECT * FROM TEAM- 즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
Member member = memberRepository.find(memberId); // 여기서 JOIN 문이 들어간 SQL 실행
Team team = member.getTeam();
String teamName = team.getName();- 즉, 몇가지 설정으로 2번 query가 날아갈거를 보고 1번 에 가져오도록 할 수 있다.
JPA 설정
설치
spring-boot-starter-data-jpa 라이브러리를 사용하면 JPA와 스프링 데이터 JPA를 스프링 부트와 통합하고, 설정도 아주 간단히 할 수 있다.
build.gradle 에 다음 의존 관계를 추가한다.
//JPA, 스프링 데이터 JPA 추가
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'참고로 spring-boot-starter-data-jpa 는 spring-boot-starter-jdbc 도 함께 포함(의존)한다.
따라서 해당 라이브러리 의존관계를 제거해도 된다. 추가로 mybatis-spring-boot-starter 도 spring-boot-starter-jdbc 를 포함하기 때문에 제거해도 된다.
그럼 아래와 같은 library들이 추가된다.
hibernate-core : JPA 구현체인 하이버네이트 라이브러리
jakarta.persistence-api : JPA 인터페이스
spring-data-jpa : 스프링 데이터 JPA 라이브러리
로그
application.properties 에 다음 설정을 추가하자.
main - application.properties
#JPA log
logging.level.org.hibernate.SQL=DEBUG
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE 마찬가지로 test 패키지에 있는 application.properties에도 똑같이 추가해준다.
org.hibernate.SQL=DEBUG : 하이버네이트가 생성하고 실행하는 SQL을 확인할 수 있다.
org.hibernate.type.descriptor.sql.BasicBinder=TRACE : SQL에 바인딩 되는 파라미터를 확인할 수 있다.
spring.jpa.show-sql=true: 참고로 이런 설정도 있다. 이전 설정은 logger 를 통해서 SQL이 출력된다.
이 설정은 System.out 콘솔을 통해서 SQL이 출력된다. 따라서 이 설정은 권장하지는 않는다. (둘다 켜면 logger , System.out 둘다 로그가 출력되어서 같은 로그가 중복해서 출력된다.)
스프링 부트 3.0
스프링 부트 3.0 이상을 사용하면 하이버네이트 6 버전이 사용되는데, 로그 설정 방식이 달려졌다. 다음과 같이 로그를설정해야 한다.
#JPA log
logging.level.org.hibernate.SQL=DEBUG
logging.level.org.hibernate.orm.jdbc.bind=TRACE