데이터분석종합반 3일차
스파르타코딩클럽 데이터분석종합반
학습일자: 2022/06/04
강의: 데이터분석종합반
진도: 2-1 ~ 2-6
============================
2주차부터는
텍스트 분석을 중점적으로 다룬다고 한다.
텍스트 가공, 가공된 텍스트로 결과를 예측
============================
*리스트 컴프리헨션
참고자료: https://wikidocs.net/22805
print([x for x in range(1, 11)])
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
if문 혼합
짝수를 찾는방법
>>> [x for x in range(1, 10+1) if x % 2 == 0]
[2, 4, 6, 8, 10]
2주차 초장부터 어렵다고 으름장을 놓고 있다.
이런다고 내가 쫄줄 알았냐?
============================
2-2. 텍스트 마이닝을 위한 기본 세팅
코랩 사용시 - 폰트 지정
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()코랩 환경에서 csv파일 업로드
여기서 파일 드래그해도 됨
코랩 매번 켤 때마다 다시 진행해줘야 함
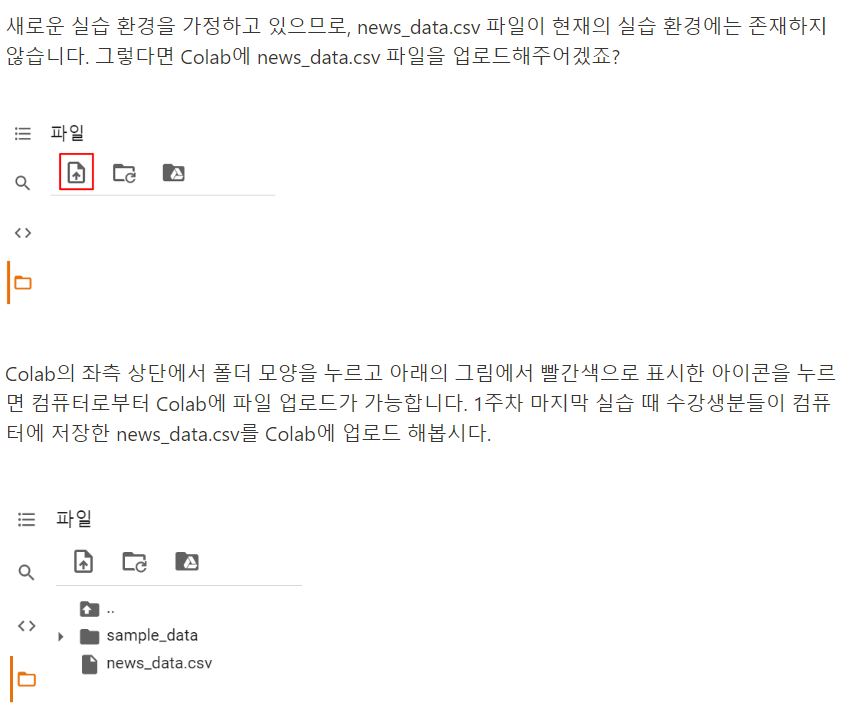
갑자기 1주차때 만든 데이터를 쓰자고 한다.
아니 말을 해줘야지 ㅠㅠ난 저장 안했는데...
그래서 코드를 다시 짰다
import requests
import pandas as pd
from newspaper import Article
from bs4 import BeautifulSoup
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
# 연습 ===========================
# page_num = 1
# code = 101
# date = 20200506
# url = 'https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1='+str(code)+'&date='+str(date)+'&page='+str(page_num)
# print(url)
# news = requests.get(url, headers=headers)
# print(news.content)
# 연습 끝 =========================
def make_urllist(page_num, code, date):
urllist = []
for i in range(1, page_num + 1):
url = f'https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1='+str(code)+'&date='+str(date)+'&page='+str(i)
news = requests.get(url, headers=headers)
# news.content
soup = BeautifulSoup(news.content, 'html.parser')
news_list = soup.select('.type06_headline li dl')
news_list.extend(soup.select('.type06 li dl'))
for line in news_list:
urllist.append(line.a.get('href'))
return urllist
url_list = make_urllist(2, 101, 20200506)
print('뉴스 기사의 개수 :',len(url_list))
print(url_list[:5])
idx2word = {'101' : '경제', '102' : '사회', '103' : '생활/문화', '105' : 'IT/과학'}
def make_data(urllist, code):
text_list = []
for url in urllist:
article = Article(url, language='ko')
article.download()
article.parse()
text_list.append(article.text)
df = pd.DataFrame({'news': text_list})
df['code'] = idx2word[str(code)]
return df
data = make_data(url_list, 101)
# print(data[:10])
code_list = [102, 103, 105]
def make_total_data(page_num, code_list, date):
df = None
for code in code_list:
url_list = make_urllist(page_num, code, date)
df_temp = make_data(url_list, code)
print(str(code)+'번 코드에 대한 데이터를 만들었습니다.')
if df is not None:
df = pd.concat([df, df_temp])
else: df = df_temp
return df
df = make_total_data(10, code_list, 20200506)
print('뉴스 기사의 개수 :',len(df))
df.to_csv('news_data.csv', index=False)============================
2-3. 텍스트 마이닝 (1)
2-3강에서 사용되는 판다스 함수 정리
isnull() -> 빈 행/열을 true값으로 반환
isnull().sum() -> 빈 행/열의 개수를 반환
unique() -> 고유값
nunique() -> 고유값들의 개수
drop_duplicates() -> 중복 제거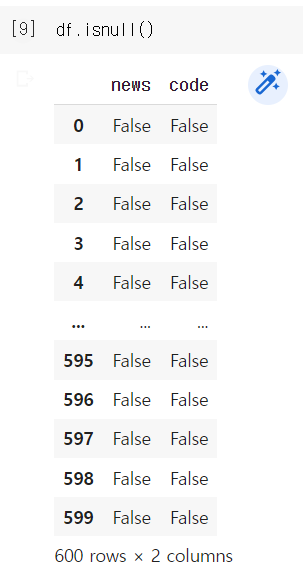
df.isnull()의 출력형태

df.isnull().sum()의 출력형태

df.['컬럼명'].unique()의 출력형태
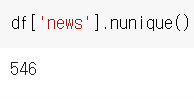
df.['컬럼명'].nunique()의 출력형태
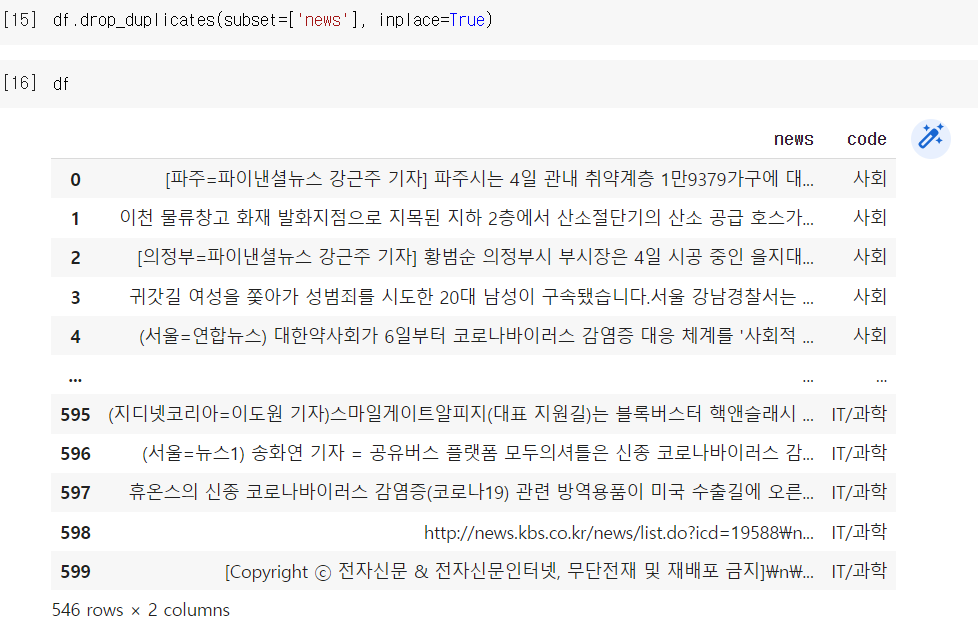
df.drop_duplicates(subset=['컬럼명'], inplace=True)의 출력형태
subset = 중복값을 체크할 컬럼명
inplace = 원본데이터를 수정할지(True) 말지(False)를 선택.
inplace를 지정하지 않고 코딩하면 원본데이터인 df는 변동이 없음.
df2 = df.drop_duplicates(subset=['news'])의 형태로 새 변수에 할당하는 방식
- len(df) = df의 인덱스 개수 확인가능
============================
2-3. 텍스트마이닝(1) 계속
컬럼별 개수를 확인하고 싶을 때
df['컬럼'].value_counts()
df['code'].value_counts()의 출력형태
위 데이터를 시각화하고 싶을 때
막대형 그래프로 출력하는 법
df['code'].value_counts().plot(kind='bar')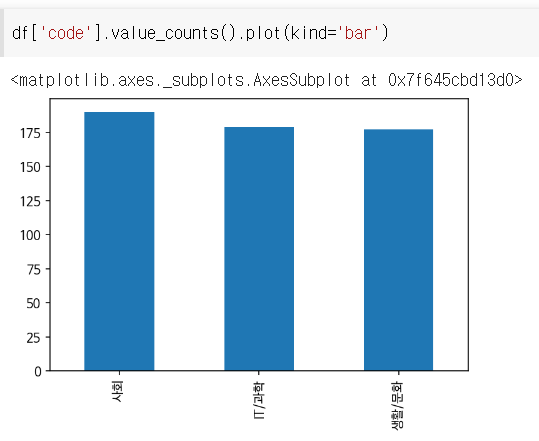
아니 이런 미친? 이게 걍 바로되네
============================
2-3. 텍스트 마이닝 (1)
2-2강 복습정리
============================
2-4. 텍스트 마이닝 (2)
필요없는 단어를 확인하고 제거하는 작업
형태소 분석, 토큰화
형태소 분석 라이브러리
터미널: pip install konlpy
코드: from konlpy.tag import Okt (명사 단위 형태소 분석)
###konlpy 에러 시!
본 벨로그의 파이썬 에러 모음집 참고!
tokenizer = Okt() #명사분석기를 토크나이저로 사용하겠다 선언
kor_text = '밤에 귀가하던 여성에게 범죄를 시도한 대 남성이 구속됐다서울 제주경찰서는 \
상해 혐의로 씨를 구속해 수사하고 있다고 일 밝혔다씨는 지난달 일 피해 여성을 \
인근 지하철 역에서부터 따라가 폭행을 시도하려다가 도망간 혐의를 받는다피해 \
여성이 저항하자 놀란 씨는 도망갔으며 신고를 받고 주변을 수색하던 경찰에 \
체포됐다피해 여성은 이 과정에서 경미한 부상을 입은 것으로 전해졌다'konly 사용 방법
from konlyp.tag import Okt (명사 단위 형태소 분석)
변수 A (예: tokenizer) = Okt() # 명사분석기를 변수A로 사용하겠다 선언
변수 B (예: kor_text) = 문자열 텍스트
tokenizer.nouns(kor_text) (명사만 뽑아냄)
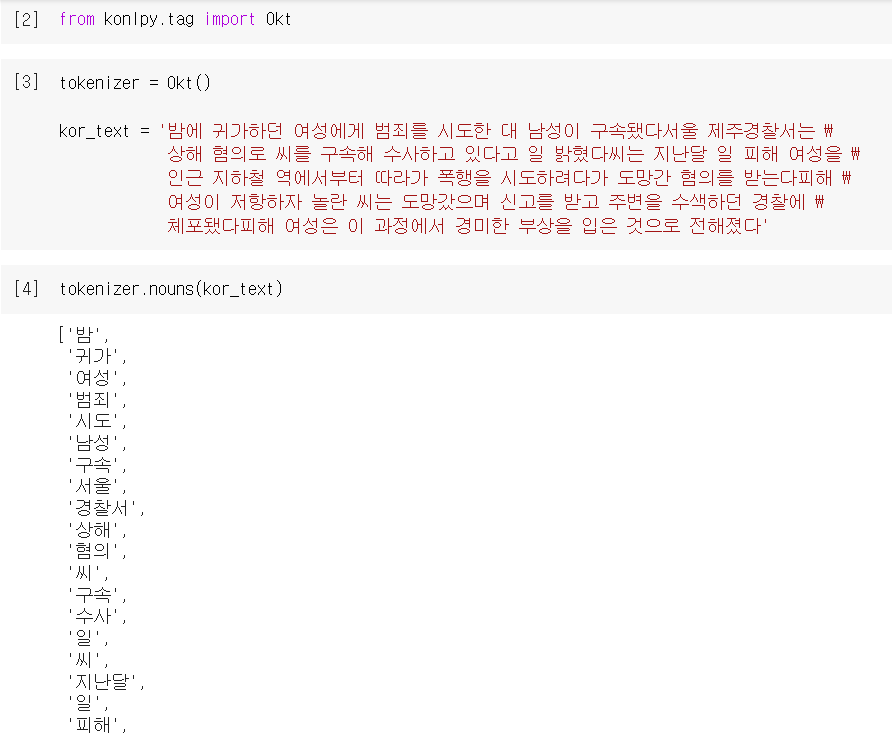
이야 ㅋㅋㅋㅋ
불용어 리스트
stop_words = ['기자', '제공', '무단', '배포', '무단배포', '배포금지', '이번', '위해', '라며', '금지', '뉴스', '통해', '오늘', '지난달', '지난', '대한', '경우', '관련', '뉴시스', '현재', '지난해', '때문', '지금', '또한', '만큼', '최근', '당시', '올해', '대해', '다시', '모두']df['tokenized'] = df['news'].apply(tokenizer.nouns)df['컬럼명']apply(함수) = 함수가 컬럼에 있는 열 각각마다 진행됨
위의 코드는 뉴스에 있는 각각의 열마다 명사로 토큰화를 하고, tokenized라는 열에 저장하겠다는 뜻

이제, stop_words에 포함된 단어가 있는지 확인해서 제외하는 단계
그 전에
리스트 컴프리헨션, 람다
리스트 컴프리헨션 예시
test_list = ['경찰서', '상해', '혐의', '씨', '구속', '수사', '일']
remove_word_list = ['경찰서', '구속']
test_list = [item for item in test_list if item not in remove_word_list and len(item) > 1]

람다 예시
df['tokenized'] = df['tokenized'].apply(lambda x: [item for item in x if item not in stop_words and len(item) > 1])

============================
2-5. 텍스트 마이닝 (3)
불용어 제거된 데이터프레임을 활용해 빈도수를 확인해보는 과정
df[df['code']=='사회']
대괄호 안에 조건을 넣으면, 조건을 충족하는 것만 출력됨

df[df['code']=='사회'].values
df['컬럼'].values. 속성을 출력함

예시
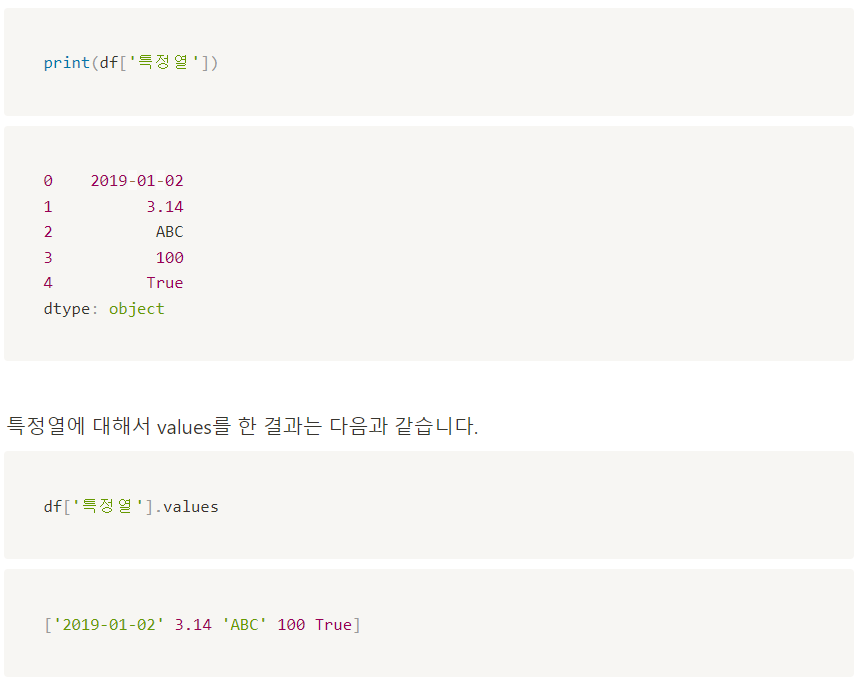

코드가 사회인 것 중 컬럼이 tokenized인 애들만 출력됨
df[df['code']=='사회']['tokenized'].values를 해봤더니

리스트 안에 리스트들이 들어있음. 이걸 원하는게 아닌데.
여기서 필요한 Numpy 등장
근데... 그냥 extend로 처리하면 안되나?
아무튼, 여기서 요소들이 중복되게 있다면 중복을 제거해주는가?
import numpy as np
temp_list = [['a', 'b', 'c'], ['i', 'j', 'k'], [1, 2, 3, 'c']]
result = np.hstack(temp_list)
print(result)
중복된 데이터를 제거하지 않고 반환한다.

counter 함수의 등장
from collections import Counter
함수 예제
test_list = ['바나나', '전화기', '바나나', '바나나', '사과', '사과', '딸기', '메론', '수박', '수박', '토마토', '토마토', '전화기', '전화기', '전화기']단어 카운트를 수행
test_word_count = Counter(test_list)전체 단어 카운트를 출력
print(test_word_count)
>>>Counter({'전화기': 4, '바나나': 3, '사과': 2, '수박': 2, '토마토': 2, '딸기': 1, '메론': 1})빈도수 상위 3개에 대해서만 카운트를 출력
print(test_word_count.most_common(3))
>>>[('전화기', 4), ('바나나', 3), ('사과', 2)]
============================
2-6. 데이터 시각화 - 워드 클라우드
워드클라우드 뼈대 코드
터미널에서 pip install wordcloud 진행 후
from wordcloud import WordCloud
# 사용하고자 하는 폰트의 경로. Colab에서는 이 경로를 사용하시면 됩니다.
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
wc = WordCloud(max_words = 사용할 단어의 수 , width = 가로, height = 세로, font_path = fontpath).generate('입력 문자열')
plt.imshow(wc, interpolation = 'bilinear')워드클라우드는 리스트형태가 아니라 문자열 형태로만 만든다.
그러므로, 지난강의에 만든 리스트를 문자열로 변환한다.


' '.join(변수) = ' ' 사이에 있는 기호를 변수 내 각각의 요소에 넣으면서 문자열로 통합
워드클라우드 생성 코드
# 사용하고자 하는 폰트의 경로. Colab에서는 이 경로를 사용하시면 됩니다.
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
wc = WordCloud(max_words = 2000 , width = 1600, height = 800, font_path = fontpath).generate(temp_data)
plt.imshow(wc, interpolation = 'bilinear')
생성된 워드클라우드의 모습
============================
무엇을 배웠나
collections - counter(변수), most_common(숫자)
numpy - np.hstack(변수)중복을 제거하지 않고 리스트 병함
koNLpy - Okt()명사단위로 형태소 분석, nouns(변수)
리스트 컴프리헨션, 람다
pandas - df['컬럼'].values, df['컬럼의 조건']
각 모듈별 사용된 함수 정리하기!
============================
============================
============================
============================
