데이터분석종합반 1일차
스파르타코딩클럽 데이터분석종합반
학습일자: 2022/05/30
강의: 데이터분석종합반
진도: 1-1 ~ 1-12
============================
회사가 주는 지원금으로 스파르타코딩클럽 데이터분석 종합반 수강신청.
이번엔 어떤 스트레스를 줄지 기대되는 강의.
============================
1-2. 데이터분석 맛보기
학생들의 데이터를 모아놓은 엑셀로 요인과 성적의 상관관계 분석
이런식으로 상관관계가 있다~ 라고 설명하는 정도.
============================
1-3. 구글 colab과 익숙해지기
Colab = 개발도구. 문서작성기. 인터넷과 구글아이디 필요. 파이썬 노필요. 실행은 쉬프트+엔터
Colab 홈페이지
마지막에 작성한 코드값만 출력되는 특징이 있음

이런 식...

프린트를 쓰면 두개 다 출력된다.
============================
1-4. 파이썬 기초 (1)
변수, 자료형(정수-inteager, 실수형-float, 문자열-string, 리스트-list)
리스트의 인덱스, 추가(append), 리스트 합치기(extend)

extend 사용한 모습.

append 사용한 모습.
append를 사용하면 b가 a의 요소 중 하나로 들어가고, extend를 사용하면 b의 각 요소들이 a의 각 요소들이 된다.
============================
1-5. 파이썬 기초 (2)
반복문. 코딩시 들여쓰기 중요
============================
1-6. 파이썬 기초 (3)
비교연산자(>, <, >=, <=, !=, ==)
조건문에 대한 설명
============================
1-7. 파이썬 기초 (4)
함수에 대한 설명
함수(인자)형태
============================
1-8. 파이썬 기초 (5)
클래스, 인스턴스
붕어빵 틀 = 클래스
붕어빵 틀에서 생산돼 나온 붕어빵 = 인스턴스(객체)
try, except문
============================
1-9. 파이썬 기초 (6)
패키지란 무엇인가
누군가 만들어놓은 함수, 클래스 덩어리. 라이브러리. import로 불러옴
예시1
import pandas as pd
items = {'code' : [101, 102, 103, 104, 105, 106, 107, 108],
'과목': ['수학', '영어', '국어', '체육', '미술', '사회', '도덕', '과학'],
'수강생':[15, 15, 10, 50, 20, 50, 70, 10],
'선생님': ['김민수','김현정','강수정', '이나리', '도민성', '강수진', '김진성', '오상배']}
df = pd.DataFrame(items)
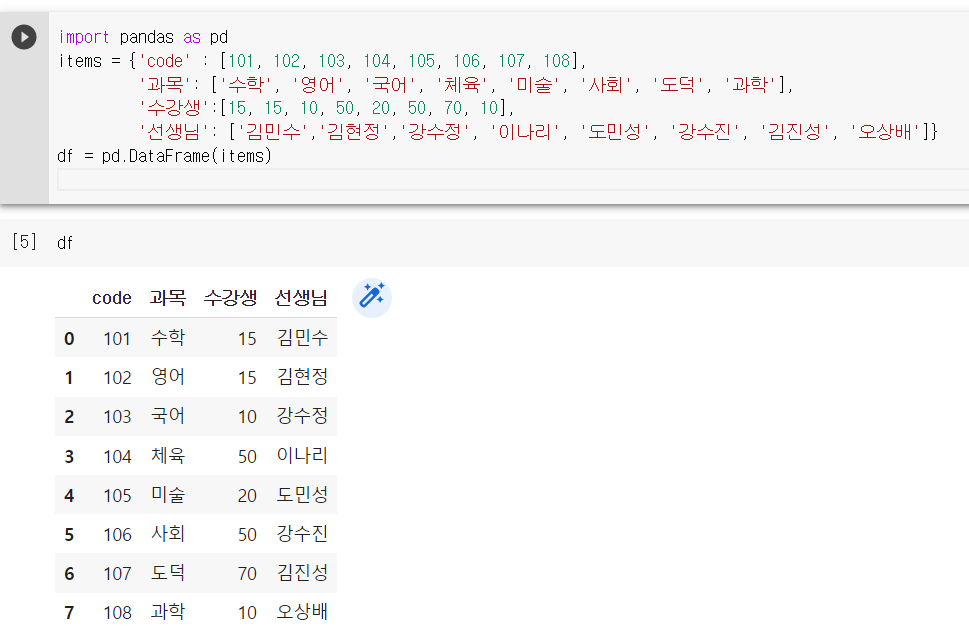
df라는 변수에 데이터프레임을 담고
df.head() = 상위 5개 행만 출력
df.tail() = 하위 5개 행만 출력

df.sample(3) = 무작위로 n개만큼 추출
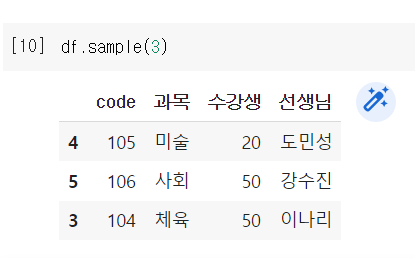
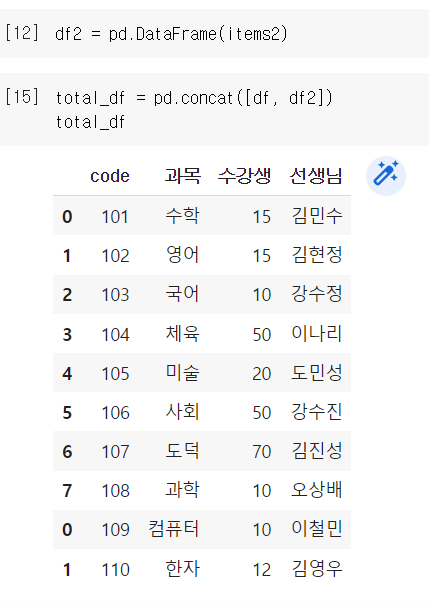
예시2
items2 = {'code' : [109, 110],
'과목': ['컴퓨터', '한자'],
'수강생':[10, 12],
'선생님': ['이철민', '김영우']}total_df = df.concat([df, df2]) << 두 데이터프레임을 병합
가공한 데이터 저장
total_df.to_csv('data.csv')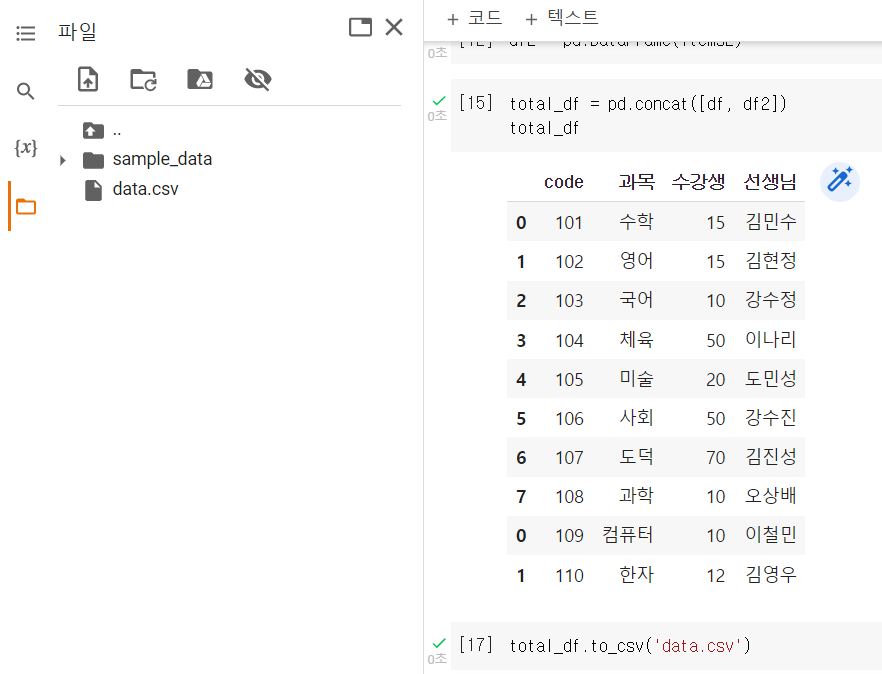
구글코랩에선 이런식으로 저장됨
저장한 데이터를 불러오기
new_df = pd.read_table('data.csv', sep=',')
# sep='' seperator. ''안에 들어있는 것을 기준으로 열을 나누겠다
new_df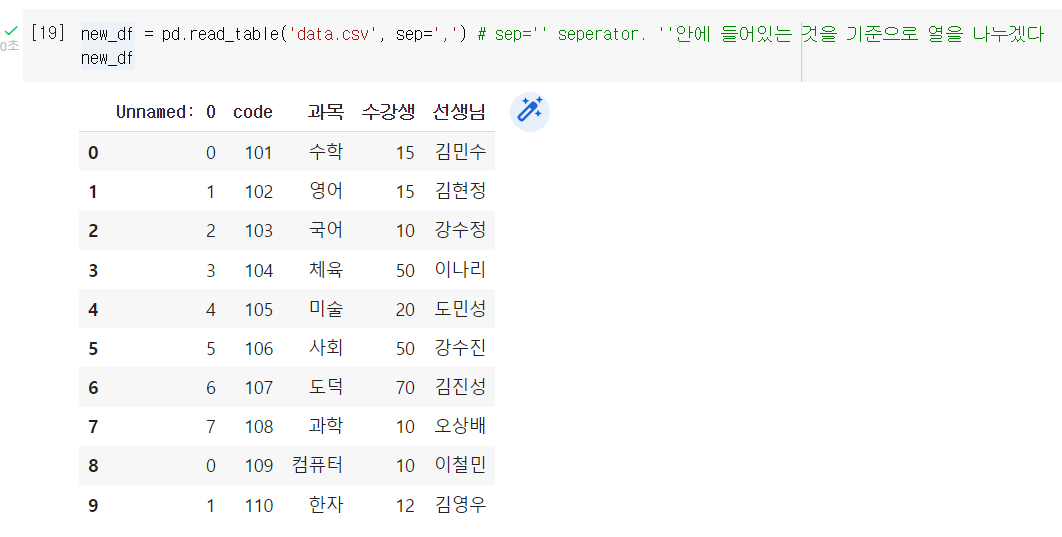
unnamed:0 << 이건 무엇이냐?
위에서 csv파일로 저장할때 인덱스까지 저장해버려서 나오는 컬럼
저장 단계에서 제외되도록 처리할 수 있는데,
total_df.to_csv('data.csv', index=False)
이렇게 처리하면 인덱스는 제외됨
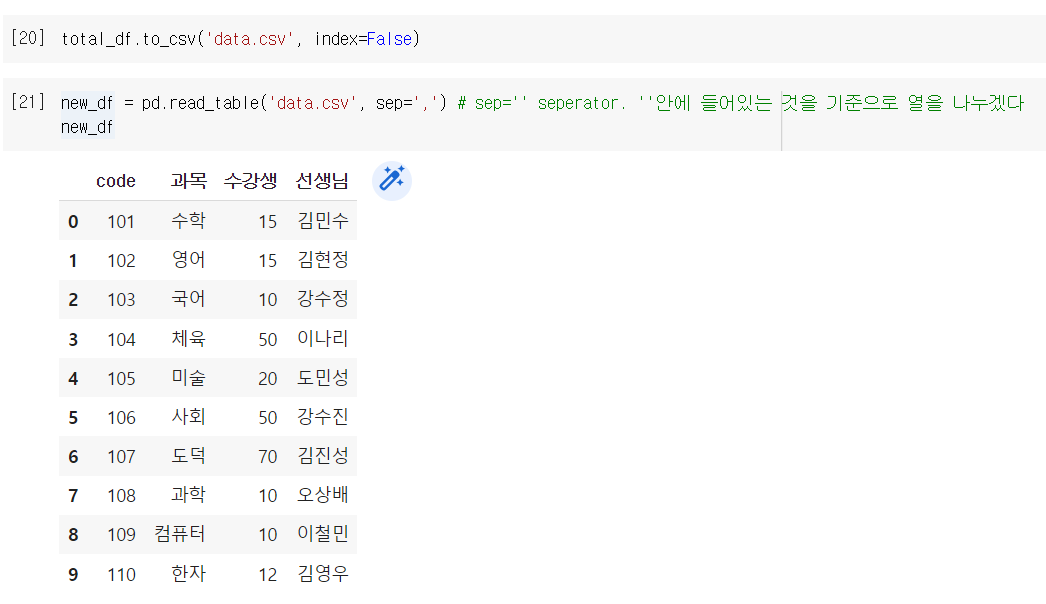
unnamed가 사라진 것을 확인.
============================
1-10. 웹 이해하기
웹이란 무엇인가에 대한 이해가 선행되어야 함.
웹사이트는 사실 텍스트 덩어리다.
크롤링 = 웹사이트로부터 데이터를 가져오는 것
크롤러 = 크롤링 하는 프로그램
HTML = 웹에서 출력되는 텍스트 덩어리
태그 =<div></div>, <body></body>, <a></a>등등 꺽쇠 안에 있는 것
선택자 = 아이디, 클래스 등. 웹페이지 내부의 구성요소의 주소
============================
1-11. 웹스크래핑 패키지 이해하기
패키지란 이미 만들어져있는 함수, 기능들의 묶음이다.
설치시
pip install 패키지이름
사용시
import 패키지이름 (as 호출할때 쓸 이름)
혹은
from 패키지이름 import 모듈(패키지 내부에서 가져올 기능 이름) (as 호출할때 쓸 이름)
크롤링 시 자주 쓰는 패키지: BeautifulSoup
웹페이지를 긁어와서 html이라는 변수에 저장했다는 가정 하에
soup = BeautifulSoup(html, 'html.parser')
(변수이름, 어떤 식으로 분석할지 그 방법)
--> BeautifulSoup은 html 말고도 다양한 양식을 분석할 수 있다는 뜻beautifulsoup을 사용해서 선택자를 불러올 수 있다.
soup.select() or soup.select_one()
- soup.select('태그명') : 태그를 입력으로 사용할 경우
- soup.select('.클래스명') : 클래스를 입력으로 사용할 경우
- soup.select('#아이디') : ID를 입력으로 사용할 경우
- soup.select('상위태그명 하위태그명') : 자손 관계 (어떤 태그 내부에 있는 모든 태그를 자손이라고 함)
- soup.select('상위태그명 > 하위태그명') : 자식 관계 (어떤 태그 내부에 있는 태그 중 바로 한 단계 아래에 있는 태그를 자식이라고 함)
예제)
# HTML 문서를 문자열 html로 저장
html = '''
<html>
<head>
</head>
<body>
<h1> 장바구니
<p id='clothes' class='name' title='라운드티'> 라운드티
<span class = 'number'> 25 </span>
<span class = 'price'> 29000 </span>
<span class = 'menu'> 의류</span>
<a href = 'http://www.naver.com'> 바로가기 </a>
</p>
<p id='watch' class='name' title='시계'> 시계
<span class = 'number'> 28 </span>
<span class = 'price'> 32000 </span>
<span class = 'menu'> 액세서리 </span>
<a href = 'http://www.facebook.com'> 바로가기 </a>
</p>
</h1>
</body>
</html>
'''
# BeautifulSoup 인스턴스 생성. 두번째 매개변수는 분석할 분석기(parser)의 종류.
soup = BeautifulSoup(html, 'html.parser')태그 긁어오기 - body태그의 내용을 가져오고 싶을 때

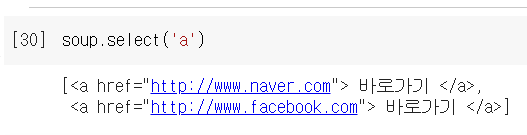
태그 긁어오기2 - a태그의 내용을 가져오고 싶을 때
클래스 긁어오기 - price만 가져오고 싶을 때

아이디 긁어오기 - watch만 가져오고 싶을 때

내부의 클래스 긁어오기 - clothes 안에 있는 price 요소만

공통된 태그 중 맨 위의 태그 가져오기(잘 안쓰는 방법)
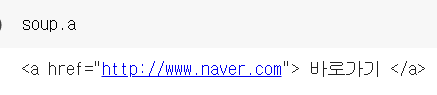
공통된 태그 중 맨 위의 태그의 속성에 담겨있는 값 가져오기(잘 안쓰는 방법)

============================
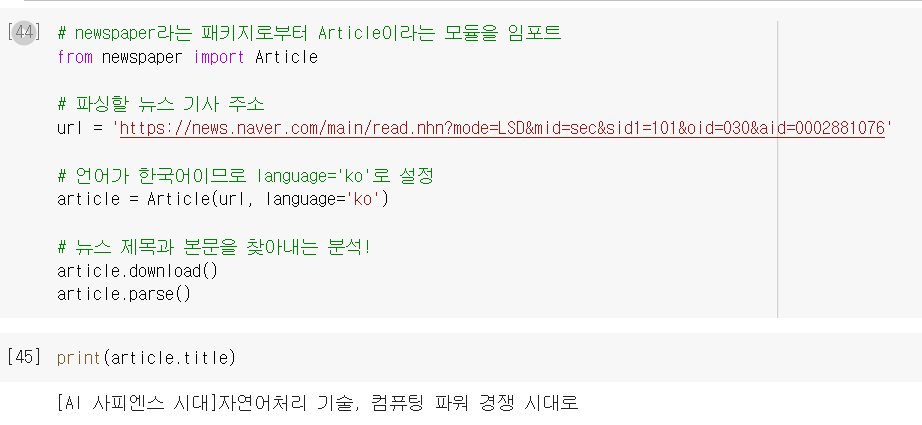
newpaper3k의 개요
newspaper3k는 뉴스 데이터를 크롤링을 위한 패키지입니다. 사용자가 인터넷 뉴스 기사의 url을 전달해주면, 이로부터 뉴스 기사의 제목과 텍스트를 추출합니다.
여기서 잠깐,
pip install newspaper3k를 다운로드 하는데 pip 업그레이드 하라는 말이 나왔다.
cmd 관리자실행 후
python -m pip install --upgrade pip

article.title과 article.text로 제목과 본문을 각각 불러옴
============================
1-12. 네이버 뉴스 구조 파악하기
URL 분석
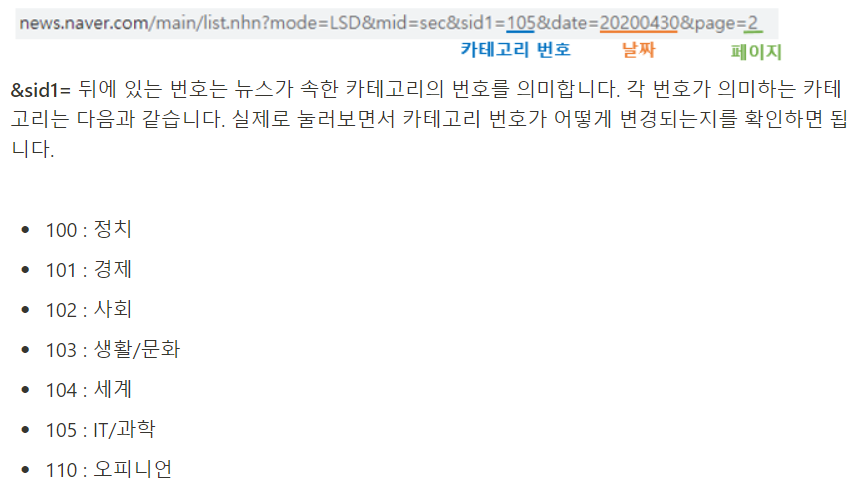
그렇다고 합니다

그렇군요...
기존에 내가 알던 내용 복습
뉴스페이지의 첫번째 기사 url 가져오기
from bs4 import BeautifulSoup
import requests
url = f'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1=101'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url, headers=headers)
# print(data) # 200
soup = BeautifulSoup(data.text, 'html.parser')
# print(soup) # html가져옴
news1_url = soup.select_one('#main_content > div.list_body.newsflash_body > ul.type06_headline > li:nth-child(1) > dl > dt.photo > a')
print(news1_url.get('href'))
성공! 단 하나만 가져오긴 했지만.
============================
============================
============================
============================
