
시계열 분석이란 시간에 따라 변하는 데이터를 사용하여 추이를 분석하는 것이다.
시계열 형태는 데이터 변동 유형에 따라 불규칙 변동, 추세 변동, 순환 변동, 계절변동으로 구분할 수 있다.
- 불규칙 변동 : 어떤 규칙성이 없어 예측 불가능하고 우연적으로 발생하는 변동
- 추세 변동 : 시계열 자료가 갖는
장기적인변화 추세- 순환 변동 : 2 ~ 3년 정도의일정한 기간을 주기로 순환적으로 나타나는 변동
- 계절 변동 : 시계열 자료에서 보통 계절적 영향과 사회적 관습에 따라 1년 주기로 발생하는 것
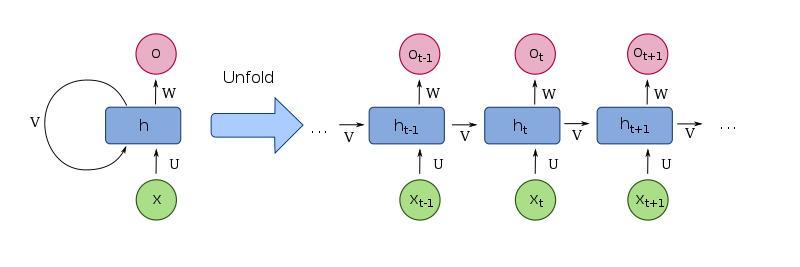
RNN(순환 신경망)
RNN(Recurrent Neural Network)은 시간적으로 연속성이 있는 데이터를 처리하려고 고안된 인공 신경망이다.
RNN에서는 외부 입력과 자신의 이전 상태를 입력받아 현재 상태를 갱신하며, 최종적으로 남겨진 기억은 모든 입력 전체를 요약한 정보이다.
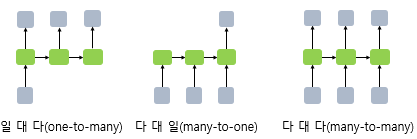
RNN의 유형은 다음과 같다.
▶︎ 일대일
- 순환이 없기 때문에 RNN이라고 말하기 어렵다.
- 순방향 네트워크가 대표적인 사례
▶︎ 일대다
- 일력이 하나이고, 출력이 다수인 구조
- 이미지 캡션(이미지를 입력해서 이미지에 대한 설명을 문장으로 츨력)이 대표적인 사례
▶︎ 다대일
- 입력이 다수이고, 출력이 하나인 구조
- 문장을 입력해서 긍정/부정을 출력하는 감성 분석기에서 사용
self.em = nn.Embedding(len(TEXT.vocab.stoi),embeding_dim) self.rnn = nn.RNNCell(input_dim,hidden_size) self.fc1 = nn.Linear(hidden_size,256) self.fc2 = nn.Linear(256,3)▶︎ 다대다
- 입력과 출력이 다수인 구조
- 언어를 번역하는 자동 번역기 등이 대표적인 사례
# tensorflow의 방식 # keras.layers.SimpleRNN(100, return_sequences = True, name = 'RNN') # pytorch의 방식 Seq2seq( (encoder): Encoder( (embedding) : Embedding(7855,256) (rnn) : LSTM(256,512,num_layers=2,dropout=0.5) (dropout) : Dropout(p=0.5, inplace=False) ) (decoder) : Decoder( (embedding) : Embedding(5893,256) (rnn) : LSTM(256,512,num_layers=2,dropout=0.5) (fc_out) : Linear(in_features=512,out_features=5893,bias=True) (dropout) : Dropout(p=0.5,inplace=False) ) )▶︎ 동기화 다대다
- 입력과 출력이 다수인 구조이다.
- 문장에서 다음에 나올 단어를 예측하는 언어 모델, 즉 프레임 수준의 비디오 분류가 대표적인 사례이다.
RNN 계층과 셀
RNN 계층이 입력된 배치 순서대로 모두 처리하는 것과 다르게 RNN 셀은 오직 하나의 단계만 처리한다. ( RNN 셀은 RNN 계층의 for loop 구문을 갖는 구조 )

RNN 계층은 셀을 래핑하여 동일한 셀을 여러 단계에 적용하며, RNN 셀은 단일 입력과 과거 상태를 가져와 출력과 새로운 상태를 생성한다.
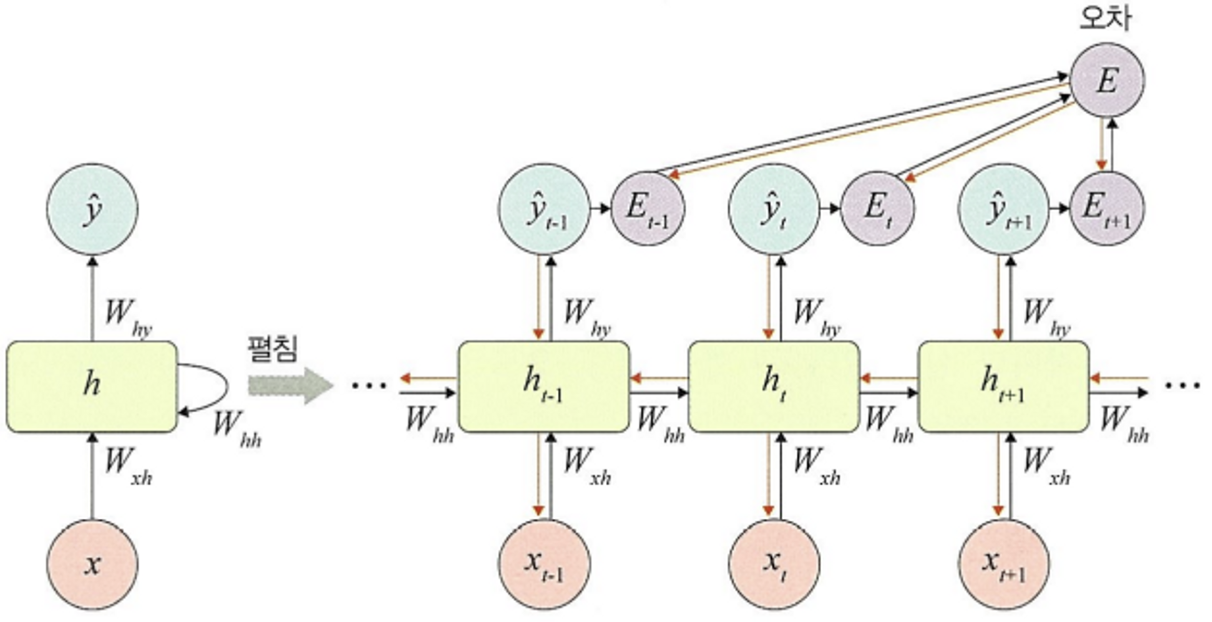
RNN 구조
RNN은 은닉층 노드들이 연결되어 이전 단계 정보를 은닉층 노드에 저장할 수 있도록 구성한 신경망이다.

RNN에서는 입력층,은닉층,출력층 외에 가중치를 세개(,,) 가진다.
- : 입력층에서 은닉층으로 전달되는 가중치
- : 시점의 은닉층에서 시점의 은닉층으로 전달되는 가중치
- : 은닉층에서 출력층으로 전달되는 가중치
🚨 가중치 ,,는 모든 시점에서 동일하다. 즉 가중치를 고유한다.
1️⃣ 은닉층
RNN에서 은닉층은 일반적으로 하이퍼볼릭 탄젠트 활성화 함수를 사용한다.
2️⃣ 출력층
심층 신경망과 계산 방법이 동일하다.
소프트맥스 함수를 적용한다.
3️⃣ 오차
심층 신경망에서 전방향 학습과 달리 각 단계()마다 오차를 측정한다.
즉, 각 단계마다 실제 값()과 예측 값()으로 평균 제곱 오차(MSE)를 이용하여 측정한다.
4️⃣ 역전파
BPTT(BackPropagation Through Time)을 이용하여 모든 단계마다 처음부터 끝까지 역전파한다.
BPTT
각 단계마다 오차를 측정하고 이전 단계로 전달한다.
오차를 이용하여 ,, 및 를 업데이트 한다.🚨 BPTT는 오차가 멀리 전파될 때 계산량이 많아지고 전파되는 양이 점차 적어
기울기 소멸 문제가 발생한다.
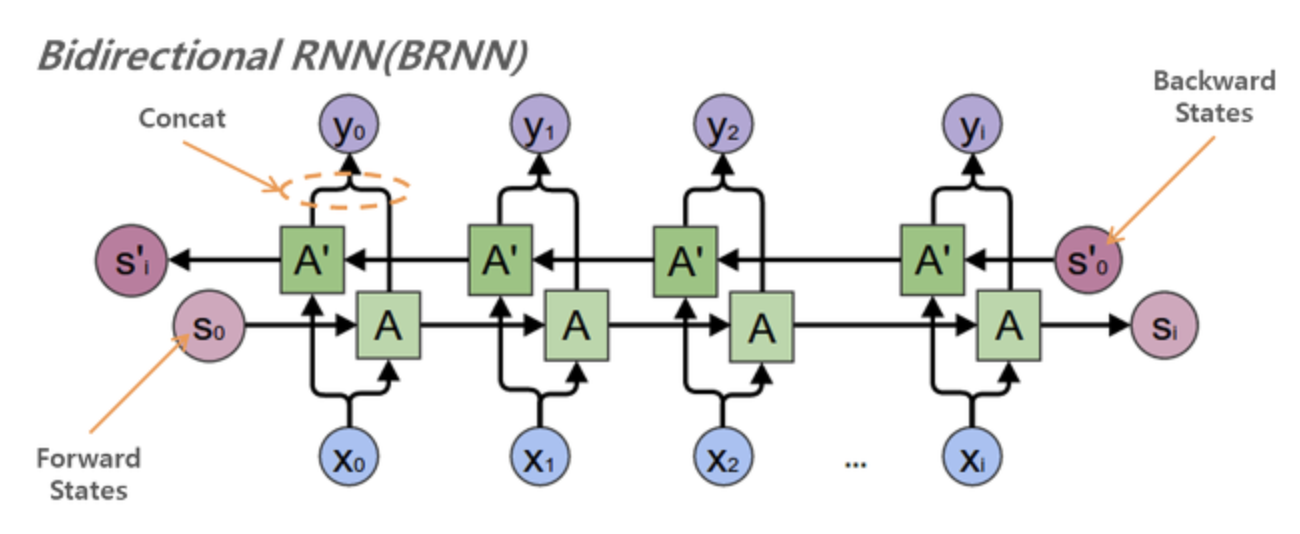
양방향 RNN
양방향 RNN은 하나의 출력 값을 예측하는 데 메모리 셀 두개를 사용한다.
- 첫 번째 메모리 셀은 이전 시점의 은닉 상태(forward states)를 전달받아 현재의 은닉 상태를 계산한다.
- 두 번째 메모리 셀은 다음 시점의 은닉 상태(backward states)를 전달받아 현재의 은닉 상태를 계산한다.
LSTM
기존의 RNN은 가중치가 업데이트되는 과정에서 기울기가 1보다 작은 값이 계속 곱해지기 때문에 기울기가 사라지는 기울기 소멸문제가 발생한다. 이를 해결하기 위해 LSTM(확장된 RNN)을 사용한다.
LSTM 구조
LSTM 순전파
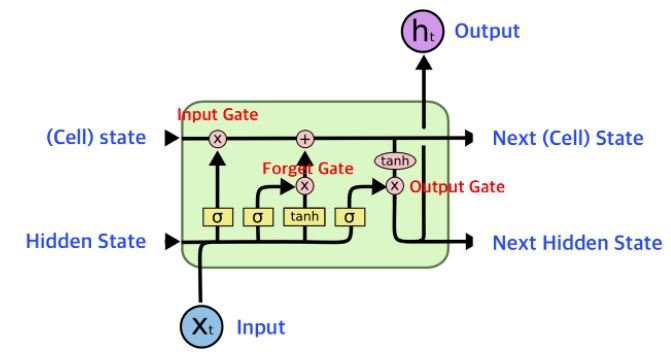
LSTM은 기울기 소멸 문제를 해결하기 위해 세개의 게이트(망각 게이트, 입력 게이트, 출력 게이트)를 은닉층의 각 뉴런에 추가했다.
1️⃣ 망각 게이트
망각 게이트(forget gate)는 과거 정보를 어느 정도 기억할지 결정한다.
- 값이 1이면 바로 직전의 정보를 메모리에 유지
- 값이 0이면 초기화
2️⃣ 입력 게이트
입력 게이트는 현재 정보를 기억하기 위해 만들어졌다. 과거 정보와 현재 데이터를 입력받아 시그모이드와 하이퍼볼릭 탄젠트 함수를 기반으로 현재 정보에 대한 보존량을 결정한다.
- 값이 1이면 입력 가 들어올 수 있도록 허용
- 값이 0이면 차단
3️⃣ 셀
각 단계에 대한 은닉 노드를 메모리 셀이라고 한다.
총합(sum)을 사용하여 셀 값을 반영하며, 이를 통해 기울기 소멸 문제를 해결할 수 있다.
4️⃣ 출력 게이트
과거 정보와 현재 데이터를 사용하여 뉴런의 출력을 결정한다.
- 값이 1이면 의미 있는 결과로 최종 출력
- 값이 0이면 해당 연산 출력을 하지 않음
LSTM 역전파
LSTM은 셀을 통해서 역전파를 수행하기 때문에 '중단 없는 기울기'라 불린다. 즉, 최종 오차는 모든 노드에 전파되는데 이때 셀을 통해서 중단 없이 전파된다.
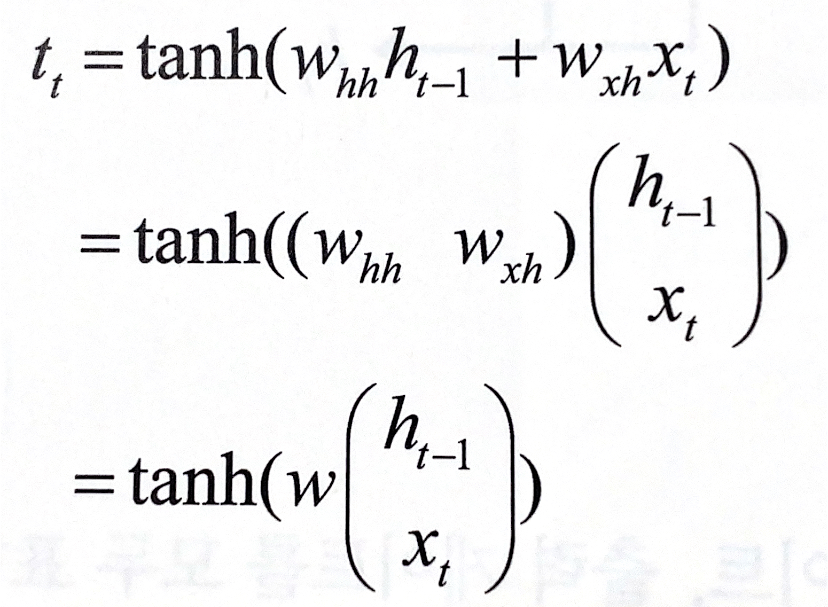
GRU(게이트 순환 신경망)
GRU 구조
GRU는 LSTM에서 사용하는 망각 게이트와 입력 게이트를 하나로 합친 것이며, 별도의 업데이트 게이트로 구성되어 있다.
하나의 게이트 컨트롤러가 망각 게이트와 입력 게이트를 모두 제어한다.
- 게이트 컨드롤러 = 1 : 망각 게이트는 열리고 입력 게이트는 닫힌다.
- 게이트 컨드롤러 = 0 : 망각 게이트는 닫히고 입력 게이트는 열린다.
👉🏻 이전 기억이 저장될 때마다 단계별 입력은 삭제된다.
1️⃣ 망각 게이트
과거 정보를 적당히 초기화시키려는 목적으로 (0,1) 값을 이전 은닉층에 곱한다.
2️⃣ 업데이트 게이트
과거와 현재 정보의 최신화 비율을 결정하는 역할이다.
- 는 현시점의 정보량을 결정하고, 1에서 뺀 값(1-)을 직전 시점의 은닉층의 정보와 곱한다.
3️⃣ 후보군
현시점의 정보에 대한 후보군을 계산한다. 과거 은닉층의 정보를 그대로 이용하지 않고 망각 게이트의 결과를 이용하여 후보군을 계산한다.
4️⃣ 은닉층 계산
업데이트 게이트 결과와 후보군 결과를 결합하여 현시점의 은닉층을 계산한다.
- 시그모이드 함수의 결과는
현시점에서 결과에 대한 정보량을 결정한다.- 1-시그모이드 함수의 결과는
과거의 정보량을 결정한다.

출처
