오늘 정리
데이터 설계는? 설계에 대한 이해, 데이터의 관계에 대한 이해를 바탕으로 설계할 수 있다.
일양의 차이? 실행계획을 통해 쿼리문을 실행하는 일의 양, 필요한 비용을 확인할 수 있다. 전체 범위, 부분 범위 처리의 차이를 알고 설계해야하며, 이를 위해 쿼리문에 대해 학습하고 경험하는 것이 필요하다.
복습
- dept(부모집합)/emp(자식집합) 데이터 실습
- 둘의 관계는 1:n의 관계 (설계에 대한 이해, 데이터의 관계에 대한 이해를 바탕으로 설계)
- 집합에 대한 구조를 자바의 클래스로 설계할 수 있어야 JPA 기술을 누림

- 부서집합의 부서번호가 사원집합으로 가게 된 것은 관계 때문이며, 부서번호를 외래키라고 함.
- 1:n의 관계가 생기는 것을 릴레이션이라고 함.[decode]
- 조건에 따라 데이터를 추출한다
- DECODE(값, 조건1, THEN1, 조건2, THEN2, 조건3, THEN3 …) 형태 & DECODE 중첩사용 가능
- 단점
- 크다, 작다의 비교 X → 비교연산을 수행하기 위해서는 GREATEST, LEAST등의 함수를 사용
--decode sum과 함께 많이 쓰임(소계, 총계 등)
SELECT
sum(decode(JOB,'CLERK',sal,NULL)) AS "CLERK"
,sum(decode(JOB,'SALESMAN',sal,NULL)) AS "SALESMAN"
,sum(decode(JOB,'CLERK',NULL,'SALESMAN',NULL,sal)) AS "ETC"
FROM emp;[rowid & rownum]
- rowid : 데이터베이스 내에서 데이터를 구분할 수 있는 유일한 값(데이터를 입력하면 자동으로 생성되는 값)
- rownum : select문에 대한 논리적 일련번호를 부여한다 → 조회되는 행 수를 제한할 때 많이 사용
[그룹함수]
- 전체범위 처리 → 속도 느림
- max, min, count, avg, sum 등
SELECT max(sal), min(sal), count(sal),sum(sal), avg(sal) FROM emp; -- 5000 800 14 29025 2073.21428571429 - 그룹함수와 일반칼럼 함께 쓸 수 없음.
-
해결방법 1 : 유효하지 않은 값 max를 붙여라 → 추천하지 않는다.
-
해결방법 2 : Group by절 사용(단, 효과가 전혀 없을 수 있다.)
--1번 해결방법. max는 단지 문법적 문제를 피하기 위함 --유효하지 않은 값이기 때문에 사용시 유의 SELECT max(sal), max(ename) FROM emp; --2번 해결방법. SELECT max(sal), ename FROM emp GROUP BY ename;
-
[case]
- DECODE함수가 제공하지 못하는 비교 연산의 단점을 해결할 수 있는 함수
SELECT 등급,count(등급) AS "갯수"
FROM(SELECT
CASE
WHEN salary > 70000000 THEN 'A'
WHEN salary BETWEEN 50000001 AND 70000000 THEN 'B'
WHEN salary BETWEEN 30000001 AND 50000000 THEN 'C'
ELSE 'D'
END AS "등급"
FROM temp
)
GROUP BY 등급
ORDER BY 등급;
SELECT
count(CASE WHEN salary > 70000000 THEN 'A' END) AS "A"
,count(CASE WHEN salary BETWEEN 50000001 AND 70000000 THEN 'B' END) AS "B"
,count(CASE WHEN salary BETWEEN 30000001 AND 50000000 THEN 'C' END) AS "C"
,count(CASE WHEN salary<=30000000 THEN 'D' END) AS "D"
FROM temp;
강의 내용
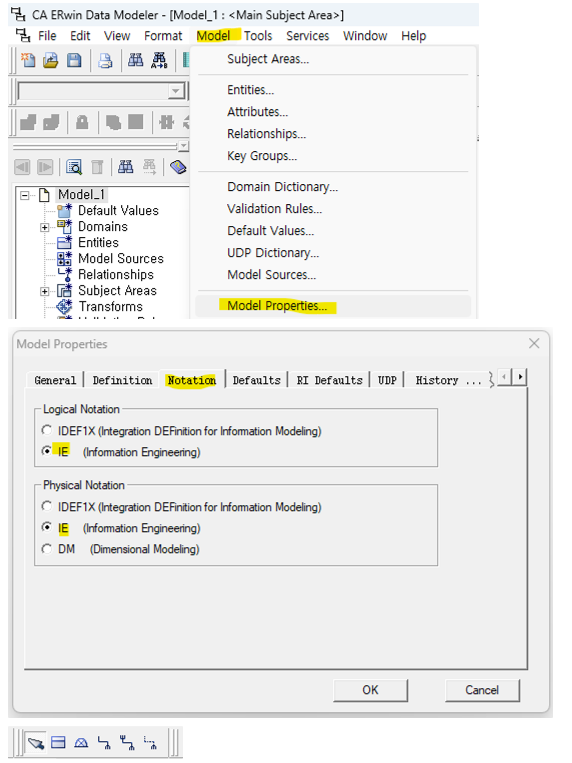
[ERwin Tip]
- IE 표기법으로 변경
- file → new 생성 → model → model properties → notation → IE 체크 → 표기법 변경 완료
[RDBMS]
- 관계성
- 1:1 : 회원과 포인트
- 1:n : 부서와 사원
- n:m : 회원과 상품, 고객과 책, 학생과 교과목
- 자료 추가 방법
- insert문 : INSERT INTO 테이블 (넣는 값)
- edit 테이블명; : 로우를 추가하거나 수정하여 sava하면 자료에 바로 반영
[인덱스 (index)]
- INDEX란? SQL 검색 속도를 높이기 위해 사용하는 기술 중 하나
- 조회 시, 해당 테이블을 Full로 스캔하는 것이 아니라 등록되어있는 인덱스 파일을 검색한다 = 빠르다.
- 인덱스는 누가 만들어주나? 자동으로 제공되며, 만들 때 기본적으로 오름차순 정렬이 됨.
--둘의 실행계획 차이를 확인할 줄 알아야 한다.
SELECT empno FROM emp;
--empno의 경우, PK키이며 인덱스 값을 가진다.
--오름차순으로 정렬되어 조회된다.
SELECT empno, ename FROM emp;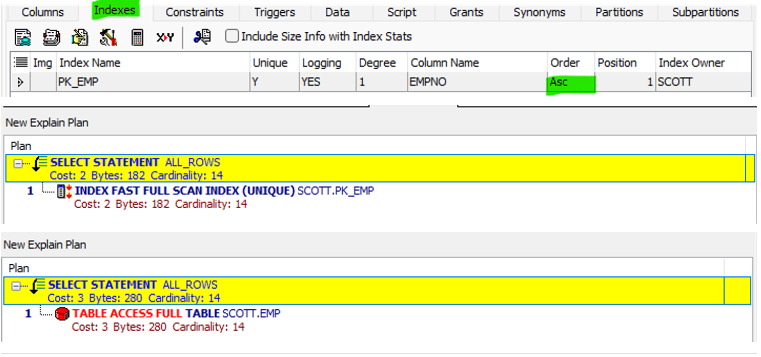
[실행계획]
- SQL 실행하여 데이터 추출 시 옵티마이저가 수립하는 작업 절차 (옵티마이저는? 가장 효율적으로 SQL 처리 경로를 생성하는 엔진)
- 옵티마이저 종류
- 규칙 기반 옵티마이저 (RBO: Rule Based Optimizer )
- 쿼리를 실행하는 방법을 규정하는 정적인 규칙에 따라 쿼리를 최적화
- 효율 기반 옵티마이저 (CBO: Cost Based Optimizer )
- 실제 이용된 데이터에서 얻은 통계를 이용해 쿼리를 최적화
- 규칙 기반 옵티마이저 (RBO: Rule Based Optimizer )
[💡힌트문]
- SQL 튜닝의 핵심 부분으로 힌트문 사용 시, 오라클이 스스로 힌트를 통해 직접 최적의 실행 방법을 지시해준다.
- 힌트절의 형태
- /+ hint /
- /+ hint(argument) /
- 종류 : 옵티마이저 목표/접근 경로/쿼리 변환/조인 순서/조인 방법에 따른 힌트
- 주 사용 힌트
-- /*+ ORDERED */: From절 나열된 테이블 순서대로 접근
-- /*+ LEADING */ : 원하는 순서로 테이블 접근 경로를 설정
-- /*+ USE_NL(B) */ : 인자값(B)으로 접근할 때 Nested Loop Join을 사용
-- /*+ USE_HASH(B) */ : 인자값(B)으로 접근할 때 Hash Join을 사용
-- /*+ INDEX(B) */ : 테이블의 인덱스 중 어떤 인덱스를 사용할지 지정
-- /*+ FULL(테이블명) PARALLEL(테이블명 병렬숫자) */ : Full은 테이블 전체를 풀스캔, Parallel은 병렬처리를 위한 힌트절--rule base 비용에 따른 실행계획 설정(Nested Loop사용)-> 8밀리초
SELECT /*+ rule */ *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
--구문입력한대로 Hash Join 사용 -> 13밀리초
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno; [Join]
- Hash Join : 두 테이블을 각각 통째로 읽어옴 → 줄을 세움 → 조건을 비교해가며 출력
--조건을 넣어 해당하는 값만 조회 가능
SELECT empno, ename, dept.dname
FROM emp, dept
WHERE emp.deptno = dept.deptno;
Plan
SELECT STATEMENT ALL_ROWSCost: 7 Bytes: 770 Cardinality: 14
3 HASH JOIN Cost: 7 Bytes: 770 Cardinality: 14
1 TABLE ACCESS FULL TABLE SCOTT.DEPT Cost: 3 Bytes: 88 Cardinality: 4
2 TABLE ACCESS FULL TABLE SCOTT.EMP Cost: 3 Bytes: 462 Cardinality: 14[퀴즈]
- 판매날짜별 판매개수, 판매가격 출력(총계 줄을 마지막에 출력)
- decode 부분은 총계의 출력을 위한 더미 데이터
--날짜별 판매개수, 판매가격
--맨 아래 로우에 '총계'추가
SELECT decode(A.rno,1,indate_vc,2,'총계') AS "판매날짜"
,to_char(sum(qty_nu)||'개') AS "판매개수"
,to_char(sum(qty_nu*price_nu)||' 원')AS "판매가격"
FROM t_orderbasket,
(
SELECT 1 rno FROM dual
UNION ALL
SELECT 2 FROM dual
)A
GROUP BY decode(A.rno,1,indate_vc,2,'총계')
ORDER BY decode(A.rno,1,indate_vc,2,'총계'); SELECT dept
,decode(rno,1,'1학년',2,'2학년',3,'3학년',4,'4학년') AS "학년"
,decode(rno,1,fre,2,sup,3,jun,4,sen) AS "정원"
FROM test11,
(
SELECT ROWNUM rno FROM dept WHERE ROWNUM <=4
)
ORDER BY dept ASC, decode(rno,1,'1학년',2,'2학년',3,'3학년',4,'4학년') ASC;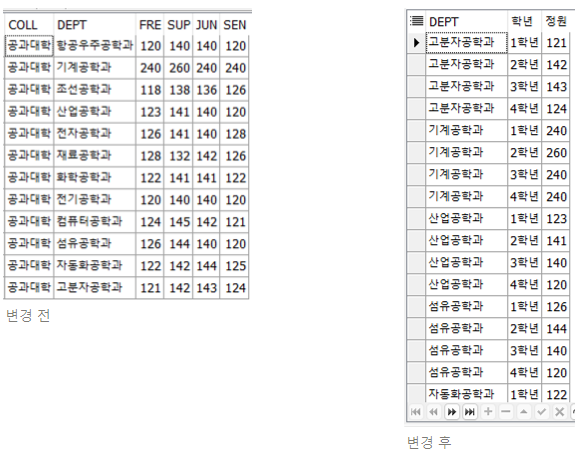
- 더미데이터 활용
SELECT
decode(b.rno,1,dname,2,'총계') AS "dname",sum(clerk) AS "CLERK" , sum(salesman) AS "SALESMAN", sum(etc) AS "ETC"
FROM
(
SELECT dname, clerk, salesman, etc, dept_sal
FROM
(
SELECT
deptno, CLERK, SALESMAN, ETC, DEPT_SAL
FROM
(
SELECT deptno,
sum(DECODE (JOB, 'CLERK', sal)) AS "CLERK",
sum(DECODE (JOB, 'SALESMAN', sal)) AS "SALESMAN",
sum(DECODE (JOB, 'CLERK', NULL, 'SALESMAN', NULL, sal)) AS "ETC",
sum(sal) AS "DEPT_SAL"
FROM emp
GROUP BY deptno
)
)E, dept d
WHERE E.deptno = d.deptno
)A,
(SELECT ROWNUM rno FROM dept WHERE ROWNUM < 3)b
GROUP BY decode(b.rno,1,dname,2,'총계')
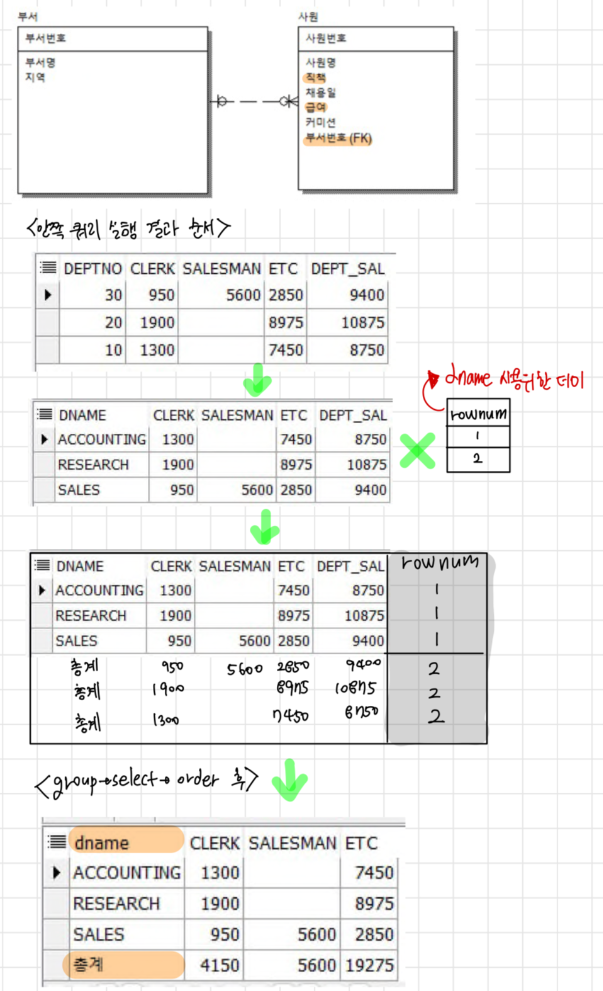
ORDER BY decode(b.rno,1,dname,2,'총계');🤔문제 제기
- 테이블을 한 번만 읽고 처리하는 방법은 없나??
- 조인을 하기 전 그룹바이를 진행하여 일의 양을 줄이기!!
⇒ 인라인뷰를 고민해보자!!
⇒ 더미테이블 사용하기(총계가 출력될 수 있도록)
❓왜 중첩 쿼리 사용?
- 실행을 처리하는 비용, 일의 양을 생각하여 설계
- 안의 쿼리문부터 실행하여 결과를 도출하는 범위를 좁혀서 일의 양을 감소
강의 마무리
- 결과값 도출도 중요하지만 그 과정에서의 cost를 생각하며 설계하는 눈이 필요(많은 쿼리문을 작성해보는 것 추천)
