빅쿼리 스토리지 들여다보기
이 글은 아래 블로그를 번역한 내용으로 모호하게 해석된 부분은 원문을 참고 부탁드립니다.
TL;DR
- BigQuery는 Columnar Storage Format을 사용한다.
- Storage Level Encryption으로 보안성을 확보하고 있다.
- Colossus 분산파일시스템의 replica를 통해 내구성 & 가용성을 확보하고 있다.
- 빅쿼리는 스캔되는 데이터의 양을 줄이거나 쿼리 성능을 개선할 수 있도록 데이터를 다음의 방식으로 저장할 수 있다.
- Partitioned Table
- Clustered Table
- Repeated & Nested Structure
- 비용 절감과 관련해서는 Table Expiration 설정과 90일 이상 미사용 데이터의 Long-term Storage 저장을 고려해라.
컬럼지향 스토리지 형식
빅쿼리는 완전 관리형 스토리지를 제공한다. 이는 직접 서버를 프로비저닝할 필요가 없다는 의미이다. 사용되는 빅쿼리 스토리지의 크기는 자동으로 조절되며 과금은 실제 사용한 만큼에 대해서만 부과된다.
빅쿼리는 이러한 컬럼지향 스토리지에 담긴 데이터를 사용하여 대규모 데이터 분석을 수행하도록 설계되었다.
Postres나 MySQL과 같은 전통적인 관계형 데이터베이스에서는 데이터를 한 행씩 레코드지향 스토리지에 저장한다. 이로 인해 트랜잭션 업데이트 등의 OLTP 유스케이스에서 훌륭하게 동작한다. 발생하는 트랜잭션에 대해서 테이블 업데이트시 하나의 레코드 단위로 읽거나 쓰거나 하기 때문이다.
반대로 어떤 컬럼내의 값들의 총합을 계산하는 것과 같은 집계 수행시에는 전체 테이블의 내용을 메모리에 올려야 하는 부담이 생긴다.
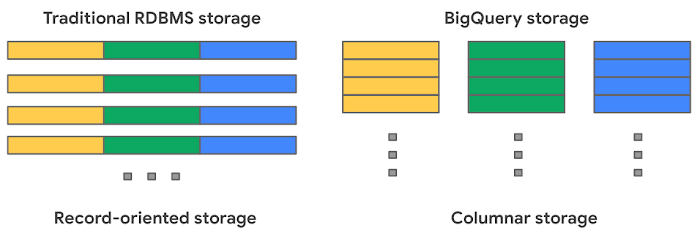
빅쿼리는 컬럼지향 스토리지를 사용하는데 여기서는 각각의 컬럼이 분리된 파일 블럭에 저장된다. 이로 인해 빅쿼리는 OLAP 유스케이스에 이상적으로 작동한다.
집계 연산이 필요한 경우 전체 테이블을 메모리에 올리는 대신 집계에 필요한 컬럼이 저장된 파일 블럭들만 스토리지에서 읽어 내면 된다.
최적화된 스토리지 형식
내부적으로 빅쿼리는 데이터를 Capacitor라는 (특허로 보호된) 컬럼지향 형식으로 저장한다. 각각의 필드 또는 컬럼의 값들이 분리되어 저장되면 파일을 읽어들일 때의 오버헤드는 실제로 읽고 있는 필드의 갯수에 비례하게 된다.
여기서 각 컬럼들이 각자 하나씩의 파일에 저장된다는 의미는 아니다. 각 컬럼이 압축된 후 하나의 파일 블럭에 독립적으로 저장되어 최적의 성능을 내도록 구성되었다 정도로 이해하면 좋겠다.
정말 멋진 것은 Capacitor가 근사(approximation)모델을 구축해서 데이터 타입(아주 긴 문자열 vs. 정수형)이나 사용패턴(예를 들어, 어떤 컬럼은 WHERE 조건절에서 필터의 용도로 자주 사용된다거나)과 같은 연관된 인자들을 고려하여 행(row)을 다시 섞거나(reshuffle) 열(column)을 인코딩(encode)한다는 것이다.
모든 컬럼이 인코딩 되는 동안에 빅쿼리는 데이터에 대한 다양한 통계 데이터를 수집한다. 통계 데이터는 따로 보관되었다가 향후 쿼리가 실행되는 동안 사용되어진다.
암호화와 내구성 관리
이제 데이터가 어떻게 파일들에 저장되는지 이해했으니 이 파일들이 실제 어디에 위치하게 되는지 알아보자. 빅쿼리의 영속 계층 (Persistence Layer)은 구글의 분산 파일 시스템인 Colossus가 제공하고 있다. 이 곳에서 데이터는 자동으로 압축되고 암호화되고 복제되고 분산된다.
구글 클라우드 플랫폼은 인가되지 않은 접근에 대해서 여러 단계의 방어체계를 갖추고 있다. 데이터를 100% 암호화하여 저장하는 것이 그 중 하나이다. 추가로 암호화를 직접 제어하고 싶다면 고객 관리형 암호화 키(CMEKs)를 사용할 수도 있다.
또한 Colossus는 삭제 인코딩(erasure encoding)이라는 것을 통해 내구성을 보장하고 있다. 삭제 인코딩은 데이터를 쪼개서 서로 다른 디스크들에 골고루 여분의 (데이터)조각들이 저장될 수 있도록 한다.
또한 데이터의 내구성과 가용성을 보장하기 위해서 이 데이터들은 데이터셋을 생성한 권역(Region)의 서로 다른 가용존(AZ)에 복제된다.
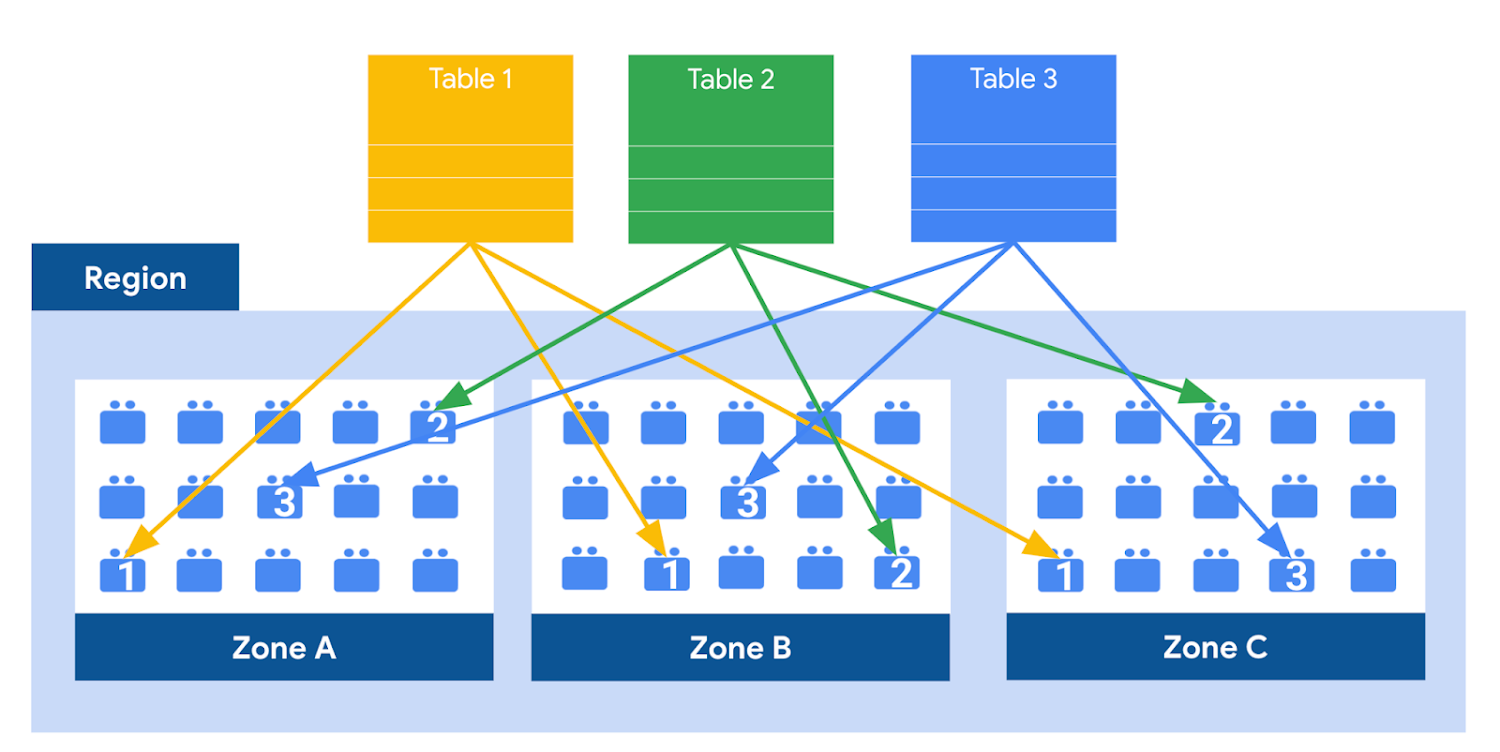
이것은 데이터가 서로 다른 전력 체계와 네트워크를 가진 서로 다른 건물에 보관된다는 의미이다. 복수의 가용존들이 동시에 오프라인이 될 가능성은 극히 낮다.
좀 더 안전하게 멀티리전을 사용하는 경우 빅쿼리는 복사본 하나를 더 권역외 복제본(off-region repica)으로 만든다. 이런 방식으로 데이터는 주요 재해 발생시에도 복구가 가능하게 된다.
이 모든 것들이 쿼리 수행에 필요한 연산 리소스에 영향을 주지 않고 이루어진다. 인코딩, 암호화 그리고 복제에 소요되는 이런 연산 비용은 모두 빅쿼리 스토리지 가격에 포함되어 있다. 몰래 과금되는 일은 없다.
쿼리 성능을 위한 스토리지 최적화
빅쿼리는 스토리지 옵티마이저를 내장하고 있다. 옵티마이저는 파일들을 주기적으로 다시 쓰면서 쿼리에 최적화된 형태가 되도록 데이터를 정리한다.
파일은 처음에는 쓰기에 최적화된 형태로 기록되다가 이후에 빠르게 조회할 수 있는 형태로 바뀐다. 이렇게 뒤에서 조용히 이루어지는 최적화와 별개로 몇가지 방식으로 스토리지를 더 개선할 수 있다.
Partitioning
파티션된 테이블은 파티션(Partition)이라 불리는 구역(segemnt)로 나뉘어진 특별한 형태의 테이블이다. 빅쿼리는 파티셔닝을 통해 Worker(역자주 - BigQuery Job을 수행하는 일종의 가상머신)들이 디스크에서 읽어들이는 데이터의 양을 최소화한다.
파티셔닝 컬럼에 대해 필터를 사용한 쿼리들은 데이터를 스캔하는 양을 극적으로 줄여 향상된 성능과 온-디맨드 쿼리에서의 비용 절감 효과를 낳는다.
(역자주 - 온-디맨드는 스캔한 데이터량에 따른 과금체계, Flat-rate 과금체계는 빅쿼리 슬롯을 구매해서 사용하는 경우이며 고정 비용 발생)
피티션된 테이블에 쓰여진 새로운 데이터는 적잘한 파티션으로 전달된다.
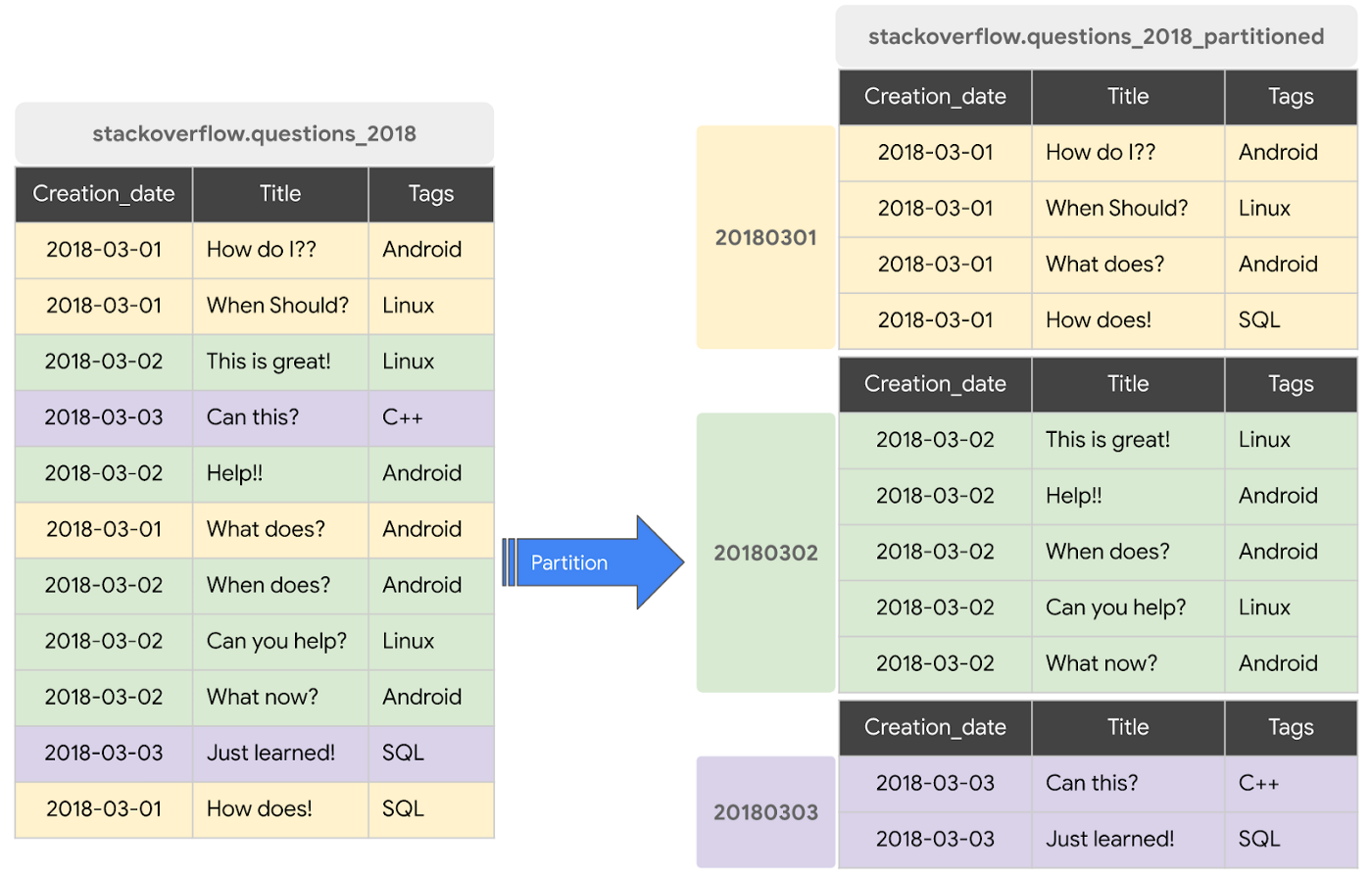
빅쿼리는 아래와 같은 방식의 파티션된 테이블들을 지원한다.
-
수집시간으로 파티션된 테이블: 데이터가 수집된 날짜를 반영한 일별 파티션. 이 옵션은 데이터가 추가된 때를 기준으로 데이터를 필터링할 때 유용하다.
예를 들어, 새로운 구글 트렌드 데이터셋이 날마다 갱신이 되는데 가장 최근의 트렌드에만 관심이 있을 수 있다. -
시간단위(Time-unit) 컬럼으로 파티션된 테이블: 빅쿼리는 파티셔닝 컬럼의 날짜 값에 따라 데이터를 적절한 파티션으로 라우팅 시킨다. 시간(Hour)단위 크기(Granularity)를 가진 파티션도 지정할 수 있다. 이 옵션은 테이블내 날짜 컬럼을 기준으로 데이타를 필터링하고자 할 때 유용하다. 예를 들어, 가장 최근의 트랜잭션을 찾고자 할 때 WHERE 절에 transaction_created_date 라는 파티셔닝 컬럼을 포함시켜 빠르게 조회가 가능하다.
-
정수 범위로 파티션된 테이블: 버켓팅된 정수값으로 파티셔닝. 이 옵션은 테이블의 정수값에 따라 데이터를 필터링할 때 유용하다. 예로써, customer_id 0 ~ 100 까지의 고객 데이터가 같은 파티션에 모이도록 정수값을 버켓팅(bucketing)할 수 있다.
(역자주) 버켓팅 - 정수형 파티션을 만들때는 파티션의 start, end, interval을 명시해야 한다. 이 값들을 통해 (end - start) / interval 개의 버켓이 만들어지는데 정수 컬럼의 값들은 이 범위내에 있어야 한다. 정수값이 범위를 벗어나면 별도 파티션에 모아진다.
파티셔닝은 쿼리 성능을 최적화하기 위한 훌륭한 방법이다. 특히 큰 테이블에서 분석을 위해 자주 데이터를 필터링하며 줄여가는 경우는 더욱 그렇다.
적절한 파티션 키를 결정해야 할 때는 항상 조직에 속한 사람들이 어떻게 테이블을 이용하고 있는지를 고려해야 한다. 비용이 많이 드는 쿼리를 만들어 내는 큰 테이블에 대해서는 파티션을 사용하도록 하는 것이 좋다.
파티션은 대량의 데이터이면서 적은 수의 구별되는(distinct) 값을 가진 곳에 맞게 설계되었다. (역자주 - 파티션키 컬럼의 Cardinality가 높지 않아야 한다는 의미인 듯)
좋은 경험 법칙 중 하나는 파티션을 최소 1GB 보다 크게 하라는 것이다.
테이블을 지나치게 파티셔닝하게 되면 많은 메타데이터를 양산하게 되고 이로 인해 많은 파티션을 읽을 때 사용자 쿼리를 느리게 만든다.
Clustering
빅쿼리에서 테이블이 클러스터링되면 데이터는 자동으로 하나 혹은 그 이상(최대4개)의 컬럼값을 기준으로 정렬된다. 높은 카디널리티(cardinality)와 날짜시간 형식이 아닌 컬럼들이 클러스터링에 적합하다. 낮은 카디널리티에 더 어울리는 파티셔닝과는 대조된다. (역자주 - 카디널리티는 하나의 컬럼이 가지는 유니크한 값의 갯수)
하나만 선택할 수 있는 것은 아니고 하나의 테이블이 동시에 파티셔닝되고 클러스터링될 수 있다.
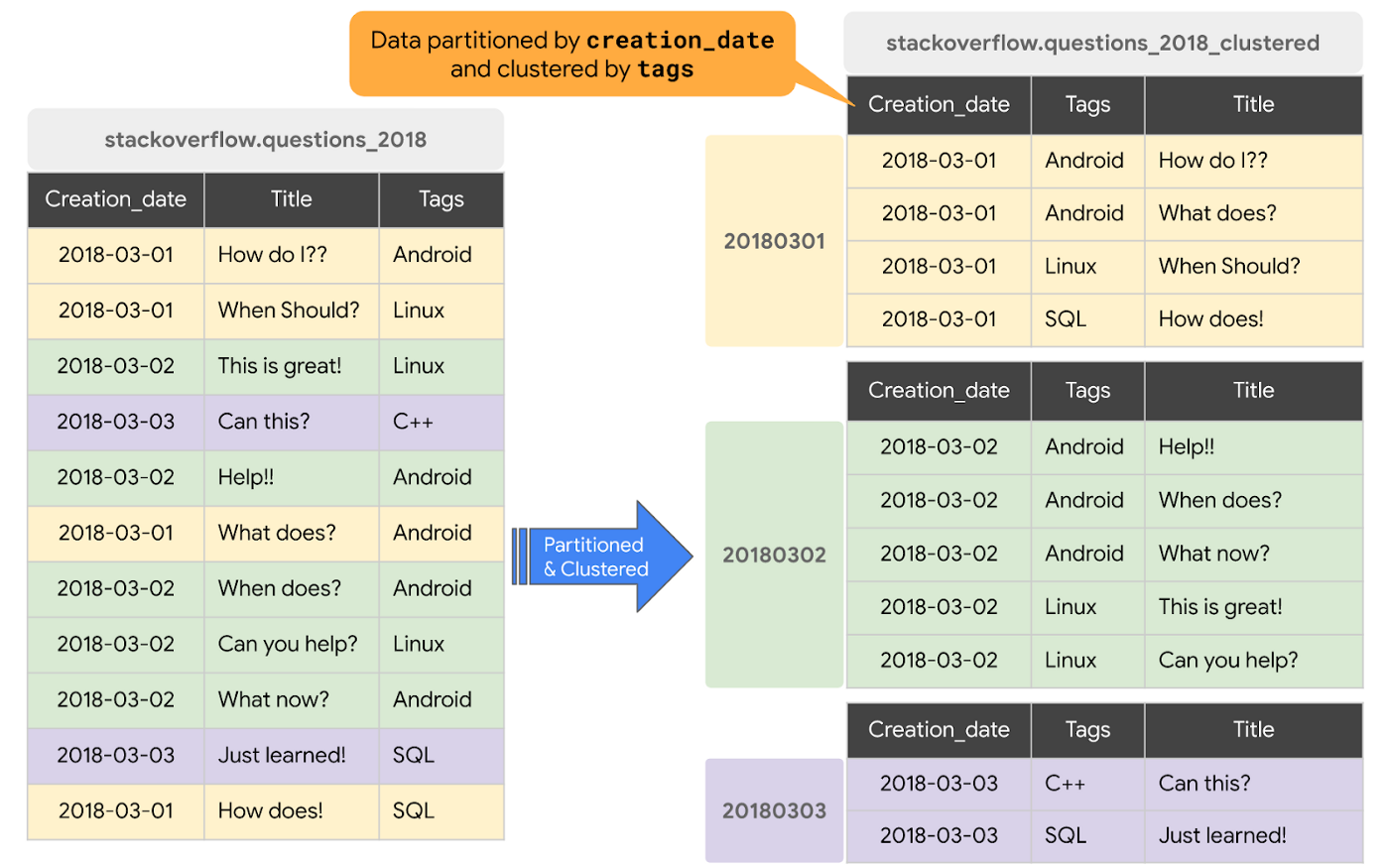
클러스터 컬럼의 순서는 데이터의 정렬 순서를 결정한다. 새로운 데이터가 테이블이나 특정 파티션에 더해지면 빅쿼리는 백그라운드에서 클러스터링을 다시 수행한다. 물론 이 때 드는 연산 비용도 무료이다.
특히 클러스터링은 다음 상황에서 개선된 쿼리 성능을 보여준다:
-
클러스터 컬럼이 WHERE 조건절에 포함될 때: 빅쿼리는 정렬된 블럭을 사용하여 불필요한 데이터의 스캔을 제거한다. WHERE절의 필터 순서가 중요하게 작용하므로 클러스터링을 사용하는 필터를 먼저 사용하도록 한다.
-
클러스터 컬럼의 값들을 기반으로 데이터를 집계하는 경우: 정렬된 블럭들은 유사한 값들을 가진 행들과 같이 위치하기 때문에 개선된 성능을 보인다.
-
JOIN키가 테이블 클러스터링을 위해 사용되는 JOIN연산에서: 적은 데이터만 스캔된다. 어떤 쿼리에서는 클러스터링이 파티셔닝 대비 큰 성능 개선을 보여준다.
Denormalizing
전통적인 데이터베이스의 백그라운드를 가진 분이라면 정규화된 스키마를 만들어내는데 익숙할 것이다. 여기서는 구조를 최적화하여 데이터가 반복되지 않도록 한다. 데이터를 자주 업데이트 해야 하는 OLTP 워크로드를 위해서는 정규화가 중요하다.
만약 고객이 구매를 할 때마다 고객 주소가 여기저기 저장된다면 주소가 바뀌었을 때 모든 주소를 업데이트 하는 일은 번거로울 수 있다.
그러나 정규화된 스키마상에서 분석작업을 수행할 때는 종종 많은 테이블들이 조인되어야 한다. 대신에 데이터를 역정규화한다면, 그래서 고객 주소같은 정보가 동일테이블에 반복적으로 저장되어 있으면 쿼리에서 JOIN연산을 제거할 수 있다.
빅쿼리에서는 Nested and Repeated 구조가 지원된다. 레코드를 STRUCTs와 ARRAYs를 사용하면 데이터에 내재된 구조를 자연스럽게 표현할 수 있을 뿐만 아니라, 어떤 경우에는 GROUP BY 없이 COUNT가 아닌 ARRAY_LENGTH로 집계 결과를 얻어낼 수 있다.
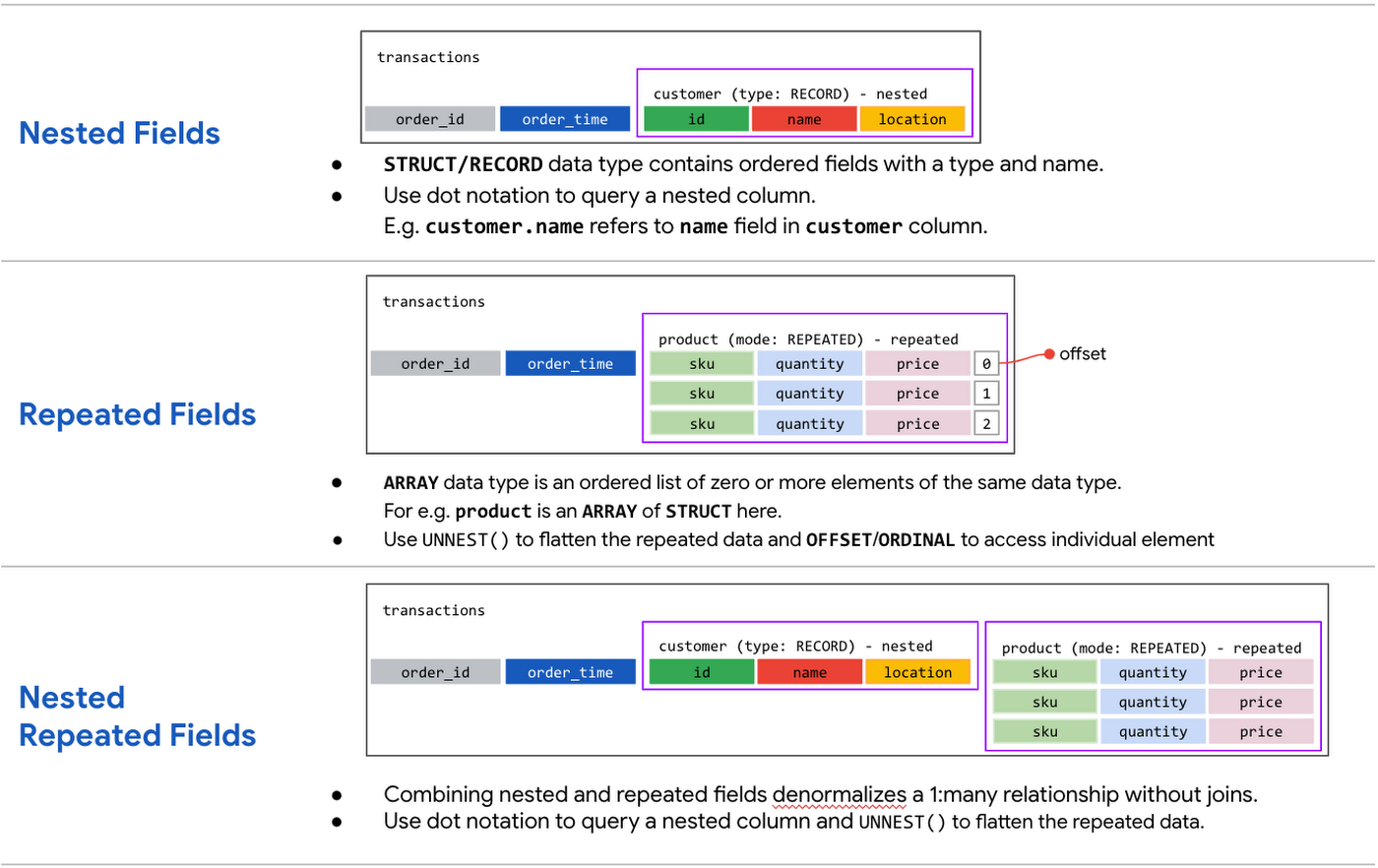
명심할 것은 역정규화가 단점도 가진다는 것이다.
첫째로, 스토리지에 최적화되어 있지 않다. 많은 경우 낮은 빅쿼리 저장비용이 이러한 우려를 불식시키곤 한다.
두번째로, 데이터의 정합성을 유지하기 위한 테스트와 검증에 많은 머신 타임과 때로는 사람의 노력을 필요로 한다는 점이다.
파티셔닝과 클러스터링에 역정규화보다 높은 우선순위를 두고, 다음으로 업데이트를 거의 필요로 하지 않는 데이터에 집중하기를 권장한다.
저장 비용 최적화
저장 비용 최적화와 관련해서는 불필요한 테이블과 파티션을 삭제하는 일에 집중하도록 한다. 테이블 또는 파티션의 기본 파기 시간을 설정할 수 있다. 이는 구체화된 뷰 혹은 애드혹 워크플로우를 위한 테이블에 유용하며 가장 최근 데이터만을 접근하는 경우에도 효과적이다.
추가적으로 빅쿼리의 장기 스토리지을 이용할 수 있다. 90일 연속으로 사용되지 않은 테이블들이 있다고 하면 스토리지 저장 비용은 50%까지 자동으로 절감된다. 이는 Cloud Storage Nearline과 동일한 가격이다. 따라서 장시간 사용되지 않는 데이터를 Cloud Storage로 내보기보다는 빅쿼리에 그대로 두는 것이 현명할 수 있다.
