도움 받은 글
깃북 : 나만의 웹 크롤러 만들기
해당 깃북을 가이드 삼아,
프로젝트에 맞춰 조금씩 바꿔서 사용했다.
들어가며
👉 데이터를 크롤링하기 위해
requests와bs4사용
⬜ 여러 페이지를 왔다갔다하는 작업을 자동화하기 위해selenium사용
⬜ 저장 된 데이터를django DB에 저장
+) 잘 마무리 될 시,postgreSQL에 저장하는 방법도 고안해보기
의존성 관리 도구로 poetry를 사용하였으며,
drf 프로젝트에 적용하였다.
1. bs4를 사용한 웹 사이트 크롤링 테스트 (feat. requests)
poetry 가상환경을 생성하고 들어가는 방법은 예전 블로그 글로 대체한다.
🔎 필요 library 설치
poetry add requests
poetry add bs4🔎 프린트 테스트 용 코드 작성
bs4가 현재 페이지의 문구를 잘 가져오는지 print문으로 테스트하는 코드를 작성해보자.
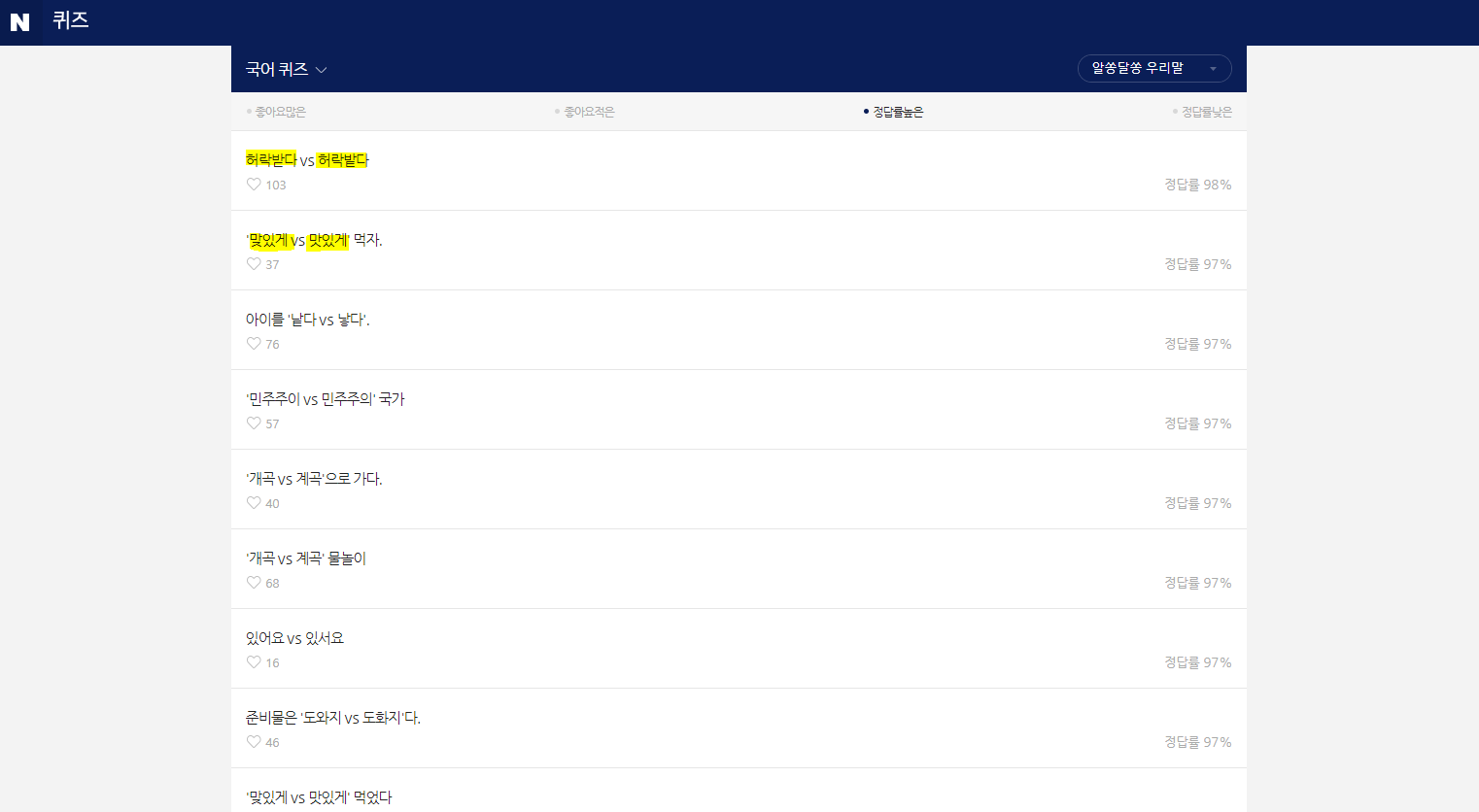
해당 페이지에서 각 단어만 뽑아와서 list로 프린트 하는 코드를 작성해봤다.
파일의 위치는 manage.py가 위치한 곳과 같은 위치!
# crawler.py
import requests
from bs4 import BeautifulSoup
import re
# HTTP 링크 가져오기
req = requests.get("https://wquiz.dict.naver.com/list.dict?service=krdic&dictType=koko&sort_type=3&group_id=1")
# html 지정
html = req.text
# 정규 표현식을 이용해 ''안의 값을 가져오는 식 작성
# 준비물은 '도와지 vs 도화지'다. < 라는 텍스트에서 도와지 vs 도화지 를 추출함
pattern = r"'([^']+)'"
# html.parser로 html을 파싱하겠다고 지정
soup = BeautifulSoup(html, "html.parser")
# 위치 지정
select_words = soup.select('#content > ul.quiz_list > li > a > p')
# for 문을 돌면서 텍스트의 알맹이를 추출
for word in select_words:
if "'" in word.text:
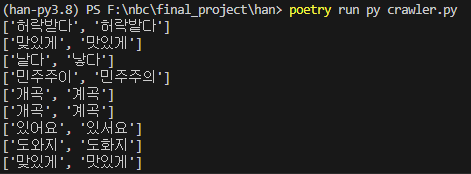
print((re.findall(pattern, word.text))[0].split(" vs "))
else:
print(word.text.split(" vs "))해당 과정을 거치면 아래와 같이 결과값이 나온다.
🔎 받아온 데이터를 json 데이터 값으로 저장해보기
print 문으로 무사히 값이 저장되는 것을 확인했으니,
json 데이터 형식으로 한번 저장해보자!!
import json
import os맨 윗줄에 이 두개를 추가해주자.
# 현재 파일의 부모 디렉토리 찾기
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
...
data = {}
i = 0
# for 문을 돌면서 텍스트의 알맹이를 추출
for word in select_words:
if "'" in word.text:
data[i] = (re.findall(pattern, word.text))[0].split(" vs ")
else:
data[i] = word.text.split(" vs ")
i += 1
with open(os.path.join(BASE_DIR, 'result.json'), 'w+', encoding='utf-8') as json_file:
json.dump(data, json_file, ensure_ascii=False)2. bs4를 사용해서 원하는 테스트 코드 작성(feat. requests)
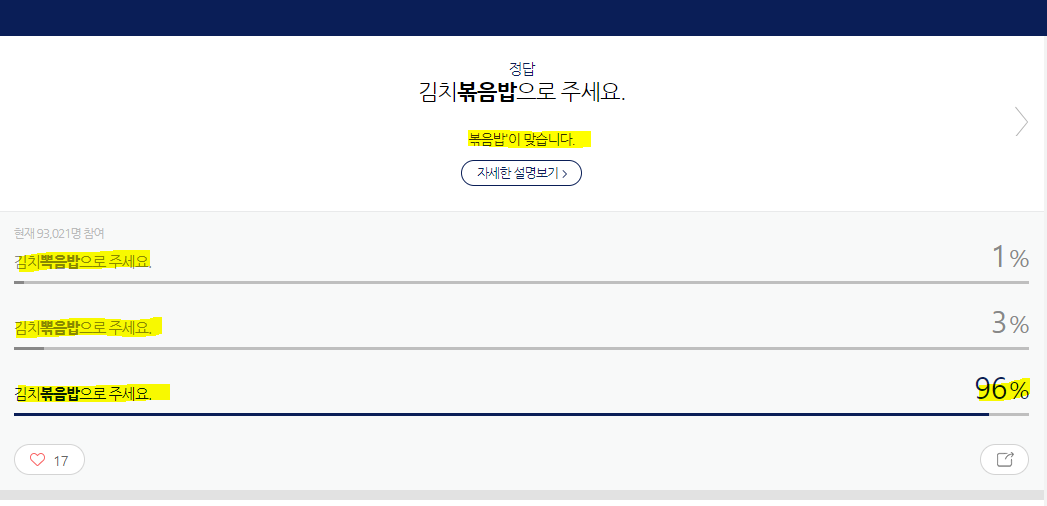
정답과 정답률, 오답과 문제 설명까지 크롤링해오는 코드로 고쳐보자!
import requests
from bs4 import BeautifulSoup
import json
import os
# 현재 파일의 부모 디렉토리 찾기
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
# HTTP 링크 가져오기
req = requests.get(
"https://wquiz.dict.naver.com/result.dict?service=krdic&dictType=koko&quizId=76df29342b404ba59a3aa8cc8f68517e&answerId=6d41c71fcc2941189a8645d47fac483b&group_id=1&seq=0"
)
# html 지정
html = req.text
# html.parser로 html을 파싱하겠다고 지정
soup = BeautifulSoup(html, "html.parser")
# 위치 지정
explain = soup.select_one("#quiz_answer > div.answer_area > div > p")
correct_option = soup.select_one(
"#quiz_answer > div.choice_result_area > ul > li.crct > span"
)
wrong_options = soup.select(
"#quiz_answer > div.choice_result_area > ul > li.wrong > span"
)
data = {
"explain": explain.text,
"option": [
{"content": correct_option.text, "is_answer": 1},
],
}
for wrong in wrong_options:
data["option"].append({"content": wrong.text, "is_answer": 0})
with open(os.path.join(BASE_DIR, "result.json"), "w+", encoding="utf-8") as json_file:
json.dump(data, json_file, ensure_ascii=False)
result.json에 담아주는 방식은 동일하다.
기존 코드와 다른 점은 soup로 데이터를 어떻게 긁어올지,
그리고 data에 값을 어떻게 담아주어야 하는지 정도이다!

저장하면 답이 이렇게 들어온다.

개발 공부 하는 비전공자 새내기. 꾸준히 합시다!