문제
NxN 크기의 시험관이 있다. 시험관은 1x1 크기의 칸으로 나누어지며, 특정한 위치에는 바이러스가 존재할 수 있다. 모든 바이러스는 1번부터 K번까지의 바이러스 종류 중 하나에 속한다.
시험관에 존재하는 모든 바이러스는 1초마다 상, 하, 좌, 우의 방향으로 증식해 나간다. 단, 매 초마다 번호가 낮은 종류의 바이러스부터 먼저 증식한다. 또한 증식 과정에서 특정한 칸에 이미 어떠한 바이러스가 존재한다면, 그 곳에는 다른 바이러스가 들어갈 수 없다.
시험관의 크기와 바이러스의 위치 정보가 주어졌을 때, S초가 지난 후에 (X,Y)에 존재하는 바이러스의 종류를 출력하는 프로그램을 작성하시오. 만약 S초가 지난 후에 해당 위치에 바이러스가 존재하지 않는다면, 0을 출력한다. 이 때 X와 Y는 각각 행과 열의 위치를 의미하며, 시험관의 가장 왼쪽 위에 해당하는 곳은 (1,1)에 해당한다.
예를 들어 다음과 같이 3x3 크기의 시험관이 있다고 하자. 서로 다른 1번, 2번, 3번 바이러스가 각각 (1,1), (1,3), (3,1)에 위치해 있다. 이 때 2초가 지난 뒤에 (3,2)에 존재하는 바이러스의 종류를 계산해보자.
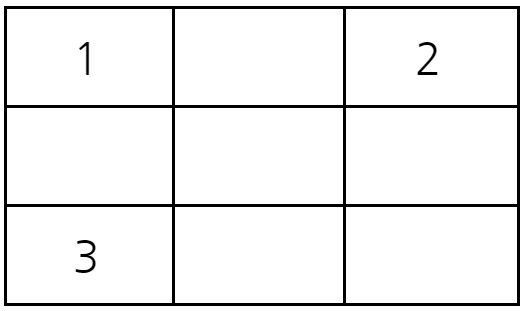
1초가 지난 후에 시험관의 상태는 다음과 같다.
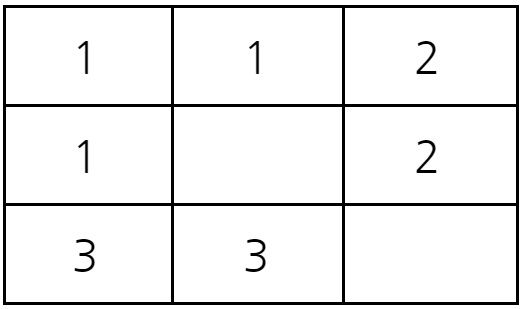
2초가 지난 후에 시험관의 상태는 다음과 같다.
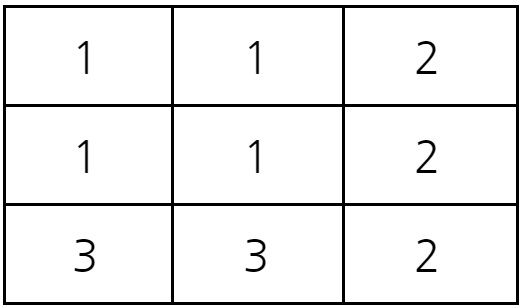
결과적으로 2초가 지난 뒤에 (3,2)에 존재하는 바이러스의 종류는 3번 바이러스다. 따라서 3을 출력하면 정답이다.
입력
첫째 줄에 자연수 N, K가 공백을 기준으로 구분되어 주어진다. (1 ≤ N ≤ 200, 1 ≤ K ≤ 1,000) 둘째 줄부터 N개의 줄에 걸쳐서 시험관의 정보가 주어진다. 각 행은 N개의 원소로 구성되며, 해당 위치에 존재하는 바이러스의 번호가 공백을 기준으로 구분되어 주어진다. 단, 해당 위치에 바이러스가 존재하지 않는 경우 0이 주어진다. 또한 모든 바이러스의 번호는 K이하의 자연수로만 주어진다. N+2번째 줄에는 S, X, Y가 공백을 기준으로 구분되어 주어진다. (0 ≤ S ≤ 10,000, 1 ≤ X, Y ≤ N)
출력
S초 뒤에 (X,Y)에 존재하는 바이러스의 종류를 출력한다. 만약 S초 뒤에 해당 위치에 바이러스가 존재하지 않는다면, 0을 출력한다.
예제 입력 1
3 3
1 0 2
0 0 0
3 0 0
2 3 2예제 출력 1
3예제 입력 2
3 3
1 0 2
0 0 0
3 0 0
1 2 2예제 출력 2
0✅ 통과 코드
from sys import stdin as f
from collections import deque
# f = open("input.txt", "rt") # 주석 처리해야 하는 부분
n, k = list(map(int, f.readline().split()))
examiner = []
for i in range(n):
examiner.append(list(map(int, f.readline().split())))
target_s, target_x, target_y = list(map(int, f.readline().split()))
# 입력 받아오기 끝! examiner를 순회하며 0보다 큰 원소일 경우 바이러스의 종류, 전염 전이므로 0초, 행, 열 인덱스를 append
q = []
for i in range(n):
for j in range(n):
if examiner[i][j]:
q.append((examiner[i][j], 0, i, j))
# 바이러스 종류 기준으로 sort
q.sort()
# popleft 사용을 위해 deque에 담자.
q = deque(q)
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
# 바이러스 한 번 당 상하좌우만 탐색하므로 bfs로 접근.
while q:
# 첫번째 원소 뜯어오자.
virus, second, x, y = q.popleft()
# target_s초가 되었다는 것은 target_s번 순회를 마쳤음을 의미.
if second == target_s:
break
# 상하좌우 탐색
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
# out of range 처리
if nx < 0 or ny < 0 or nx >= n or ny >= n:
continue
# 이미 숫자가 있는 경우 처리
if examiner[nx][ny]:
continue
# 빈 공간일 경우 전염시킴
examiner[nx][ny] = virus
# q에 새로운 원소를 append할 때 1초를 더해서 인자로 보낸다. 0초부터 시작했기 때문에 여기서 second는 1초가 지났음을 의미.
q.append((virus, second + 1, nx, ny))
print(examiner[target_x - 1][target_y - 1])와.. 드디어 해결..
이코테를 슬쩍슬쩍 보면서 풀었는데도 자잘자잘하게 계속 테스트 통과를 못하는 원인들이 숨어있었다.
그동안 내 코드에 어떤 오류가 있었는지 하나씩 파악을 해보았다.
🚨 실패 코드 모음
💩 처음 시도했던 코드 (시간복잡도 out of 안중. 당연하게도 시간 초과)
from sys import stdin as s
# s = open("input.txt", "rt") # 주석 처리해야 하는 부분
n, k = list(map(int, s.readline().split()))
examiner = []
for i in range(n):
examiner.append(list(map(int, s.readline().split())))
s, x, y = list(map(int, s.readline().split()))
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
def one_second():
global examiner
# 💩 4중 for문 실화??
for i in range(1, k + 1):
if i == 1:
temp = [row[:] for row in examiner]
for x in range(n):
for y in range(n):
if examiner[x][y] == i:
for j in range(4):
nx = x + dx[j]
ny = y + dy[j]
if nx < 0 or ny < 0 or nx >= n or ny >= n:
continue
if examiner[nx][ny] or temp[nx][ny]:
continue
temp[nx][ny] = examiner[x][y]
examiner = temp
return examiner
for i in range(s):
one_second()
print(examiner[x - 1][y - 1])그동안 코드 작성하면서 시간복잡도에 대한 고려가 너무 부족했다는 사실을 뼈저리게 느꼈던 실패 코드였다.
일단 테스트 케이스에 있는 숫자들은 작기 때문에 답은 잘 나온다.
그런데 이 코드의 시간 복잡도를 계산해보면
one_second 함수 s번 호출.
함수 호출 시마다 매번 바이러스 종류(k)만큼 for문으로 탐색
2중 for문으로 원소 일일히 또 확인
원소 하나하나 for문 돌면서 상하좌우 탐색
O(S * K * N^2)가 된다.
1 ≤ N ≤ 200
1 ≤ K ≤ 1,000
0 ≤ S ≤ 10,000
1 ≤ X, Y ≤ N
음 ㅎㅎㅎㅎㅎ 최악의 경우 10000 * 1000 * 40000 * 4 = 1,600,000,000,000
응? 0이 몇개야? 1조 6000억?
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
코드를 짜기 전에 저 숫자를 먼저 확인했어야 하는 것이었다.
코드를 다 짜고 계산하는 게 아니라 ㅠㅠ
그동안 시간 초과로 애먹은 적이 많았는데 이제는 코드 짜기 전에 내가 짤 코드가 입력 범위 이내에서 시간복잡도가 어느 정도 될지를 사전에 고려하는 훈련이 함께 필요할 것이다.
그래서 효율적인 코드를 고민고민하다가 우선순위 큐를 사용하는 풀이 방식을 떠올려보았다.
💩 BFS로 위장했는데 자세히 보면 아님
from sys import stdin as f
import heapq
# f = open("input.txt", "rt") # 주석 처리해야 하는 부분
n, k = list(map(int, f.readline().split()))
examiner = []
for i in range(n):
examiner.append(list(map(int, f.readline().split())))
s, x, y = list(map(int, f.readline().split()))
pq = []
dr = [-1, 1, 0, 0]
dc = [0, 0, -1, 1]
# 💩 BFS로 코드 짜기로 했으면서 queue를 안 쓰고 매 초를 반복문으로 돌리고 있다.
for i in range(s):
for j in range(n):
for k in range(n):
if examiner[j][k]:
heapq.heappush(pq, (examiner[j][k], j, k))
while pq:
num, r, c = pq.pop(0)
for j in range(4):
nr = r + dr[j]
nc = c + dc[j]
if nr < 0 or nc < 0 or nr >= n or nc >= n:
continue
if examiner[nr][nc]:
continue
examiner[nr][nc] = num
# 💩 queue에 새로운 원소 append 안합니까 휴먼?
print(examiner[x - 1][y - 1])BFS로 풀어야지!
했는데 자세히 보면 BFS가 아닌 코드이다.
pq에서 우선순위가 높은 원소(min heap이므로 숫자가 작은 바이러스)를 하나 뜯어와서 상하좌우를 탐색하고 바이러스를 퍼뜨린다음 queue에 새로운 원소를 append해야 하는데 그 과정이 없다.
저 코드 짤 때에는 1초를 나타내는 반복문을 구현하자는 생각에 갇혀 있었던 것 같다. 그러다가 아예 BFS가 아닌 코드가 나와버렸다.
심지어 pq는 deque 라이브러리를 쓴 것도 아니어서 pq.pop(0)을 하면 자바스크립트의 shift()처럼 시간복잡도가 O(N)이 추가된다.
이 코드는 나름 시간복잡도를 개선해보려고 한 노력만큼은 가상한 코드이다. 여전히 심하게 비효율적이지만..
반복문을 s번 반복
매 초마다 2중 for문으로 모든 원소를 탐색하므로 N^2
heapq 라이브러리로 정렬하므로 logN 추가 소요
pq라이브러리에서 하나씩 pop(0) 해옴
원소 하나하나 for문 돌면서 상하좌우 탐색
O(S * N^2 * (log N))이 된다.
음 다시 계산해보자.
1 ≤ N ≤ 200
1 ≤ K ≤ 1,000
0 ≤ S ≤ 10,000
1 ≤ X, Y ≤ N
최악의 경우 10000 * 40000 * log200 = 2400000000 * 6 = 14,400,000,000
나름 1,600,000,000,000보다는 많이 개선되었다. ㅋㅋㅋㅋㅋㅋㅋ (아니 조 단위가 나오는 건 너무 심한 거 아니냐구)
하지만 여전히 유사 BFS(?) 코드이므로 시간복잡도의 크나큰 개선이 필요해보인다.
💩 우선순위 큐를 deque에 담고 popleft() 사용 시 FIFO 돼버린다는 것을 몰랐음
from sys import stdin as f
from collections import deque
import heapq
# f = open("input.txt", "rt") # 주석 처리해야 하는 부분
n, k = list(map(int, f.readline().split()))
examiner = []
for i in range(n):
examiner.append(list(map(int, f.readline().split())))
target_s, target_x, target_y = list(map(int, f.readline().split()))
pq = []
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
for i in range(n):
for j in range(n):
if examiner[i][j]:
# heapq에 넣어서 우선순위가 높은 바이러스부터 꺼내자는 시도
heapq.heappush(pq, (examiner[i][j], 0, i, j))
# 💩 그걸 deque에 담아 놓고
q = deque(pq)
while q:
# 막상 popleft()를 쓰면 우선순위는 무시하고 FIFO로 가장 먼저 들어간 원소부터 나온다.
virus, second, x, y = q.popleft()
if second == target_s:
break
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if nx < 0 or ny < 0 or nx >= n or ny >= n:
continue
if examiner[nx][ny]:
continue
examiner[nx][ny] = virus
q.append((virus, second + 1, nx, ny))
print(examiner[target_x - 1][target_y - 1])이건 내가 우선순위 큐를 deque에 담고 popleft()를 하면 우선순위가 높은 원소부터 나올 것이라고 잘못 생각해서 틀린 코드이다. heapq에 원소들을 담고 나서 우선순위가 높은 원소부터 나오게 하려면 heappop()을 사용해야 한다. 최소힙이 우선순위가 가장 높은 원소부터 나오는 자료구조니까! 내 맘대로 deque에 옮겼다가 popleft()를 쓰면 바로 최소힙의 의미가 사라지게 되는 것이다.
그런데 여기서 while문 내부에서는 heappop()을 사용할 수 없다. while문에서는 FIFO를 유지해야 하기 때문이다.
아랫 부분에서 상하좌우를 탐색하면서 새롭게 전염된 원소들을 q에 넣고 while문 초반 코드로 돌아가서 첫번째 원소를 빼올 때 FIFO대로 빼와야 하는 것이다.
그래서 우여곡절 끝에 결국 통과!! 하.. 정말 오래 걸린 문제였다 ㅎㅎㅎㅎ
실패 이유를 요약해보자면
- 시간 복잡도 고려 안하거나 못함
- BFS로 풀기로 했으면서 인접노드를 q에 append안하고 반복문 돌림
- heapq에 원소들을 넣고 deque()에 인자로 전달하면 popleft()할 때 우선순위가 높은 원소가 나올 것이라고 착각함. (그냥 FIFO임.)
이 문제는 나중에 또 풀어볼 가치가 있는 문제!!이다.
이코테에 괜히 있는 문제가 아녀 ㅎㅎ
이제 나름 시간복잡도를 고려하면서 문제 푸는 습관이 조금씩 들기 시작하는 것 같다! 앞으로도 그 습관 유지하도록!!
오늘 점심 뭐먹지.. 짜이찌앤~~~
