
우리는 데이터가 읽고 불러오기 쉽게 잘 정리되어 있기를 원한다.
이를 위해 컴퓨터 과학자들은 자료 구조라는 것을 사용한다.
배열
배열이 메모리에 저장되는 방법은 매우 간단하다.
컴파일러가 우리의 배열을 메모리 주소 1000에 저장했다고 가정하자.

j[5]를 찾고 싶다면 프로그램은 메모리주소 1000으로 가서 5를 더한 위치에서 값 4를 얻는다.
배열은 매우 다양하게 사용되는 데이터 구조이므로 유용한 것들을 다루는 많은 함수가 있다.
ex) 정렬 기능
문자열
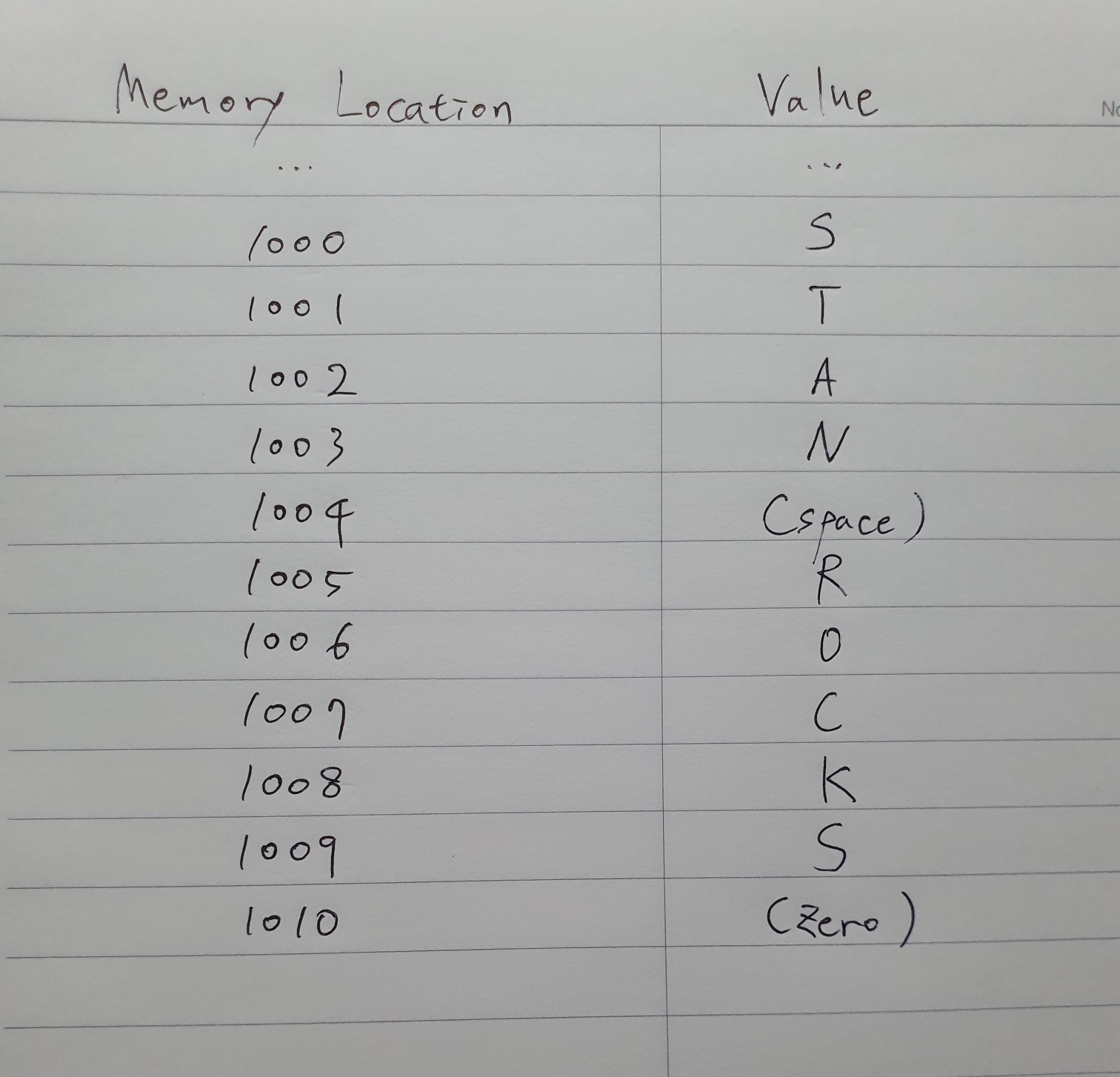
메모리에 배열을 저장할 때에는 쌍따옴표 안에 넣는다.
ex) j = "stanrocks"
문자열은 사실 배열이다.
메모리 상에서 배열은 (zero)로 끝난다.
문자 0이 아니라 이진법 값 0이다.
(컴파일러가 자동으로 문자열뒤에 null 붙여줌.)
null문자라고 하며 문자열의 끝을 나타낸다.
참고: https://easy7.tistory.com/83
null문자는 왜 필요한가?
만약 print quote와 같은 함수로 이 문자열을 출력하려고 한다면
시작 메모리 주소부터 순서대로 출력을 하겠지만
언제 출력을 멈춰야 할지 알아야 한다.
그렇지 않으면 메모리 안의 모든 문자를 출력할 것,,
마찬가지로 문자열만 다루는 함수도 굉장히 많다.
ex) string concatenation(문자열 이어붙이기)
매트릭스(배열의 배열)
스프레드시트의 표나 화면의 픽셀처럼 2차원적으로 확장된 자료를 다루고 싶을 때 사용한다.
ex) j = [[10,15,12],[8,7,42][18,12,7]]

특정 값에 접근하려면 인덱스 2개를 알려줘야 한다.
ex) a = j[2][1]
Struct(구조체)
연관성 있는 자료를 연결해서 저장하고 싶을 때 사용.
ex) 은행 계좌번호와 잔고를 같이 저장.
Struct account
Variable accountNumber
Variable balance
End Struct변수의 그룹은 Struct(구조체)로 묶을 수 있다.
이제 단일 숫자가 아닌 여러 데이터를 한 번에 저장 가능한 복합 데이터로 된 변수를 만들 수 있다.
Struct 또한 배열로 만들어 묶을 수 있다.
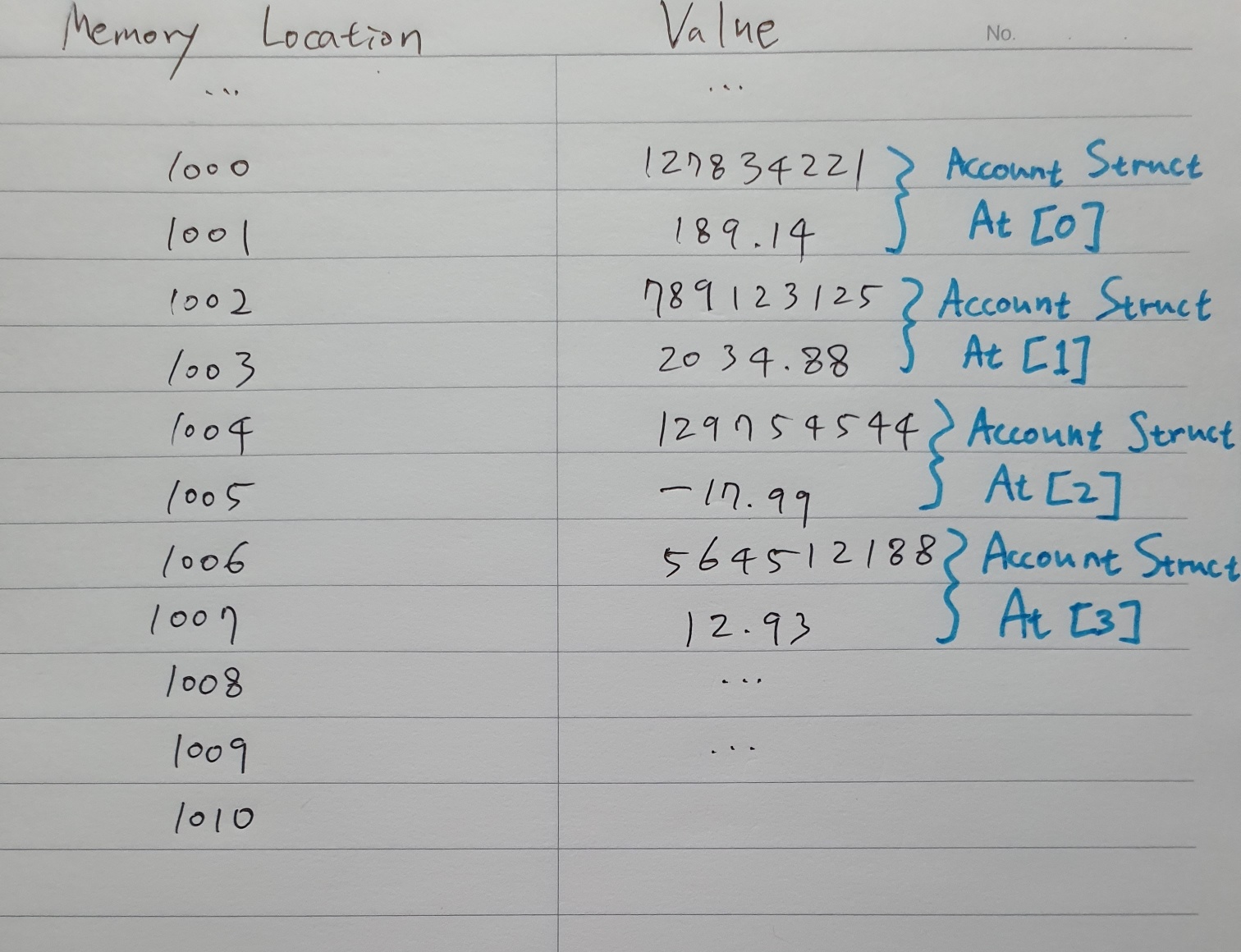
j[0]을 찾고 싶다면?
전체 구조체가 저장된 곳에서 우리가 원하는 계좌번호랑 잔고 두 정보를 다 찾아낼 수 있다.
구조체가 담긴 배열은 여느 배열처럼 확장이 자유롭지는 못하다.
게다가 배열은 메모리에 순서대로 저장되기 때문에 중간에 새로운 값을 넣기 어렵다.
하지만 Struct 데이터 구조를 사용해서 보다 복잡한 데이터 구조를 만드는 데에 사용할 수 있다.
이제 node라는 이름의 구조체를 살펴보자.
node
이는 포인터임과 동시에 숫자와 같은 변수를 저장한다.
Struct node
Variable i
Pointer next
End Struct포인터란? 메모리의 주소를 가리키는 특별한 변수이다.
노드를 여러개 저장할 수 있는 유연한 구조체인 연결리스트(linked list)를 만들 수 있다.
각 노드가 목록의 다음 노드를 가리키도록함으로써 실행될 수 있다.
노드 구조체가 메모리 주소 1000, 1002, 1008 이렇게 3군데에 저장되어 있다고 가정해보자.
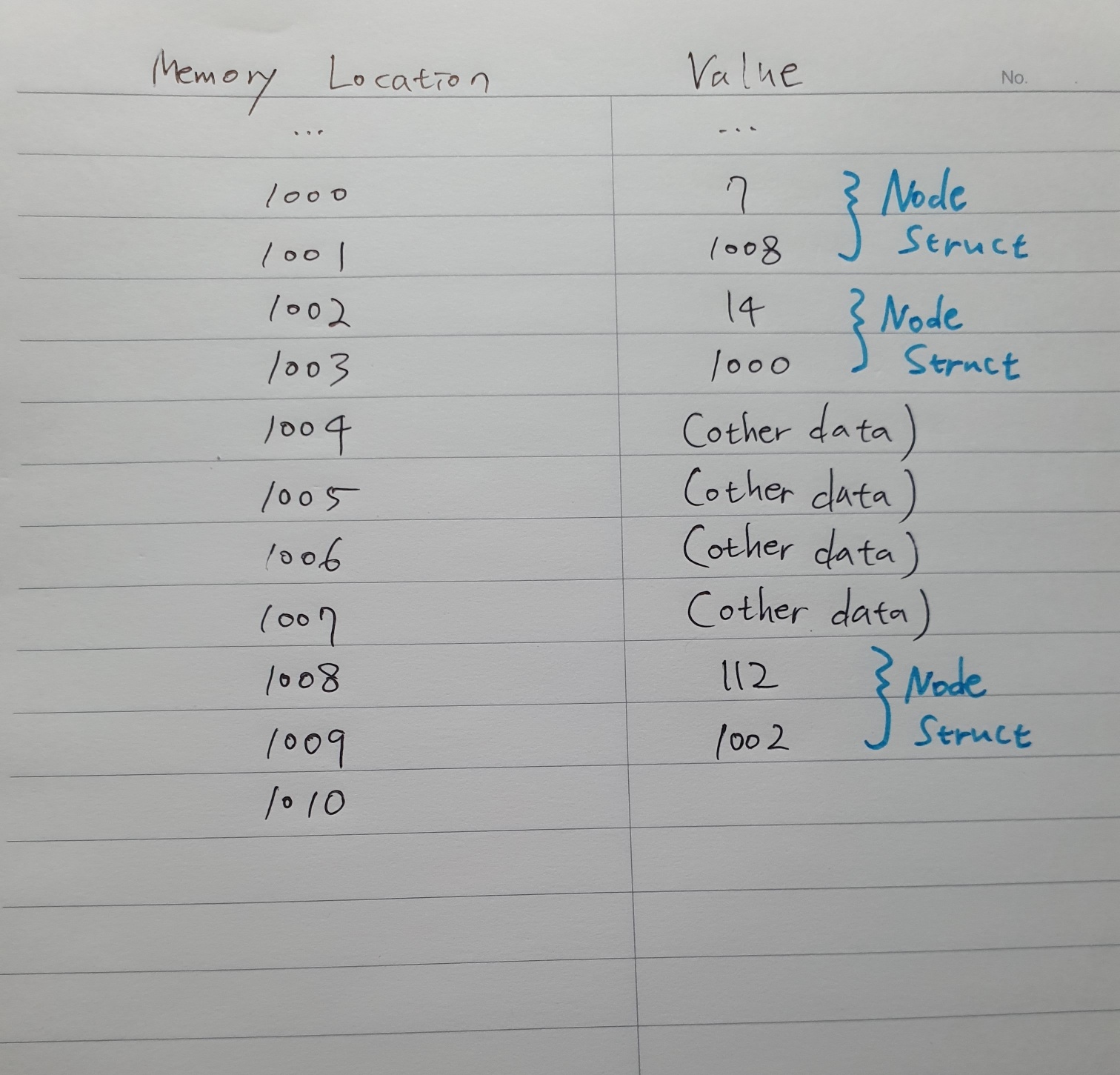
각각 다른 시간에 만들어졌기 때문에 멀리 떨어져 있고,
가운데 다른 데이터가 저장되어 있을 수도 있다.
첫 노드에는 값 7이 저장되어 있고, 주소 1008이 그 다음 포인터이다.
다음 노드가 연결리스트(linked list) 안에서 메모리 위치 1008에 있다는 것을 의미한다.
이 연결된 배열을 따라가보면 다음 위치에는 값 112를 저장할 수 있고
다음 노드는 1002 주소를 가리키고 있다.
또 따라가면 값 14를 구할 수 있고 다시 메모리 주소 1000으로 포인트하고 있다.
이 연결리스트는 원형이 되었다!!
하지만 다음 포인터 값을 0(NULL)로 해줌으로써 연결리스트를 끝낼 수도 있다. NULL값은 끝에 도달했음을 의미.
프로그래머가 연결 리스트를 사용할 때는 다음 목록에 저장된 메모리 값을 거의 보지 못한다.
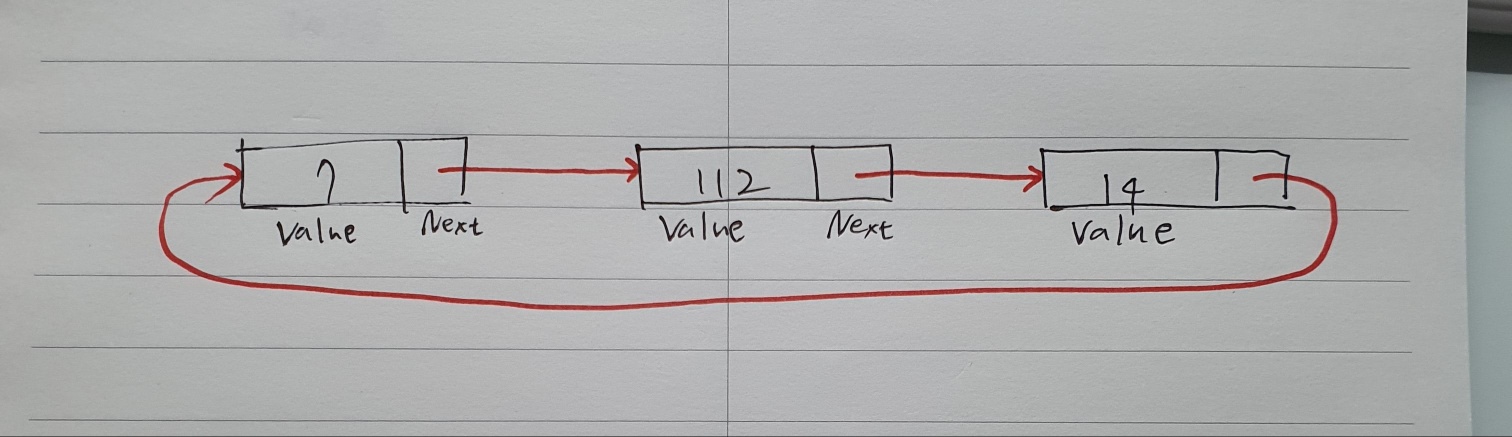
대신 그림처럼 추상화된 연결리스트를 사용해서 훨씬 쉽게 개념화할 수 있다.
크기를 미리 지정해줘야 하는 배열과는 달리
연결 리스트는 크기를 상황에 따라 늘이거나 줄일 수 있다.
다음 포인터만 변경하면 메모리에 새 노드를 할당하고 연결리스트에 삽입할 수 있다.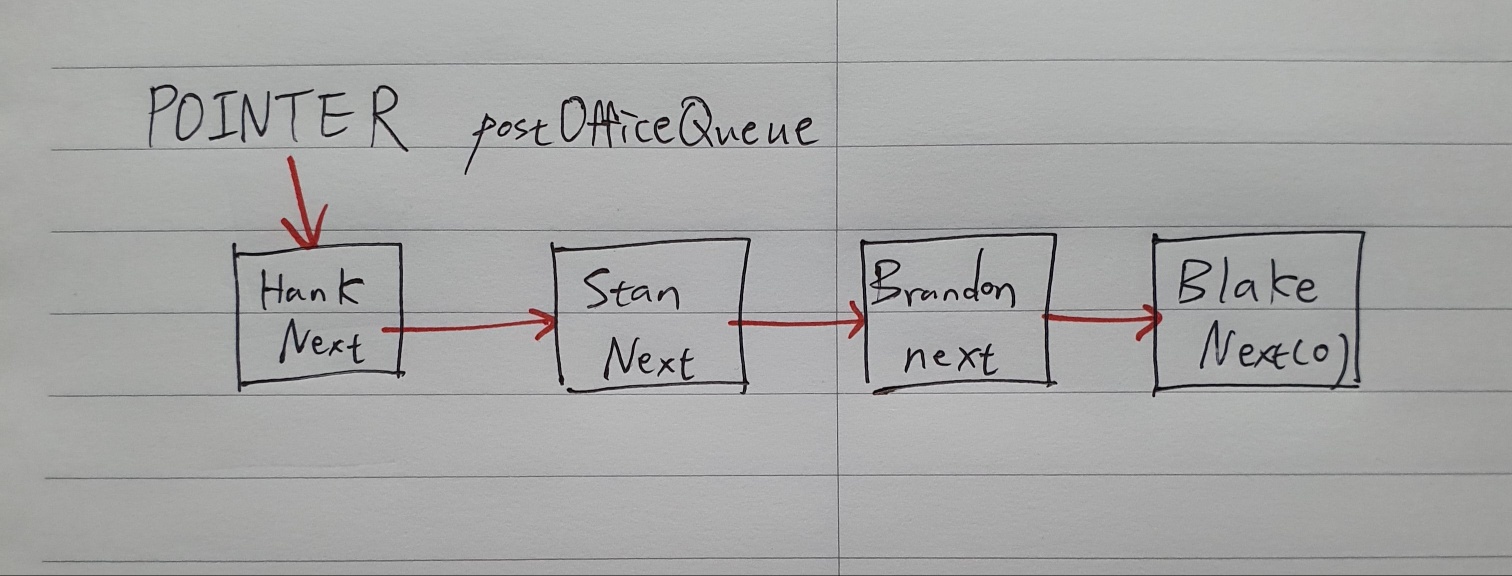
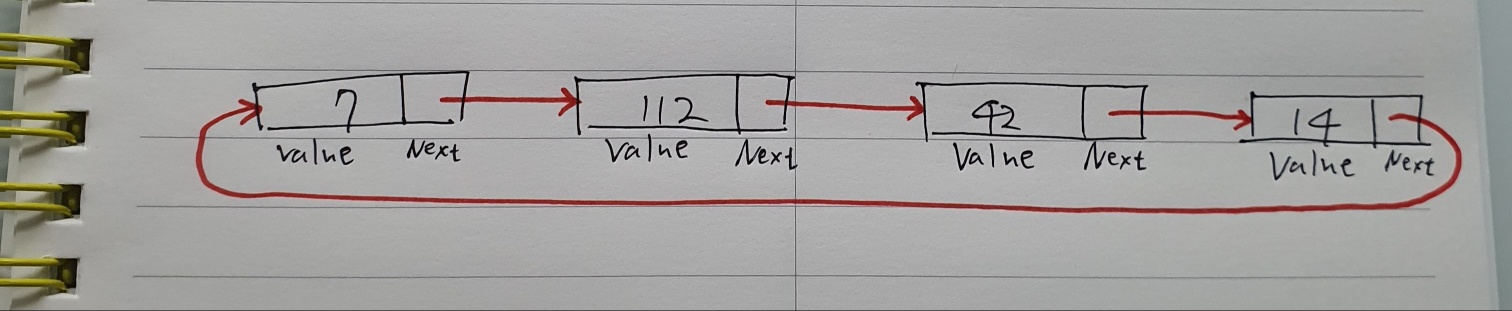
연결 리스트는 쉽게 순서를 바꾸거나 간략화, 쪼개기, 뒤집기 등이 가능하다.
정렬 알고리즘에도 유용하게 쓰인다.
이러한 유연성 덕분에 더욱 더 복잡한 자료 구조들이 연결 리스트 위에 구축되었다.
가장 유명하고 보편적인 것은 stack & queue이다.
큐(queue)
FIFO(First-In First-Out)
연결 리스트의 첫번째 노드를 가리키는 Post office queue라는 포인터가 있다고 가정해보자.
Hank에게 서비스를 제공해주고 나면 바로 뒤에 있던 사람의 포인터를 읽고 post office queue 포인터를 다음 사람으로 업데이트할 수 있다.
Hank 제거!
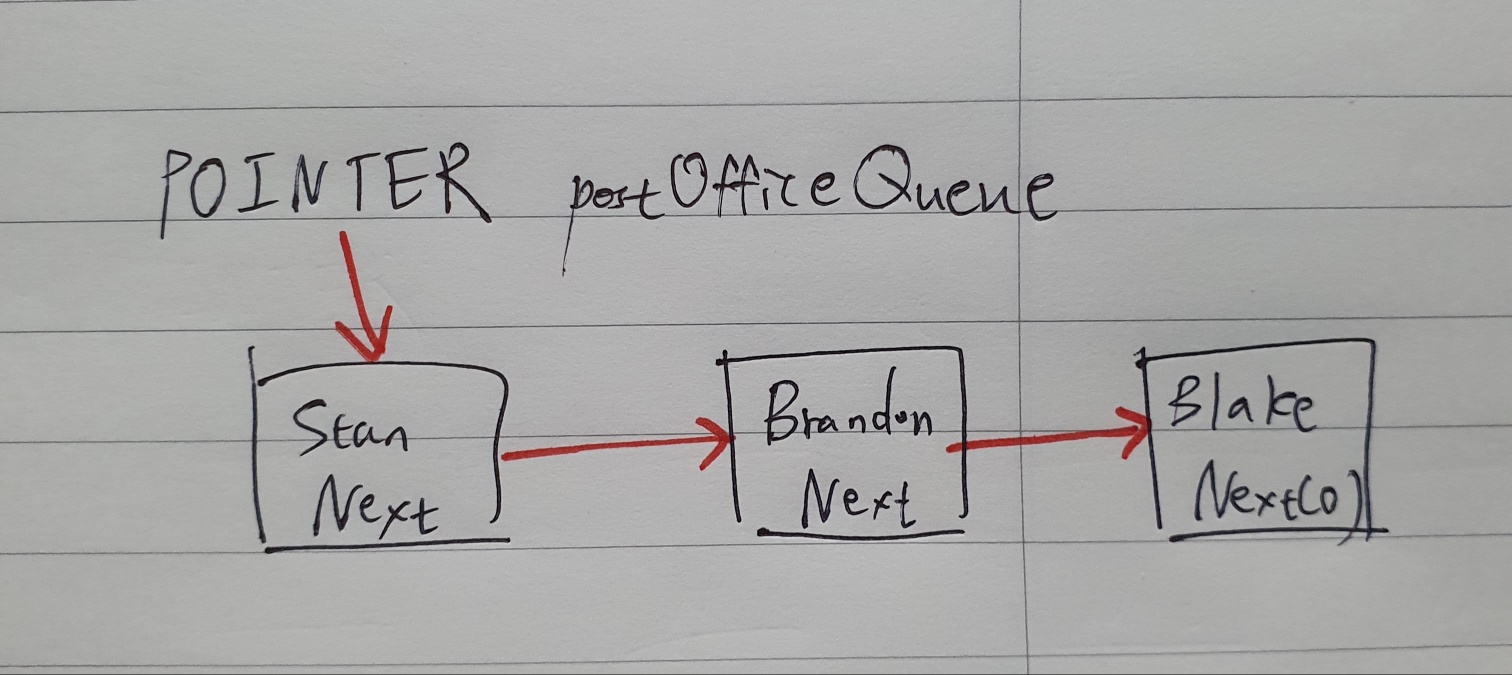
만약 누군가를 큐에 넣고 싶다면 연결리스트 마지막 사람의 포인터를 다음 사람을 향해서 연결해주면 된다.

스택(Stack)
LIFO(Last-In First-Out)

스택에서 데이터는 push로 추가되고 pop으로 제거된다.
마치 팬케익 더미처럼!
트리 구조(Trees)
우리가 노드 구조체를 포인터 한 개 대신 두개를 갖게 한다면,
다양한 알고리즘에 쓰이는 트리 구조를 만들 수 있다.
Struct node
Variable i
Pointer nextLeft
Pointer nextRight
End Struct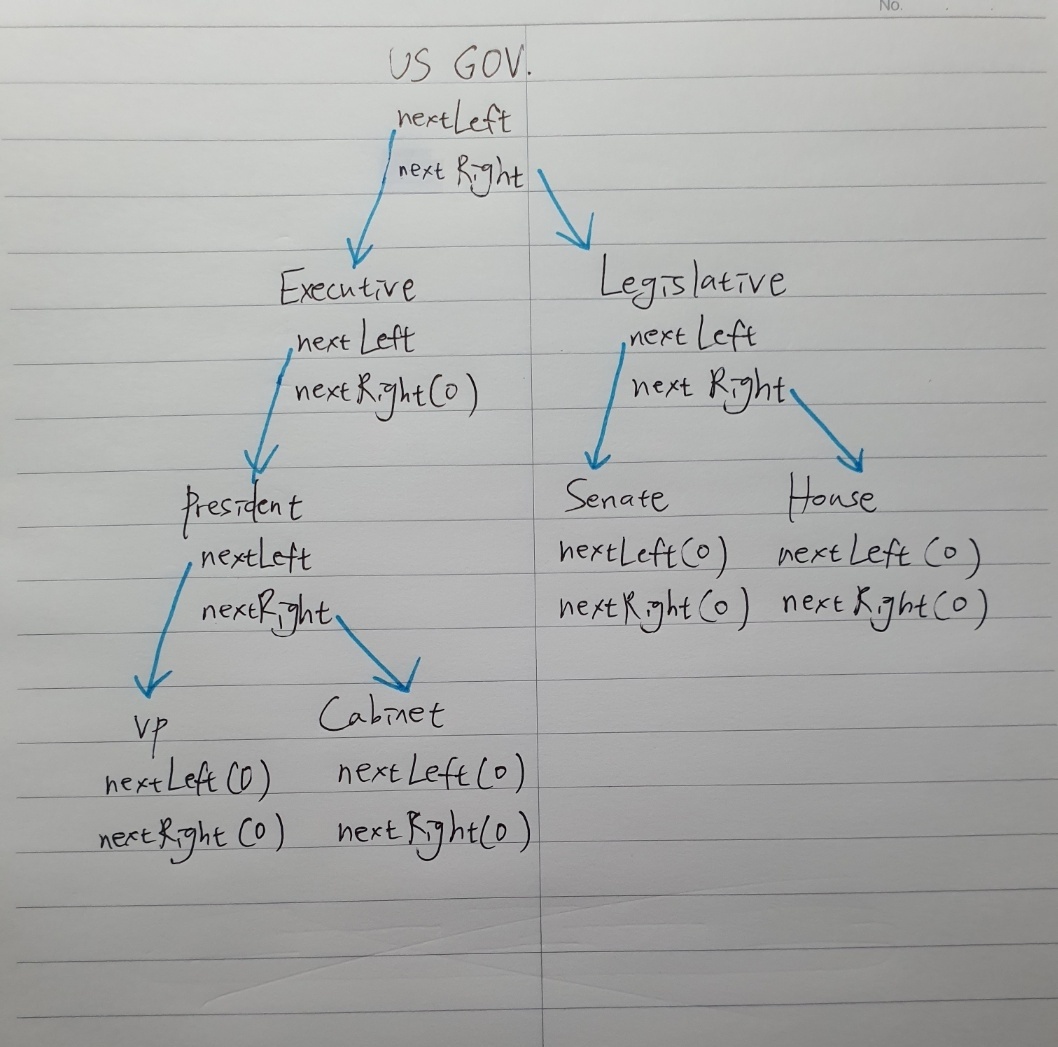
루트(root) : 가장 위에 있는 노드
자식 노드(Children nodes) : 한 노드에서 뻗어나오는 노드들
부모 노드(Parent nodes) : 자식 노드 위의 노드
리프 노드(Leaf nodes) : 자식 노드가 없는 맨 끝의 노드
이 예시를 보면 한 노드는 두 개까지의 자식을 가질 수 있다.
=> 이진 트리(binary tree)라고 함.
하지만 상황에 맞게 자료 구조를 수정하여 트리의 자식 노드 수를 3 이상의 임의의 수로도 늘릴 수 있다.
트리 구조에서 중요한 것은 뿌리에서 잎까지 하나의 길이 존재한다는 것이다.
무한 루프처럼 제멋대로 연결되는 자료들은 그래프 데이터 구조를 사용한다.
그래프 데이터 구조(Graph data)
지난 시간에 봤던 예시를 살펴보자.
도시들이 도로로 연결되어있다.
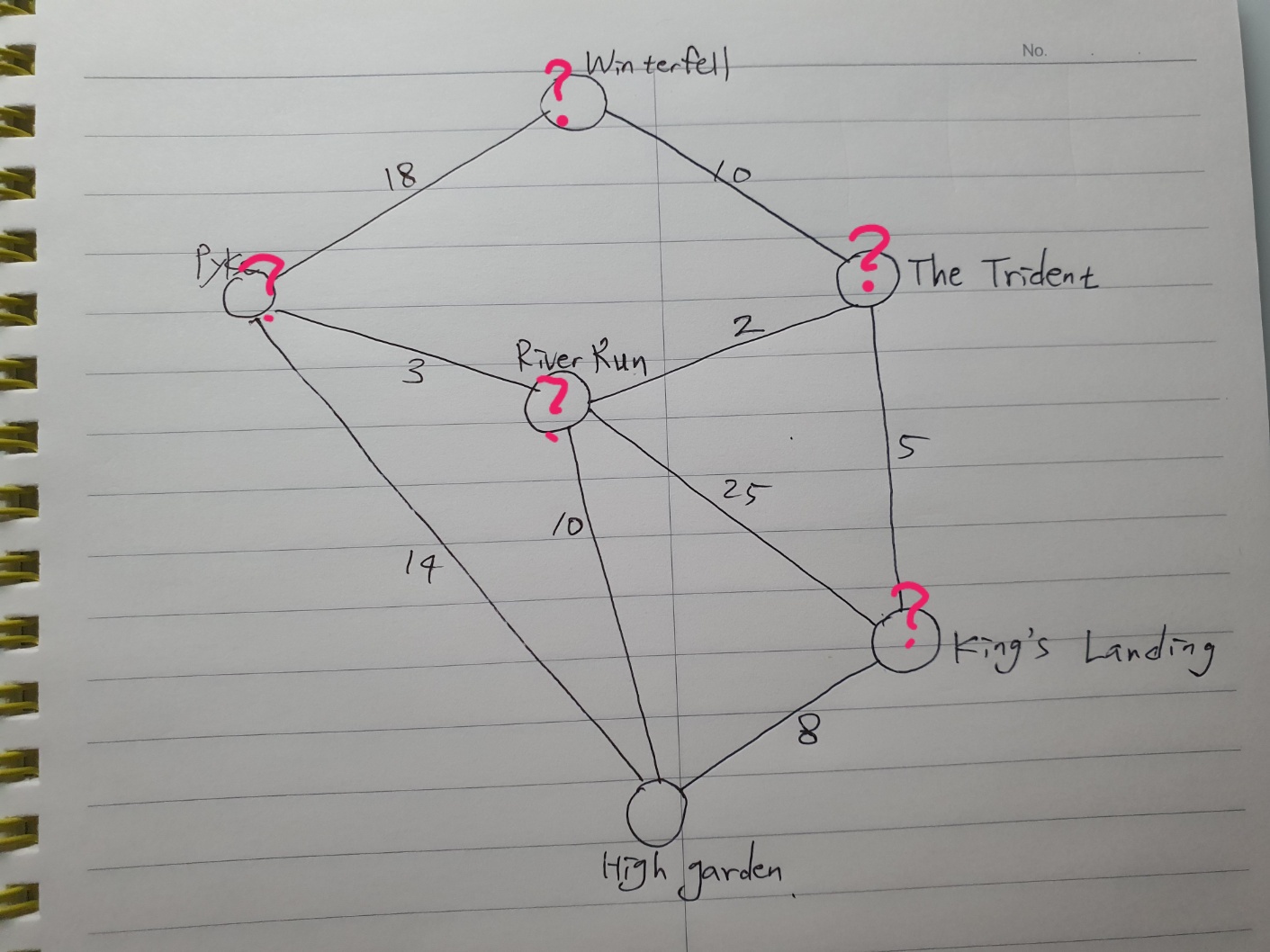
트리처럼 많은 포인터를 가지고 있는 노드로 저장할 수야 있지만
루트나 리프, 부모와 자식에 대한 개념은 없다.
anything can point anything!
위와 같은 기본적인 뼈대 위에 변형된 자료구조들도 많이 생겨났다.
힙이나 red-black 트리와 같은 자료구조들도 있다.
각각 다른 자료구조는 특정 계산에 유용한 속성을 가지고 있다.
알맞는 데이터 구조의 선택은 우리의 일을 쉽게 만들어준다!
다행히도 많은 프로그래밍 언어의 라이브러리에는 이미 만들어진 자료구조들이 가득하다.
ex) C++ : Standard Temlplate Library
Java : Java Class Library
