일부 알고리즘은 같은 결과를 생산해낼지라도 다른 알고리즘보다 우수하다.
일반적으로 계산에 소요되는 단계가 줄어들수록 더 좋은 결과를 얻을 수 있지만,
때로는 사용하는 메모리 양과 같은 다른 요인도 고려해야 한다.
알고리즘이라는 용어는 페르시아의 천재였던 Muhammad ibn Mūsā al-Khwārizmī(천년 전에 대수학의 아버지라 불리던 사람)에게서 비롯된 것.
효율적인 알고리즘의 제작은 현대 컴퓨터 이전에도 존재하던 문제였다.
정렬(sorting)
선택 정렬(selection sort)
CS에서 가장 중요한 알고리즘 문제 중 하나는 정렬(sorting)이다.
정렬의 종류는 매우 많다.
참고 : 갓무위키
https://namu.wiki/w/%EC%A0%95%EB%A0%AC%20%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
컴퓨터 과학자들은 멋진 이름으로 정렬 알고리즘을 수십년 동안 발명해왔다.
인디애나 폴리스를 가기 위한 항공 요금 배열을 가지고 있다고 상상해보자.
[307, 239, 214, 250, 384, 299, 223, 312]
이것을 오름차순 정렬해보자.
모든 숫자를 훑어보았을 때 214가 가장 작다.
따라서 맨 왼쪽과 번호와 위치를 바꾼다.
[214, // 239, 307, 250, 384, 299, 223, 312]이제 동일한 절차를 반복하지만 맨 왼쪽부터 시작하는 대신 한 칸 오른쪽부터 시작한다.
[214, 223 // 307, 250, 384, 299, 239, 312]세번째부터 이 과정을 반복하면
[214, 223, 239, 250, 299, 307, 312, 384]정렬 완료!
pseudo-code를 보자면
Function selectionSort(array)
For i = 0 To end of array
smallest = i
For index = i + 1 To end if array
If array item index < array item smallest
smallest = index
End if
Next
swap array items at index and smallest
Next
Return array이 함수는 8,80 또는 8천만개의 숫자를 정렬하는 데에도 사용할 수 있다.
또한 함수를 계속해서 다시 쓸 수도 있다.
이 정렬 알고리즘으로 배열 안의 각 위치를 맨 왼쪽부터 맨 오른쪽까지 순환한다.
각 위치에 대하여 배열에서 위치를 바꿀 가장 작은 수를 찾을 때까지 반복 실행한다.
이 코드에서 For루프가 다른 For루프 안에 포함되어 있는 것을 볼 수 있다.
이것은 우리가 N개의 항목을 정렬하고 싶다면 그 안에서 루프를 N번 반복해야 한다는 것을 의미한다. N*N루프!
입력하는 input의 크기와 number of steps 간의 관계는 선택정렬 알고리즘의 복잡도를 특징화하여, 알고리즘이 얼마나 빠를지 또는 느릴지에 대한 근사치를 제공한다.
이러한 성장 순서를 big O 표기법으로 기록한다.
O(n²)우리가 살펴본 예제에서는 n = 8개 항목이 있으므로
8제곱은 64이다.
배열의 크기를 8에서 80으로 늘리면?
실행 시간은 이제 80의 제곱인 6400이 된다. ㅎㄷㄷ
배열의 원소의 개수는 10배 증가했지만 실행시간은 100배 증가했다!!
Google과 같이 수십억개의 항목으로 배열을 정렬해야 하는 회사에게는 큰 문제이다.

더 효율적인 정렬 알고리즘도 있을까? Yes~~
합병 정렬(merge sort)
같은 배열을 보자.
[307, 239, 214, 250, 384, 299, 223, 312]우선 배열의 크기가 1보다 큰지 확인한다.
1보다 큰 경우 배열을 두 개로 나눈다.
[307, 239, 214, 250]
[384, 299, 223, 312]크기 1보다 여전히 크므로 다시 크기가 2인 배열로 나눈다.
[307, 239]
[214, 250]
[384, 299]
[223, 312]마지막에 각각 1개의 항목인 8개의 배열로 분해된다.
[307]
[239]
[214]
[250]
[384]
[299]
[223]
[312]처음 두 배열을 시작으로 첫번째 값이자 유일한 값인 307과 239를 읽는다.
239 < 307이므로 먼저 그 값을 가져온다.
그리고 남은 번호는 307이므로 307을 다음으로 가져온다.
[214]
[250]
[384]
[299]
[223]
[312]
// [239, 307]병합 성공!
남겨진 쌍들에도 반복하면
[239, 307]
[214, 250]
[384, 299]
[223, 312]그런 다음 합병 과정이 반복된다.
[239, 307]의 첫번째 원소와 [214, 250]의 첫번째 원소를 비교해보자.
214 < 239이므로 214를 먼저 놓는다.
[239, 307]
[250]
[384, 299]
[223, 312]
// [214]그 다음 239와 250을 비교.
239 < 250이므로 230을 놓는다.
[307]
[250]
[384, 299]
[223, 312]
// [214, 239]그런 다음 250과 307을 차례로 추가!
[384, 299]
[223, 312]
// [214, 239, 250, 307]남아있는 2쌍의 배열도 똑같은 합병 과정을 반복하면
[214, 223, 239, 250]
[299, 307, 312, 384]이제 크기가 4인 2개의 정렬된 배열이 있다.
이전과 마찬가지로 각 배열의 첫 번째 숫자를 비교하여 더 낮은 수를 가져오는 방식으로 모든 숫자가 합병될 때까지 정렬하면
[214, 223, 239, 250, 299, 307, 312, 384]정렬 완료!
합병 정렬의 계산 복잡도는
O(n * log n)이다.
n은 비교하고 합병하는데에 필요한 횟수만큼 발생하고,
이는 정렬 안의 배열 항목 수와 직접 비례한다.
log n은 병합 단계의 수에서 나온다.
이 예에서는 8개의 항목인 배열을 4개로, 2개로, 1개로 3번!!! 쪼갰다.
이런 식으로 반으로 나누는 것은 항목 수 사이에 로그 관계를 가지고 있다.
log₂(8) = 3이다.
만약 배열의 크기를 2배인 16으로 하면 정렬할 항목 수는 2배가 늘어나지만,
log₂(16) = 4이므로, 분할 단계 횟수는 1이 증가한다.
이해하는 데 도움이 많이 되었던 니꼬쌤 유튜브 링크
https://www.youtube.com/watch?v=BEVnxbxBqi8&list=PL7jH19IHhOLMdHvl3KBfFI70r9P0lkJwL&index=4
배열의 크기를 8에서 1000배인 8000으로 늘려도 분할 단계 수는 꽤 낮다.
log₂(8000) = 12.966
3보다 약 4배 정도 커지는 데에 그친다.
이러한 이유로 병합 정렬이 선택 정렬보다 훨씬 효율적이다!!
그래픽 탐색(graph search)
그래픽 문제의 고전적인 알고리즘 해법은 Edsger Dijkstra가 발명했다.
그래프는 선으로 연결된 노드 네트워크이다.
또는 도시와 각 도시를 연결하는 도로로 된 지도라고 생각해도 무방하다.
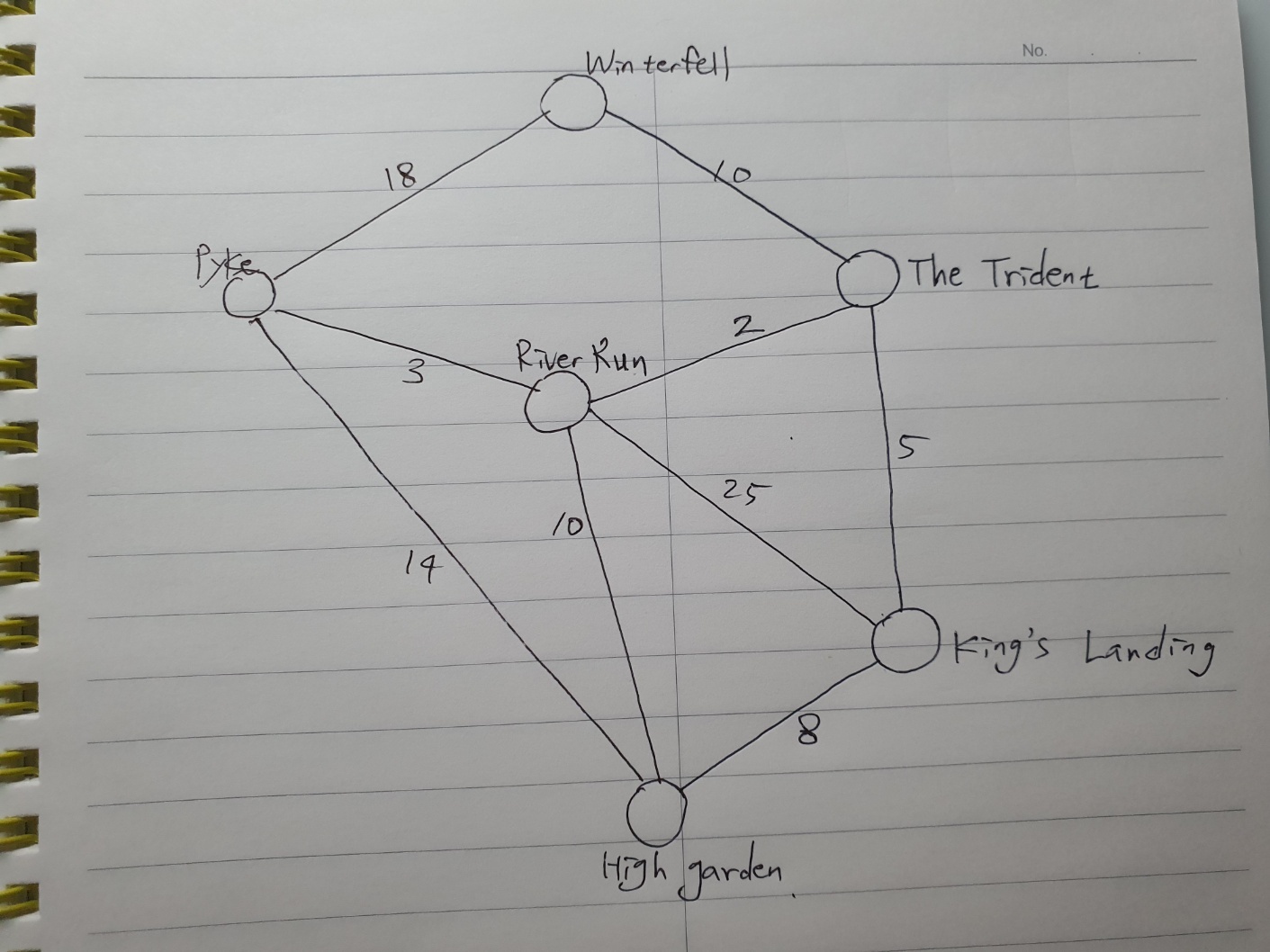
도시들 간의 경로는 각각 다른 시간이 걸린다.
비용이나 무게 또는 weeks of travel로 각각의 선을 이름 붙일 수 있다.
Highgarden에 있는 군대가 Winterfell의 성까지 가장 빠른 경로를 찾고 싶다고 가정해보자.
가장 간단한 방법은 모든 단일 경로를 철저히 조사하고 각각의 총 비용을 계산하는 것이다. (무차별적 접근)
체계적으로 모든 순열(permutation)을 검사하여 정렬 여부를 확인함으로써 무차별적 접근 방식을 사용할 수도 있다.
이것은
O(n!)의 복잡성을 가진다. n제곱보다도 나쁘다.
영리해지자.
먼저 Highgarden에서 0의 값으로 시작하는 것을 노드 안에 표시를 하겠다.
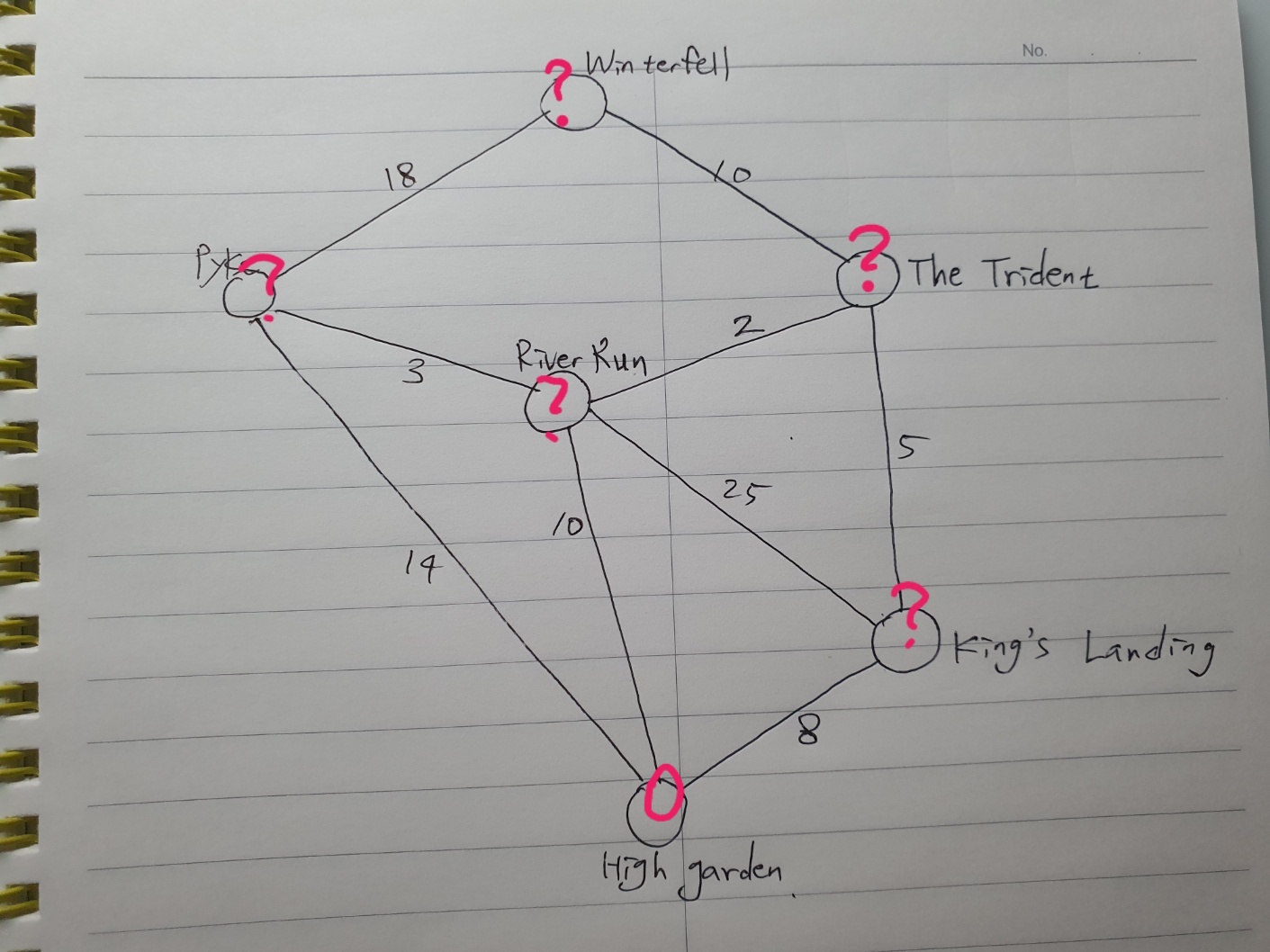
Edsger Dijkstra의 알고리즘은 항상 값이 가장 낮은 노드에서 시작한다.
이 경우에는 Highgarden에서 시작하여 한 단계 떨어져서 연결되어 있는 모든 노드로의 길을 하나씩 따라가며 각 노드에 도달하기 위한 값을 기록한다.

한 단계 완료!
아직 Winterfell에 도착하지 못했으므로 Dijkstra의 알고리즘을 반복 실행한다.
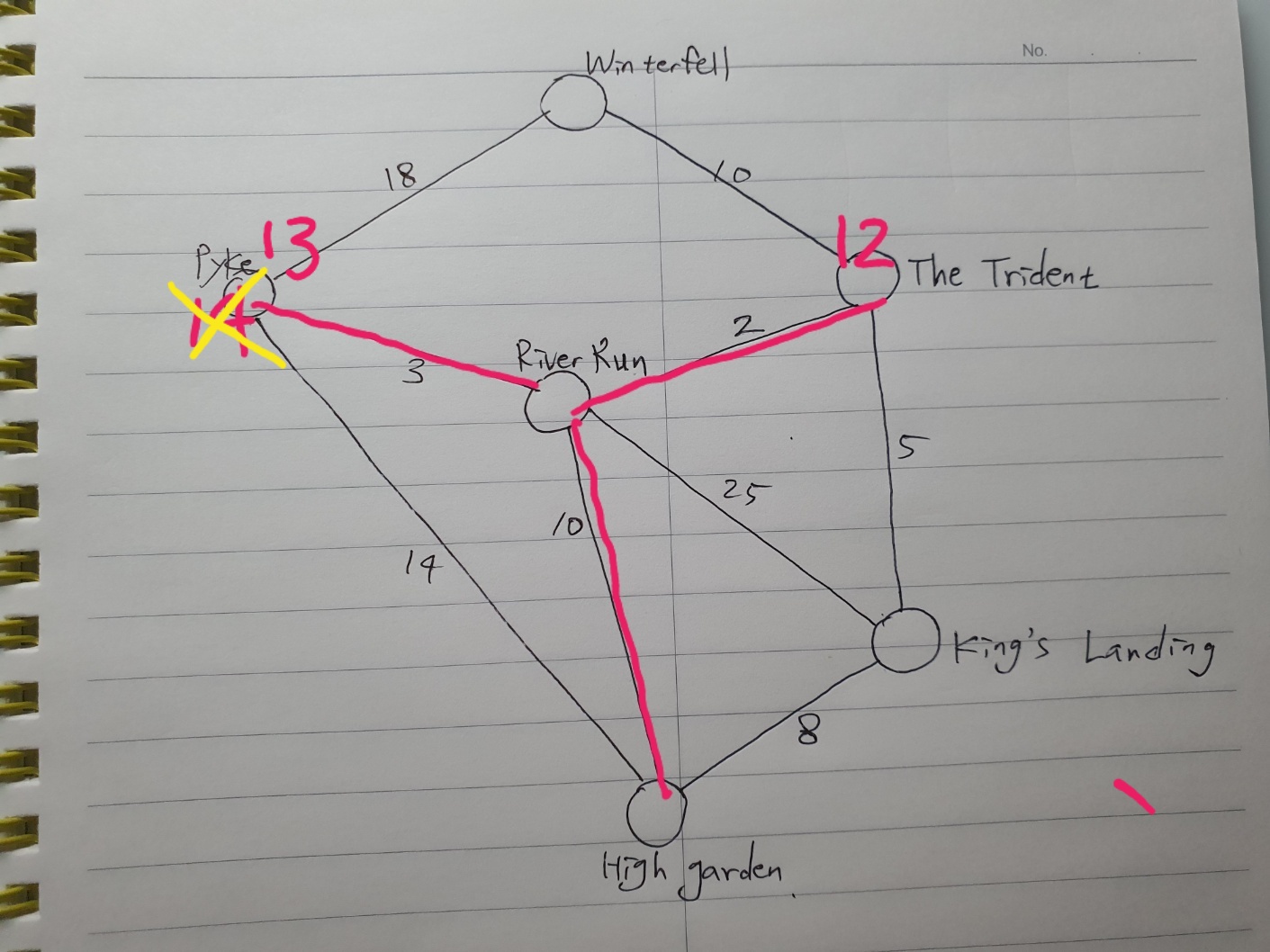
다음 최저값 노드는 King's Landing이다.
아직 방문하지 않은 연결된 도시로 따라간다.
The Trident로 가는 선은 5이므로 The Trident에 total값인 13을 표시한다.
이제 RiverRun으로 가는 오프로드 경로를 따라가본다.
25의 높은 값을 가지고 있으며 총합은 33이다.
하지만 기존에 표시한 10 < 33이므로 King's Landing - RiverRun의 경로는 버린다.
King's Landing 다음으로 가장 작은 수의 노드는 RiverRun의 10주이다.
먼저 The Trident로 가는 경로를 확인해보자.
total이 12인데 기존 13보다 낮네?
The Trident로 가는 경로를 업데이트 한다!
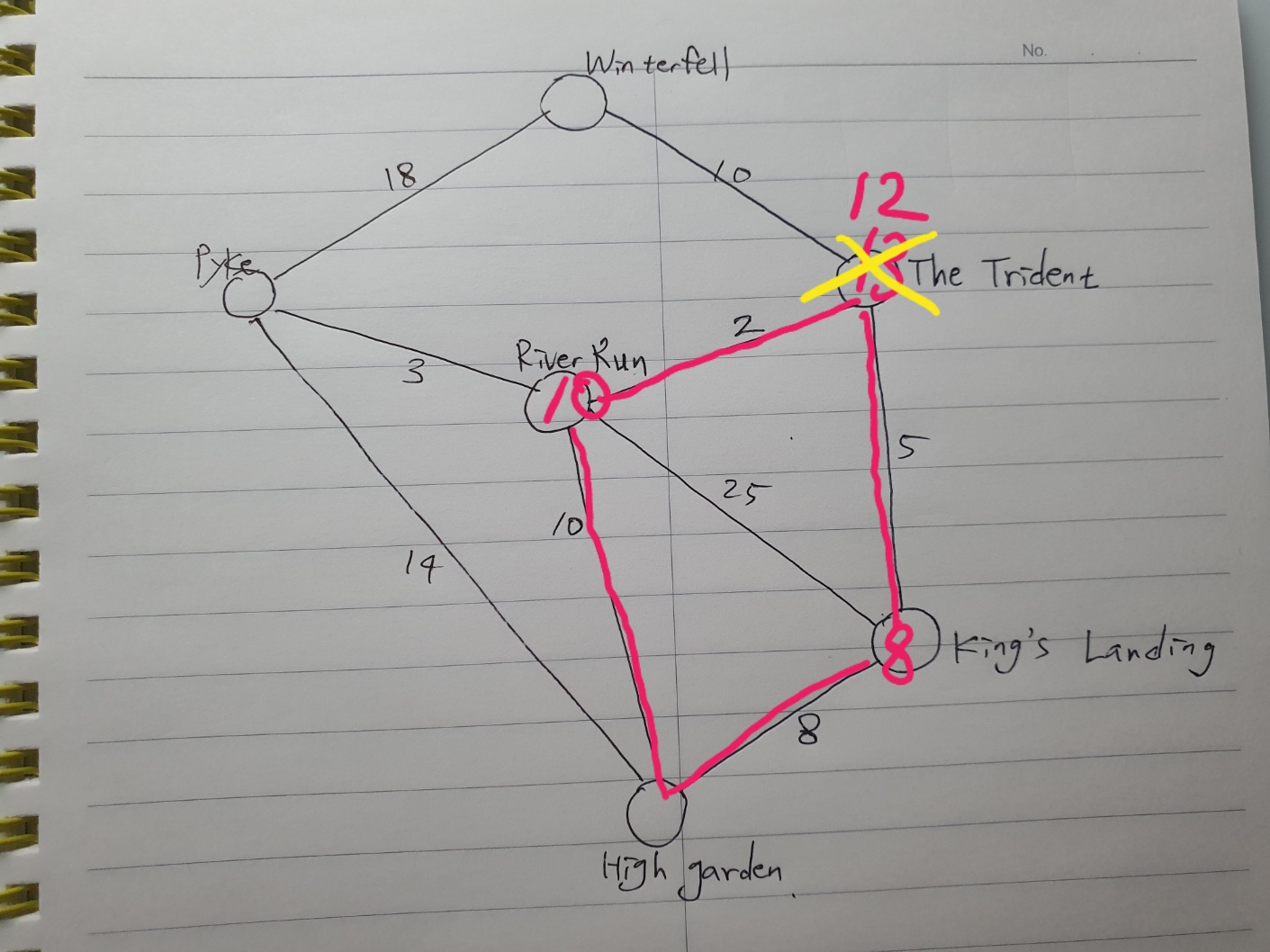
Pyke로 가는 경로도 같은 이유로 업데이트 한다.
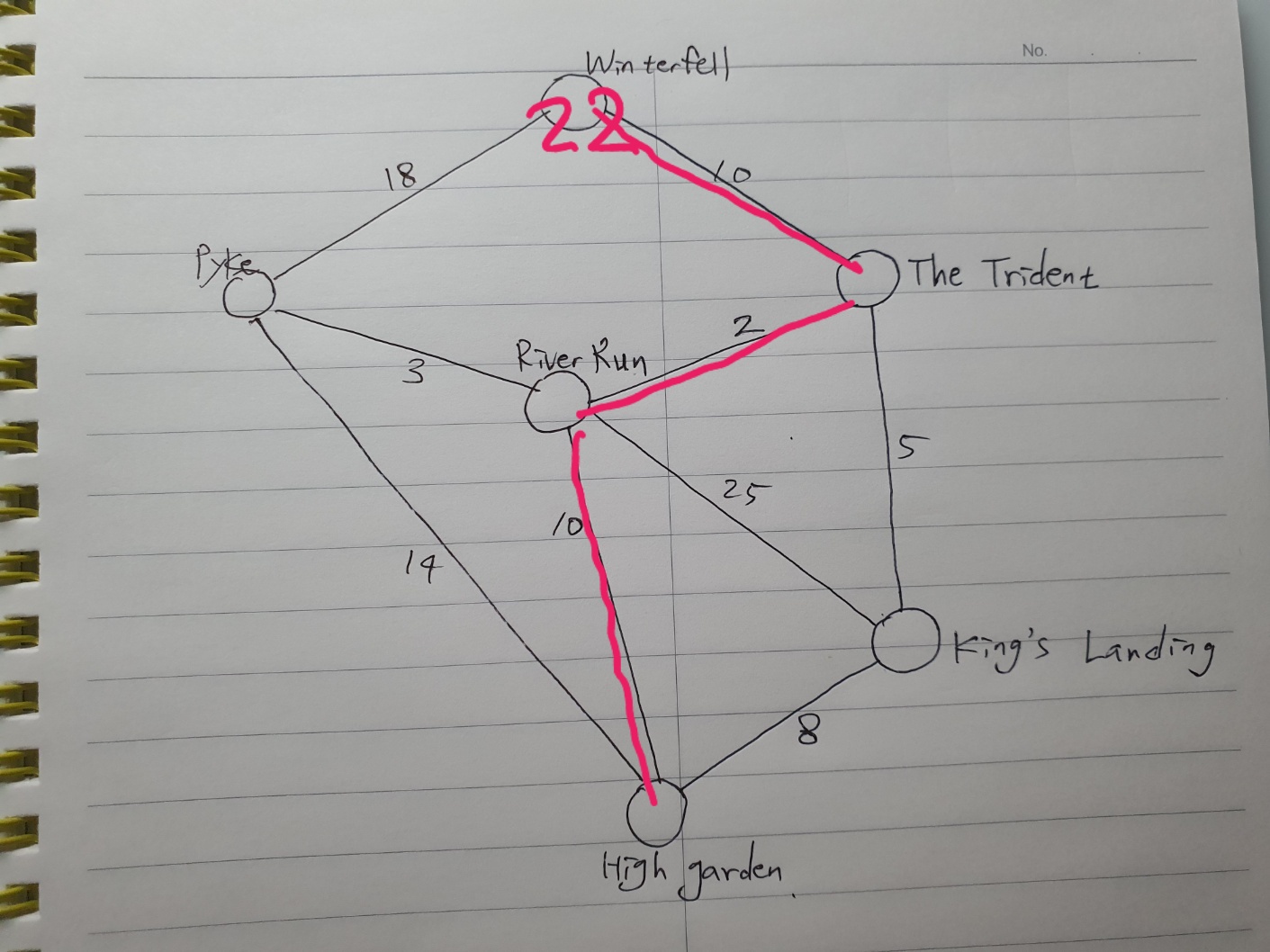
마지막으로 Dijkstra의 알고리즘 루프를 반복하면
The Trident에서 시작하며 Winterfell까지 가는 경로는 12 + 10 = 22이고
Pyke에서 시작하여 Winterfell까지 가는 경로는 13 + 18 = 31이므로
경로가 결정되었다.
Dijkstra의 원조 알고리즘은 1956년에 구상되었고,
그래프 안의 노드 수의 제곱만큼의 복잡도를 지녔다.
이미 논의되었듯이 제곱된 알고리즘은 절대 좋지 않다.
미국 전체의 도로 지도와 같은 커다란 범위의 알고리즘 문제를 해결할 수 없기 때문이다.
다행히도 몇 년 뒤 Dijkstra의 알고리즘이 개선되었다.
O(n * log n + I)n은 도시의 수이고, I는 경로(선)의 수이다.
예제 그래프에 적용해보면
O(n²) O(6²) = 36
O(n * log n + I) O(6 * log 6 + 9) = 13.7우리의 알고리즘은 36개의 루프에서 약 14개의 알고리즘으로 떨어진다.
정렬과 마찬가지로 수많은 장단점을 가진 무수히 많은 그래프 검색 알고리즘이 있다.
Google 지도로 길을 찾는 것과 같은 서비스를 사용할 때마다 Dijkstra의 알고리즘은 서버에서 실행되어 최고의 길을 안내해준다.
알고리즘은 어디에나 있으며 현대 세상은 알고리즘 없이는 불가능하다!!
