정방행렬은 고유분해로 고윳값과 고유벡터를 찾을 수 있었다. 정방행렬이 아닌 행렬은 고유분해가 불가능하다. 하지만 대신 고유분해와 비슷한 특이분해를 할 수 있다.
1. 특잇값과 특이벡터
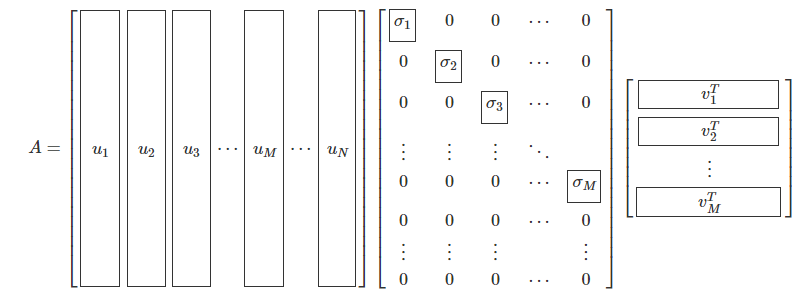
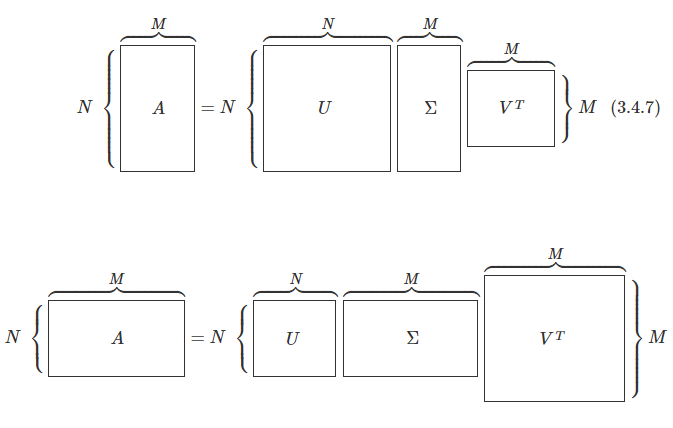
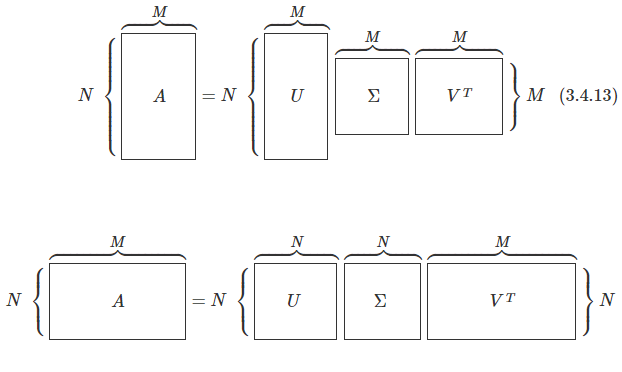
N × M N \times M N × M A A A 특이분해(singular-decomposition) 또는 특잇값 분해(singular value decomposition) 라고 한다.
A = U Σ V T A = U\Sigma V^T A = U Σ V T 여기에서 U , Σ , V U, \Sigma, V U , Σ , V
대각성분이 양수인 대각행렬이어야 한다. 큰 수부터 작은 수 순서로 배열한다.
Σ ∈ R N × M \Sigma \in \mathbf{R}^{N \times M} Σ ∈ R N × M
U U U N N N
U ∈ R N × N U \in \mathbf{R}^{N \times N} U ∈ R N × N
V V V M M M
V ∈ R M × M V \in \mathbf{R}^{M \times M} V ∈ R M × M 위 조건을 만족하는 행렬 Σ \Sigma Σ 특잇값(singular value) , 행렬 U U U 왼쪽 특이벡터 (left singular vector), 행렬 V V V 오른쪽 특이벡터 (right singular vector)라고 부른다.
[정리] 특이분해는 모든 행렬에 대해 가능하다. 즉 어떤 행렬이 주어지더라도 위와 같이 특이분해할 수 있다.
증명은 이 책의 범위를 벗어나므로 생략한다.
2. 특이값 분해 행렬의 크기
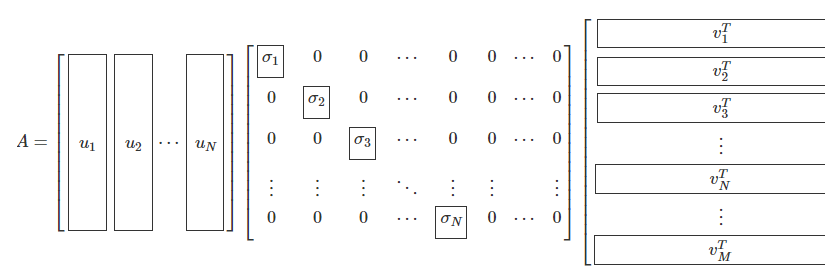
특잇값의 개수는 행렬의 열과 행의 개수 중 작은 값과 같다. 특이분해된 형태를 구체적으로 쓰면 다음과 같다.N > M N > M N > M Σ \Sigma Σ M M M N < M N < M N < M Σ \Sigma Σ N N N
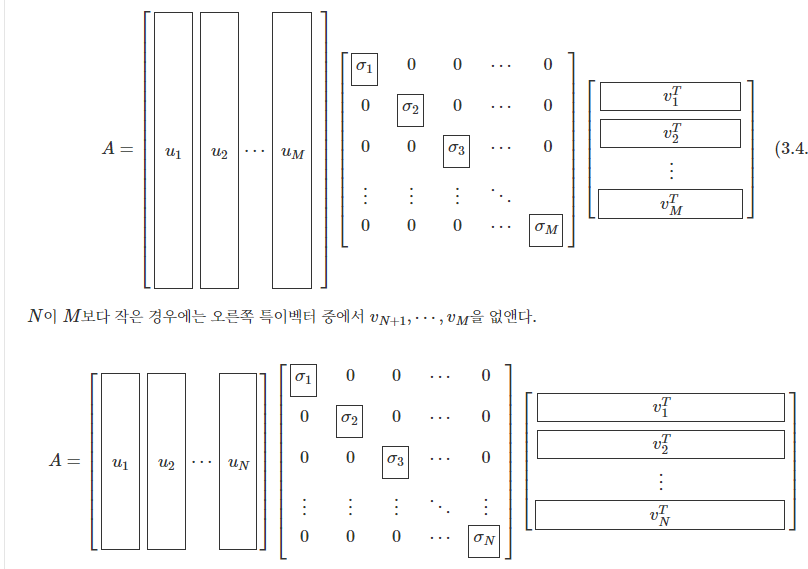
3. 특잇값 분해의 축소형
특잇값 대각행렬에서 0인 부분은 사실상 아무런 의미가 없기 때문에 대각행렬의 0 원소 부분과 이에 대응하는 왼쪽(혹은 오른쪽) 특이벡터들을 없애고 다음처럼 축소된 형태로 해도 마찬가지로 원래 행렬이 나온다.
N N N M M M u M + 1 , ⋯ , u N u_{M+1}, \cdots, u_N u M + 1 , ⋯ , u N
4. 파이썬을 사용한 특이분해
numpy.linalg 서브패키지와 scipy.linalg 서브패키지에서는 특이분해를 할 수 있는 svd() 명령을 제공한다. 오른쪽 특이행렬은 전치행렬로 출력된다는 점에 주의하라.
from numpy. linalg import svd
A = np. array( [ [ 3 , - 1 ] , [ 1 , 3 ] , [ 1 , 1 ] ] )
U, S, VT = svd( A) 5. 특잇값과 특이벡터의 관계
행렬 V V V
특이분해된 등식의 양변에 V V V
A V = U Σ V T V = U Σ AV = U\Sigma V^TV = U\Sigma A V = U Σ V T V = U Σ A [ v 1 v 2 ⋯ v M ] = [ u 1 u 2 ⋯ u N ] [ σ 1 0 ⋯ 0 σ 2 ⋯ ⋮ ⋮ ⋱ ] A \begin{bmatrix} v_1 & v_2 & \cdots & v_M \end{bmatrix} = \begin{bmatrix} u_1 & u_2 & \cdots & u_N \end{bmatrix} \begin{bmatrix} \sigma_1 & 0 & \cdots \\ 0 & \sigma_2 & \cdots \\ \vdots & \vdots & \ddots \\ \end{bmatrix} A [ v 1 v 2 ⋯ v M ] = [ u 1 u 2 ⋯ u N ] ⎣ ⎢ ⎢ ⎡ σ 1 0 ⋮ 0 σ 2 ⋮ ⋯ ⋯ ⋱ ⎦ ⎥ ⎥ ⎤ 행렬 A A A M M M N N N
[ A v 1 A v 2 ⋯ A v N ] = [ σ 1 u 1 σ 2 u 2 ⋯ σ N u N ] \begin{bmatrix} Av_1 & Av_2 & \cdots & Av_N \end{bmatrix} = \begin{bmatrix} \sigma_1u_1 & \sigma_2u_2 & \cdots & \sigma_Nu_N \end{bmatrix} [ A v 1 A v 2 ⋯ A v N ] = [ σ 1 u 1 σ 2 u 2 ⋯ σ N u N ] 이 되고 N N N M M M
[ A v 1 A v 2 ⋯ A v M ] = [ σ 1 u 1 σ 2 u 2 ⋯ σ M u M ] \begin{bmatrix} Av_1 & Av_2 & \cdots & Av_M \end{bmatrix} = \begin{bmatrix} \sigma_1u_1 & \sigma_2u_2 & \cdots & \sigma_Mu_M \end{bmatrix} [ A v 1 A v 2 ⋯ A v M ] = [ σ 1 u 1 σ 2 u 2 ⋯ σ M u M ] 이 된다.
즉, i i i σ i \sigma_i σ i u i u_i u i v i v_i v i
A v i = σ i u i ( i = 1 , … , min ( M , N ) ) Av_i = \sigma_i u_i \;\; (i=1, \ldots, \text{min}(M,N)) A v i = σ i u i ( i = 1 , … , min ( M , N ) ) 이 관계는 고유분해와 비슷하지만 고유분해와는 달리 좌변과 우변의 벡터가 다르다.
6. 특이분해와 고유분해의 관계
행렬 A A A A T A A^TA^{} A T A
A T A = ( V Σ T U T ) ( U Σ V T ) = V Λ V T A^TA^{} = (V^{} \Sigma^T U^T)( U^{}\Sigma^{} V^T) = V^{} \Lambda^{} V^T A T A = ( V Σ T U T ) ( U Σ V T ) = V Λ V T 가 되어 행렬 A A A A T A A^TA^{} A T A 행렬 A A A A T A A^TA^{} A T A 가 된다.
위 식에서 Λ \Lambda Λ N N N M M M
Λ = [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ M 2 ] \Lambda = \begin{bmatrix} \sigma_1^2 & 0 & \cdots & 0 \\ 0 & \sigma_2^2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \sigma_M^2 \\ \end{bmatrix} Λ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ σ 1 2 0 ⋮ 0 0 σ 2 2 ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ σ M 2 ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ 이고 N N N M M M
Λ = [ σ 1 2 0 ⋯ 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋯ 0 ⋮ ⋮ ⋱ ⋮ ⋮ ⋮ 0 0 ⋯ σ N 2 ⋯ 0 ⋮ ⋮ ⋯ ⋮ ⋱ ⋮ 0 0 ⋯ 0 ⋯ 0 ] = diag ( σ 1 2 , σ 2 2 , ⋯ , σ N 2 , 0 , ⋯ , 0 ) \Lambda = \begin{bmatrix} \sigma_1^2 & 0 & \cdots & 0 & \cdots & 0 \\ 0 & \sigma_2^2 & \cdots & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots \\ 0 & 0 & \cdots & \sigma_N^2 & \cdots & 0 \\ \vdots & \vdots & \cdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 0 & \cdots & 0 \\ \end{bmatrix} = \text{diag}(\sigma_1^2, \sigma_2^2, \cdots, \sigma_N^2, 0, \cdots, 0) Λ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ σ 1 2 0 ⋮ 0 ⋮ 0 0 σ 2 2 ⋮ 0 ⋮ 0 ⋯ ⋯ ⋱ ⋯ ⋯ ⋯ 0 0 ⋮ σ N 2 ⋮ 0 ⋯ ⋯ ⋮ ⋯ ⋱ ⋯ 0 0 ⋮ 0 ⋮ 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = diag ( σ 1 2 , σ 2 2 , ⋯ , σ N 2 , 0 , ⋯ , 0 ) 이다.
마찬가지 방법으로 행렬 A A A A A T AA^T A A T 가 된다는 것을 증명할 수 있다.
7. 1차원 근사
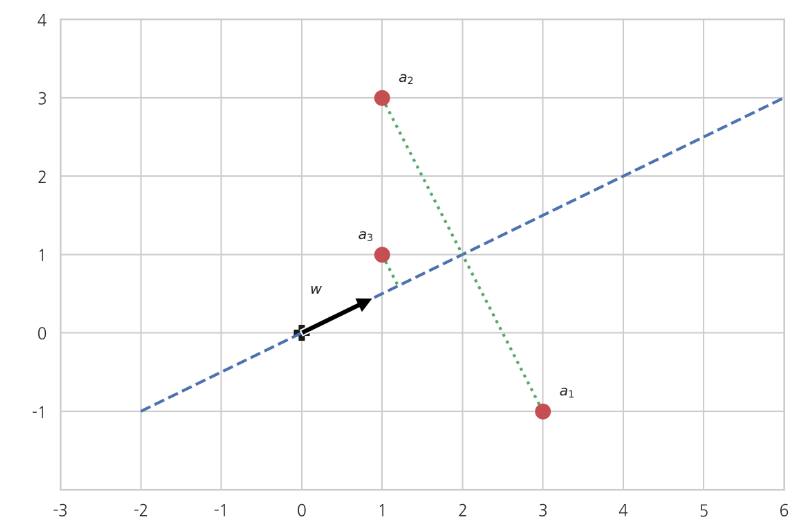
2차원 평면 위에 3개의 2차원 벡터 a 1 , a 2 , a 3 a_1, a_2, a_3 a 1 , a 2 , a 3 w w w
벡터 w w w a i a_i a i
∥ a i ⊥ w ∥ 2 = ∥ a i ∥ 2 − ∥ a i ∥ w ∥ 2 = ∥ a i ∥ 2 − ( a i T w ) 2 \Vert a_i^{\perp w}\Vert^2 = \Vert a_i\Vert^2 - \Vert a_i^{\Vert w}\Vert^2 = \Vert a_i\Vert^2 - (a_i^Tw)^2 ∥ a i ⊥ w ∥ 2 = ∥ a i ∥ 2 − ∥ a i ∥ w ∥ 2 = ∥ a i ∥ 2 − ( a i T w ) 2 벡터 a 1 , a 2 , a 3 a_1, a_2, a_3 a 1 , a 2 , a 3 A A A
A = [ a 1 T a 2 T a 3 T ] A = \begin{bmatrix} a_1^T \\ a_2^T \\ a_3^T \end{bmatrix} A = ⎣ ⎢ ⎡ a 1 T a 2 T a 3 T ⎦ ⎥ ⎤ 행벡터의 놈의 제곱의 합은 행렬의 놈이므로 모든 점들과의 거리의 제곱의 합은 행렬의 놈으로 계산된다. (연습 문제 2.3.2)
∑ i = 1 3 ∥ a i ⊥ w ∥ 2 = ∑ i = 1 3 ∥ a i ∥ 2 − ∑ i = 1 3 ( a i T w ) 2 = ∥ A ∥ 2 − ∥ A w ∥ 2 \begin{aligned} \sum_{i=1}^3 \Vert a_i^{\perp w}\Vert^2 &= \sum_{i=1}^3 \Vert a_i\Vert^2 - \sum_{i=1}^3 (a_i^Tw)^2 \\ &= \Vert A \Vert^2 - \Vert Aw\Vert^2 \\ \end{aligned} i = 1 ∑ 3 ∥ a i ⊥ w ∥ 2 = i = 1 ∑ 3 ∥ a i ∥ 2 − i = 1 ∑ 3 ( a i T w ) 2 = ∥ A ∥ 2 − ∥ A w ∥ 2 점 a i a_i a i A A A ∥ A w ∥ 2 \Vert Aw\Vert^2 ∥ A w ∥ 2 w w w
arg max w ∥ A w ∥ 2 \arg\max_w \Vert Aw \Vert^2 arg w max ∥ A w ∥ 2 8. 1차원 근사의 풀이
벡터 w w w a i a_i a i
∥ a i ⊥ w ∥ 2 = ∥ a i ∥ 2 − ∥ a i ∥ w ∥ 2 = ∥ a i ∥ 2 − ( a i T w ) 2 \Vert a_i^{\perp w}\Vert^2 = \Vert a_i\Vert^2 - \Vert a_i^{\Vert w}\Vert^2 = \Vert a_i\Vert^2 - (a_i^Tw)^2 ∥ a i ⊥ w ∥ 2 = ∥ a i ∥ 2 − ∥ a i ∥ w ∥ 2 = ∥ a i ∥ 2 − ( a i T w ) 2 벡터 a 1 , a 2 , a 3 a_1, a_2, a_3 a 1 , a 2 , a 3 A A A
A = [ a 1 T a 2 T a 3 T ] A = \begin{bmatrix} a_1^T \\ a_2^T \\ a_3^T \end{bmatrix} A = ⎣ ⎢ ⎡ a 1 T a 2 T a 3 T ⎦ ⎥ ⎤ 행벡터의 놈의 제곱의 합은 행렬의 놈이므로 모든 점들과의 거리의 제곱의 합은 행렬의 놈으로 계산된다. (연습 문제 2.3.2)
∑ i = 1 3 ∥ a i ⊥ w ∥ 2 = ∑ i = 1 3 ∥ a i ∥ 2 − ∑ i = 1 3 ( a i T w ) 2 = ∥ A ∥ 2 − ∥ A w ∥ 2 \begin{aligned} \sum_{i=1}^3 \Vert a_i^{\perp w}\Vert^2 &= \sum_{i=1}^3 \Vert a_i\Vert^2 - \sum_{i=1}^3 (a_i^Tw)^2 \\ &= \Vert A \Vert^2 - \Vert Aw\Vert^2 \\ \end{aligned} i = 1 ∑ 3 ∥ a i ⊥ w ∥ 2 = i = 1 ∑ 3 ∥ a i ∥ 2 − i = 1 ∑ 3 ( a i T w ) 2 = ∥ A ∥ 2 − ∥ A w ∥ 2 점 a i a_i a i A A A ∥ A w ∥ 2 \Vert Aw\Vert^2 ∥ A w ∥ 2 w w w
arg max w ∥ A w ∥ 2 \arg\max_w \Vert Aw \Vert^2 arg w max ∥ A w ∥ 2 위에서 예로 든 행렬 A ∈ R 3 × 2 A \in \mathbf{R}^{3 \times 2} A ∈ R 3 × 2
첫 번째 특잇값: σ 1 \sigma_1 σ 1 u 1 ∈ R 3 u_1 \in \mathbf{R}^{3} u 1 ∈ R 3 v 1 ∈ R 2 v_1 \in \mathbf{R}^{2} v 1 ∈ R 2
두 번째 특잇값: σ 2 \sigma_2 σ 2 u 2 ∈ R 3 u_2 \in \mathbf{R}^{3} u 2 ∈ R 3 v 2 ∈ R 2 v_2 \in \mathbf{R}^{2} v 2 ∈ R 2
첫 번째 특잇값 σ 1 \sigma_1 σ 1 σ 2 \sigma_2 σ 2
σ 1 ≥ σ 2 \sigma_1 \geq \sigma_2 σ 1 ≥ σ 2 또한 위에서 알아낸 것처럼 A에 오른쪽 특이벡터를 곱하면 왼쪽 특이벡터 방향이 된다.
A v 1 = σ 1 u 1 A v_1 = \sigma_1 u_1 A v 1 = σ 1 u 1 A v 2 = σ 2 u 2 A v_2 = \sigma_2 u_2 A v 2 = σ 2 u 2 오른쪽 특이벡터 v 1 , v 2 v_1, v_2 v 1 , v 2
우리는 ∥ A w ∥ \Vert Aw\Vert ∥ A w ∥ w w w w w w v 1 , v 2 v_1, v_2 v 1 , v 2
w = w 1 v 1 + w 2 v 2 w = w_{1} v_1 + w_{2} v_2 w = w 1 v 1 + w 2 v 2 단, w w w w 1 , w 2 w_{1}, w_{2} w 1 , w 2
w 1 2 + w 2 2 = 1 w_{1}^2 + w_{2}^2 = 1 w 1 2 + w 2 2 = 1 이때 ∥ A w ∥ \Vert Aw\Vert ∥ A w ∥
∥ A w ∥ 2 = ∥ A ( w 1 v 1 + w 2 v 2 ) ∥ 2 = ∥ w 1 A v 1 + w 2 A v 2 ∥ 2 = ∥ w 1 σ 1 u 1 + w 2 σ 2 u 2 ∥ 2 = ∥ w 1 σ 1 u 1 ∥ 2 + ∥ w 2 σ 2 u 2 ∥ 2 (orthogonal) = w 1 2 σ 1 2 ∥ u 1 ∥ 2 + w 2 2 σ 2 2 ∥ u 2 ∥ 2 = w 1 2 σ 1 2 + w 2 2 σ 2 2 (unit vector) \begin{aligned} \Vert Aw\Vert^2 &= \Vert A(w_{1} v_1 + w_{2} v_2)\Vert^2 \\ &= \Vert w_{1}Av_1 + w_{2}Av_2 \Vert^2 \\ &= \Vert w_{1} \sigma_1 u_1 + w_{2} \sigma_2 u_2 \Vert^2 \\ &= \Vert w_{1} \sigma_1 u_1 \Vert^2 + \Vert w_{2} \sigma_2 u_2 \Vert^2 \;\; \text{(orthogonal)} \\ &= w_{1}^2 \sigma_1^2 \Vert u_1 \Vert^2 + w_{2}^2 \sigma_2^2 \Vert u_2 \Vert^2 \\ &= w_{1}^2 \sigma_1^2 + w_{2}^2 \sigma_2^2 \;\; \text{(unit vector)}\\ \end{aligned} ∥ A w ∥ 2 = ∥ A ( w 1 v 1 + w 2 v 2 ) ∥ 2 = ∥ w 1 A v 1 + w 2 A v 2 ∥ 2 = ∥ w 1 σ 1 u 1 + w 2 σ 2 u 2 ∥ 2 = ∥ w 1 σ 1 u 1 ∥ 2 + ∥ w 2 σ 2 u 2 ∥ 2 (orthogonal) = w 1 2 σ 1 2 ∥ u 1 ∥ 2 + w 2 2 σ 2 2 ∥ u 2 ∥ 2 = w 1 2 σ 1 2 + w 2 2 σ 2 2 (unit vector) σ 1 > σ 2 > 0 \sigma_1 > \sigma_2 > 0 σ 1 > σ 2 > 0 w 1 2 + w 2 2 = 1 w_{1}^2 + w_{2}^2 = 1 w 1 2 + w 2 2 = 1 w 1 , w 2 w_{1}, w_{2} w 1 , w 2
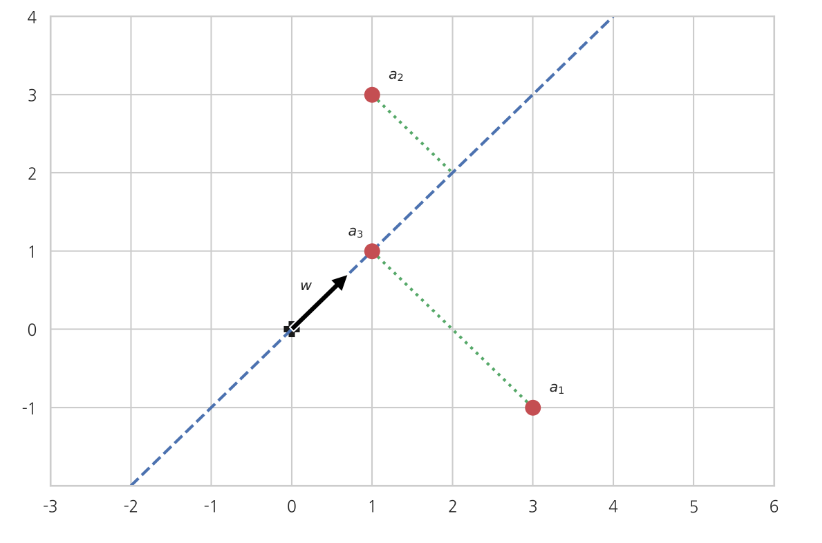
w 1 = 1 , w 2 = 0 w_{1} = 1, w_{2} = 0 w 1 = 1 , w 2 = 0 이다. 즉, 첫 번째 오른쪽 특이벡터 방향으로 하는 것이다.
이때 ∥ A w ∥ \Vert Aw\Vert ∥ A w ∥
∥ A w ∥ = ∥ A v 1 ∥ = ∥ σ 1 u 1 ∥ = σ 1 ∥ u 1 ∥ = σ 1 \Vert Aw\Vert = \Vert Av_1\Vert = \Vert \sigma_1 u_1\Vert = \sigma_1 \Vert u_1\Vert = \sigma_1 ∥ A w ∥ = ∥ A v 1 ∥ = ∥ σ 1 u 1 ∥ = σ 1 ∥ u 1 ∥ = σ 1 위에서 예로 들었던 행렬
A = [ 3 − 1 1 3 1 1 ] A = \begin{bmatrix} 3 & -1 \\ 1 & 3 \\ 1 & 1 \end{bmatrix} A = ⎣ ⎢ ⎡ 3 1 1 − 1 3 1 ⎦ ⎥ ⎤ 첫 번째 오른쪽 특이벡터
v 1 = [ 2 2 2 2 ] v_1 = \begin{bmatrix} \frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} \\ \end{bmatrix} v 1 = [ 2 2 2 2 ] 가 가장 거리의 합이 작은 방향이 된다. 그리고 이때의 거리의 제곱의 합은 다음과 같다.
∥ A ∥ 2 − ∥ A w ∥ 2 = ∥ A ∥ 2 − σ 1 2 \Vert A \Vert^2 - \Vert Aw\Vert^2 =\Vert A \Vert^2 - \sigma_1^2 ∥ A ∥ 2 − ∥ A w ∥ 2 = ∥ A ∥ 2 − σ 1 2 만약 N = 3 N=3 N = 3
∥ A w ∥ 2 = ∑ i = 1 N ( a i T w ) 2 = ∑ i = 1 N ( a i T w ) T ( a i T w ) = ∑ i = 1 N w T a i a i T w = w T ( ∑ i = 1 N a i a i T ) w = w T A T A w \begin{aligned} \Vert Aw \Vert^2 &= \sum_{i=1}^{N} (a_i^Tw)^2 \\ &= \sum_{i=1}^{N} (a_i^Tw)^T(a_i^Tw) \\ &= \sum_{i=1}^{N} w^Ta_ia_i^Tw \\ &= w^T \left( \sum_{i=1}^{N} a_ia_i^T \right) w \\ &= w^T A^TA w \\ \end{aligned} ∥ A w ∥ 2 = i = 1 ∑ N ( a i T w ) 2 = i = 1 ∑ N ( a i T w ) T ( a i T w ) = i = 1 ∑ N w T a i a i T w = w T ( i = 1 ∑ N a i a i T ) w = w T A T A w 분산행렬의 고유분해 공식을 이용하면,
w T A T A w = w T V Λ V T w = w T ( ∑ i = 1 M σ i 2 v i v i T ) w = ∑ i = 1 M σ i 2 ( w T v i ) ( v i T w ) = ∑ i = 1 M σ i 2 ∥ v i T w ∥ 2 \begin{aligned} w^T A^TA w &= w^T V \Lambda V^T w \\ &= w^T \left( \sum_{i=1}^{M} \sigma^2_iv_iv_i^T \right) w \\ &= \sum_{i=1}^{M}\sigma^2_i(w^Tv_i)(v_i^Tw) \\ &= \sum_{i=1}^{M}\sigma^2_i\Vert v_i^Tw\Vert^2 \\ \end{aligned} w T A T A w = w T V Λ V T w = w T ( i = 1 ∑ M σ i 2 v i v i T ) w = i = 1 ∑ M σ i 2 ( w T v i ) ( v i T w ) = i = 1 ∑ M σ i 2 ∥ v i T w ∥ 2 이 된다. 이 식에서 M M M
즉, 우리가 풀어야 할 문제는 다음과 같다.
arg max w ∥ A w ∥ 2 = arg max w ∑ i = 1 M σ i 2 ∥ v i T w ∥ 2 \arg\max_w \Vert Aw \Vert^2 = \arg\max_w \sum_{i=1}^{M}\sigma^2_i\Vert v_i^Tw\Vert^2 arg w max ∥ A w ∥ 2 = arg w max i = 1 ∑ M σ i 2 ∥ v i T w ∥ 2 이 값을 가장 크게 하려면 w w w v 1 v_1 v 1
9. 랭크-1 근사문제
또 a i a_i a i w w w
a i ∥ w = ( a i T w ) w a^{\Vert w}_i = (a_i^Tw)w a i ∥ w = ( a i T w ) w 이므로 w w w N N N M M M a 1 , a 2 , ⋯ , a N ( a i ∈ R M ) a_1, a_2, \cdots, a_N\;(a_i \in \mathbf{R}^M) a 1 , a 2 , ⋯ , a N ( a i ∈ R M ) N N N a 1 ∥ w , a 2 ∥ w , ⋯ , a N ∥ w ( a i ∥ w ∈ R 1 ) a^{\Vert w}_1, a^{\Vert w}_2, \cdots, a^{\Vert w}_N\;(a^{\Vert w}_i \in \mathbf{R}^1) a 1 ∥ w , a 2 ∥ w , ⋯ , a N ∥ w ( a i ∥ w ∈ R 1 )
A ′ = [ ( a 1 ∥ w ) T ( a 2 ∥ w ) T ⋮ ( a N ∥ w ) T ] = [ a 1 T w w T a 2 T w w T ⋮ a N T w w T ] = [ a 1 T a 2 T ⋮ a N T ] w w T = A w w T A'= \begin{bmatrix} \left(a^{\Vert w}_1\right)^T \\ \left(a^{\Vert w}_2\right)^T \\ \vdots \\ \left(a^{\Vert w}_N\right)^T \end{bmatrix} = \begin{bmatrix} a_1^Tw^{}w^T \\ a_2^Tw^{}w^T \\ \vdots \\ a_N^Tw^{}w^T \end{bmatrix} = \begin{bmatrix} a_1^T \\ a_2^T \\ \vdots \\ a_N^T \end{bmatrix} w^{}w^T = Aw^{}w^T A ′ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ( a 1 ∥ w ) T ( a 2 ∥ w ) T ⋮ ( a N ∥ w ) T ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 T w w T a 2 T w w T ⋮ a N T w w T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 T a 2 T ⋮ a N T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ w w T = A w w T 이 답은 원래 행렬 A A A w w T w^{}w^T w w T A A A A ′ A' A ′
arg min w ∥ A − A ′ ∥ = arg min w ∥ A − A w w T ∥ \arg\min_w \Vert A - A' \Vert = \arg\min_w \Vert A^{} - A^{}w^{}w^T \Vert arg w min ∥ A − A ′ ∥ = arg w min ∥ A − A w w T ∥ 따라서 문제를 랭크-1 근사문제(rank-1 approximation problem) 라고도 한다.
10. K차원 근사
이번에는 N N N M M M a 1 , a 2 , ⋯ , a N ( a i ∈ R M ) a_1, a_2, \cdots, a_N\;(a_i \in \mathbf{R}^M) a 1 , a 2 , ⋯ , a N ( a i ∈ R M ) w 1 , w 2 , ⋯ , w K w_1, w_2, \cdots, w_K w 1 , w 2 , ⋯ , w K K K K N N N K K K a 1 ∥ w , a 2 ∥ w , ⋯ , a N ∥ w a^{\Vert w}_1, a^{\Vert w}_2, \cdots, a^{\Vert w}_N\; a 1 ∥ w , a 2 ∥ w , ⋯ , a N ∥ w w 1 , w 2 , ⋯ , w K w_1, w_2, \cdots, w_K w 1 , w 2 , ⋯ , w K K K K
기저벡터행렬을 W W W
W = [ w 1 w 2 ⋯ w K ] W = \begin{bmatrix} w_1 & w_2 & \cdots & w_K \end{bmatrix} W = [ w 1 w 2 ⋯ w K ] 정규직교 기저벡터에 대한 벡터 a i a_i a i a i ∥ w a^{\Vert w}_i a i ∥ w
a i ∥ w = ( a i T w 1 ) w 1 + ( a i T w 2 ) w 2 + ⋯ + ( a i T w K ) w K = ∑ k = 1 K ( a i T w k ) w k \begin{aligned} a^{\Vert w}_i &= (a_i^Tw_1)w_1 + (a_i^Tw_2)w_2 + \cdots + (a_i^Tw_K)w_K \\ \end{aligned} = \sum_{k=1}^K (a_i^Tw_k)w_k a i ∥ w = ( a i T w 1 ) w 1 + ( a i T w 2 ) w 2 + ⋯ + ( a i T w K ) w K = k = 1 ∑ K ( a i T w k ) w k 벡터 a 1 , a 2 , ⋯ , a N a_1, a_2, \cdots, a_N a 1 , a 2 , ⋯ , a N A A A
A = [ a 1 T a 2 T ⋮ a N T ] A = \begin{bmatrix} a_1^T \\ a_2^T \\ \vdots \\ a_N^T \end{bmatrix} A = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 T a 2 T ⋮ a N T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ 모든 점들과의 거리의 제곱의 합은 다음처럼 행렬의 놈으로 계산할 수 있다.
∑ i = 1 N ∥ a i ⊥ w ∥ 2 = ∑ i = 1 N ∥ a i ∥ 2 − ∑ i = 1 N ∥ a i ∥ w ∥ 2 = ∥ A ∥ 2 − ∑ i = 1 N ∥ a i ∥ w ∥ 2 \begin{aligned} \sum_{i=1}^N \Vert a_i^{\perp w}\Vert^2 &= \sum_{i=1}^N \Vert a_i\Vert^2 - \sum_{i=1}^N \Vert a^{\Vert w}_i\Vert^2 \\ &= \Vert A \Vert^2 - \sum_{i=1}^N \Vert a^{\Vert w}_i\Vert^2 \\ \end{aligned} i = 1 ∑ N ∥ a i ⊥ w ∥ 2 = i = 1 ∑ N ∥ a i ∥ 2 − i = 1 ∑ N ∥ a i ∥ w ∥ 2 = ∥ A ∥ 2 − i = 1 ∑ N ∥ a i ∥ w ∥ 2 행렬 A A A
∑ i = 1 N ∥ a i ∥ w ∥ 2 = ∑ i = 1 N ∑ k = 1 K ∥ ( a i T w k ) w k ∥ 2 = ∑ i = 1 N ∑ k = 1 K ∥ a i T w k ∥ 2 = ∑ k = 1 K w k T A T A w k \begin{aligned} \sum_{i=1}^N \Vert a^{\Vert w}_i\Vert^2 &= \sum_{i=1}^N \sum_{k=1}^K \Vert (a_i^Tw_k)w_k \Vert^2 \\ &= \sum_{i=1}^N \sum_{k=1}^K \Vert a_i^Tw_k \Vert^2 \\ &= \sum_{k=1}^K w_k^T A^TA w_k \\ \end{aligned} i = 1 ∑ N ∥ a i ∥ w ∥ 2 = i = 1 ∑ N k = 1 ∑ K ∥ ( a i T w k ) w k ∥ 2 = i = 1 ∑ N k = 1 ∑ K ∥ a i T w k ∥ 2 = k = 1 ∑ K w k T A T A w k 분산행렬의 고유분해를 사용하면
∑ k = 1 K w k T A T A w k = ∑ k = 1 K w k T V Λ V T w k = ∑ k = 1 K w k T ( ∑ i = 1 M σ i 2 v i v i T ) w k = ∑ k = 1 K ∑ i = 1 M σ i 2 ∥ v i T w k ∥ 2 \begin{aligned} \sum_{k=1}^K w_k^T A^TA w_k &= \sum_{k=1}^K w_k^T V \Lambda V^T w_k \\ &= \sum_{k=1}^K w_k^T \left( \sum_{i=1}^{M} \sigma^2_iv_iv_i^T \right) w_k \\ &= \sum_{k=1}^K \sum_{i=1}^{M}\sigma^2_i\Vert v_i^Tw_k\Vert^2 \\ \end{aligned} k = 1 ∑ K w k T A T A w k = k = 1 ∑ K w k T V Λ V T w k = k = 1 ∑ K w k T ( i = 1 ∑ M σ i 2 v i v i T ) w k = k = 1 ∑ K i = 1 ∑ M σ i 2 ∥ v i T w k ∥ 2 이 문제도 1차원 근사문제처럼 풀면 다음과 같은 답을 얻을 수 있다.
가장 큰 K K K
11. 랭크-K 근사문제
우리가 찾아야 하는 것은 이 값을 가장 크게 하는 K K K w k w_k w k 오른쪽 기저벡터 중 가장 큰 K K K
이 문제는 다음처럼 랭크-K K K
a i ∥ w = ( a i T w 1 ) w 1 + ( a i T w 2 ) w 2 + ⋯ + ( a i T w K ) w K = [ w 1 w 2 ⋯ w K ] [ a i T w 1 a i T w 2 ⋮ a i T w K ] = [ w 1 w 2 ⋯ w K ] [ w 1 T w 2 T ⋮ w K T ] a i = W W T a i \begin{aligned} a^{\Vert w}_i &= (a_i^Tw_1)w_1 + (a_i^Tw_2)w_2 + \cdots + (a_i^Tw_K)w_K \\ &= \begin{bmatrix} w_1 & w_2 & \cdots & w_K \end{bmatrix} \begin{bmatrix} a_i^Tw_1 \\ a_i^Tw_2 \\ \vdots \\ a_i^Tw_K \end{bmatrix} \\ &= \begin{bmatrix} w_1 & w_2 & \cdots & w_K \end{bmatrix} \begin{bmatrix} w_1^T \\ w_2^T \\ \vdots \\ w_K^T \end{bmatrix} a_i \\ &= WW^Ta_i \end{aligned} a i ∥ w = ( a i T w 1 ) w 1 + ( a i T w 2 ) w 2 + ⋯ + ( a i T w K ) w K = [ w 1 w 2 ⋯ w K ] ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a i T w 1 a i T w 2 ⋮ a i T w K ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = [ w 1 w 2 ⋯ w K ] ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ w 1 T w 2 T ⋮ w K T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ a i = W W T a i 이러한 투영벡터를 모아놓은 행렬 A ′ A' A ′
A ′ = [ ( a 1 ∥ w ) T ( a 2 ∥ w ) T ⋮ ( a N ∥ w ) T ] = [ a 1 T W W T a 2 T W W T ⋮ a N T W W T ] = [ a 1 T a 2 T ⋮ a N T ] W W T = A W W T A'= \begin{bmatrix} \left(a^{\Vert w}_1\right)^T \\ \left(a^{\Vert w}_2\right)^T \\ \vdots \\ \left(a^{\Vert w}_N\right)^T \end{bmatrix} = \begin{bmatrix} a_1^TW^{}W^T \\ a_2^TW^{}W^T\\ \vdots \\ a_N^TW^{}W^T \end{bmatrix} = \begin{bmatrix} a_1^T \\ a_2^T \\ \vdots \\ a_N^T \end{bmatrix} W^{}W^T = AW^{}W^T A ′ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ ( a 1 ∥ w ) T ( a 2 ∥ w ) T ⋮ ( a N ∥ w ) T ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 T W W T a 2 T W W T ⋮ a N T W W T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ a 1 T a 2 T ⋮ a N T ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ W W T = A W W T 따라서 이 문제는 원래 행렬 A A A W W T W_{}W^T W W T A A A A ′ A' A ′
arg min w 1 , ⋯ , w K ∥ A − A W W T ∥ \arg\min_{w_1,\cdots,w_K} \Vert A - AW^{}W^T \Vert arg w 1 , ⋯ , w K min ∥ A − A W W T ∥ ※ 출처
김도형의 데이터 사이언스스쿨 중 3.4 특잇값 분해