벡터와 행렬도 숫자처럼 덧셈, 뺄셈, 곱셈 등의 연산을 할 수 있다. 벡터와 행렬의 연산을 이용하면 대량의 데이터에 대한 계산을 간단한 수식으로 나타낼 수 있다. 물론 벡터와 행렬에 대한 연산은 숫자의 사칙 연산과는 몇 가지 다른 점이 있으므로 이러한 차이를 잘 알아야 한다.
[목차]
1. 벡터(or행렬)의 덧셈과 뺄셈
2. 스칼라와 벡터(or행렬)의 곱셈 :브로드캐스팅, 선형조합
3. 벡터간 곱셈 : ex> 가중합, 가중평균, 유사도, 선형회귀모형, 제곱합
4. 행렬간 곱셈 : 교환법칙, 분배법칙, 결합법칙, 항등행렬의 곱셈
5. 행렬과 벡터의 곱셈: ex> 열벡터의 선형조합, 잔차 (※잔차제곱합), 이차형식
1. 벡터/행렬의 덧셈과 뺄셈
같은 크기를 가진 두 개의 벡터나 행렬은 덧셈과 뺄셈을 할 수 있다. 두 벡터와 행렬에서 같은 위치에 있는 원소끼리 덧셈과 뺄셈을 하면 된다. 이러한 연산을 요소별(element-wise) 연산이라고 한다.
예를 들어 벡터 x와 y가 다음과 같으면,
x=⎣⎢⎡101112⎦⎥⎤,y=⎣⎢⎡012⎦⎥⎤
벡터 x와 y의 덧셈 x+y와 뺄셈 x−y는 다음처럼 계산한다.
x+y=⎣⎢⎡101112⎦⎥⎤+⎣⎢⎡012⎦⎥⎤=⎣⎢⎡10+011+112+2⎦⎥⎤=⎣⎢⎡101214⎦⎥⎤
x−y=⎣⎢⎡101112⎦⎥⎤−⎣⎢⎡012⎦⎥⎤=⎣⎢⎡10−011−112−2⎦⎥⎤=⎣⎢⎡101010⎦⎥⎤
2. 스칼라와 벡터/행렬의 곱셈
벡터 x 또는 행렬 A에 스칼라값 c를 곱하는 것은 벡터 x 또는 행렬 A의 모든 원소에 스칼라값 c를 곱하는 것과 같다.
c[x1x2]=[cx1cx2]
c[a11a21a12a22]=[ca11ca21ca12ca22]
브로드캐스팅
원래 덧셈과 뺄셈은 크기(차원)가 같은 두 벡터에 대해서만 할 수 있다. 하지만 벡터와 스칼라의 경우에는 관례적으로 다음처럼 1-벡터를 사용하여 스칼라를 벡터로 변환한 연산을 허용한다. 이를 브로드캐스팅(broadcasting)이라고 한다.
⎣⎢⎡101112⎦⎥⎤−10=⎣⎢⎡101112⎦⎥⎤−10⋅1=⎣⎢⎡101112⎦⎥⎤−⎣⎢⎡101010⎦⎥⎤
데이터 분석에서는 원래의 데이터 벡터 x가 아니라 그 데이터 벡터의 각 원소의 평균값을 뺀 평균제거(mean removed) 벡터 혹은 0-평균(zero-mean) 벡터를 사용하는 경우가 많다.
x=⎣⎢⎢⎢⎢⎡x1x2⋮xN⎦⎥⎥⎥⎥⎤→x−m=⎣⎢⎢⎢⎢⎡x1−mx2−m⋮xN−m⎦⎥⎥⎥⎥⎤
위 식에서 m은 샘플 평균이다.
m=N1i=1∑Nxi
선형조합
벡터/행렬에 다음처럼 스칼라값을 곱한 후 더하거나 뺀 것을 벡터/행렬의 선형조합(linear combination)이라고 한다. 벡터나 행렬을 선형조합해도 크기는 변하지 않는다.
c1x1+c2x2+c3x3+⋯+cLxL=x
c1A1+c2A2+c3A3+⋯+cLAL=A
c1,c2,…,cL∈R
x1,x2,…,xL,x∈RM
A1,A2,…,AL,A∈RM×N
벡터나 행렬의 크기를 직사각형으로 표시하면 다음과 같다.
c1x1+c2x2+⋯+cLxL
c1A1+c2A2+⋯+cLAL
3. 벡터와 벡터의 곱셈
행렬의 곱셈을 정의하기 전에 우선 두 벡터의 곱셈을 알아보자. 벡터를 곱셈하는 방법은 여러 가지가 있지만 여기서는 내적(inner product)에 대해서만 다룬다. 벡터 x와 벡터 y의 내적은 다음처럼 표기한다.
내적은 다음처럼 점(dot)으로 표기하는 경우도 있어서 닷 프로덕트(dot product)라고도 부르고 < x,y > 기호로 나타낼 수도 있다.
x⋅y=<x,y>=xTy
두 벡터를 내적하려면 다음과 같은 조건이 만족되어야 한다.
- 우선 두 벡터의 차원(길이)이 같아야 한다.
- 앞의 벡터가 행 벡터이고 뒤의 벡터가 열 벡터여야 한다.
이때 내적의 결과는 스칼라값이 되며 다음처럼 계산한다. 우선 같은 위치에 있는 원소들을 요소별 곱셈처럼 곱한 다음, 그 값들을 다시 모두 더해서 하나의 스칼라값으로 만든다.
xTy=[x1x2⋯xN]⎣⎢⎢⎢⎢⎡y1y2⋮yN⎦⎥⎥⎥⎥⎤=x1y1+⋯+xNyN=i=1∑Nxiyi
x∈RN×1
y∈RN×1
xTy∈R
다음은 두 벡터의 내적의 예다.
x=⎣⎢⎡123⎦⎥⎤,y=⎣⎢⎡456⎦⎥⎤
xTy=[123]⎣⎢⎡456⎦⎥⎤=1⋅4+2⋅5+3⋅6=32
넘파이에서 벡터와 행렬의 내적은 dot()이라는 명령 또는 @(at이라고 읽는다)이라는 연산자로 계산한다. 2차원 배열로 표시한 벡터를 내적했을 때는 결과값이 스칼라가 아닌 2차원 배열이다.
x = np.array([[1], [2], [3]])
y = np.array([[4], [5], [6]])
x.T @ y
array([[32]])
넘파이에서는 1차원 배열끼리도 내적을 계산한다. 이때는 넘파이가 앞의 벡터는 행 벡터이고 뒤의 벡터는 열 벡터라고 가정한다.
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
x @ y
왜 벡터의 내적은 덧셈이나 뺄셈과 달리 이렇게 복잡하게 정의된 것일까? 그 이유는 데이터 분석을 할 때 이러한 연산이 필요하기 때문이다. 벡터의 내적을 사용하여 데이터를 분석하는 몇 가지 예를 살펴보자.
1. 가중합
벡터의 내적은 가중합을 계산할 때 쓰일 수 있다. 가중합(weighted sum)이란 복수의 데이터를 단순히 합하는 것이 아니라 각각의 수에 어떤 가중치 값을 곱한 후 이 곱셈 결과들을 다시 합한 것을 말한다.
만약 데이터 벡터가 x=[x1,⋯,xN]T이고 가중치 벡터가 w=[w1,⋯,wN]T이면 데이터 벡터의 가중합은 다음과 같다.
w1x1+⋯+wNxN=i=1∑Nwixi
이 값을 벡터 x와 w의 곱으로 나타내면 wTx 또는 xTw 라는 간단한 수식으로 표시할 수 있다.
i=1∑Nwixi=[w1w2⋯wN]⎣⎢⎢⎢⎢⎡x1x2⋮xN⎦⎥⎥⎥⎥⎤=[x1x2⋯xN]⎣⎢⎢⎢⎢⎡w1w2⋮wN⎦⎥⎥⎥⎥⎤=wTx=xTw
예를 들어 쇼핑을 할 때 각 물건의 가격은 데이터 벡터, 각 물건의 수량은 가중치로 생각하여 내적을 구하면 총금액을 계산할 수 있다.
만약 가중치가 모두 1이면 일반적인 합(sum)을 계산한다.
w1=w2=⋯=wN=1
또는
w=1N
이면
i=1∑Nxi=1NTx
연습 문제 2.2.1
A, B, C 세 회사의 주식은 각각 100만원, 80만원, 50만원이다. 이 주식을 각각 3주, 4주, 5주를 매수할 때 필요한 금액을 구하고자 한다.
(1) 주식의 가격과 수량을 각각 p 벡터, n 벡터로 표시하고 넘파이로 코딩한다.
(2) 주식을 매수할 때 필요한 금액을 곱셈으로 표시하고 넘파이 연산으로 그 값을 계산한다.
2. 가중평균
가중합의 가중치값을 전체 가중치값의 합으로 나누면 가중평균(weighted average)이 된다. 가중평균은 대학교의 평균 성적 계산 등에 사용할 수 있다.
예를 들어 고등학교에서는 국어, 영어, 두 과목의 평균 점수를 구할 때 단순히 두 과목의 점수(숫자)를 더한 후 2으로 나눈다. 그러나 대학교에서는 중요한 과목과 중요하지 않는 과목을 구분하는 학점(credit)이라는 숫자가 있다. 일주일에 한 시간만 수업하는 과목은 1학점짜리 과목이고 일주일에 세 시간씩 수업하는 중요한 과목은 3학점짜리 과목이다. 1학점과 3학점 과목의 점수가 각각 100점, 60점이면 학점을 고려한 가중 평균(weighted average) 성적은 다음과 같이 계산한다.
1+31×100+1+33×60=70
벡터로 표현된 N개의 데이터의 단순 평균은 다음처럼 생각할 수 있다.
xˉ=N1i=1∑Nxi=N11NTx
위 수식에서 보인 것처럼 x 데이터의 평균은 보통 xˉ라는 기호로 표기하고 "엑스 바(x bar)" 라고 읽는다.
다음은 넘파이로 평균을 계산하는 방법이다.
x = np.arange(10)
N = len(x)
np.ones(N) @ x / N
4.5
3. 유사도
벡터의 곱셈(내적)은 두 벡터 간의 유사도를 계산하는 데도 이용할 수 있다. 유사도(similarity)는 두 벡터가 닮은 정도를 정량적으로 나타낸 값으로 두 벡터가 비슷한 경우에는 유사도가 커지고 비슷하지 않은 경우에는 유사도가 작아진다. 내적을 이용하면 코사인 유사도(cosine similarity)라는 유사도를 계산할 수 있다.
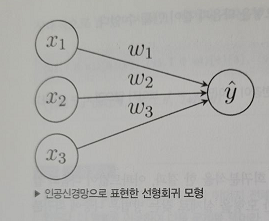
4. 선형회귀 모형
선형회귀 모형(linear regression model)이란 독립변수 x에서 종속변수 y를 예측하는 방법의 하나로 독립변수 벡터 x와 가중치 벡터 w와의 가중합으로 y에 대한 예측값 y^를 계산하는 수식을 말한다.
y^=w1x1+⋯+wNxN
이 수식에서 기호 ^는 "캐럿(caret)"이라는 기호이다. y^는 "와이 햇(y hat)"이라고 읽는다.
이 수식은 다음처럼 벡터의 내적으로 나타낼 수 있다.
y^=wTx
선형회귀 모형은 가장 단순하면서도 가장 널리 쓰이는 예측 모형이다.
예를 들어 어떤 아파트 단지의 아파트 가격을 조사하였더니 아파트 가격은 (1)면적, (2)층수, (3)한강이 보이는지의 여부, 즉 이 세 가지 특징에 의해 달라진다는 사실을 알게 되었다. 이때 이 단지 내의 아파트 가격을 예측하는 예측 모형을 다음과 같이 만들 수 있다.
- 면적(m2)을 입력 데이터 x1라고 한다.
- 층수를 입력 데이터 x2라고 한다
- 한강이 보이는지의 여부를 입력 데이터 x3라고 하며 한강이 보이면 x3=1, 보이지 않으면 x3=0이라고 한다.
- 출력 데이터 y^는 해당 아파트의 예측 가격이다.
위와 같이 입력 데이터와 출력 데이터를 정의하고 회귀분석을 한 결과, 아파트값이 다음과 같은 선형회귀 모형으로 나타난다고 가정하자. 이러한 모형을 실제로 찾는 방법은 나중에 회귀분석 파트에서 공부하게 된다.
y^=500x1+200x2+1000x3
이 모형은 다음과 같이 해석할 수 있다.
- 면적이 1m2 증가할수록 가격은 500만 원이 증가한다.
- 층수가 1층 높아질수록 가격은 200만 원이 증가한다.
- 한강이 보이는 집은 1,000만 원의 웃돈(프리미엄)이 존재한다.
위 식은 다음과 같이 벡터의 내적으로 고쳐 쓸 수 있다.
y^=[5002001000]⎣⎢⎡x1x2x3⎦⎥⎤=wTx
즉, 위 선형회귀 모형은 다음 가중치 벡터로 대표된다.
wT=[5002001000]
인공신경망(artificial neural network)에서는 선형회귀 모형을 다음과 같은 그림으로 표현한다. 데이터는 노드(node) 혹은 뉴런(neuron)이라는 동그라미로 표시하고 곱셈은 선분(line)위에 곱할 숫자를 써서 나타낸다. 덧셈은 여러 개의 선분이 만나는 것으로 표시한다.
선형회귀 모형의 단점
선형회귀 모형은 비선형적인 현실 세계의 데이터를 잘 예측하지 못할 수 있다는 단점이 있다. 예를 들어 집값은 면적에 단순 비례하지 않는다. 소형 면적의 집과 대형 면적의 집은 단위 면적당 집값의 증가율이 다를 수 있다. 또한 저층이 보통 고층보다 집값이 싸지만 층수가 올라갈수록 정확히 층수에 비례하여 가격이 증가하지도 않는다.
이러한 현실 세계의 데이터와 선형회귀 모형의 괴리를 줄이기 위해 선형회귀 모형이 아닌 완전히 다른 모형을 쓰기보다는 선형회귀 모형을 기반으로 여러 기법을 사용해 수정한 모형을 사용하는 것이 일반적이다. 이러한 수정 선형회귀 모형에 대해서는 나중에 공부하게 된다.
5. 제곱합
데이터의 분산(variance)이나 표준 편차(standard deviation) 등을 구하는 경우에는 각각의 데이터를 제곱한 뒤 이 값을 모두 더한 제곱합(sum of squares)을 계산해야 한다. 이 경우에도 벡터의 내적을 사용하여 xTx로 쓸 수 있다.
xTx=[x1x2⋯xN]⎣⎢⎢⎢⎢⎡x1x2⋮xN⎦⎥⎥⎥⎥⎤=i=1∑Nxi2
4. 행렬과 행렬의 곱셈
벡터의 곱셈을 정의한 후에는 이를 이용하여 행렬의 곱셈을 정의할 수 있다. 행렬과 행렬을 곱하면 행렬이 된다. 방법은 다음과 같다.
A 행렬과 B 행렬을 곱한 결과가 C 행렬이 된다고 하자.
C의 i번째 행, j번째 열의 원소 cij의 값은 A 행렬의 i번째 행 벡터 aiT와 B 행렬의 j번째 열 벡터 bj의 곱이다.
C=AB→cij=aiTbj
이 정의가 성립하려면 앞의 행렬 A의 열의 수가 뒤의 행렬 B의 행의 수와 일치해야만 한다.
A∈RN×L,B∈RL×M→AB∈RN×M
다음은 4×3 행렬과 3×2을 곱하여 4×2을 계산하는 예다.
⎣⎢⎢⎢⎡a11a21a31a41a12a22a32a42a13a23a33a43⎦⎥⎥⎥⎤⎣⎢⎡b11b21b31b12b22b32⎦⎥⎤=⎣⎢⎢⎢⎡(a11b11+a12b21+a13b31)(a21b11+a22b21+a23b31)(a31b11+a32b21+a33b31)(a41b11+a42b21+a43b31)(a11b12+a12b22+a13b32)(a21b12+a22b22+a23b32)(a31b12+a32b22+a33b32)(a41b12+a42b22+a43b32)⎦⎥⎥⎥⎤
다음은 실제 행렬을 사용한 곱셈의 예다.
A=[142536]
B=⎣⎢⎡135246⎦⎥⎤
C=AB=[22492864]
넘파이를 이용하여 행렬의 곱을 구할 때도 @ 연산자 또는 dot() 명령을 사용한다.
인공신경
위 그림을 행렬식으로 표현하면 다음과 같다.
[y^1y^2]=[w11w21w12w22w13w23]⎣⎢⎡x1x2x3⎦⎥⎤
교환법칙과 분배법칙
행렬의 곱셈은 곱하는 행렬의 순서를 바꾸는 교환 법칙이 성립하지 않는다. 그러나 덧셈에 대한 분배법칙은 성립한다.
A(B+C)=AB+AC
(A+B)C=AC+BC
A, B, C가 다음과 같을 때 위 법칙을 넘파이로 살펴보자.
A=[1324]
B=[5768]
C=[9786]
전치 연산도 마찬가지로 덧셈/뺄셈에 대해 분배 법칙이 성립한다.
(A+B)T=AT+BT
전치 연산과 곱셈의 경우에는 분배법칙이 성립하기는 하지만 전치 연산이 분배되면서 곱셈의 순서가 바뀐다.
(AB)T=BTAT
(ABC)T=CTBTAT
마찬가지로 넘파이로 위 법칙이 성립하는지 살펴보자.
결합법칙: 곱셈의 연결
연속된 행렬의 곱셈은 계산 순서를 임의의 순서로 해도 상관없다.
ABC=(AB)C=A(BC)
ABCD=((AB)C)D=(AB)(CD)=A(BCD)=A(BC)D
항등행렬의 곱셈
어떤 행렬이든 항등행렬을 곱하면 그 행렬의 값이 변하지 않는다.
AI=IA=A
넘파이로 다음과 같이 확인한다.
5. 행렬과 벡터의 곱
그럼 이러한 행렬의 곱셈은 데이터 분석에서 어떤 경우에 사용될까? 행렬의 곱셈 중 가장 널리 쓰이는 것은 다음과 같은 형태의 행렬 M과 벡터 v의 곱이다.
벡터와 행렬의 크기를 직사각형으로 표시하면 다음과 같다.
c1x1+c2x2+⋯+cLxL
Mv=Mv
행렬과 벡터의 곱을 사용하는 몇가지 예를 살펴보자.
1. 열 벡터의 선형조합
벡터의 크기를 직사각형으로 표시하면 다음과 같다.
행렬 X와 벡터 w의 곱은 행렬 X를 이루는 열벡터 c1,c2,…,cM을 뒤에 곱해지는 벡터 w의 각 성분 w1,w2,…,wM으로 선형조합(linear combination)을 한 결과 벡터와 같다.
Xw=[c1c2⋯cM]⎣⎢⎢⎢⎢⎡w1w2⋮wM⎦⎥⎥⎥⎥⎤=w1c1+w2c2+⋯+wMcM
벡터의 크기를 직사각형으로 표시하면 다음과 같다.
c1+,c2+⋯+cM
c1+,c2+⋯+cM⎣⎢⎢⎢⎢⎡w1w2⋮wM⎦⎥⎥⎥⎥⎤=w1c1+w2c2+⋯+wMcM
2. 잔차
선형 회귀분석(linear regression)을 한 결과는 가중치 벡터 w라는 형태로 나타나고 예측치는 이 가중치 벡터를 사용한 독립변수 데이터 레코드 즉, 벡터 xi의 가중합 wTxi이 된다고 했다. 예측치와 실젯값(target) yi의 차이를 오차(error) 혹은 잔차(residual) ei라고 한다. 이러한 잔찻값을 모든 독립변수 벡터에 대해 구하면 잔차 벡터 e가 된다.
ei=yi−y^i=yi−wTxi
잔차 벡터는 다음처럼 y−Xw로 간단하게 표기할 수 있다.
e=⎣⎢⎢⎢⎢⎡e1e2⋮eM⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡y1y2⋮yM⎦⎥⎥⎥⎥⎤−⎣⎢⎢⎢⎢⎡x1Twx2Tw⋮xMTw⎦⎥⎥⎥⎥⎤=y−Xw
잔차 제곱합
잔차의 크기는 잔차 벡터의 각 원소를 제곱한 후 더한 잔차 제곱합(RSS: Residual Sum of Squares)을 이용하여 구한다. 이 값은 eTe로 간단하게 쓸 수 있으며 그 값은 다음처럼 계산한다.
i=1∑Nei2=i=1∑N(yi−wTxi)2=eTe=(y−Xw)T(y−Xw)
3. 이차형식
위의 연습 문제에서 마지막 항은 wTXTXw라는 형태다. 이 식에서 XTX는 정방행렬이 되므로 이 정방행렬을 A라고 이름 붙이면 마지막 항은 wTAw와 같은 형태가 된다.
벡터의 이차형식(Quadratic Form)이란 이처럼 어떤 벡터와 정방행렬이 '행벡터 × 정방행렬 × 열벡터'의 형식으로 되어 있는 것을 말한다.
이 수식을 풀면 i=1,…,N,j=1,…,N에 대해 가능한 모든 i,j 쌍의 조합을 구한 다음 i, j에 해당하는 원소 xi, xj를 가중치 ai,j와 같이 곱한 값 ai,jxixj의 총합이 된다.
xTAx=[x1x2⋯xN]⎣⎢⎢⎢⎢⎡a1,1a2,1⋮aN,1a1,2a2,2⋮aN,2⋯⋯⋱⋯a1,Na2,N⋮aN,N⎦⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎡x1x2⋮xN⎦⎥⎥⎥⎥⎤=i=1∑Nj=1∑Nai,jxixj
※ 출처
김도형의 데이터 사이언스스쿨 중 2.2 벡터와 행렬의 연산
