
1. Deep Learning 이전의 LNP
Bag-of-Words
Bag-of-words는 단어들의 관계가 아니라 등장 빈도(frequency)에 기반하여 텍스트를 데이터화 하는 방법입니다.
이 방법은 크게 2가지 단계로 구성됩니다.
1단계) 사전(Vocabulary) 구축
텍스트 데이터 셋에서 unique한 단어만 모아 vocabulary을 구축합니다.
예를 들어 "I really really like DL"이라는 문장이 있다면 중복되는 단어는 한 번만 수집되도록 V = {I, really, like, DL}이라는 vocabulary를 생성합니다.
2단계) one-hot-vector로 표기
Vocabulary의 size(포함된 단어의 수)가 n개 라면, 각각의 단어는 n차원 벡터로 표현할 수 있습니다.
위의 예시 문장은
[1000]+2*[0100]+[0010]+[0001]=[1211]
따라서 [1211]이라는 벡터로 표현할 수 습니다.
one-hot vector에서 각 단어는 거리가 항상 sqrt(2),
cosine similarity는 항상 0이 됩니다.
NaiveBayes Classifier
NaiveBayes Classifier는 Bag-of-Words로 구성된 텍스트 데이터를 분류 할 수 있는 기법 중 하나입니다.
d라는 문서가 C개의 분류(정치, 경제, 스포츠, 연예 등) 중 하나에 속할 확률로 구체적인 계산식은 아래와 같습니다. 여기서 P(d)는 문서 d가 선택될 확률을 의미하기 때문에 문서 하나를 고정할 경우 생략 가능합니다.
여기서 P(d)는 문서 d가 선택될 확률을 의미하기 때문에 문서 하나를 고정할 경우 생략 가능합니다.
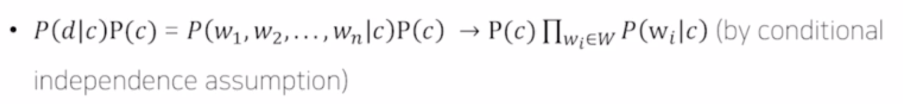 문서 안에 각 단어들이 서로 독립적이라면, 문서 d가 c로 분류될 확률은 전체 문서중에서 해당 class인 문서가 등장할 확률과 해당 class에서 문서 d를 구성하는 각 단어들이 등장할 확률의 곱과 같습니다.
문서 안에 각 단어들이 서로 독립적이라면, 문서 d가 c로 분류될 확률은 전체 문서중에서 해당 class인 문서가 등장할 확률과 해당 class에서 문서 d를 구성하는 각 단어들이 등장할 확률의 곱과 같습니다.
예를 들어 조간 신문에서 특정 기사가 정치 카테고리로 분류될 확률은,
그 신문 중 정치 카테고리 기사가 등장할 확률과 해당 기사에서 등장하는 단어들이 정치 카테고리로 분류될 확률을 종합적(곱셈)으로 검토하여 추정할 수 있습니다.
이런 확률 추정 방식은 MLE(Maximum Likelihood Estimation) 방식을 기반으로 추정되기 때문에 자세한 이론은 MLE에서 배울 수 있습니다.
2. Word Embedding
Word Embedding은 단어를 벡터로 변환하는 기법을 말합니다.
사실 Word Embedding 자체도 DL, ML 기법으로, 비슷한 의미를 갖는 단어가 좌표공간 속에서 가까운 위치에 있도록 하고, 서로 다른 단어는 멀리 위치하도록 배치할 수 있어야 합니다.
Word2Vec
가장 대표적인 word embedding 기법으로,
같은 문장에 나타난 단어들이 서로 의미적 관련성이 높은 것으로 분류합니다.
즉, 한 단어를 중심으로 주변 단어를 숨겼을 때 특정 단어가 해당 자리에 나타날 확률을 예측한다고 볼 수 있습니다.
Word2Vec은 다음과 같은 순서로 제작합니다.
1) 입출력 단어 쌍 만들기
one-hot vector 를 만든 뒤, sliding window 기법으로 한 단어의 앞뒤 단어를 묶어 입출력 단어 쌍을 구성합니다.
"I study DL" 라는 문장에 window size가 1로 정해졌다면
(I, study), (study, I), (study, DL), (DL, study)라는 단어 쌍을 구성할 수 있습니다.
2) 예측 task
위와 같은 단어쌍에 대해 예측 task를 수행하는 NN 제작합니다.
단어 데이터를 분석하여 빈칸에 들어갈 단어를 예측해야하기 때문에 입출력 레이어의 노드 수는 당연히 단어 벡터의 차원과 같습니다.
hidden layer의 노드 수는 사용자가 정하는 hyperparameter로 word embedding을 수행하는 차원수와 동일합니다.
"I study DL"를 분석하는 2 layer NN(hidden layer는 2차원)는 다음과 같습니다.
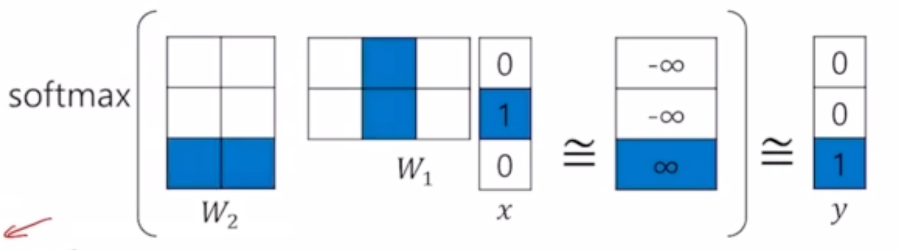
3) 학습 과정
최종 출력값은 soft max를 통과하여 3차원의 확률분포로 변환되고, ground truth와 output의 확률 분포가 서로 가까워지게 하는 방향으로 hidden layer(W1, W2)를 학습하게 됩니다.
GloVe
Word2Vec과 더불어 가장 많이 쓰이는 Word Embedding 방법입니다.
Word2Vec과 차이점
GlovVe는 학습 데이터에서 각 입출력쌍이 한 윈도우 내에 몇 번 동시에 등장하는지를 사전에 계산합니다.
이때, 입출력 단어 벡터 간의 내적값이 log(동시 등장 횟수)에 가까워지도록 loss function 사용하여 학습합니다.
반면, Word2Vec은 동시에 많이 등장하는 단어쌍이 많이 학습되게 구성되어 있습니다.
GloVe에서는 동시 등장 횟수를 미리 계산하여 내적값과 비교하기 때문에 중복 학습을 줄여주고, 따라서 Word2Vec에 비해 상대적으로 학습이 빠르게 진행되고, 적은 데이터에서도 더 잘 작동합니다.

많은 것을 배웠습니다, 감사합니다.