Paper Review
1.[논문 리뷰] Learning Transferable Visual Models From Natural Language Supervision
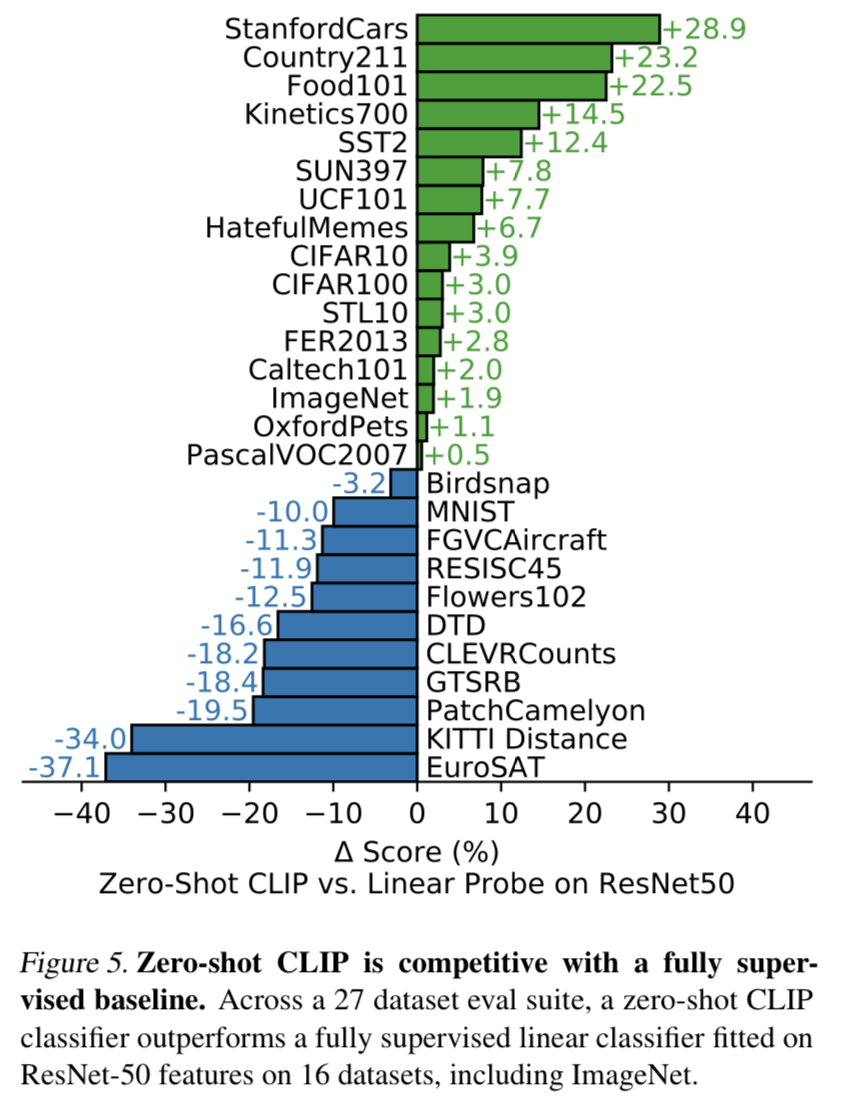
Abstract 기존 CV 분야의 SOTA 모델은 사전에 정의된 object categories들의 데이터셋만을 예측하도록 학습되었다. 이러한 supervised 부분이 generality와 usability를 제한한다. 추가적인 labeled data가 필요하기
2023년 8월 6일