Abstract
-
기존 CV 분야의 SOTA 모델은 사전에 정의된 object categories들의 데이터셋만을 예측하도록 학습되었다.
- 이러한 supervised 부분이 generality와 usability를 제한한다. 추가적인 labeled data가 필요하기 때문이다.
-
이미지에 대해 텍스트로 바로 학습하는 방법이 더 유용할 것이다.
- 4억개의 데이터셋으로 caption과 이미지 간 예측하는 사전학습 방법을 통해 SOTA image representation을 학습하는데 효과적이었다.
- 사전학습 이후, natural language로 학습된 visual concepts를 reference해 모델의 zero-shot transfer를 가능하게 해주었다.
-
30개가 넘는 CV, OCR, 영상 인식 등의 task들에서 fully supervised 방식만큼 좋은 성능을 보였다.
1. Introduction and Motivating Work
-
텍스트로부터 바로 학습을 하는 사전학습 방법은 NLP에서 오랜 시간 발전해왔다.
- autoregressive나 maksked language modeling과 같은 task- agnostic objectives는 성능을 꾸준히 향상시켜왔다.
- "text-to-text"의 발전은 zero-shot transfer를 가능케했고, 이는 specific한 dataset의 customization없이도 task를 해결할 수 있게 해주었다.
- GPT3는 specific한 training data 없이도 다양한 task에서 경쟁력을 지닌다.
-
이러한 결과는, NLP에서는 lable이 있는 데이터에 대해 학습하는 것보다 대용량의 사전학습모델로 학습하는 것이 더 좋은 성능을 갖는다는 것을 의미한다.
- 하지만 아직 CV 분야에서는 ImageNet처럼 label이 있는 데이터셋에대해 사전학습 모델을 적용하고 있어서 CV 분야에서도 scalable 사전학습 방식이 통할지 봐야한다.
-
weakly supervised 모델과, 최근 연구중인 텍스트로부터 이미지 바로 학습하는 모델의 주요한 차이점은 'Scale' 이다.
- CLIP은 4억 개의 이미지 - 텍스트(caption) pair로 대규모 학습을 진행하였고, 여러 task, 특히 zero-shot transfer에서 기존 transformer language 모델이나 Bag of words 베이스라인 모델보다 훨씬 향상된 성능을 보였다.
- CLIP은 성능이 뛰어날 뿐만 아니라 computational cost도 효율적이고, zeo-shot CLIP 모델은 여타 모델보다 robustness도 뛰어나다.
- CLIP은 4억 개의 이미지 - 텍스트(caption) pair로 대규모 학습을 진행하였고, 여러 task, 특히 zero-shot transfer에서 기존 transformer language 모델이나 Bag of words 베이스라인 모델보다 훨씬 향상된 성능을 보였다.
2. Approach
2.1. Natural Language Supervision
-
CLIP은 natural language를 supervision으로 학습한다. 기존에도 이미지
-
텍스트 pair로 visual representation을 학습한 여러 연구가 있었지만, 이들은 모두 unsupervised, self-supervised, weakly supervised, supervised 등 다르게 표현하였다.
-
natural language로부터 바로 학습하는 것은 다른 training 방식에 비해 별도의 번거로운 labeling 작업이 필요 없어 scaling하기가 수월하다.
-
추가로, 이미지 뿐만 아니라 natural language 까지의 연결해서 Representation learning이 가능하며, 다른 task로도 유연한 zero-shot transfer가 가능하다.
2.2. Creating a Sufficiently Large Dataset
-
기존 연구에서는 3가지 데이터셋을 사용했다.
1. MS-COCO
2. Visual Genome
3. YFCC100M -
MS-COCO, Visual Genome은 품질은 좋으나 그 양이 매우 적고, YFCC100M은 각 이미지에 대한 메타 데이터가 부족하고 품질이 모두 다르다.
-
기존의 데이터셋이 인터넷 상의 수많은 데이터를 따라가지 못하기에 해당 연구에서는 WIT(WebImageText)라는 4억개의 이미지, 텍스트 pair 데이터셋을 구축했다.
2.3. Selecting an Efficient Pre-Training Method
-
기존 SOTA CV 시스템은 computation 비용이 매우 컸다.
-
해당 논문에서는 초기 연구에서 VirTex와 유사하게 image CNN과 text transformer를 처음부터 함께 훈련해 이미지의 caption을 예측하게끔 했다. 하지만 이 방법으로는 파라미터가 6300만개로, 너무 많아 효율적으로 scaling하기가 힘들었다. 간단한 bag-of- words 모델보다 3배나 느렸다.
- 이 방법은 이미지에서 정확한(exact) 단어를 예측하려고 하는데, 이는 이미지의 descriptions, comments, related text의 wide variaty함 때문에 어렵다.
-
constrastive 방식이 predictive 방식보다 representations를 학습하는 데 있어 더 낫다는 것이 최근 밝혀졌다.
-
해당 연구에서는 단어 하나만이 아니라 '텍스트 전체(text as a whole)'를 이미지와 짝지어 학습하였다.
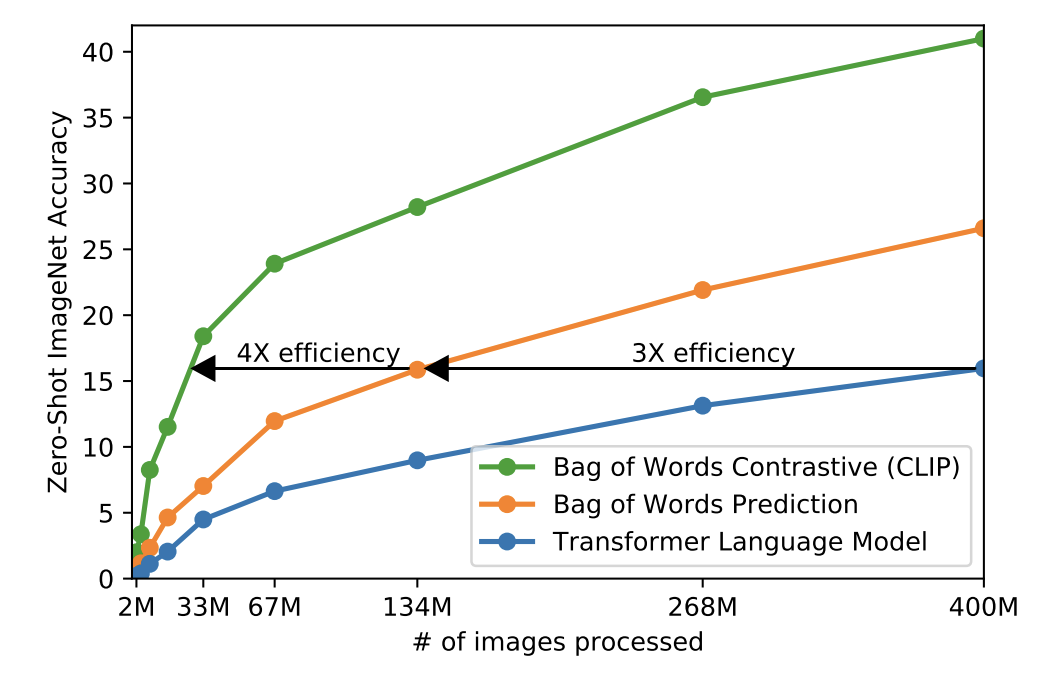
- 같은 bag-of-words baseline에서 predictive objective를 contrastive objective로 변경하는 것 만으로 zero-shot transfer에서 4배의 efficiency 개선을 이루어냈다.
-
모델 구조
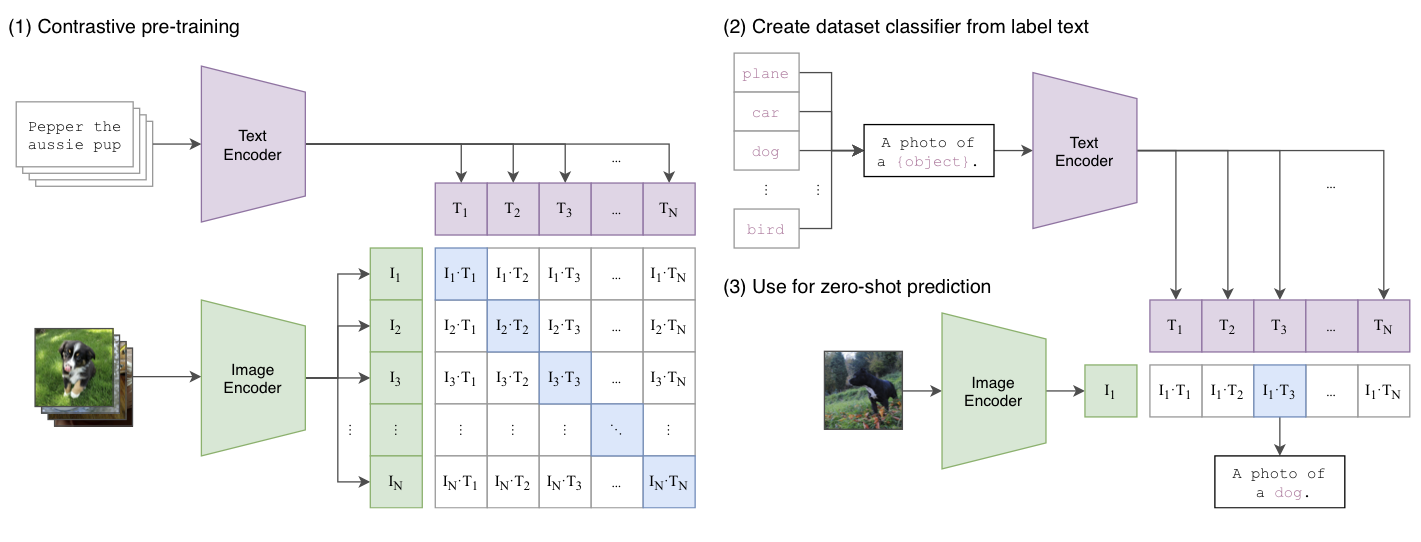
- 하나의 batch는 N개의 (이미지-텍스트) 쌍(pair)으로 이루어진다. 전체는 따라서 N x N개의 쌍이 생기고, 각각에 대해 학습이 이루어진다.
- N 개의 쌍을 모든 i,j에 대해서 비교하면 N개의 positive pair (그림에서의 파란색 부분)와 N^2-N 개의 negative pair를 얻을 수 있다.
- image encoder와 text encdoer를 함께 공통된 multi-modal embedding space에서 함께 학습하는데, 위의 positive pair에 대해서는 코사인 similarity를 최대화하고, negative pair에 대해서는 최소화하는 방향으로 학습을 진행한다.
- 이 유사도 점수들에 대해 symmetric cross entropy loss를 optimize한다.
- pesudo code

-
큰 size의 pretrained-trainig 데이터셋을 사용하기 때문에 overfitting 문제가 중요한데, 이를 해결하기 위해서 CLIP을 학습할 때 image encoder는 ImageNet weights를 사용하지 않았고, text encoder는 pre-trained weights를 사용하지 않고 initialize하였다.
- representation과 contrastive embedding space 사이에 non-linear projection을 사용하지 않고 linear pojection만을 사용해 encoder의 representation을 multi-modal embedding space에 매핑시켰다.
-
학습 과정에서 data augementation에 있어서는 random square crop만 사용하였다.
-
softmax의 logits의 범위를 조절해주는 temperature parameter τ를 optimize해주어 log-parmeterized multiplicative scalar가 하이퍼파라미터로 튜닝되는 것을 방지해주었다.
2.4. Choosing and Scaling a Model
- image encoder 부분에서, 2 종류의 architecture를 고려했다.
1) Res-Net-50에서 일부를 수정한 ResNet-D를 사용했고, global average pooling layer를 attention pooling으로 대체했다.
2) Vision Transformer(ViT)를 이용하는데, additional layer normlaizaiton을 추가했다. - text encoder 부분에서는 Transformer를 사용했고, lower-cased BPE representation을 이용했다.
- Masked self-attention은 사용하지 않았다.
- 기존 CV 연구에서는 모델을 width와 depth를 증가시켜 scale했던 반면 해당 연구에서는 그러한 방식이 오직 모델의 한 차원에서만 작동한다는 점에서 그 방식을 택하지 않았다고 한다.
- text encoder에 대해, 모델의 width만을 scale하고 depth는 scale하지 않았다. CLIP의 성능은 text encoder의 capacity에 덜 민감하기 때문이다.
2.5. Training
- 5개의 ResNet, 3개의 Vision Transformer로 학습했다.
- ResNet: ResNet-50, ResNet-101, EfficientNet의 모델 3개(ResNet-50의 4배, 16배, 64배에 해당)
- Vision Transformer: ViT-B/32, ViT-B/16, ViT-L/14
- 전부 32 epoch으로 학습시켰고, optimizer는 Adam을 사용, scheduler는 cosine scheduler를 사용해 learning rate를 감소시켰다.
- 초기 하이퍼파라미터는 그리드서치, 랜덤서치를 혼합하여 사용해 세팅했다.
- 이후 하이퍼파라미터는 computational constraints에 맞추어 모델에 맞게 휴리스틱하게 맞추었다.
- temperature parameter τ는 처음 0.07로 설정했다.
- batch 사이즈는 32,768로 매우 크게 설정했다.
- 가장 큰 RestNet모델인 RN50X64는 592개의 V100 GPU로 18일간 학습시켰고, 가장 큰 ViT모델은 256개의 V100 GPU로 12일 학습시켰다.
3. Experiments
3.1. Zero-Shot Transfer
-
CLIP은 image-text간 예측을 위해 pre-trained 되었는데, 이 capability를 재사용해서 zero-shot classificaiton을 진행한다.
- 각 데이터셋에, 모든 class의 name을 이용해 (image, text) 쌍의 가장 probable한 pair를 predict한다.
- 이미지의 feature embedding과 possible한 텍스트 셋의 feature embedding을 각각의 인코더로 계산한 후, 코사인 유사도를 계산해, softmax를 거쳐 확률 분포로 정규화한다.
-
각 class의 name을 "a photo of a { }." 형식의 문장으로 바꾼 후, 주어진 이미지와 유사도를 모든 class에 대해 계산하는 방식으로 prediction이 이루어진다.
-
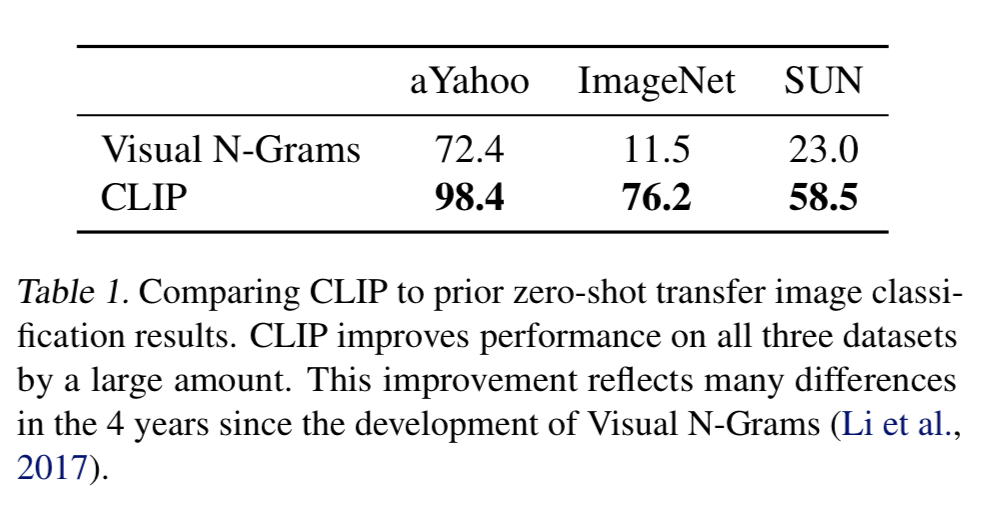
기존 Visul N-Gram과 비교했을 때, aYahoo, ImageNet, SUN 3개의 데이터셋에 대해 CLIP이 모두 zero-shot 성능이 뛰어났다.
-
Prompt Engineering and Ensembling
- image classification 데이터셋은 숫자 ID로 구성되는 경우가 많아 task description에 의존하는 zero-shot transfer가 힘들다.
- Polysemy(다의성) 문제도 있어 class name만이 유일한 정보일 때 다른 class로 인식할 수 있기도 하다.
- pre-training dataset에 이미지에 대한 text pair가 single word로 존재하는 경우가 매우 적다. 보통은 이미지를 full sentence로 설명한다. 이 gap을 줄이기 위해서, "A photo of a {label}"과 같은 형식의 prompt template을 사용해 성능을 향상시킬 수 있었다.
- GPT3의 "prompt engineering"과 마찬가지로, CLIP 모델에서도 task마다 prompt text를 cutomize해줌으로써 zero-shot 성능을 크게 향상시켜줄 수 있었다.
- Oxford-IIIT Pets 데이터셋을 대상으로는 "A photo of a {label}, a type of pet."
- Food101 데이터셋에는 a type of food, FGVC Aircraft 데이터셋에는 a type of aircraft
- satellite image classification 데이터셋에는 "a satellite photo fo a {label}."
- 이런식으로 prompt를 맞춰주어 성능을 향상시켰다.
-
Zero-shot CLIP 성능을 RESNET-50의 성능을 비교해보았을 때, 27개의 데이터셋 중 16개의 데이터셋에서 성능이 앞섰다.
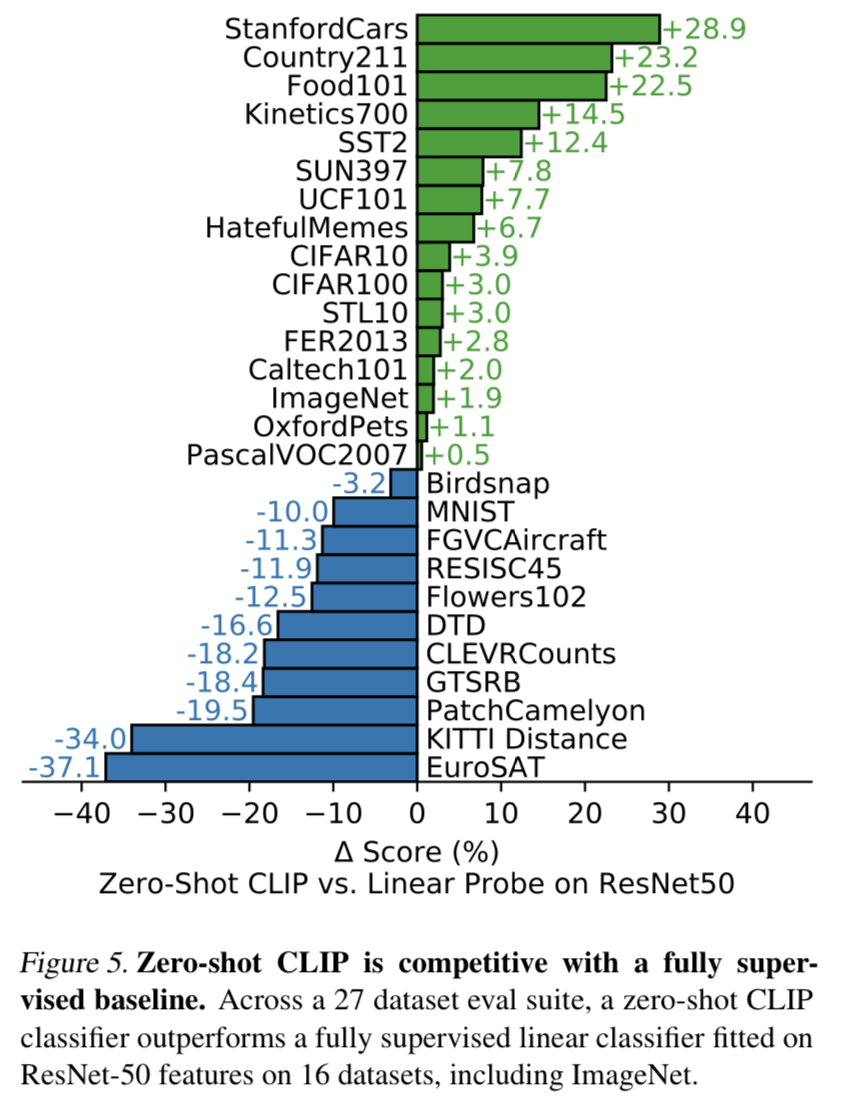
- StanfordCars와 Food101를 대상으로 했을 때 20%가 넘게 앞선 반면, EuroSAT(위성사진 이미지 분류)이나 KITTI Distance(가까운 차의 거리 구하기)와 같은 complex한 task에 대해서는 zero-shot CLIP이 취약한 모습을 보였다.
-
Zero-shot CLIP의 성능을 few-shot methods와 비교했을 때도 대체로 성능이 앞서는 것을 볼 수 있었다.
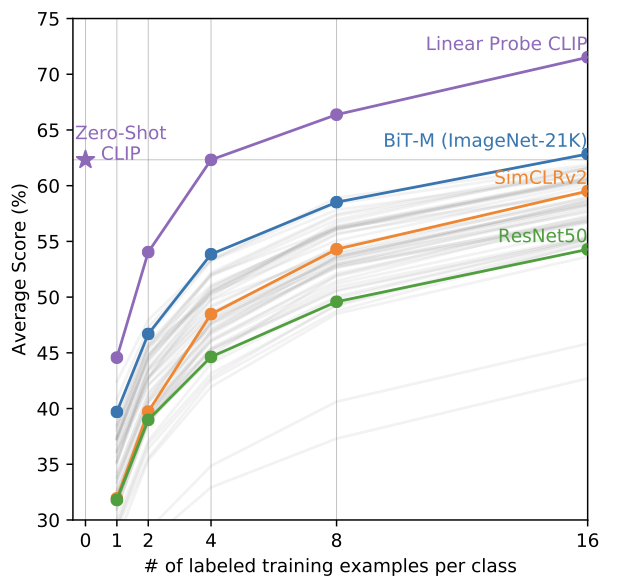
-
Representation Learning
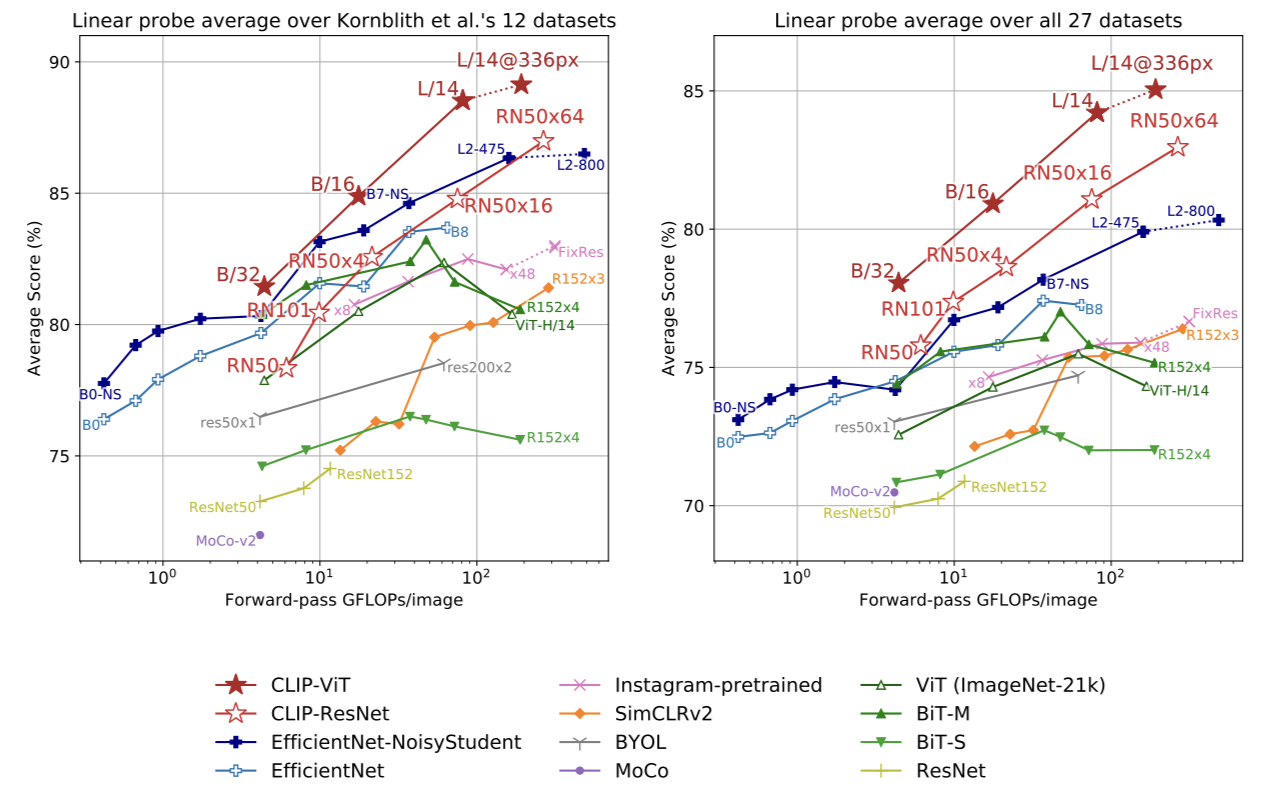
- CLIP은 representation learning에서도 다른 모델들에 비해 성능이 뛰어나고, 보다 compute efficient하다.
-
Robustness to Natural Distribution Shift
- CLIP은 distribution shift에 강한 robustness를 갖는 것이 큰 특징이자, 장점이다. ImageNet과 관련된 여러 distribution shift에 대해 CLIP은 기존 ImageNet ResNet101 모델에 비해 shift가 이루어져도 크게 향상된 성능을 보였다.
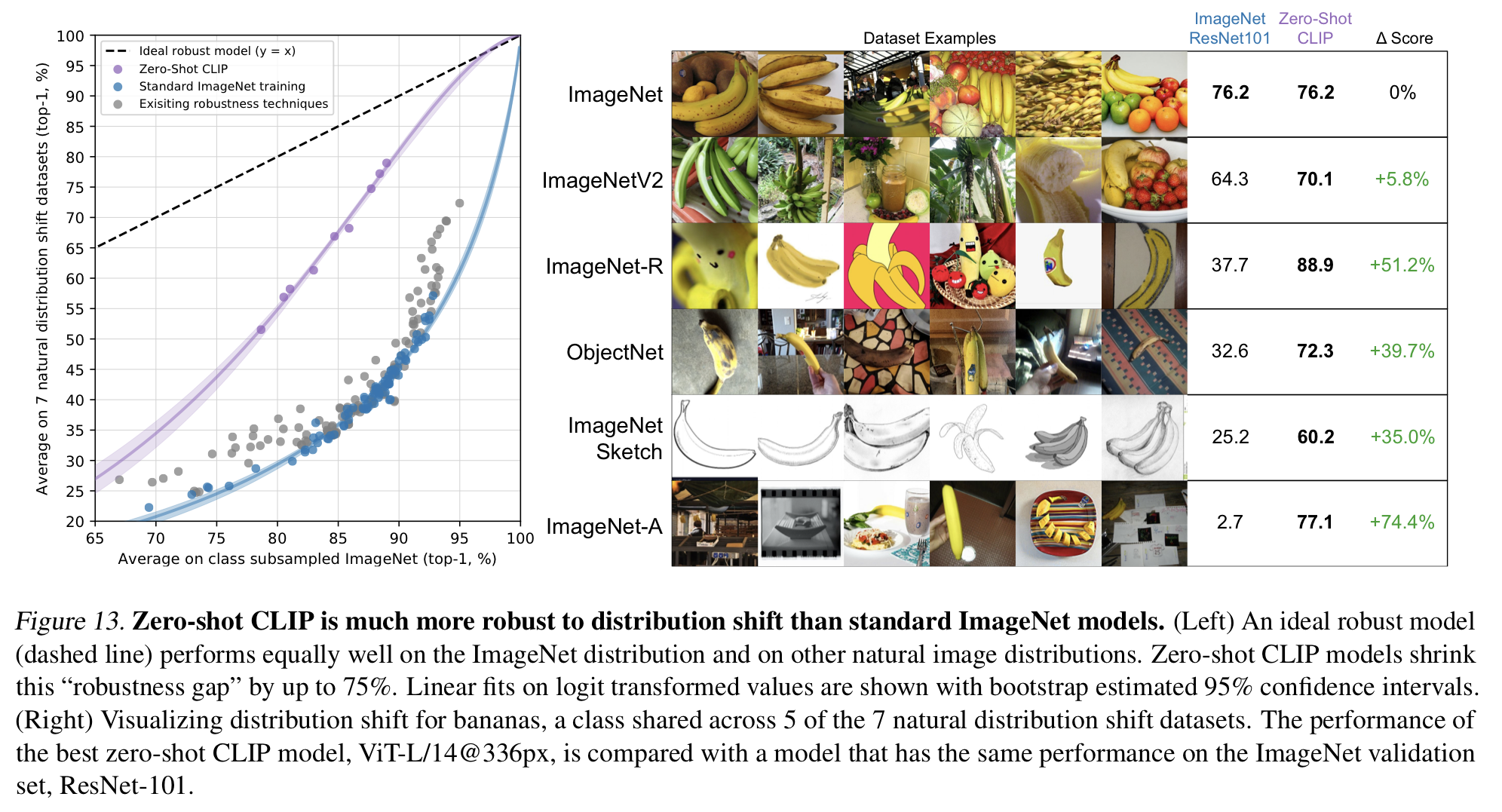
- ImageNet이 바나나 사진이라면, 스케치된 그림의 형태로 나타난 ImageNetSketch나 바나나 외 다른 여러 object들이 담기고 여러 구도에서 찍힌 ImageNet-A 등의 distribution shift가 일어나도 CLIP은 robust하게, ImageNet을 대상으로 했던 score와 비슷하게 task를 잘 수행해냈다.
- 정확도(accuracy)를 향상시키기 위해 supervised adaptation을 시키면, 정확도를 향상되지만 robustness가 감소하는 trade-off가 존재한다.
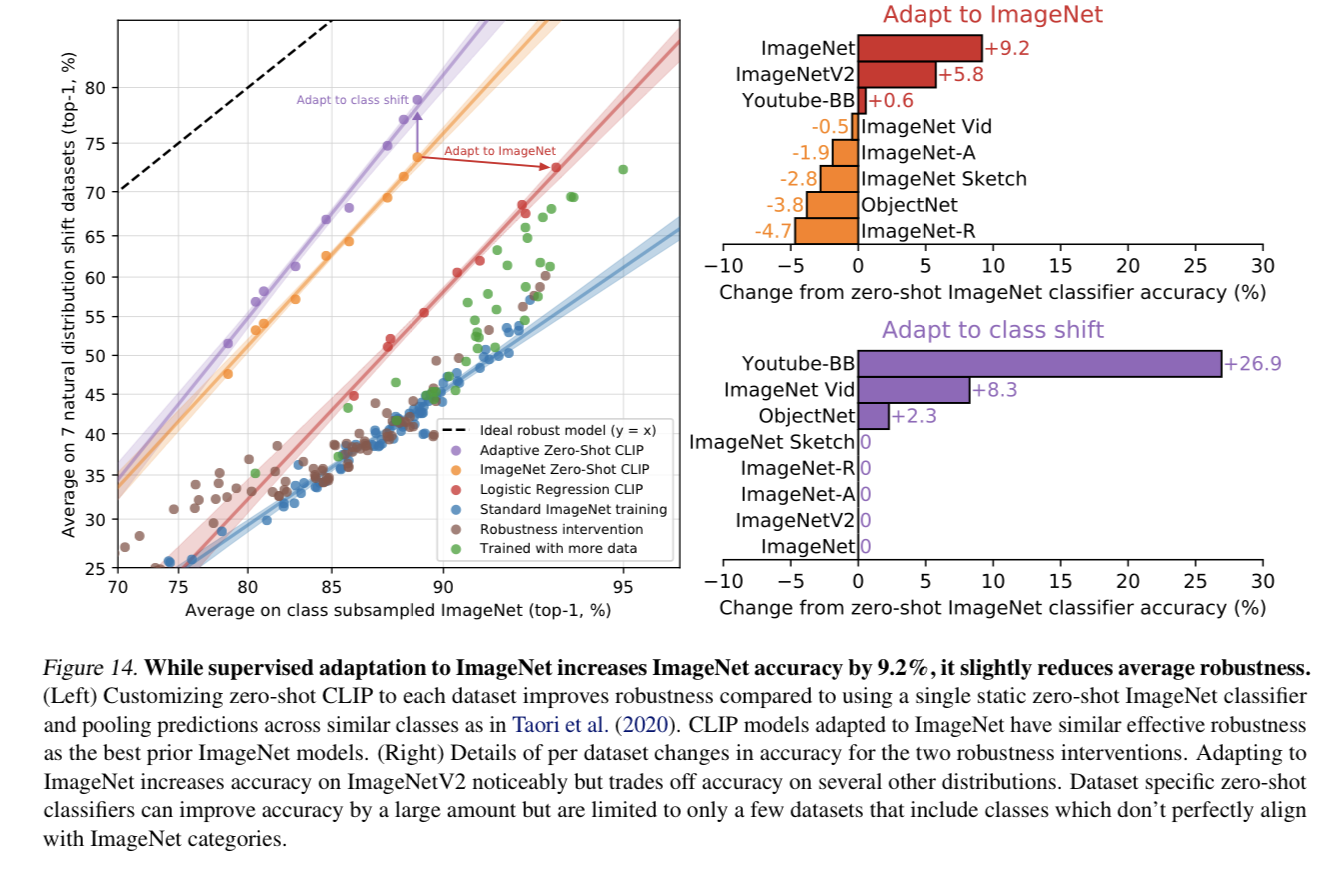
- robustness는 zero shot CLIP > Few shot CLIP > 기존 ImageNet 모델 순으로 강하다.
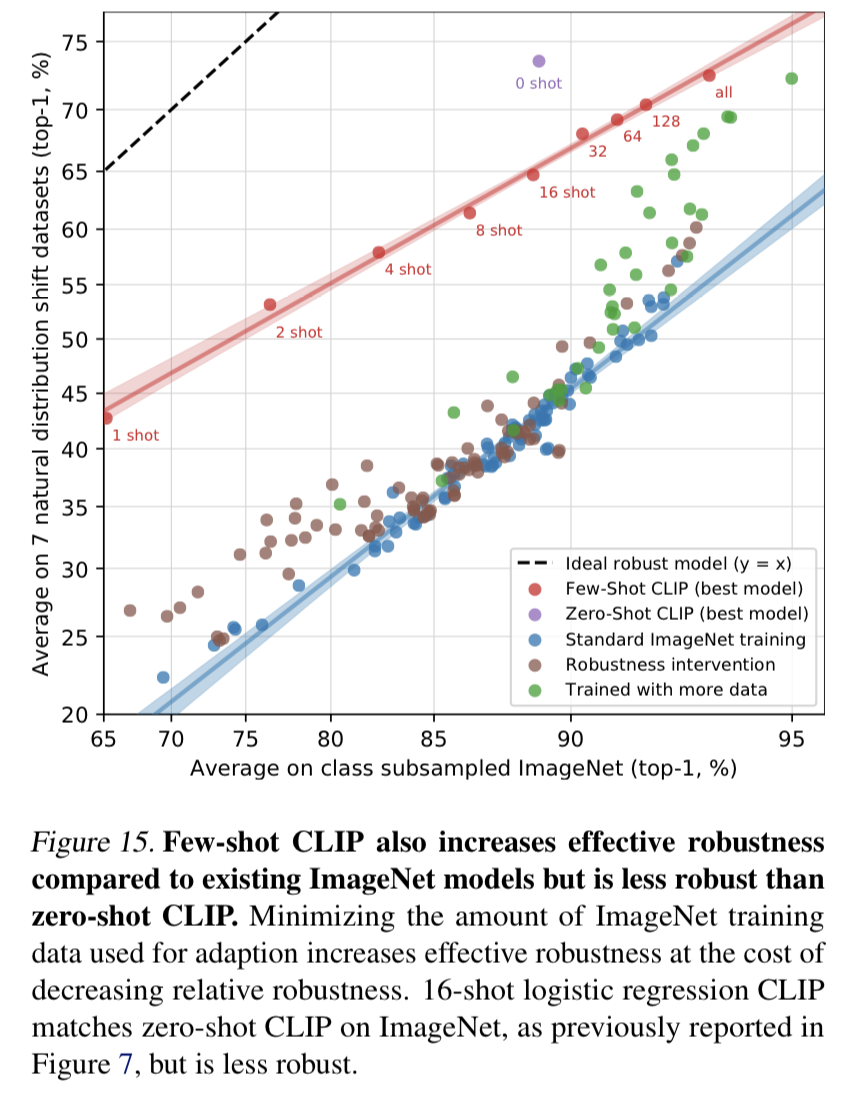
- CLIP은 distribution shift에 강한 robustness를 갖는 것이 큰 특징이자, 장점이다. ImageNet과 관련된 여러 distribution shift에 대해 CLIP은 기존 ImageNet ResNet101 모델에 비해 shift가 이루어져도 크게 향상된 성능을 보였다.
4. Comparison to Human Performance
- 사람이 직접 task를 진행했을 때의 정확도를 CLIP 모델의 정확도와 비교해보았다.
- Oxford IIT Pets task에 대해 zero-shot CLIP, zero-shot human, one-shot human, two-shot human의 정확도를 각각 비교했는데, zero-shot CLIP이 사람이 진행한 것보다 훨씬 높은 성능을 보였다.
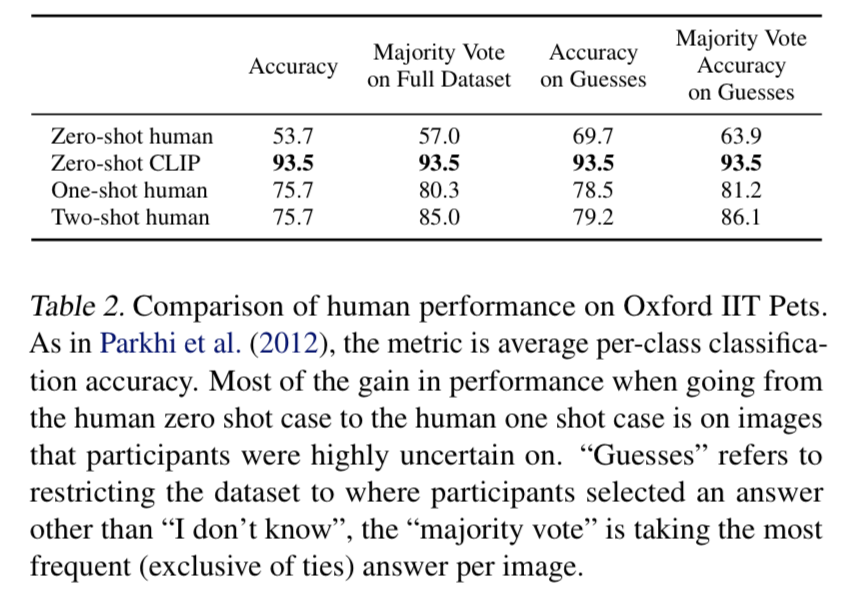
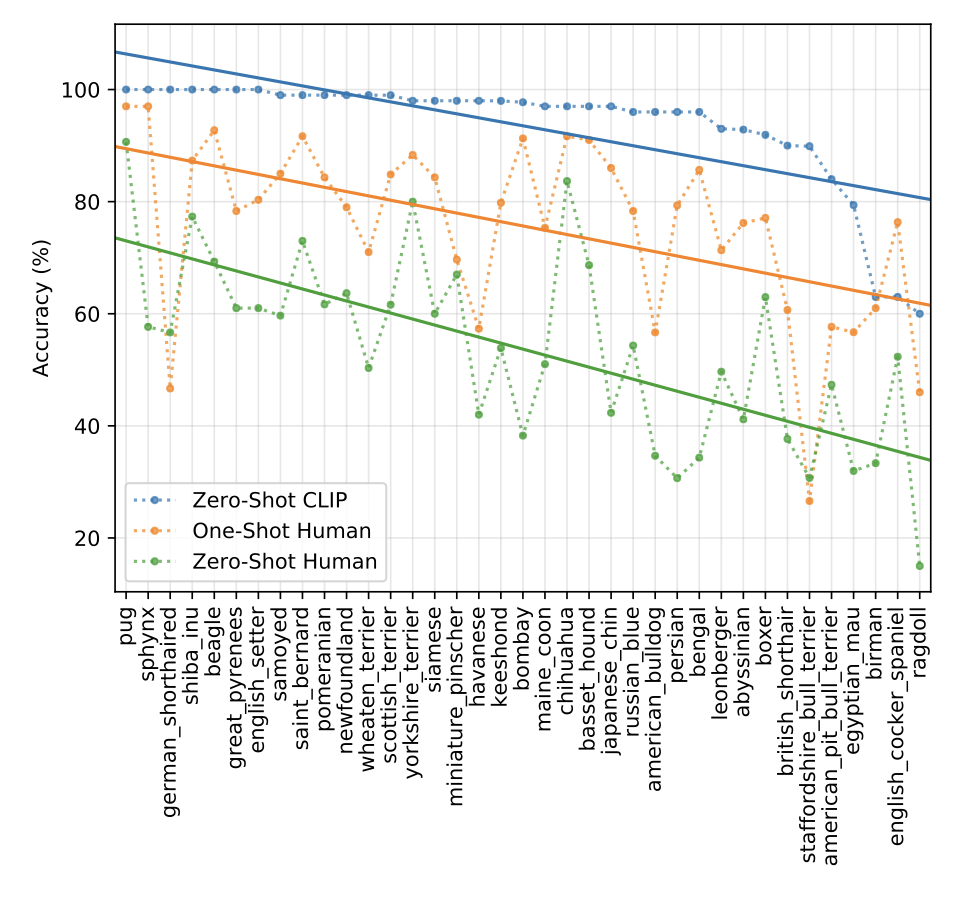
- Oxford IIT Pets task에 대해 zero-shot CLIP, zero-shot human, one-shot human, two-shot human의 정확도를 각각 비교했는데, zero-shot CLIP이 사람이 진행한 것보다 훨씬 높은 성능을 보였다.
5. Data Overlap Analysis
-
인터넷상의 매우 큰 데이터셋으로 pre-train하기 때문에 의도치않게 데이터가 겹칠 수 있다.
-
이를 방지 하기 위해 모델을 학습하기 전 모든 중복된 데이터를 제거할 수 있는데, 이렇게 하면 benchmarking과 분석의 scope를 제한할 수 있다.
-
대신 CLIP은 데이터가 얼마나 겹치는지 확인하고, 그에 따라 성능이 얼마나 변화하는지를 살펴보았다.
- 각 evaluation 데이터셋마다, duplicate detector를 사용한다. 이후 가장 가까운 neighbors를 찾고 데이터셋마다 recall을 최대화하면서 높은 precision을 유지하도록 threshold를 걸어준다. 이 threshol를 이용해서 2개의 subsets(부분집합)를 만든다.
-
Overlap: contains all examples which have a similarity to a training example above the threshold
-
Clean: contains all examples which have a similarity to a training example above the threshold
-
ALL: unaltered full dataset
-
ALL 대비 Overlap의 비율을 통해 degree of data contamination을 기록한다.
-
위 3개의 split에 대해 CLIP RN50x64의 zero-shot accuracy를 측정하고 'All - Clean'을 주요 metric으로 사용한다.
-
overlap 정도가 낮을 경우 binomial significance test를 진행하고, Overlap subset에 대해 one-trailed(greater) p-value를 계산한다. Dirty의 99.5% Clopper-Pearson confidence intervals 도 계산한다.
-
-
detector가 완벽하지 않을 수 있고, data distribution이 'Overlap', 'Clean' Subsets 간 shift가 일어날 수 있다는 문제가 있지만, 기존 large scale pretraining의 연구에서의 결과를 따른다는 점에서 활용 의의가 있다.
6. Limitations
-
zero-shot CLIP은 ResNet-50의 baseline과 비슷한 수준이지만 SOTA에 비하면 성능이 많이 떨어진다. SOTA 수준의 성능까지 올리려면 computation을 1000배 늘려야 하는데 이는 현재 하드웨어로 불가능한 수준이다.
-
CLIP의 zero-shot 성능은 아직 여러 task에 대해 저조한 모습을 보인다. task-specific한 모델들에 비해 fine-grained classification에서 취약한 모습을 보이고, abstract 하고 systematic한 task에 대해 어려움을 겪는다. CLIP의 pre-training dataset에 없는 novel task에 대해서도 많이 취약한 모습을 보인다.
-
out-of-distribution 데이터에 대해 generalize하기 힘들다.
-
인터넷 상의 데이터로 학습을 했기에 많은 social bias를 학습한다.
7. Conclusion
-
NLP 분야에서 성공한 task-agnostic web-scale pre-training 방식을 vision 분야에 transfer하여 적용함이 가능함을 확인하였다.
-
CLIP 모델을 학습하여 pre-training 과정에서 다양한 종류의 task를 수행하도록 하여 optimize하였고, 이 task learing이 다양한 dataset에 대해 zero-shot transfer를 가능케했다.

좋은 글 감사합니다. 자주 방문할게요 :)