CH.8 MNIST

-
필기체 0~9까지의 데이터셋, 60000개 트레이닝 데이터, 10000개 테스트 데이터
-
train data: 1개의 데이터는 785개의 숫자가 ,로 분리되어 있는데, 정답을 나타내는 1개의 숫자와 필기체 숫자 이미지를 나타내는 784개의 숫자로 구성
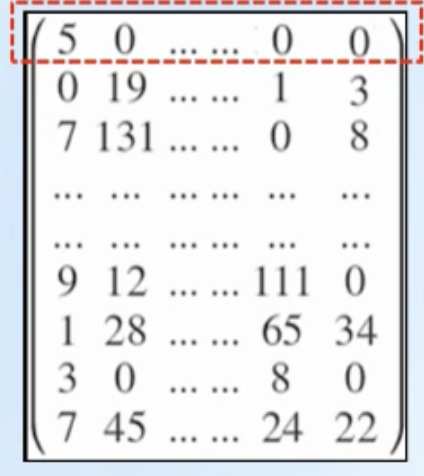
- 1개의 레코드(행)는 785개의 열로 구성
- 1열에는 정답이 있음
- 2열부터 마지막 열까지는 정답을 나타내는 이미지의 색을 나타내는 숫자 값들이 784개 연속으로 있음
- 흑백 이미지를 표현할 때 숫자 0에 가까울수록 검은색, 255에 가까울수록 흰색으로 나타냄, 2열부터 마지막열까지 나열된 숫자가 이미지 색을 나타내는 정보
- 이미지 표현
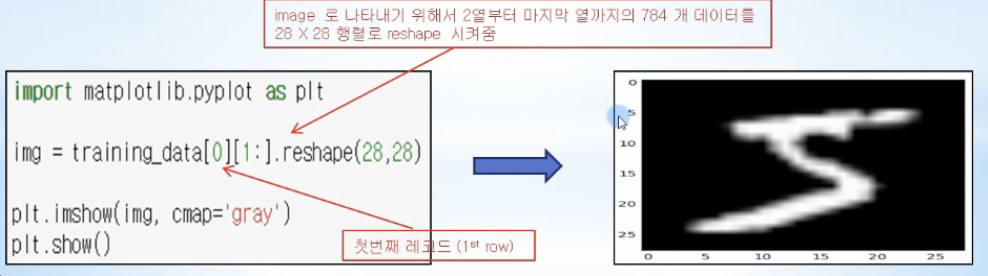
-
test data: 학습을 마친 후에 구현된 딥러닝 아키텍처가 얼마나 잘 동작하는지 테스트하기 위해 사용, 정답이 포함된 785개의 숫자
-
딥러닝 아키텍처
- 입력층 노드를 입력 데이터 개수와 일치하도록 784개로 설정 (정답을 제외하고 숫자 이미지를 나타내는 열의 개수)
- 은닉층 노드 개수는 임의로 설정(하이퍼 파라미터)
- 출력층 노드는 10개로 설정
- 정답은 0~9중 하나이므로 10개의 원소를 갖는 리스트를 만들고, 리스트에서 가장 큰 값을 가지는 인덱스를 정답으로 판단할 수 있도록 함 (one-hot encoding)
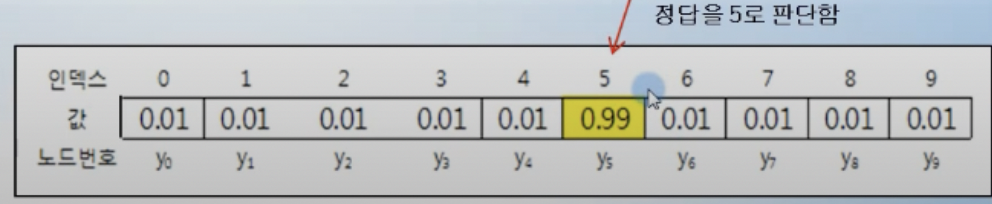
- 정답은 0~9중 하나이므로 10개의 원소를 갖는 리스트를 만들고, 리스트에서 가장 큰 값을 가지는 인덱스를 정답으로 판단할 수 있도록 함 (one-hot encoding)
-
전체 구조

-
feed forward, 수치미분 문제점
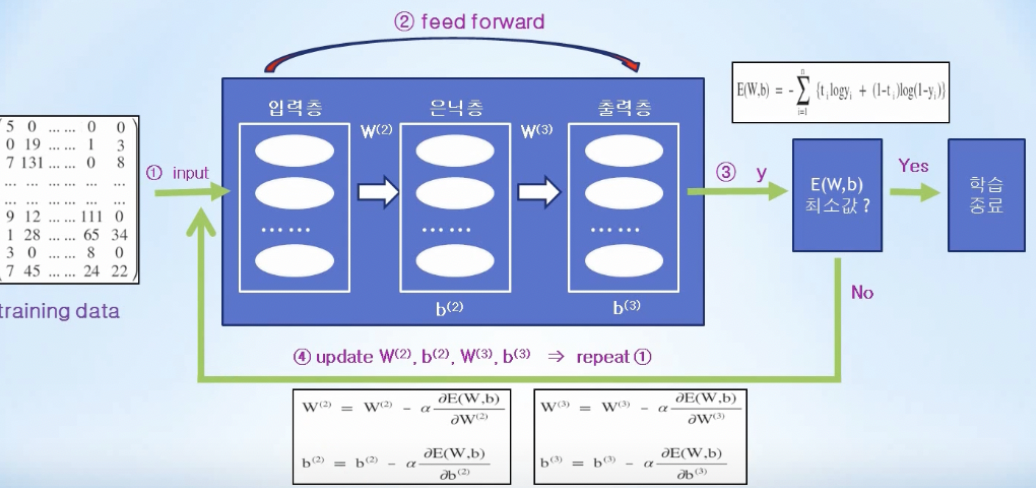
- 직관적이지만 손실함수값을 줄이기 위해 매번 처음으로 돌아가야해서 미분 계산시 많은 시간이 소요됨
- 오차역전파로 해결
