CH.5 선형회귀와 분류 (Linear Regression & Classification)
- regression - 학습(learning) 개념
- 입력(x)과 출력(y)은 y = Wx + b 형태로 나타낼 수 있음
- y = Wx + b는 다양한 직선의 형태를 띨 수 있는데, training data의 특성을 가장 잘 표현할 수 있는 가중치 W와 바이어스 b 를 찾는 것이 학습(Learning) 개념임
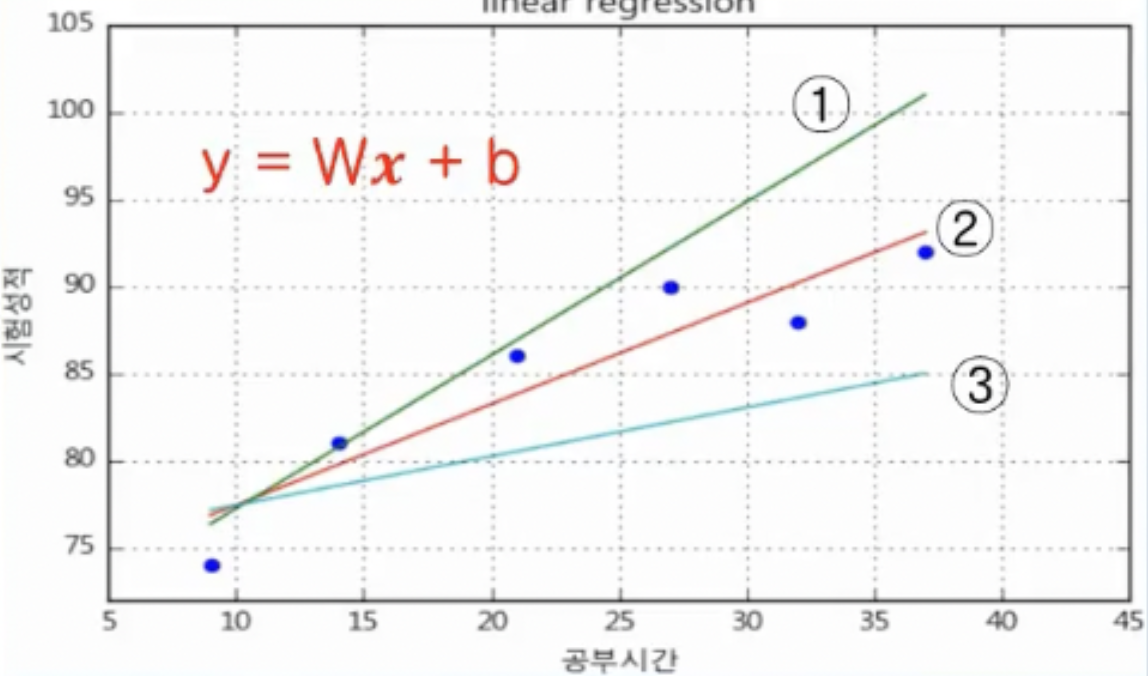
- 오차 (error), 가중치 (weight) W, 바이어스 (bias) b
- 오차(error): training data의 정답과 직선 y = Wx+b 값의 차이
- 오차 = t - y = t - (Wx+b)
- 오차가 크다면 임의로 설정한 직선의 가중치와 바이어스 값이 잘못된 것이고, 오차가 작다면 잘 된 것이기에 미래 값 예측도 정확할 수 있다고 예상할 수 있음
- 머신러닝의 regression 시스템은, 모든 데이터의 오차의 합이 최소가 되어서, 미래 값을 잘 예측할 수 있는 가중치 W와 바이어스 b 값을 찾아야 함
- 오차(error): training data의 정답과 직선 y = Wx+b 값의 차이
- 손실함수 (loss function)
- training data의 정답(t)과 입력(x)에 대한 계산 값 y의 차이를 모두 더해 수식으로 나타낸 것
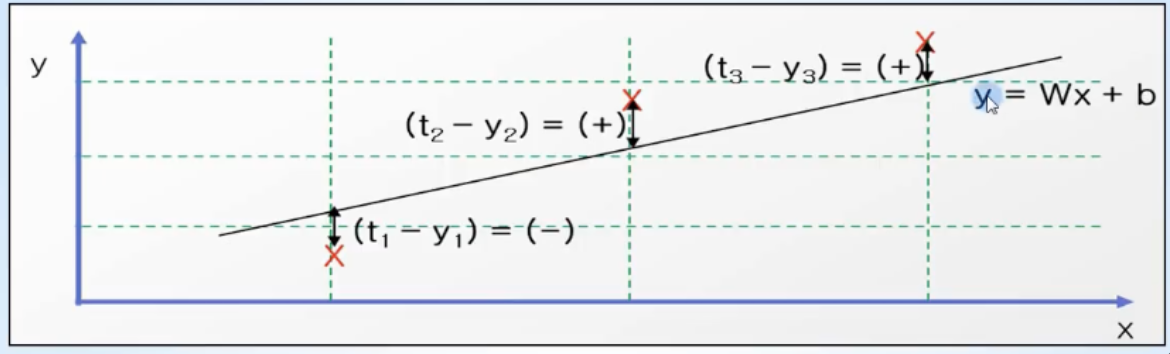
- 각각의 오차인 (t-y)를 모두 더해서 손실함수를 구하면 오차는 (+), (-)값이 동시에 존재하기에 오차의 합이 0이 나올 수 있음
- 따라서 손실함수에서 오차(error)를 계산할 때는 제곱을 활용함
- 그렇게 하면 오차는 언제나 양수이며, 제곱을 하기 때문에 정답과 계산값 차이가 크다면, 제곱에 의해 오차는 더 큰 값을 가지게 되어 머신러닝 학습에 있어 장점을 가짐

- x와 t는 training data에서 주어지는 값이므로, 손실함수인 E(W,b)는 결국 W와 b에 영향을 받는 함수임
- E(W,b)값이 작다는 것은 정답과 y = Wx+b에 의해 계산된 값의 평균 오차가 작다는 의미
- training data를 바탕으로 손실함수 E(W,b)가 최소값을 갖도록 (W,b)를 구하는 것이 linear regression model의 최종 목적
- training data의 정답(t)과 입력(x)에 대한 계산 값 y의 차이를 모두 더해 수식으로 나타낸 것
- 경사하강법 (gradient decent algorithm)
- regression에서 손실함수는 포물선 형태로 나타나며, 손실함수에서 최소값을 가지는 가중치 W값을 찾는 것 최종 목표

- 임의의 가중치 W 선택
- 그 W에서의 직선의 기울기를 나타내는 미분값 (해당 W에서의 미분, E(W)편미분) 을 구함
- 그 미분 값이 작아지는 방향으로 W감소(또는 증가)시켜 나감 (미분값이 양수면 왼쪽으로, 음수면 오른쪽으로 이동시킴)
- 최종적으로 기울기가 더 이상 작아지지 않는 곳을 찾으면 그곳이 손실함수 E(W)의 최소값
- 이처럼 W에서의 직선의 기울기인 미분값을 이용하여 그 값이 작아지는 방향으로 진행하며 손실함수 최소값을 찾는 방법이 경사하강법(gradient decent algorithm)임
- W값 구하기
- 편미분값이 양수일 때는 W에서 편미분값만큼 빼주어서 감소시키고, 음수일 때는 W에서 편미분값만큼 증가해줌

- b도 마찬가지
- 편미분값이 양수일 때는 W에서 편미분값만큼 빼주어서 감소시키고, 음수일 때는 W에서 편미분값만큼 증가해줌
- regression에서 손실함수는 포물선 형태로 나타나며, 손실함수에서 최소값을 가지는 가중치 W값을 찾는 것 최종 목표
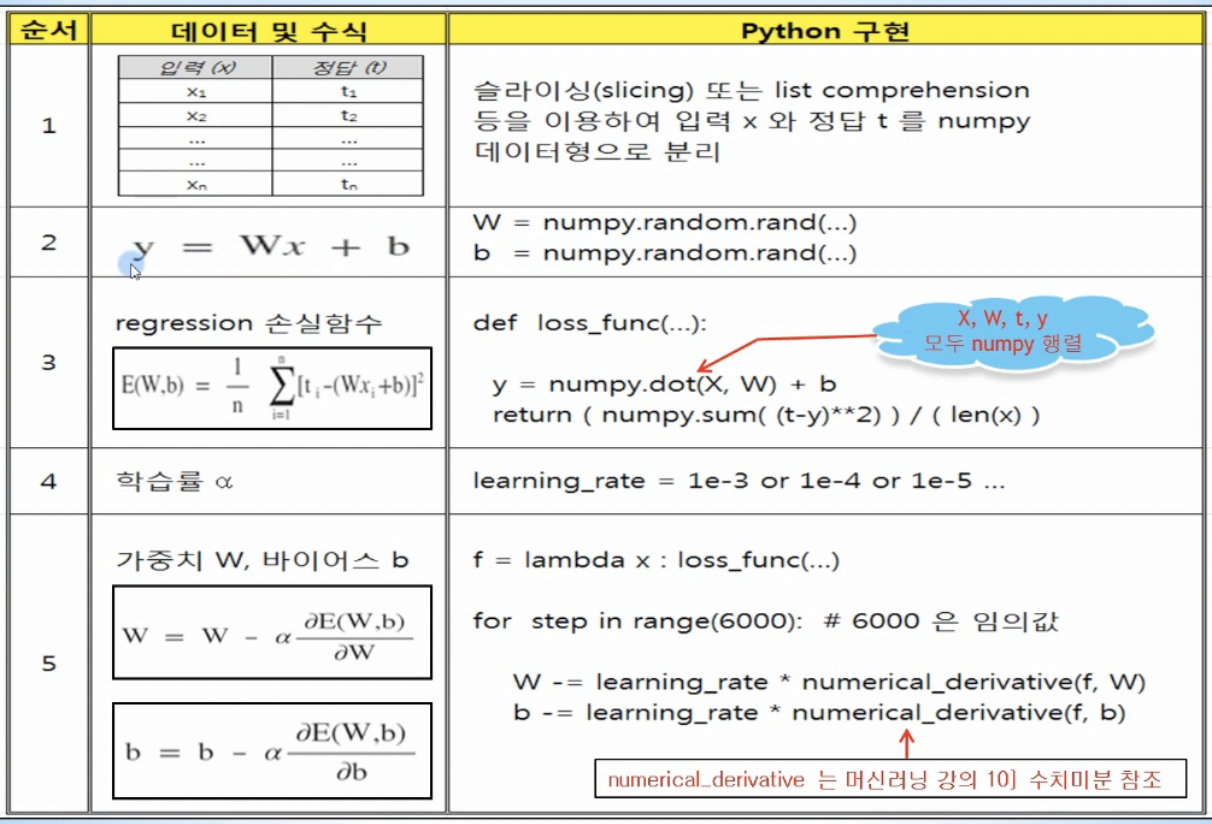
- linear regession을 코드로 구현
- 학습을 위해 필요한 training data 준비
- 슬라이싱 또는 list comprehension 등을 이요해 입력 x와 정답 t를 Numpy 데이터타입으로 분리
- 임의의 직선 y = Wx + b 정의
- W와 b는 numpy.random.rand()함수를 이용해 0 과 1 사이의 랜덤한 값으로 초기화
- 손실함수 정의
- y = Wx+b 부분이 행렬곱을 이용하여 구현됨
- 모든 입력 데이터 x와 정답 데이터 t를 한꺼번에 계산하는 장점이 있어 머신러닝 코드에서 자주 사용됨
- y = Wx+b 부분이 행렬곱을 이용하여 구현됨
- 학습률 (learning rate) 정의
- 1e-3, 1e-4 등 적절한 값 설정
- 손실함수 loss_func를 lambda를 활용해 함수로 정의한 후에 수치미분 numerical_derivative를 이용해 손실함수 f를 미분하고, 이를 바탕으로 W와 b를 업데이트해 손실함수의 최소값을 찾음
- 학습을 위해 필요한 training data 준비
- 입력 변수가 1개인 simple linear regression
- 오차를 계산하기 위해서는 training data의 모든 입력 x에 대해 각각의 y = Wx+b를 계산해야하는데, 이 때 입력 x, 정답 t, 가중치 W 모두를 행렬로 나타낸 후 행렬곱(dot product)을 이용하면 계산 값 y 또한 행렬로 표시되어 모든 입력 데이터에 대해 한번에 쉽게 계산됨
- 입력 변수가 2개 이상인 linear regression (multi-variable regression)
- simple linear regression과 비슷
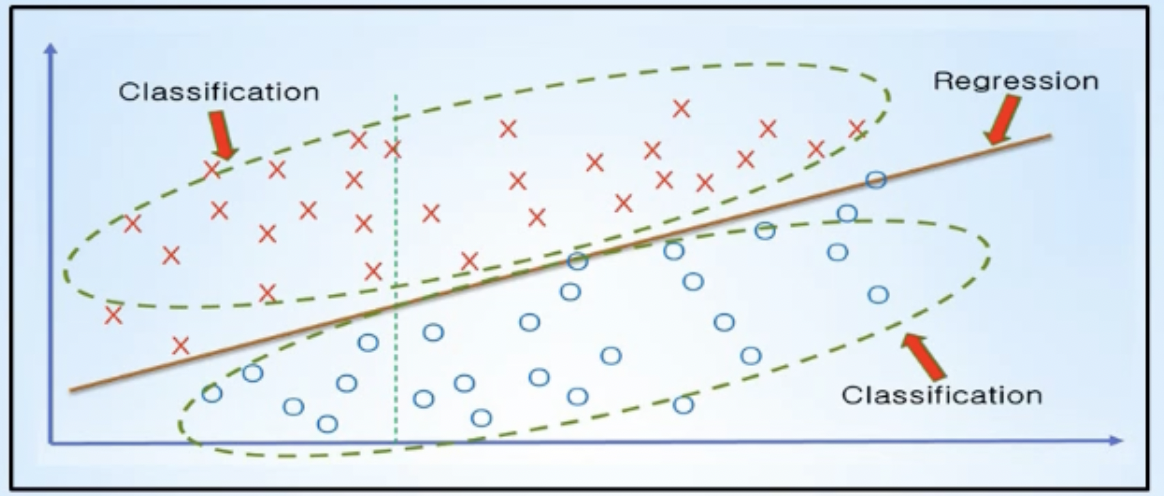
- 분류 (Classification)
- training data의 특성과 관계 등을 파악한 후에, 미지의 입력 데이터에 대해서 결과가 어떤 종류의 값으로 분류될 수 있는지를 예측하는 것
- Logistic Regression 알고리즘
- training data 특성과 분포를 나타내는 최적의 직선을 찾고(Linear Regression), 그 직선을 기준으로 데이터를 위(1) 또는 아래(0) 등으로 분류(Classification)해주는 알고리즘
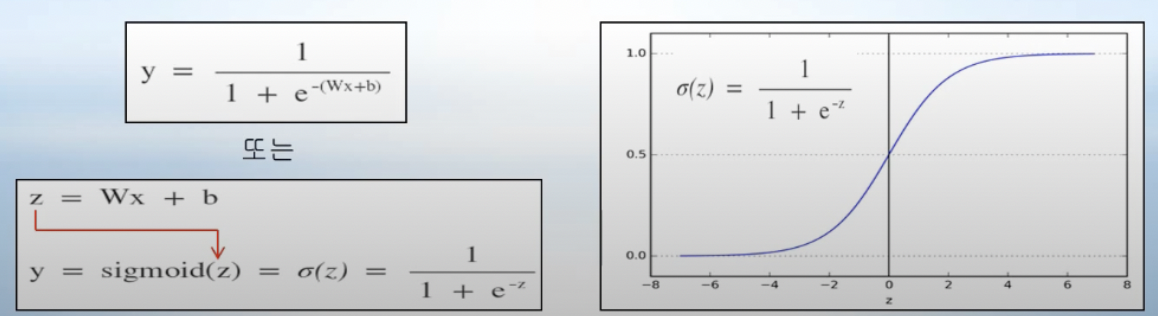
- sigmoid function
-
출력값 y가 1 또는 0만은 가져야만하는 분류(classification)시스템에서, 함수 값으로 0~1 사이의 값을 가지는 sigmoid 함수를 사용할 수 있음
→ 즉 linear regression 출력 Wx+b가 어떤 값을 갖더라도, 출력 함수로 sigmoid를 사용해서 1) sigmoid 계산값이 0.5보다 크면 결과로 1이 나올 확률이 높다는 것이기 때문에 출력값 y는 1을 정의하고 2) sigmoid 계산값이 0.5 미만이면 결과로 0이 나올 확률이 높다는 것이므로 출력값 y는 0을 정의하여 classifcation 시스템을 구현할 수 있음 (sigmoid 함수의 실제 계산값 simoid(z)는 결과가 나타날 확률을 의미함)

-
- Classification의 손실함수 cross-entropy
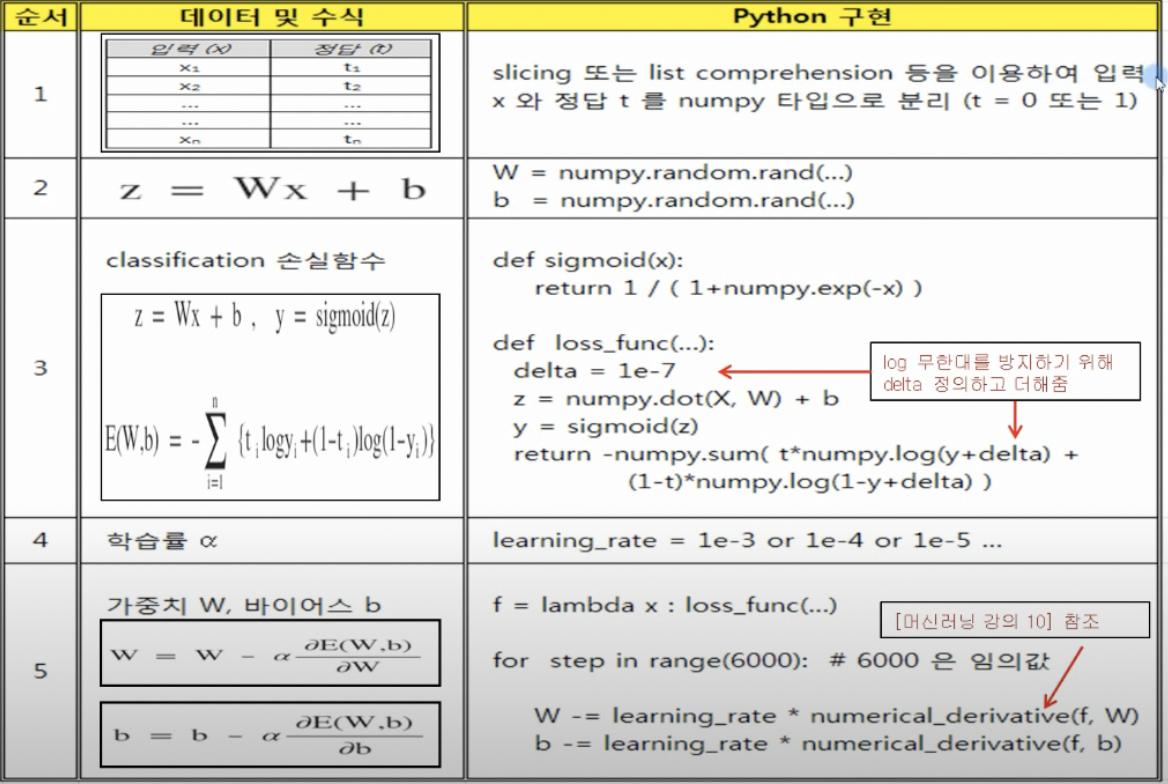
- Classification 최종 출력값 y는 sigmoid 함수에 의해 논리적으로 1 또는 0의 값을 갖기 때문에, 연속 값을 갖는 선형회귀 때와는 다른 손실함수가 필요함
- logistic regression을 코드로 구현
- 학습을 위해 필요한 training data 준비
- 입력데이터 x와 정답 데이터 t를 numpy 타입으로 분리 (t = 0 또는 1)
- 임의의 직선 y = Wx + b 정의
- W와 b는 numpy.random.rand()함수를 이용해 0 과 1 사이의 랜덤한 값으로 초기화
- sigmoid 함수와 손실함수 구현
- 손실함수 부분에서, delta라는 아주 작은 값을 정의해서 log안에 더해줌
- 작은 값을 더해주지 않으면 y가 0이나 1인 경우에 log 내부는 무한대가 될 수 있기에 이를 방지
- 학습률 (learning rate) 정의
- 1e-3, 1e-4 등 적절한 값 설정
- 손실함수 loss_func를 lambda를 활용해 함수로 정의한 후에 수치미분 numerical_derivative를 이용해 손실함수 f를 미분하고, 이를 바탕으로 W와 b를 업데이트해 손실함수의 최소값을 찾음
- 학습을 위해 필요한 training data 준비
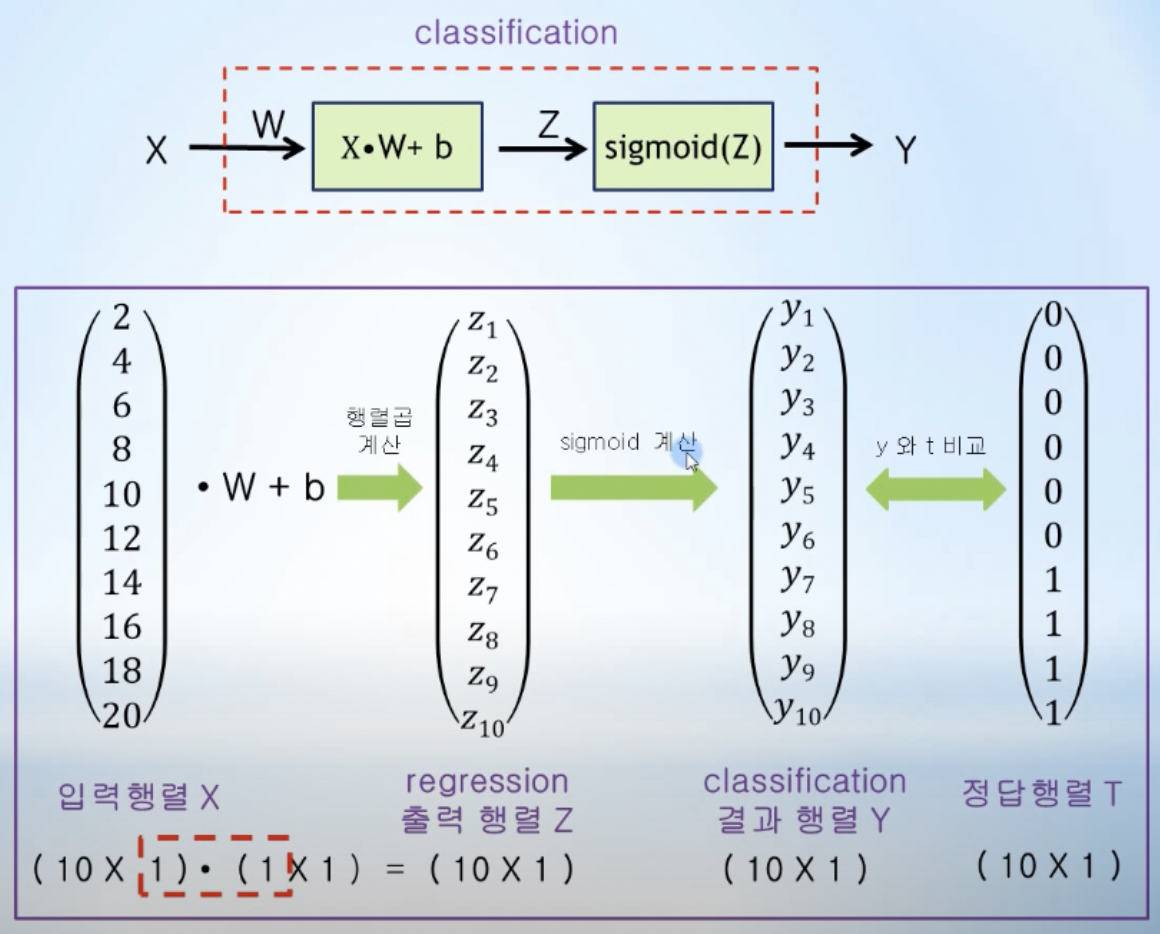
- 입력변수가 1개인 simple logistic regression
- 입력행렬과 가중치행렬을 행렬곱으로 계산하고, b를 더해서 Z 행렬을 구한 후, sigmoid에 입력으로 들어가서 행렬 Y로 계산됨
- 계산된 Y와 정답t를 비교하여 손실함수 값이 가장 최소가 되는 W와 b를 구하는 것이 최종 목적
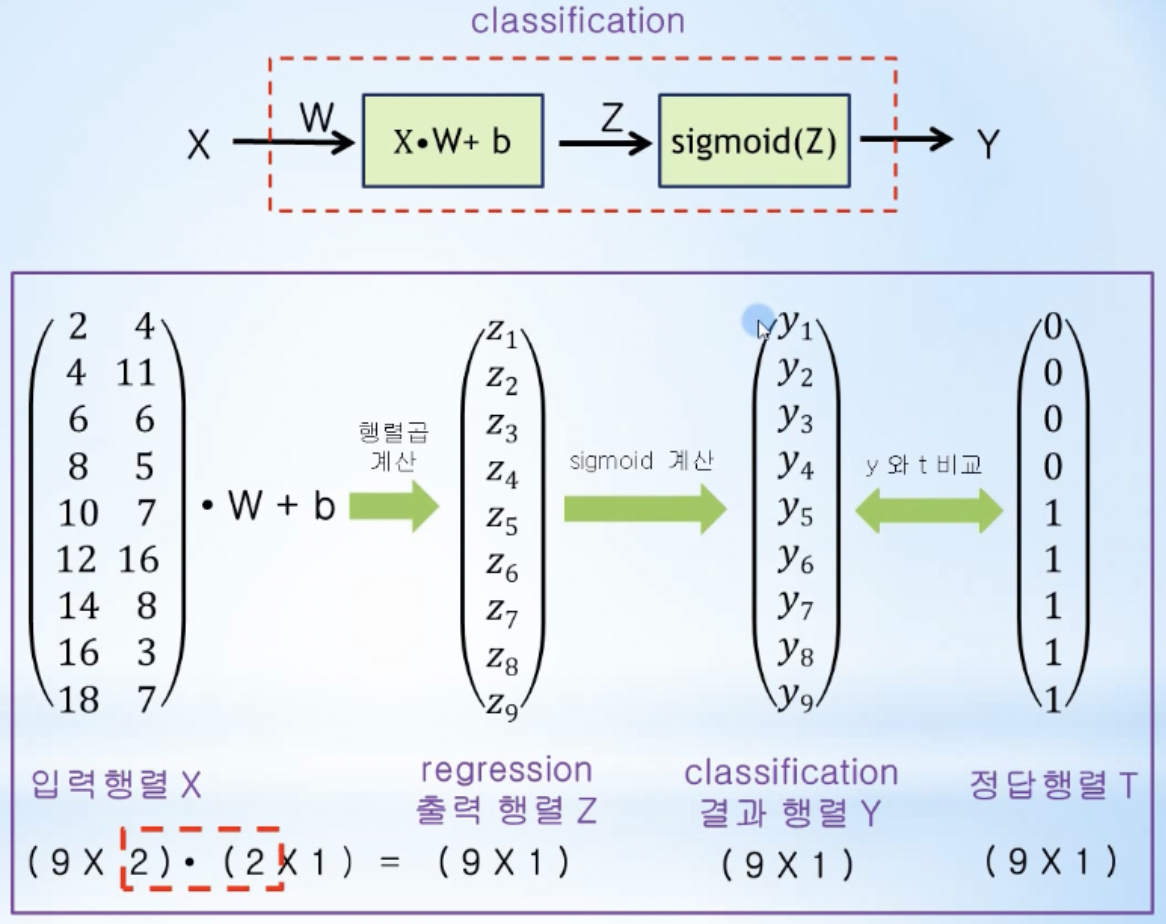
- 입력변수가 2개 이상인 multi-variable logistic regression
- 입력행렬과 가중치행렬(입력이 2개이기에 가중치행렬도 w1, w2 2개의 행렬로 맞춰줌)을 행렬곱으로 계산하고, b를 더해서 Z 행렬을 구한 후, sigmoid에 입력으로 들어가서 행렬 Y로 계산됨
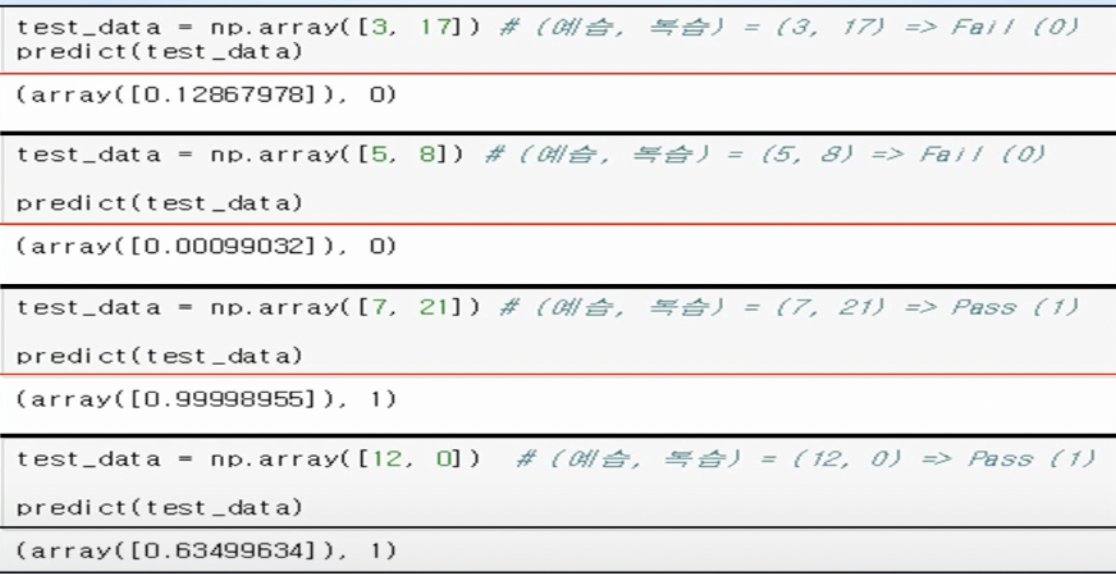
- 미래값 예측

- 미래값을 예측해보면, 복습보다는 예습시간이 합격에 미치는 영향이 크다는 것을 알 수 있음(예습시간에 대한 가중치 W1 = 2.28, 복습시간에 대한 가중치 W2 = 1.06에서 보듯이 예습시간이 복습시간에 비해 최종결과에 미치는 영향이 2배 이상임)
- 미래값을 예측해보면, 복습보다는 예습시간이 합격에 미치는 영향이 크다는 것을 알 수 있음(예습시간에 대한 가중치 W1 = 2.28, 복습시간에 대한 가중치 W2 = 1.06에서 보듯이 예습시간이 복습시간에 비해 최종결과에 미치는 영향이 2배 이상임)
