Hive 예제 사용해보기 (영화 크롤링 파일)
Hive를 이용하여 영화 크롤링 파일 mapreduce 해보기
- hadoop 유저 접속
su hadoop
# 별칭으로 지정했던 명령어 실행하기
start_dfs
start_yarn
start_mr
- 제공해준 파일 tmdb.zip 파일 받기
clinet 에서 실행
cd ~
wget https://mydatahive.s3.ap-northeast-2.amazonaws.com/tmdb.zip- unzip 설치
sudo yum install unzip #unzip설치
# tmdb 파일 만들어서 tmdb.zip 파일을 tmdb파일안에 압축해제
mkdir tmdb && unzip ./tmdb.zip -d ./tmdb
# 하둡에 tmdb파일 만들고 csv파일 붓기
hdfs dfs -mkdir /tmdb
hdfs dfs -put ./*.csv /tmdb-
잘들어갔는지 확인 (namenode:50070에서 확인)
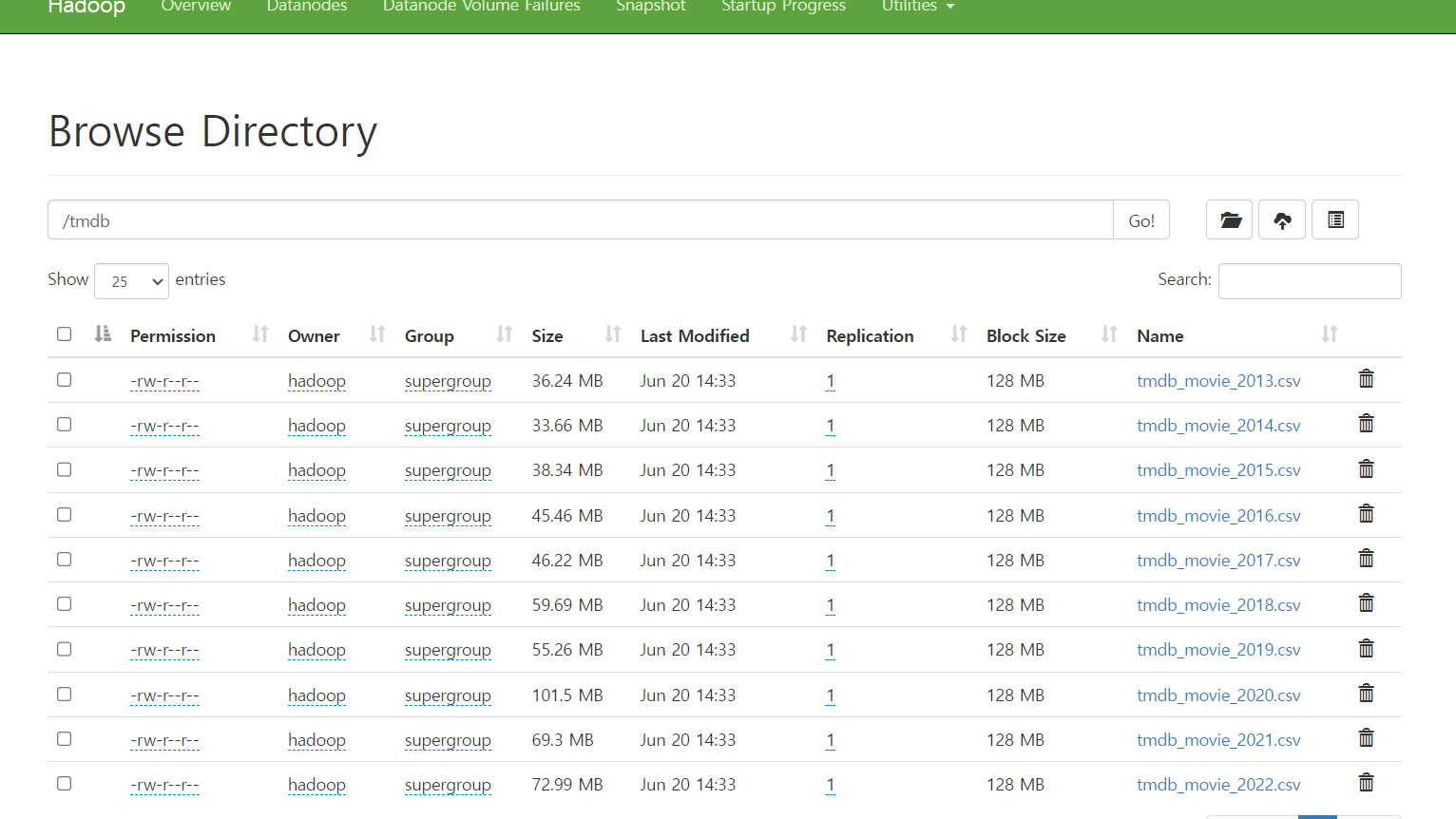
-
putty에서 확인하는 방법
hdfs dfs -ls /tmdb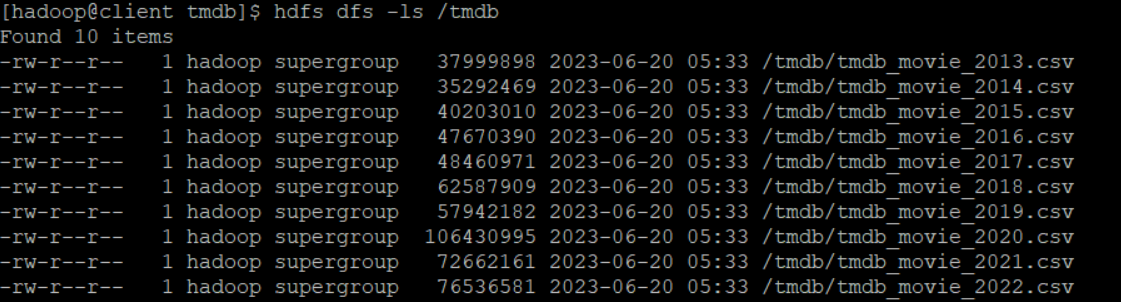
Hive 맵리듀스 해보기
- 받았던 csv파일을 sql 쿼리를 날려 테이블 생성
CREATE EXTERNAL TABLE IF NOT EXISTS movie(
Movie_ID STRING,
Adult STRING,
Backdrop_Path STRING,
Genres STRING,
Homepage STRING,
Original_Language STRING,
Original_Title STRING,
Overview STRING,
Popularity STRING,
Poster_Path STRING,
Production_Companies STRING,
Production_Countries STRING,
Release_Date STRING,
Revenue STRING,
Runtime STRING,
Spoken_Languages STRING,
Status STRING,
Tagline STRING,
Title STRING,
Vote_Average FLOAT,
Vote_Count INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/tmdb';- 잘 적용됐는지 확인해보기
SELECT * FROM movie limit 5;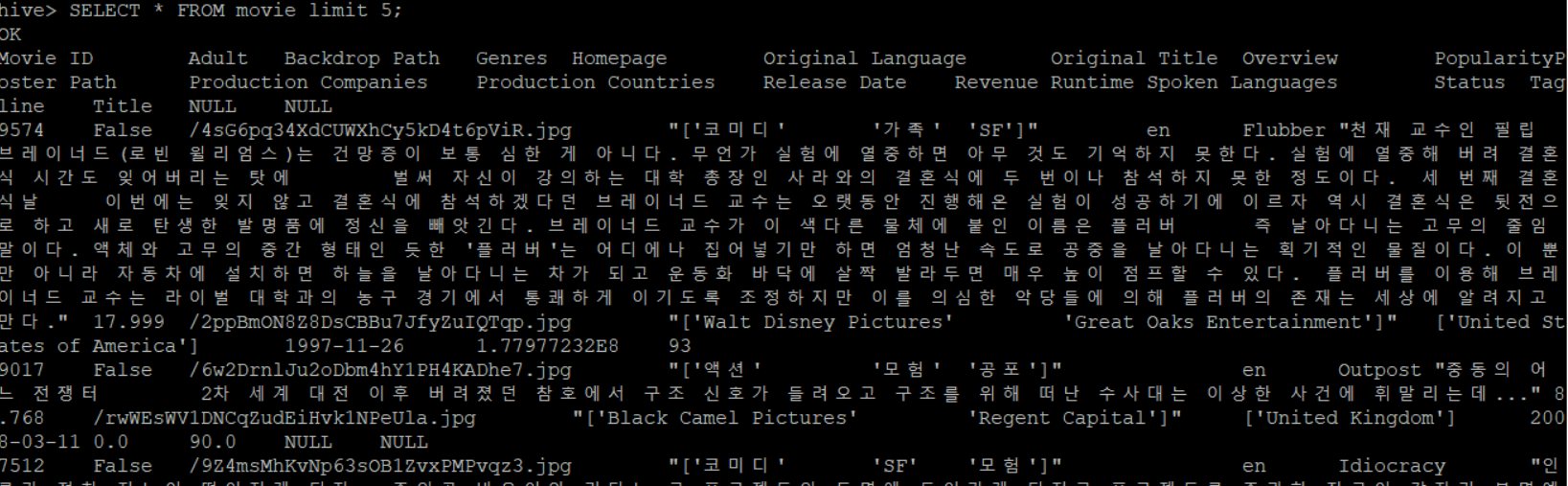
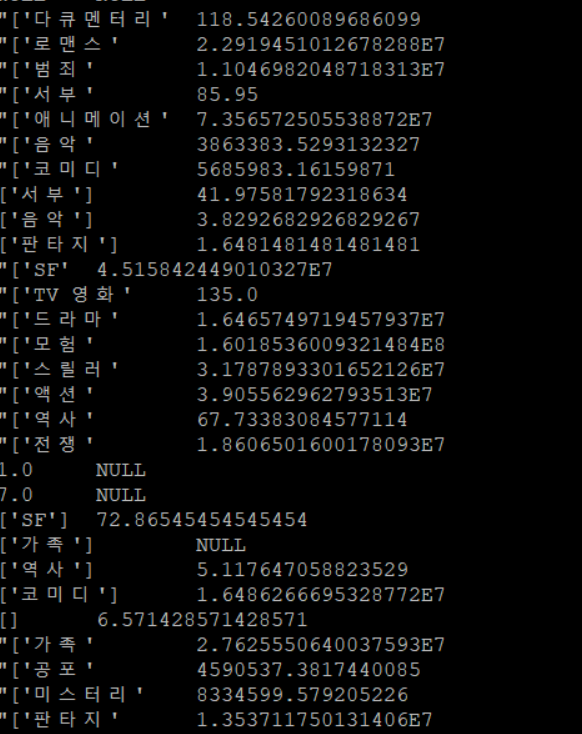
장르별로 집계해보기
SELECT Genres , AVG(Vote_Count) FROM movie GROUP BY Genres -
map 과 reduce 과정
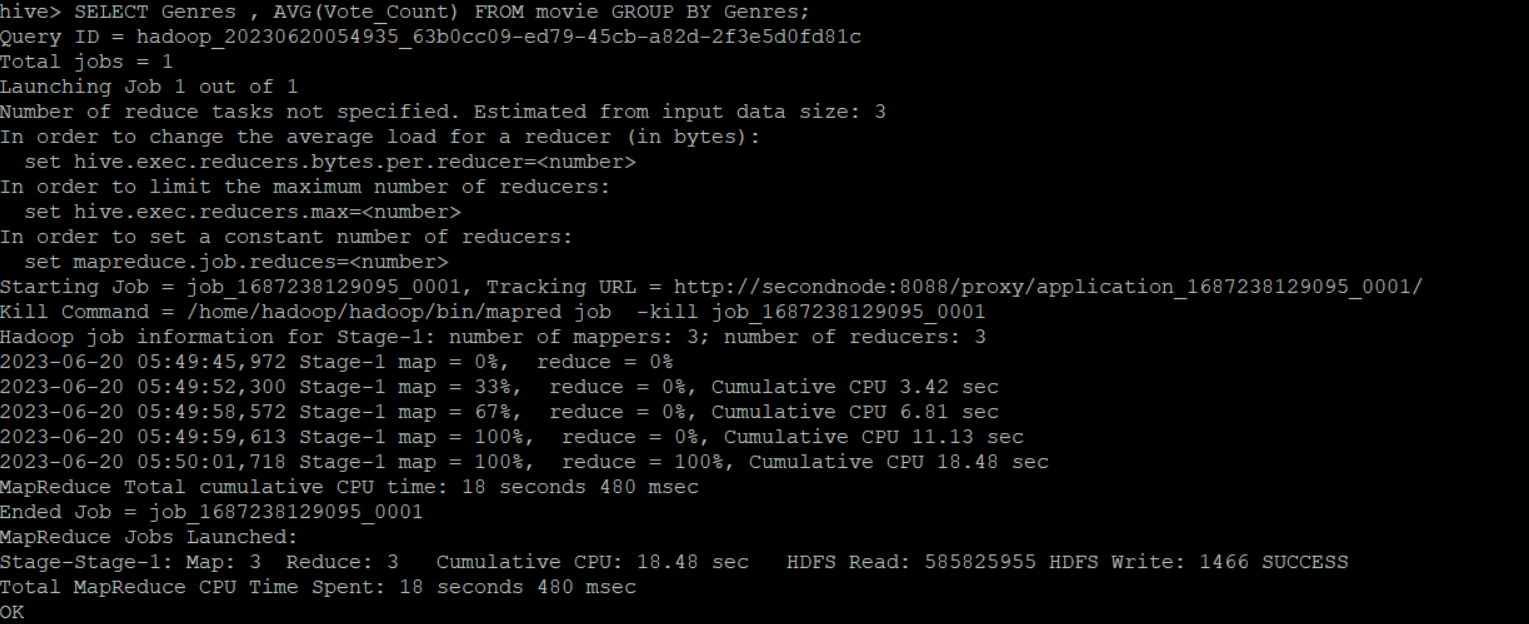
-
결과창

공부 기록