Hadoop에서 wordcount 하기
putty 접속 후
su hadoop
#bashrc 명령어 실행
$ start dfs
$ start_yarn
$ start_mr- hdfs에 새로운 폴더 생성
$ hdfs dfs -mkdir /mydata- hdfs에 데이터 넣기
$ hdfs dfs -put ~/hadoop/etc/hadoop/`*.xml` /mydata- Hadoop Cluster에서 텍스트 파일 검색하기
$ hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /mydata /output2 'dfs[a-z.]+'Hadoop MapReduce의 예제 중 하나인 grep 실행
하둡 클러스터에서 텍스트 파일을 검색
/mydata 경로에 있는 텍스트 파일을
dfs[a-z.]+라는 문법 (dfs가 들어가는 거를 wordcount)을 통해서 작업할거고, 그 아웃풋을 /output2 에 담겠다.
-
MapReduce 성공 결과 세부 내역 확인
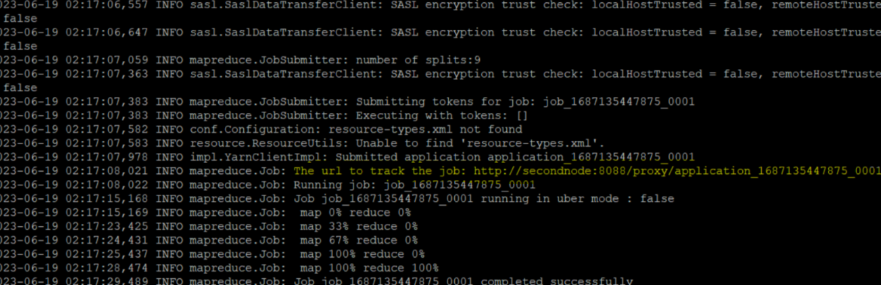
노란색 url 경로를 들어가면 아래 그림과 같이 확인할 수 있다.
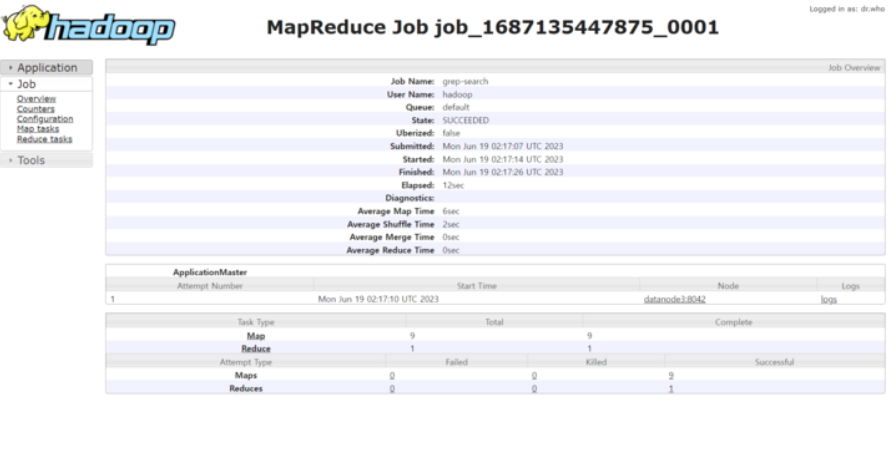
-
결과 확인
$ hdfs dfs -cat /output2/*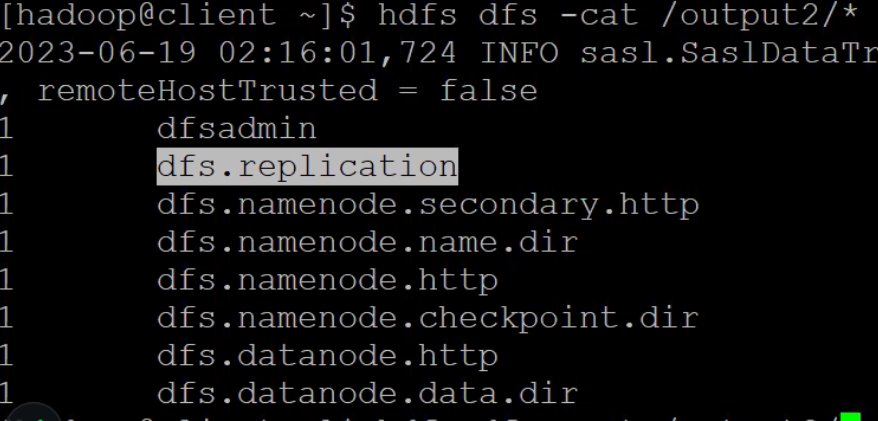

공부 기록