
최근 팀에서 자체 NLU 모델을 개발하며 안정적인 Multi-model Serving에 요구가 생겼습니다. 그 동안 NLU 엔진은 DialogFlow, Watson, Lex 등의 서비스에 비용을 지불하며 SDK로 연동해왔으나, 추론 성능, 모델 관리, 비용 등에 제약이 많았습니다. 따라서 좀 더 유연한 모델 생성 및 관리, 지속적인 학습, 빠른 추론 성능을 위한 NLU 파이프라인을 구축해나가기 시작했고 그 중 가장 고민을 많이 한 부분은 모델 서빙 파트였습니다.
현재 운영중인 서비스의 NLU 모델은 각 유저(에이전트)마다의 학습모델이 존재합니다. 즉, 10명의 고객이 있다면 10개의 모델이 존재하는 것이죠. 고객이 늘어날수록 관리해야하는 모델도 선형적으로 증가하게 됩니다.
추론 서버 구성에 앞서 우선 FastAPI에서 동작하는 비동기 추론 서버를 생성하여 테스트를 진행해보았습니다. 현재 팀 내 모든 서비스는 Kubernetes 위에서 동작하기 때문에 스케일 인/아웃으로 어느 정도 트래픽을 커버할 수 있으리라 생각하였습니다. 하지만 역시나 문제가 있습니다. 모델은 1~5mb정도로 작은 사이즈이지만 예를 들어 10,000명의 고객이 서비스를 동시에 이용하게 될 경우, 약 50GB 상당의 모델이 모두 메모리에 올라가야 합니다. 이 상태로는 스케일 아웃이 된다해도 굉장히 비효율적일 것 입니다.

다른 방안으로 고민한 것은 Amazon SageMaker의 Multi-Model Endpoint 구조였습니다. Multi-Model Endpoint는 다수의 모델 서빙을 위해 다수의 컨테이너에 모델을 고유하게 분배하여 관리하는 방법입니다. 만약 10개의 모델이 있고, 5개의 컨테이너가 있다면 각 컨테이너 당 2개의 모델씩 분배하여 안정성과 확장성을 잡을 수 있는 방법입니다.
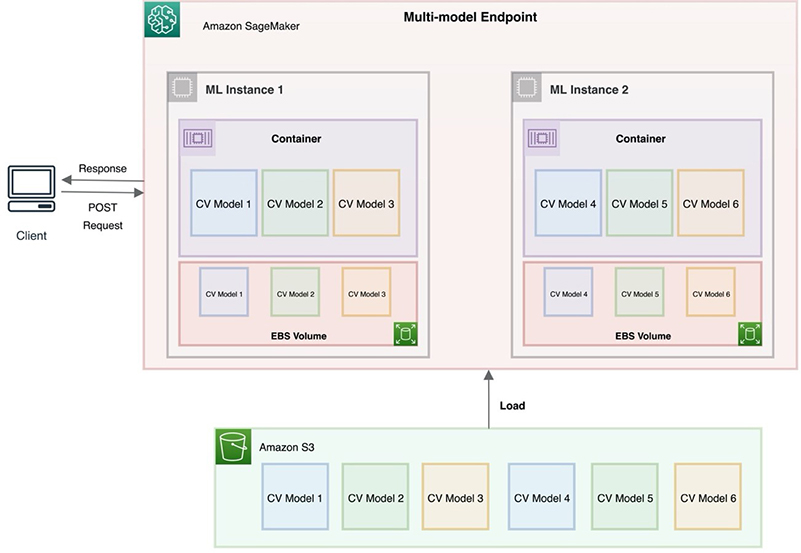
하지만 SageMaker 서비스를 사용한다면 모를까, 위와 같은 방식으로 모델을 관리하기에는 어려움 뿐만 아니라 안정성도 확보하기 힘들었습니다. 우선 각 컨테이너 마다 고유의 모델이 분배되기 때문에 스케일 인/아웃되는 Stateless 서비스를 이용하는데 한계가 있었고, Statefulset 방식으로 운영하더라도 모델이 늘어날수록 관리해야하는 컨테이너가 지속적으로 늘어나야 하기 때문에 비용적인 측면에서 비효율적이었습니다.
RedisAI
다른 방법을 고민하며 정리해보던 중 지금 상황에서 고려되어야 하는 부분은 아래 4가지였습니다.
- 여러 딥러닝 프레임워크를 동시에 서빙할 수 있어야 한다. (유연성 측면)
- 쿠버네티스 위에서 동작하며 스케일 아웃이 가능해야한다. (확장성 측면)
- 모델들이 컨테이너 마다 고유하게 분산 저장되어 관리되어야한다. (안정성 측면)
- 모델들이 미리 메모리에 로드되어있어 빠르게 추론이 가능해야한다. (퍼포먼스 측면)
그러던 와중에 위의 4가지를 모두 만족시켜주는 서비스를 찾게 되었는데, 그것이 바로 소개드릴 RedisAI입니다.
서두가 길었지만 본 글에서는 RedisAI가 무엇인지 소개하며 더불어 RedisAI와 FastAPI를 활용하여 간단한 추론 서버를 구축해보도록 하겠습니다.
이후 이어지는 2편에서는 Scaliability를 위한 RedisAI Cluster 구축방안에 대해 소개하고자 합니다.
1. RedisAI
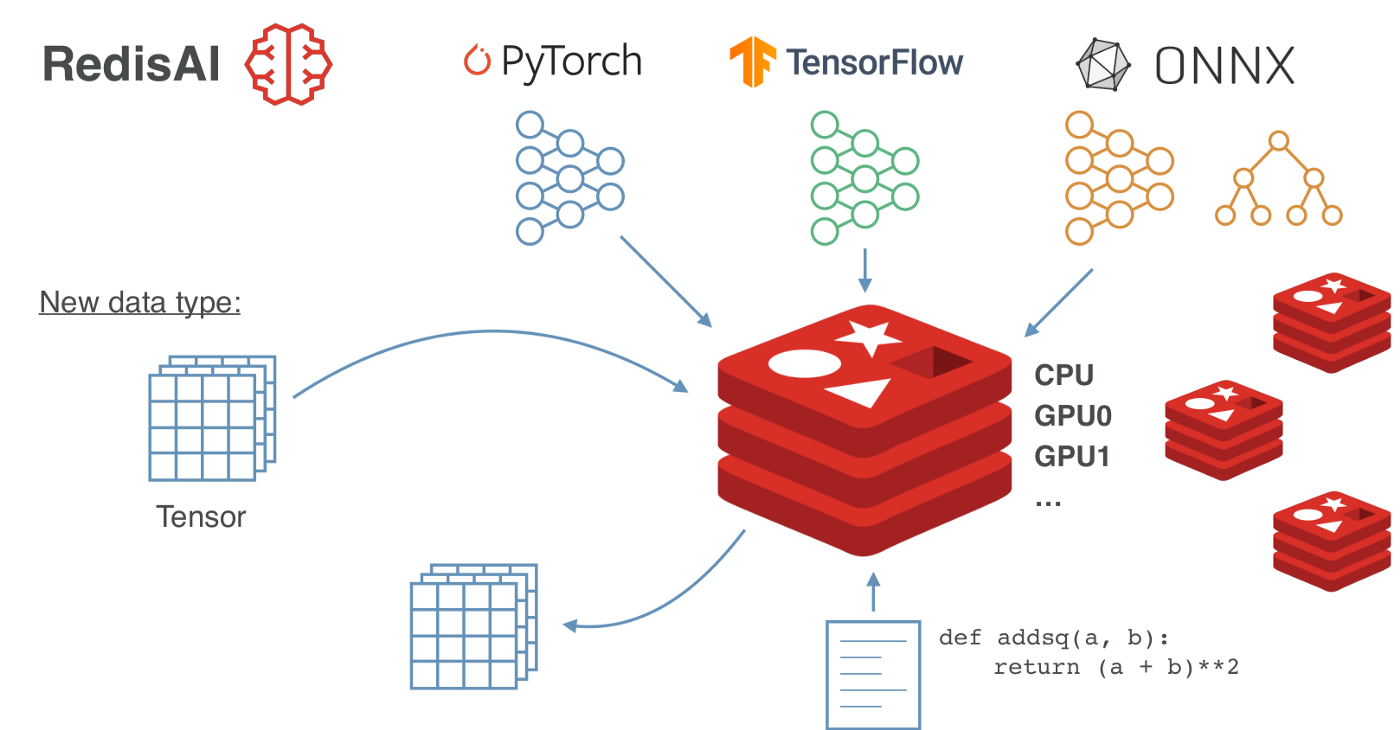
RedisAI는 이름에서부터 알 수 있듯이 Cache DB로 많이 사용되는 Redis를 만든 Redis Labs에서 만들어진 오픈소스 입니다.
RedisAI는 In-Memory 방식인 Redis의 장점을 그대로 머신러닝에 적용한 서비스라고 생각하면 됩니다. 가장 큰 차이점은 int, float, str 타입의 데이터 뿐만 아니라 tf, torch, onnx 같은 ml프레임워크 모델을 저장할 수 있다는 것입니다. 또한 모델이 메모리에 이미 올라가있기 때문에 로드시간이 거의 소요되지 않는다는 것과 추론 연산을 RedisAI서버 내에서 수행한다는 것이 큰 특징입니다.
또한 RedisAI는 기본적으로 Redis위에서 동작하기 때문에, Redis를 이미 이용하고 있다면 RedisAI 모듈만 따로 로드해주는 것만으로도 RedisAI 서비스를 이용할 수 있습니다.
1.1. RedisAI Architecture
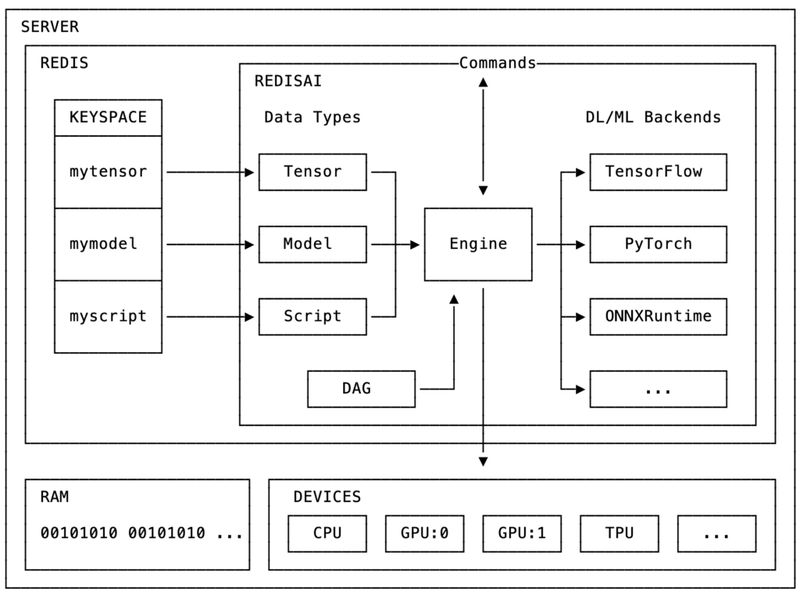
RedisAI의 가장 큰 장점은 바로 특정 프레임워크에 종속될 필요없는 유연성을 가지고 있다는 것입니다. 일반적으로 회사마다 기 구축된 머신러닝 프레임워크가 있고 그 안에서 tf를 사용하느냐, torch를 사용하느냐, sklearn을 사용하느냐에 따라 train, inference 코드가 달라지기 때문에 개발환경이 고착화 될 수 있습니다. 하지만 각 프레임워크마다 주는 특징과 장점이 있고 저도 파인튜닝같은 작업을 할때는 tf나 torch를 사용하는 반면, 가벼운 분류모델을 만들때는 sklearn을 주로 사용하기 때문에 다양한 프레임워크를 지원해준다면 좋을 것 같다는 생각을 하였습니다.
RedisAI는 우선 어떤 프레임워크를 사용하던 tensor라는 메인 데이터 타입을 이용하고 있기에 굳이 input type을 앞단에서 고려할 필요가 없습니다. 또한 현재 머신러닝 프레임워크로서 Tensorflow, PyTorch, ONNX 등을 지원하고 있기에 모델러에게 좀 더 편한 혹은 각 task에 적합한 프레임워크로 모델을 각각 생성하여 활용할 수 있고, 모델 추론 연산 또한 RedisAI 서버 내에서 이루어지기 때문에 프레임워크별 추론 코드를 별도로 만들 필요도 없습니다.
1.1.1. Data Type
RedisAI의 ML 데이터의 가장 일반적인 representation인 Tensor 타입을 이용합니다. RedisAI에 저장되는 모든 데이터는 tensor타입을 가지기 때문에 Tensorflow, Torch 등과 같은 다양한 프레임워크와 호환됩니다.

1.1.2. Model Type
현재 RedisAI에서 지원하는 ML frameworks는 Tensorflow, Tensorflow Light, Pytorch, ONNX 입니다. (앞으로 더 많은 프레임워크를 지원할 예정이라고 합니다.)

1.2. Benchmarking RedisAI
Redis 홈페이지에서 소개하는 RedisAI의 코어 밸류는 아래 2가지 입니다.
- Minimizing end-to-end inferencing time by reducing the time spent on processes other than inferencing.
- Simplifying a scalable deployment of AI models.
굉장히 빠른 inference를 강점으로 소개하고 있는만큼 RedisAI의 벤치마크 결과에 대해 공식 홈페이지에 올라와 있는 내용을 간단히 소개드리겠습니다.
우선 벤치마크를 위한 비교 대상은 아래 4가지 입니다.
- TorchServe: built and maintained by Amazon Web Services (AWS) in collaboration with Facebook, TorchServe is available as part of the PyTorch open-source project.
- Tensorflow Serving: a high-performance serving system, wrapping TensorFlow and maintained by Google.
- Common REST API serving: a common DL production grade setup with Gunicorn (a Python WSGI HTTP server) communicating with Flask through a WSGI protocol, and using TensorFlow as the backend.
- RedisAI: an AI serving engine for real-time applications built by Redis and Tensorwerk, seamlessly plugged into Redis.
RedisAI is written in C/C++, TensorFlow Serving in C++, TorchServe is written in Java, and the common REST API servers are written in Python
1.2.1. Baseline latency comparing different solutions
첫번째 비교 실험은 어떤 DB와의 커넥션없이 오로지 single client내에서 데이터 처리 및 추론을 했을 때의 결과입니다.


위 결과를 보면 RedisAI가 inference per second 및 inference time에서 가장 우수한 것을 확인할 수 있습니다. inference per second의 경우 Torchserve에 비해 약 4.6배, HTTP server에 비해 7.1배 높은 것을 확인할 수 있습니다.
1.2.2. Impact of latency with reference data
두번째 비교 실험은 Redis로 부터 데이터를 request/response 후 모델 서버에서 추론을 진행했을 때의 결과입니다.
우선 Tensorflow Serving, TorchServe, HTTP Server의 경우 Redis를 참조 후 추론이 이루어지는 반면, RedisAI의 경우 이미 Redis위에서 동작하기 때문에 따로 request/response 과정이 생략된다는 점이 실험의 차이점입니다.

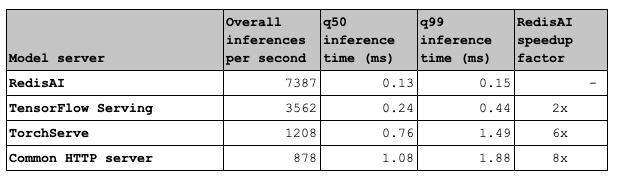
위 결과는 더울 놀라운 결과를 보여줍니다. inferences per second의 경우 TorchServe에 비해 6배, HTTP server에 비해서는 무려 8.4배 빠른 성능을 보입니다.
1.2.3. Scale on highly concurrent scenarios
위의 실험들은 single-client 상에서의 퍼포먼스 테스트였다면 이번 실험은 다수의 클라이언트에 대한 부하 테스트 결과입니다. 16개의 클라이언트에서 최대 160개의 클라이언트가 초마다 16개씩 증가하는 시나리오입니다.
RedisAI 이외의 대상들의 inference per seconed가 50k를 넘지 못하는 것에 반해 RedisAI는 192k까지 향상합니다. 😮
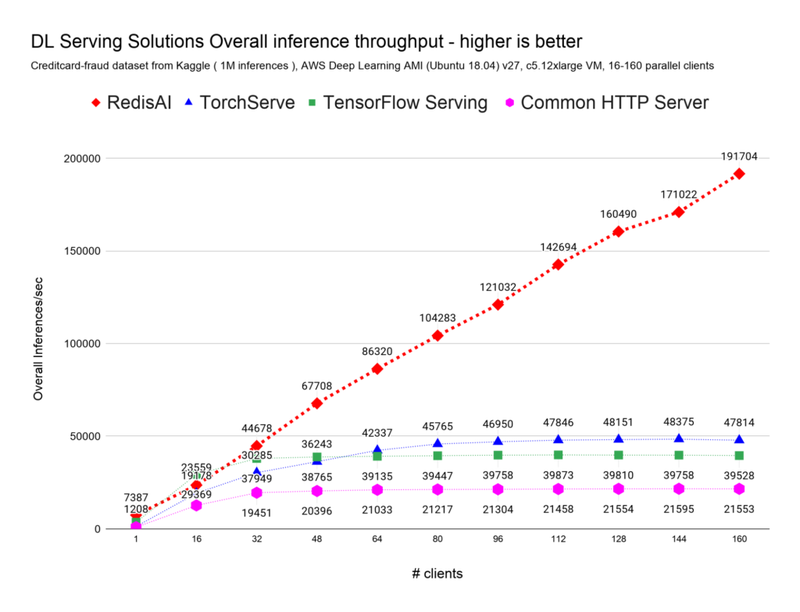
전반적인 퍼포먼스를 측정해보았을 때, 역시나 RedisAI가 가장 빠르며 두번째로 높은 성능인 TorchServe와는 16x 차이를 보입니다.
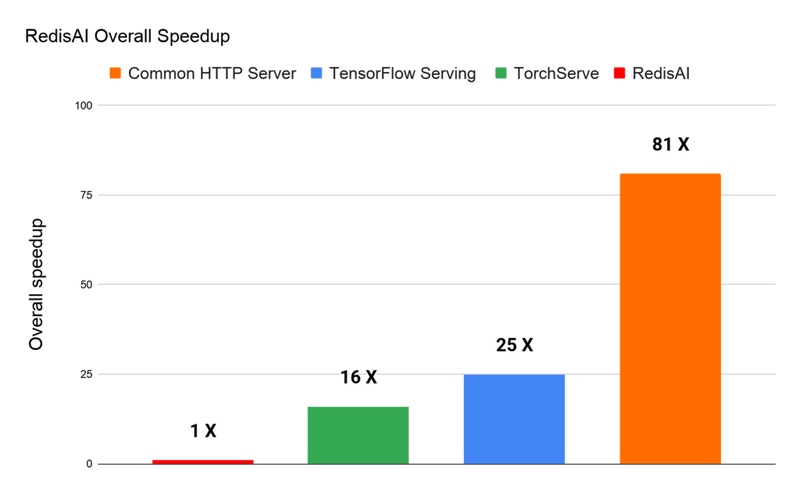
벤치마크에 대한 자세한 내용은 공식 홈페이지 참고
2. RedisAI Usages
2.1. Install RedisAI
RedisAI를 사용하는 가장 간편한 방법은 Docker 이미지를 이용하는 것입니다. RedisAI 이미지를 이용할 수도 있고, RedisMods 이미지에서 RedisAI를 로드하는 방식으로도 이용할 수 있습니다.
# RedisAI image
docker run -p 6379:6379 redislabs/redisai:latest
# or
# Load RedisAI module on RedisMod image
docker run -p 6379:6379 redislabs/redismod --loadmodule /usr/lib/redis/modules/redisai.so2.2. RedisAI Commands
RedisAI는 기본적으로 Redis와 거의 유사합니다. key-value 형태의 값을 set으로 저장하고, get으로 호출합니다. 다른 점은 데이터에 관련된 작업을 할때는 TENSOR가 붙고 (ex. TENSORSET, TENSORGET 등) 모델과 관련된 작업에서는 MODEL이 붙습니다. (MODELSET, MODELGET 등)
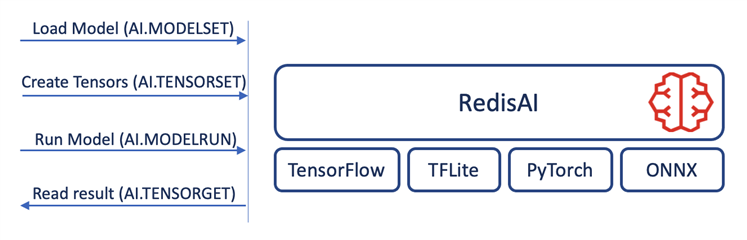
RedisAI의 다양한 커맨드는 해당 링크를 참조
3. Build model serving API with FastAPI + RedisAI
FastAPI를 프록시로 하여 RedisAI와 연동 후 모델 학습 및 추론을 하는 간단한 API 예제를 소개합니다.
사용된 데이터셋은 흔히 알고 있는 iris 분류 데이터셋이며, sklearn의 LogisticRegression모델을 통해 학습된 모델을 ONNX로 변환 후, RedisAI에 저장하고 저장된 모델을 통해 추론을 수행하는 예제입니다.
데모를 위해 사용된 전체 코드는 github를 참고
3.1. Setup
Install RedisAI
Docker 이미지를 활용하여 RedisAI를 실행합니다.
docker run -p 6379:6379 redislabs/redisai:latestInstall dependencies
필요한 dependency를 설치합니다.
numpy
pandas
scikit-learn
skl2onnx
onnxmltools
onnxruntime
redisai
ml2rt
uvicorn
fastapi3.2. RedisAI Client
RedisAI는 다양한 언어를 위한 SDK를 제공하고 있습니다. 본 예제에서는 Python SDK를 사용합니다.
RedisAI의 python sdk는 해당 링크를 참고
아래와 같이 RedisAI 클라이언트를 생성할 수 있으며, tensor, model, script 등의 데이터 타입에 대한 CRUD 메소드를 모두 제공합니다.
from redisai import Client
redisai_client = Client(host='localhost', port=6379)3.3. Model Build and Deploy
해당 코드는 모델을 학습 후 RedisAI에 저장하는 /train 엔드포인트 입니다.
iris 데이터를 로드 후 sklearn의 LogisticRegression 모델을 통해 학습을 진행하였습니다. RedisAI의 경우 아직 scikit-learn을 지원하고 있지 않기 때문에 학습된 sklearn 모델을 RedisAI에 저장하기 위해서는 tf, torch, onnx 중 하나를 선택해야 합니다. 본 예제는 학습된 sklearn 모델을 ONNX로 모델을 변환 후 이를 RedisAI로 저장하는 과정을 수행하였습니다.
# model output path
MODEL_OUTPUT_PATH = './_output/iris.onnx'
@app.get('/train')
async def train():
# 1. Prepare the train and test data
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 2. Train the model - using logistic regression classifier
model = LogisticRegression(max_iter=5000)
model.fit(X_train, y_train)
# 3. Convert sklearn model to ONNX model
dummy = X_train[0].astype(np.float32)
save_sklearn(model, MODEL_OUTPUT_PATH, prototype=dummy) # save model to MODEL_OUTPUT_PATH
# 4. Set ONNX model to RedisAI
model_name = 'iris-clf'
model = load_model(MODEL_OUTPUT_PATH)
redisai_client.modelset('iris-clf', 'onnx', 'cpu', model)
print(f">> '{model_name}'' model is saved to RedisAI 🟢.")- iris 데이터를 로드 후 train/test셋을 분리합니다.
- sklearn 모델을 통해 모델을 학습합니다.
- save_sklearn() 메소드를 통해 sklearn모델을 ONNX 포맷으로 변환합니다.
- modelset() 메소드에 모델 이름, 백엔드(tf, torch, tflite, onnx), device(cpu, gpu), 모델 객체를 넣어주면 모델 이름을 key값으로 하여 저장됩니다.
3.4. Inference
해당 코드는 RedisAI에 저장된 모델을 통해 Inference를 수행하는 /inference 엔드포인트 입니다.
Arguements로는 model 이름과 iris 데이터를 input으로 받도록 구성하였습니다.
# model output path
MODEL_OUTPUT_PATH = './_output/iris.onnx'
@app.get('/inference')
async def inference(model: str, sepal_length: float, sepal_width: float, petal_length: float, petal_width: float):
# 1. Check Model in RedisAI
try:
model_meta = redisai_client.modelget(f'{model}', meta_only=True)
print(f">> '{model}'' model is active on RedisAI 🟢.")
print(model_meta)
except:
model_meta = None
print(f">>{model}' model is not active on RedisAI. 🔴")
return JSONResponse({'status':'fail', 'class':None})
if model_meta:
# 2. Set input tensor
input_value = [sepal_length, sepal_width, petal_length, petal_width]
intput_tensor = np.array(input_value).astype(np.float32)
redisai_client.tensorset(f'{model}:in', intput_tensor)
# 3. Predict
redisai_client.modelexecute(model, inputs=[f'{model}:in'], outputs=[f'{model}:out1', f'{model}:out2'])
# 4. Get result
out = redisai_client.tensorget(f'{model}:out1')[0]
labels = ['setosa', 'versicolor', 'virginica']
print(labels[out])
return JSONResponse({'status':'success', 'pred':labels[out]})- 먼저 Argument에 입력된 model 이름을 key값으로 갖는 모델이 RedisAI에 있는지 확인합니다.
- 모델이 존재한다면 입력된 iris 데이터를 numpy array 타입으로 변환 후 tensorset() 메소드를 통해 'model이름:in'(ex. iris-clf:in) 라는 키값에 input값을 저장합니다.
- modelexecute() 메소드에 사용할 모델 키값과 2번에서 저장된 input 키값, 그리고 예측결과를 저장할 output 키값을 전달하여 예측을 수행합니다.
- 3번이 정상적으로 수행되었다면 output 키값에 예측값이 저장되며, 이를 tensorget() 메소드를 통해 값을 리턴받습니다.
3.6 API Test
- 우선 FastAPI 서버를 구동합니다.
uvicorn main:app - 모델 학습 엔드포인트를 호출합니다.
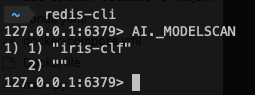
http GET "localhost:8000/train"redis-cli에서 AI._MODELSCAN 커맨드를 통해 모델이 잘 저장되었는지 확인할 수 있습니다.
$ redis-cli AI._MODELSCAN
- 추론 엔드포인트를 호출합니다.
http GET "localhost:8000/inference?model=iris-clf&sepal_length=4.7&sepal_width=3.2&petal_length=1.6&petal_width=0.2"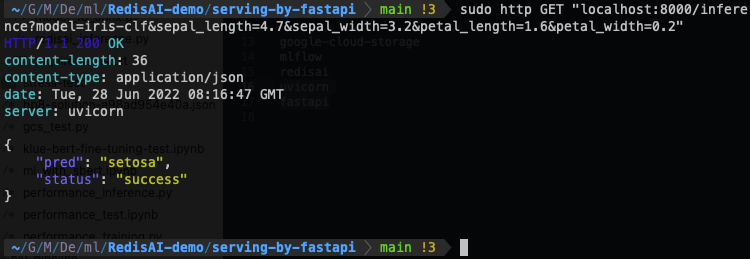
Conclusion
RedisAI는 redis의 in-memory db라는 장점을 가지고 있다는 점에서 확실히 사용성 및 퍼포먼스가 좋다고 느껴졌습니다. 하지만 실제로 운영환경에서 RedisAI가 사용된 사례는 국내 레퍼런슨느 거의 전무했고 해외에서도 조차 많지가 않았습니다.
왜 그럴까하고 이를 운영 서비스에 적용해보려고 시도해보던 중 이유를 알게되었습니다.
일반적으로 Redis를 운영할때는 확장성을 위해 Redis Cluster를 구축하는 경우가 많고 이를 위해 ElasticCache for redis 혹은 Redis Enterprise와 같은 클라우드 서비스를 이용하는 경우가 많습니다. 하지만 Redis Labs에 직접 문의해본 결과 RedisAI 모듈은 아직 위와 같은 클라우드 서비스에서 이용할 수 없다는 답변을 받게 되었습니다.

RedisAI 1.0을 릴리즈 한지 꽤 오랜시간이 지났음에도 아직 이러한 작업이 이루어지지 않았다는 것이 좀 의아했습니다.
하지만 길이 막혔다면 길을 뚫어서라도 가야 하는 법.
위의 서비스를 이용할 수 없다면, 직접 Redis Cluster를 구축 후 RedisAI 모듈을 연동하는 것이 가능하리라 생각되었고, 결론적으로는 가능했습니다.
다음 글에서는 Redis Cluster 구축 및 RedisAI 모듈 연동에 대해 소개하도록 하겠습니다.
References
.jpeg)