
Intro of Intro
오랜만에 글을 쓰는것 같다. 아무도 안궁금하겠지만, 근황을 말하자면.. 취준생에서 증권사 fe -> 블록체인 be, fe -> 통신사 be -> 통신사 devops 로 아주 짧은 시간에 여러 분야를 거쳤고 다음 스텝으로 MLOps 를 공부하기 위해 해당 시리즈를 작성하려고 한다.
나의 velog를 보면 상당한 텀이 존재하는데, 그만큼 실무 경험이 쌓인 만큼 이전과는 달리 조금 전문적인 ( 그러나 읽기 쉬운 ) 글을 쓰도록 노력해보겠다.
없겠지만, 근황 궁금한게 있다면 댓글로... ( TMI 방출 상시대기중.. )
Intro
이번 시리즈에서 다루는 MLOps는 단순히 머신러닝 모델을 프로덕션에 배포하는 것을 넘어, 시스템 개발과 운영을 통합하고 간소화하며 최적화하는 과정으로 데이터 엔지니어, ML 엔지니어, IT 전문가 간의 협업을 포함하여 머신러닝 애플리케이션의 엔드투엔드 라이프사이클을 자동화하고 최적화하는 것을 목표로 한다. ( 다소 거창하지만 원래 Devops의 목표와 동일하다.)
MLOps란?
MLOps는 다양한 도구와 기술을 활용하여 전체 머신러닝 파이프라인을 프로덕션화하고 자동화하는 데 도움을 준다.
🙋 Devops와 차이점은 뭔가유?
🤖 Devops의 확장 개념으로 기존의 Devops에서 머신러닝에 대한 몇가지 Task가 추가 되었다고 생각하면 됨.
🙋 그게 뭐냐고 그니까.
🤖 밑에서 설명해줌...
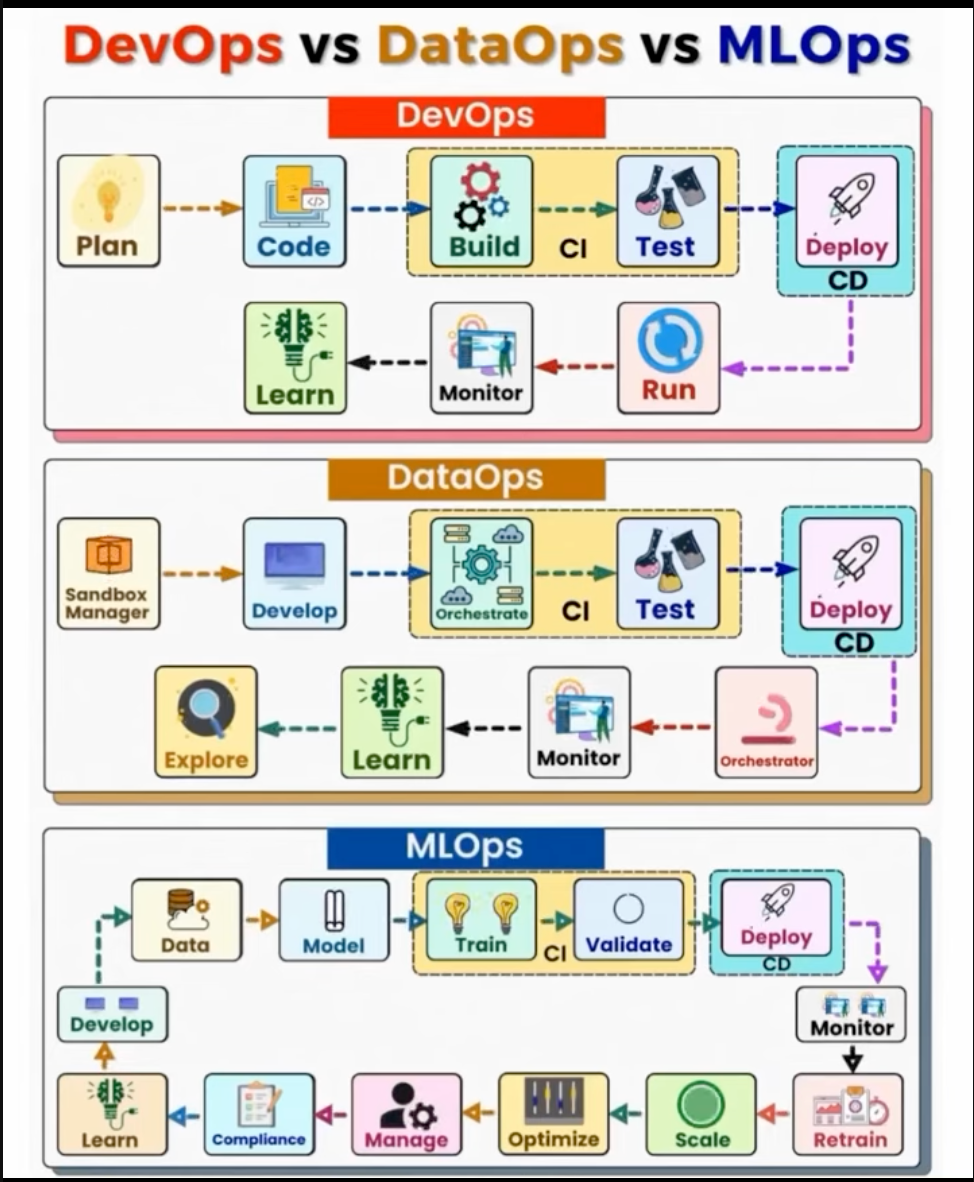
사진을 보면 Devops는 뭔가 간단해보이는데, MLOps는 뭔가 더 추가된걸 볼 수 있다.
차이점을 보이는 이유는 크게 두가지인데,
- 적용 대상의 특수성:
- DevOps: 일반적인 소프트웨어 애플리케이션에 초점
- MLOps: 머신러닝 애플리케이션의 고유한 특성에 중점. 머신러닝은 모델 구축 그 이상이며, 모델을 생산화하고 확장하는 방법을 라이프 사이클에 녹여내는게 중요하다.
- MLOps에 추가된 (or 확장된) Task
- 데이터 관리(Data Management): 다양한 소스(데이터베이스, 스트리밍 서비스, API 등)에서 데이터를 수집하고 중앙 집중식으로 저장하는 파이프라인 구축을 포함함. 이는 전통적인 접근 방식에서 데이터 주입 및 관리의 어려움을 해결합니다.
- 버전 제어(Version Control): 코드뿐만 아니라 데이터와 모델에 대한 버전 관리를 포함함.
- 파이프라인 자동화(Automation/Pipeline): 데이터 수집, 전처리, 모델 훈련, 평가, 배포 등 순차적으로 실행되는 머신러닝 파이프라인의 자동화를 가능하게 한다.
- 실험 추적(Experiment Tracking): 하이퍼파라미터 튜닝과 같은 다양한 실험의 결과를 체계적으로 기록하고 시각화하여 최적의 모델을 선택하는 데 사용됩니다. MLflow와 같은 전용 도구가 활용됩니다.
- 재훈련(Retraining): 데이터 분포의 변화나 모델 성능 저하 시, 모델을 자동으로 재훈련하여 성능을 유지하거나 개선합니다
그래서 MLOps에서 뭐가 중요한데?
DevOps를 보면 아무리 아름다운 과정을 넣어도 결국은 SW가 잘 배포되었냐? 가 중요한것 처럼 당연하게도 MLOps에서 가장 중요한건 어떻게 모델을 프로덕션 하는지가 가장 중요하다.
즉, 모델을 실제 서비스 환경에서 안정적이고 효율적으로 운영할 수 있도록 하는 '프로덕션화'와 이 과정을 효율적으로 만드는 '자동화'가 핵심이다. 이 두 가지는 MLOps의 존재 이유이자 가장 큰 이점이라고 볼 수 있다.
🙋 모델 프로덕션이라는게 뭔데?
🤖 단순히 모델을 만드는 것을 넘어, 대규모의 실제 사용자에게 서비스를 제공할 수 있도록 모델을 견고한 인프라와 아키텍처 위에 배포하고 확장하는 것을 의미해.
🙋 당연한거 아냐..?
🤖 전통적인 방식에서는 모델을 개발한 후 실제 서비스에 배포하고 많은 사용자가 몰렸을 때 시스템이 제대로 작동하지 못하는 확장성 문제가 흔했어.
🙋 왜 그랬던건데..?
🤖 예를 들어, 치킨집을 한다고 가정하면 주문이 폭주했을 때 수동으로 재료를 조달하고 요리하던 방식으로는 감당할 수 없었지만, 재료 공급망을 자동화하고 더 큰 요리 기계를 도입하여 대량의 주문을 처리할 수 있게 된 것과 같아.
🙋 이해가 잘 안가는데, 그래서 어떻게 그게 해결된거냐고
🤖 MLOps는 CI/CD(지속적 통합/지속적 배포) 파이프라인과 Docker와 같은 컨테이너화 도구를 활용하여, 서비스 중단 없이 새로운 기능을 추가하고 애플리케이션을 업데이트할 수 있도록 해줘.
확장성의 경우 클라우드가 발전하며 AWS, GCP, Azure와 같은 클라우드 플랫폼에서 EC2, S3, ECR, SageMaker, CodePipeline 등 다양한 서비스를 활용하여 인프라를 효율적으로 관리 할 수 있게 되었어.
모델 프로덕션의 경우 위와 같이 정의 및 현황을 알아 봤으니 이제 MLOps에서 어떤 부분을 자동화 해야하는지 알아보자.
자동화
-
정의 및 목표: MLOps의 핵심은 머신러닝 파이프라인의 모든 단계를 자동화하여 인간의 개입을 최소화하고 효율성과 견고성을 극대화하는 것이야. 자동화를 통해 데이터 수집부터 모델 배포, 모니터링, 재훈련에 이르는 전 과정을 끊김 없이 연결할 수 있지.
-
파이프라인 자동화: MLOps는 데이터 수집(Data Ingestion), 데이터 검증(Data Validation), 데이터 변환(Data Transformation), 모델 훈련(Model Training), 모델 평가(Model Evaluation), 예측(Prediction) 등의 순차적인 단계를 파이프라인으로 구성하고 자동으로 실행될 수 있도록 지원해.
-
데이터 관리 자동화: MLOps는 데이터 웨어하우스와 데이터 주입 파이프라인을 구축하여 다양한 소스(데이터베이스, 스트리밍 서비스, API 등)의 데이터를 자동으로 수집하고 중앙 집중적으로 저장할 수 있게 해줘. 이는 데이터 드리프트(Data Drift)와 같은 문제를 감지하고 자동으로 모델을 재훈련하여 성능을 유지하는 데 필수적이다.
- 코드 구현 자동화: MLOps는 주피터 노트북과 같은 단일 파일 방식 대신 모듈형 코딩을 권장하여, 데이터 주입, 검증, 변환, 모델 훈련 등 각 단계를 별도의 컴포넌트로 분리해. 이렇게 분리된 컴포넌트들은 유지보수, 재사용, 협업, 테스트를 용이하게 하며, DVC(Data Version Control)와 같은 도구를 통해 파이프라인 실행을 추적하고 자동화할 수 있다.
- 버전 관리 자동화: Git 및 GitHub를 사용하여 코드베이스뿐만 아니라 데이터와 모델까지 버전 관리를 자동화하여, 변경 사항을 추적하고 필요할 때 이전 버전으로 쉽게 되돌릴 수 있게 해준다.
- 실험 추적 자동화: MLflow와 같은 MLOps 도구는 하이퍼파라미터 튜닝과 같은 다양한 실험의 결과를 자동으로 기록하고 시각화된 사용자 인터페이스로 제공해. 이를 통해 수동으로 결과를 기록하고 비교하던 방식에서 벗어나, 가장 성능이 좋은 모델을 효율적으로 식별할 수 있다.
- CI/CD를 통한 배포 자동화: 코드 변경 사항이 발생하면 Jenkins, CircleCI, GitHub Actions와 같은 CI/CD 도구를 통해 자동으로 테스트, 빌드, 배포되어 지속적으로 애플리케이션을 업데이트할 수 있게 해줘. Docker를 이용한 컨테이너화는 환경 간의 일관성을 보장하며, 배포 과정의 오류를 줄여준다.
그래서 정확히 어떻게 이걸 구성하는데?
MLOps의 정의와 중요성을 이해했다면, 왜 그렇게 다양한 도구와 기술이 필요한지 명확히 알 수 있다. MLOps는 머신러닝 시스템의 복잡한 엔드투엔드 라이프사이클을 관리하기 위해 여러 핵심 구성 요소로 이루어져 있으며, 각 구성 요소는 특정 기능을 수행하는 데 필요한 전문 도구와 기술을 요구하기 때문이다.
-
데이터 관리 및 수집 (Data Management & Ingestion):
- MLOps는 데이터 웨어하우스를 구축하고 ETL(Extract, Transform, Load) 파이프라인을 생성하여 다양한 소스(데이터베이스, 스트리밍 서비스, API 등)에서 데이터를 자동으로 수집하고 저장하는 데 중점을 둔다.
- 이러한 과정에는 Kafka, Apache Kafka와 같은 스트리밍 서비스 도구와 MongoDB, MySQL과 같은 데이터베이스 지식이 필요할 수 있다. 이는 MLOps가 데이터 엔지니어링 개념과 밀접하게 연결되어 있기 때문이다.
-
버전 관리 (Version Control):
- 코드뿐만 아니라 데이터와 모델까지도 변경 사항을 추적하고 필요할 때 이전 버전으로 되돌릴 수 있도록 버전 관리가 필수적다.
- 이를 위해 Git, GitHub, Bitbucket과 같은 도구가 사용된다. 특히 데이터 버전 관리를 위해서는 DVC(Data Version Control)와 같은 도구가 활용된다.
-
자동화 및 ML 파이프라인 (Automation & ML Pipelines):
- MLOps의 핵심은 데이터 수집부터 모델 훈련, 평가, 배포에 이르는 전 과정을 자동화된 파이프라인으로 구축하는 것이다.
- 파이프라인 구축을 위해 DVC가 주요 도구로 언급되며, Kubeflow, Airflow와 같은 도구가 가장 유명하다.
- 코드 구현 측면에서는 주피터 노트북과 같은 단일 파일 방식 대신, 유지보수, 재사용, 협업, 테스트 용이성을 위해 각 단계를 별도의 컴포넌트로 분리하는 모듈형 코딩 방식(Python OOP 개념 포함)이 권장된다.
-
실험 추적 (Experiment Tracking):
- 하이퍼파라미터 튜닝과 같이 다양한 모델 실험 결과를 자동으로 기록하고 시각화하여 최적의 모델을 효율적으로 식별하는 기능이 필요함.
- 이러한 실험 추적을 위해 MLflow라는 강력한 도구로 사용된다. MLflow는 사용자 인터페이스를 통해 실험 결과를 비교하고 최적의 모델을 선택할 수 있다.
-
CI/CD (Continuous Integration/Continuous Delivery/Deployment):
- 코드 변경 사항이 발생하면 자동으로 테스트, 빌드, 배포되어 서비스 중단 없이 애플리케이션을 지속적으로 업데이트하는 과정이다.
- Jenkins, CircleCI, GitHub Actions와 같은 CI/CD 도구들이 활용되며, 애플리케이션의 일관된 실행 환경을 보장하기 위해 Docker를 사용한 컨테이너화가 필수적이다.
-
모니터링 및 재훈련 (Monitoring & Retraining):
- 배포된 모델의 성능을 지속적으로 모니터링하고(예: 데이터 드리프트 감지), 성능 저하 시 자동으로 모델을 재훈련하는 시스템이 필요하다.
- 모니터링에는 Grafana, Evidently와 같은 도구가 사용되며, 재훈련은 자동화된 파이프라인(DVC, Airflow 등)을 통해 이루어진다.
-
인프라 관리 및 배포 (Infrastructure Management & Deployment):
- ML 모델은 실제 프로덕션 환경에서 대규모 트래픽을 처리할 수 있도록 견고한 인프라 위에 배포되어야 한다.
- 이를 위해 AWS, GCP(Google Cloud Platform), Azure와 같은 클라우드 플랫폼이 사용되며, 각 플랫폼 내의 다양한 서비스(예: AWS의 EC2, S3, ECR, IAM, SageMaker, CodePipeline; GCP의 Vert.x AI, GCS buckets, VM instances)가 활용된다.
- 특히, 프로덕션 서버의 대부분이 Linux 기반 운영 체제를 사용하며, 머신러닝 및 딥러닝 프레임워크(Scikit-learn, TensorFlow, PyTorch 등)가 Linux에 최적화되어 있어 Linux 명령어를 다루는 능력도 중요하다.
결론
이렇게 대충 MLOps란 뭐고 어떤걸 중요하게 생각하는지, 이를 위해 어떤 구성으로 Flow를 제공하고 어떤 도구를 주로 사용하는지 어렴풋이 다루게 되었다.
앞으로는 각각 구성에 대해서 자세히 보며 어떻게 할지 딥다이브 할 예정이다.
