▷ 오늘 학습 계획: 딥러닝 강의(10~13)
📖 06_Transfer Learning
잘 학습된 모델의 weight 가지고 오기
- 내 모델에 맞게 weight를 수정하여 학습(Trainable)
- weight 고정(Freeze)
from torchvision import models
resnet = models.resnet50(pretrained=True)
# 학습이 완료된 weight 받아오기(False로 지정하면 구조만 가져온다.)
# 가져온 모델과 내 모델의 클래스 숫자가 다르다.
num_ftrs = resnet.fc.in_features_
# resnet50의 마지막 fully-connected layer의 채널 수
resnet.fc = nn.Linear(num_ftrs, 33)
criterion = nn.CrosEntropyLoss()
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, resnet.parameters()), lr=0.001)
# 마지막 fully-connected layer 33개는 학습이 안되어 있어서
from torch.optim import lr_scheduler
# epoch에 따라 learning rate를 바꿔준다.
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
# 7 epoch 마다 0.1씩 learning rate를 감소시킨다.
# resnet의 10개 layer중에 입력에 가까운 5번 layer까지는 학습하지 않도록 freeze
ct=0
for child in resnet.children():
ct += 1
if ct < 6:
for param in child.parameters():
param.requires_grad = False전이 학습 유형
- 큰 데이터셋, pre-trained 모델의 데이터셋과 다른 경우: 모델 전체 훈련
- 큰 데이터셋, pre-trained 모델의 데이터셋과 유사한 경우: 일부 레이어 훈련
- 작은 데이터셋, pre-trained 모델의 데이터셋과 다른 경우: 일부 레이어 훈련
- 작은 데이터셋, pre-trained 모델의 데이터셋과 유사한 경우
: convolutional base를 freeze
📖 07_Autoencoders, Image Augmentation
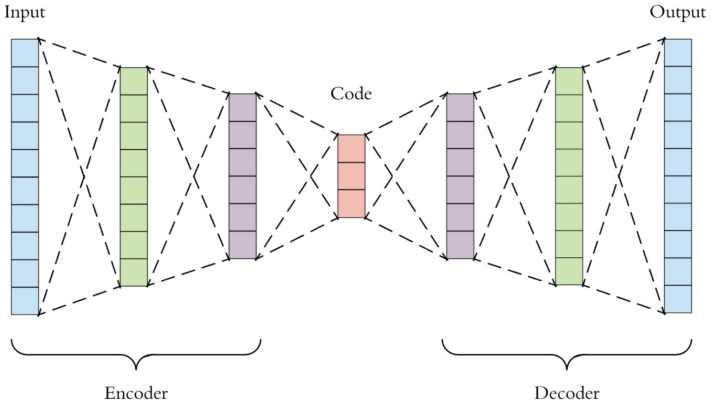
Autoencoders
입력과 출력 동일(자기 자신을 재생성하는 네트워크)
- Latent Vector: 잠재변수
- Encoder: 특징 추출기와 같은 역할
- Decoder: 압축된 데이터 다시 복원
t-SNE(Stochastic Nearest Neighbor)
고차원의 벡터를 저차원으로 옮겨서 시각화에 도움을 주는 방법
각 데이터의 유사도 정의, 원래 공간에서의 유사도와 저차원 공간에서의 유사도가 비슷해지도록 학습(수학적으로 확률로 표현됨)
augmentation
과적합을 방지하기 위해 반전, crop 등을 적용(반전을 시키면 안되는 경우는 제외)
OpenCV를 이용하면 별도의 폴더에 저장해서 한번에 불러와서 학습할 수 있다.
- transforms.RandomHorizontalFlip()
- transforms.RandomVerticalFlip()
- transforms.RandomCrop(52) → 52×52 사이즈로 일부 자르기
📖 08_YOLO
-
classification
데이터를 주어진 라벨(클래스)에 의해 분류하는 법을 학습 -
clustering
데이터의 특징에 의해 스스로 클래스로 분류 -
regression
데이터의 경향성을 파악하고 함수 예측 -
class vs feature
분류하고자 하는 클래스에 따라서 다른 접근법 사용
데이터의 분포 특성에 따라 더 적합한 classifier를 사용하는 것이 바람직
deep learning classification
- classification
- classification + localization
- object detection
여러가지 물체 classification + 물체 위치정보 파악 localization - instance segmentation
영역 표시
CNN
- feature extraction
특징 추출(receptive field, convolution filter) - shift and distortion invariance
변화에 영향을 받지 않기 위한 단계: subsampling(max pooling) - classification
분류기: fully connected output
Detector
- 1-stage detector → YOLO
regional proposal과 classification 동시에(YOLO, SSD 계열) - 2-stage detector(딥러닝이 두번)
regional proposal과 classification 순차적(R-CNN 계열)
YOLO
input image → extract features → FC layer → classification
- MultiClass Classification, Bounding Box Regression
- 초기에 anchor box 생성하여 bounding box 예측
- 초기 anchor box의 신뢰도(confidence)
- 해당 그리드에 물체가 있을 확률 × 예측한 박스와 groung truth 박스가 겹치는 영역을 비율로 나타내는 IoU(Intersection of Union)
- 각각의 그리드마다 C개의 클래스에 대해 해당 클래스일 확률 계산
- darknet이라는 framework에서 YOLO가 학습이 된다.
📖 09_RNN
순환신경망
- 활성화 신호가 입력에서 출력으로 한 방향으로
- 순환 신경망은 뒤쪽으로 연결하는 순환 연결이 있다.
- 순서가 있는 데이터를 입력으로 받고 변화하는 입력에 대한 출력을 얻는다.
- 단점: 입력 데이터가 길어지면 학습 능력이 떨어진다.
- sequence-to-sequence 형태
시계열 데이터 예측에 사용(주식 가격)- sequence-to-vector 형태
벡터로 출력(영화 리뷰의 연속된 단어의 문장 → 평점)- encoder-decoder 형태
번역기와 같은 형태
메모리셀
순환 뉴런의 출력은 메모리 형태라고 말할 수 있다.
메모리셀: 타임스텝에 걸쳐서 어떤 상태를 보존하는 신경망의 구성 요소
LSTM
simple RNN의 장기 의존성 문제를 해결하기 위한 알고리즘
모델을 명시적으로 나열한 개념, time step을 가로지르며 셀 상태가 보존된다.
- cell state
- forget gate
- input gate
- update cell state
- output gate
감성 분석
- 입력된 자연어 안의 주관적 의견, 감정 등을 찾아내는 문제
- 이중 문장의 긍정/부정 등을 구분하는 경우가 많다.
Embedding Lyaer
- 자연어를 수치화된 정보로 바꾸기 위한 레이어
- 자연어는 시간의 흐름에 따라 정보가 연속적으로 이어지는 시퀀스 데이터
- 여러 단위로 묶어서 사용하는 n-gram 방식도 있다.
- 원핫인코딩까지 포함
▷ 내일 학습 계획: 텐서플로 강의
[이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.]
