▷ 오늘 학습 계획: 머신러닝 강의(8~9)
📖 Chapter 04_Model Evaluation
1) 모델 평가의 개념
모델을 좋다, 나쁘다 등으로 평가할 방법은 없다.
다양한 모델, 다양한 파라미터를 두고, 상대적으로 비교한다.
- 회귀모델: 실제 값과의 에러치를 가지고 계산
- 분류 모델의 평가 항목
정확도(Accuacy), 오차행렬(Confusion Matrix), 정밀도(Precision), 재현율(Recall), F1 score, ROC AUC이진 분류 모델의 평가
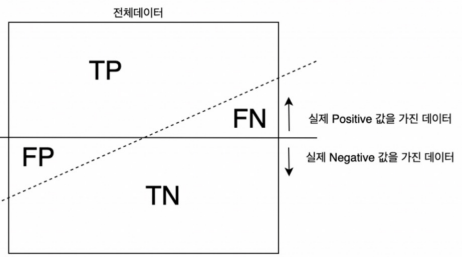
TP: 실제 Positive를 Positive라고 맞춘 경우
FN: 실제 Positive를 Negative라고 틀리게 예측한 경우
TN: 실제 Negative를 Negative라고 맞춘 경우
FP: 실제 Negative를 Positive라고 틀리게 예측한 경우(1종 오류)Accuracy
전체 데이터 중 맞게 예측한 것의 비율: TP+TN / TP+TN+FP+FN
Precision
양성이라고 예측한 것 중에서 실제 양성의 비율: TP / TP+FP
→ 스팸메일RECALL(TPR: True positive ratio, sensitivity)
참인 데이터들 중에서 참이라고 예측한 것: TP / TP+FN
→ 암환자 진단FALL-OUT(FPR: False positive ratio)
실제 양성이 아닌데 양성이라고 잘못 예측한 경우: FP/FP+TN
분류모델은 그 결과가 속할 비율(확률)을 반환한다(predict_proba)
- threshold를 0.5라고 하고 0, 1로 결과를 반영(predict)
- threshold를 변경할 경우 recall과 precision은 서로 영향을 주기 때문에 한 쪽을 극단적으로 높게 설정하면 안된다.
F1-Score: Recall과 Precision을 결합한 지표
Recall, Precision이 어느 한쪽으로 치우치지 않고 둘다 높은 값을 가질수록 F1-Score가 커진다.
2) ROC와 AUC
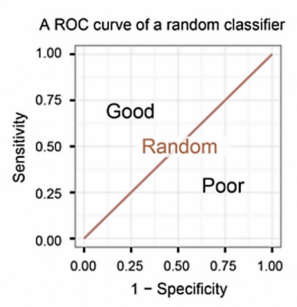
ROC 곡선
Receiver Operating Characteristic Curve
FPR이 변할 때 TPR의 변화를 그린 그림으로, 직선에 가까울 수록 머신러닝 모델의 성능이 떨어지는 것으로 판단한다.
AUC
Area under the curve
ROC 곡선 아래의 면적으로, 0.5보다 큰 값을 가진다.
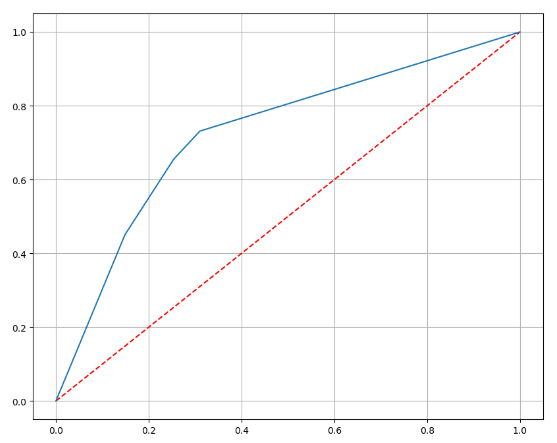
1에 가까울 수록 좋은 수치이다.ROC 커브 그리기(와인 데이터)
import matplotlib.pyplot as plt %matplotlib inline pred_proba = wine_tree.predict_proba(X_test)[:, 1] # 1일 확률만 넣기 fpr, tpr, thresholds = roc_curve(y_test, pred_proba) plt.figure(figsize=(10,8)) plt.plot([0,1], [0,1], 'r', ls='dashed') # 대각선 넣기 plt.plot(fpr, tpr) plt.grid() plt.show()
3) 수학의 기초_함수
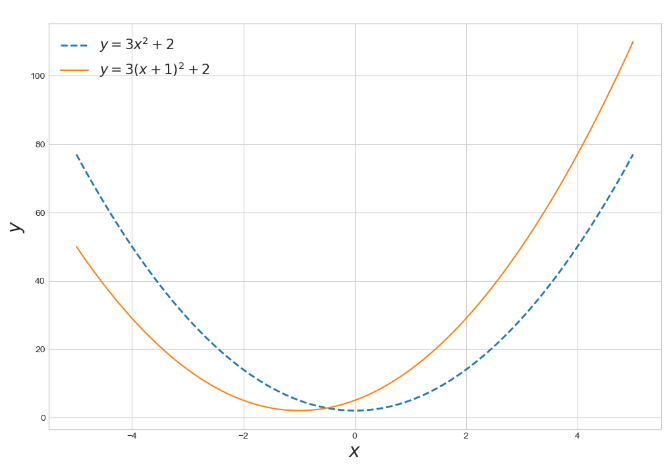
다항함수
다항함수의 x축 방향 이동
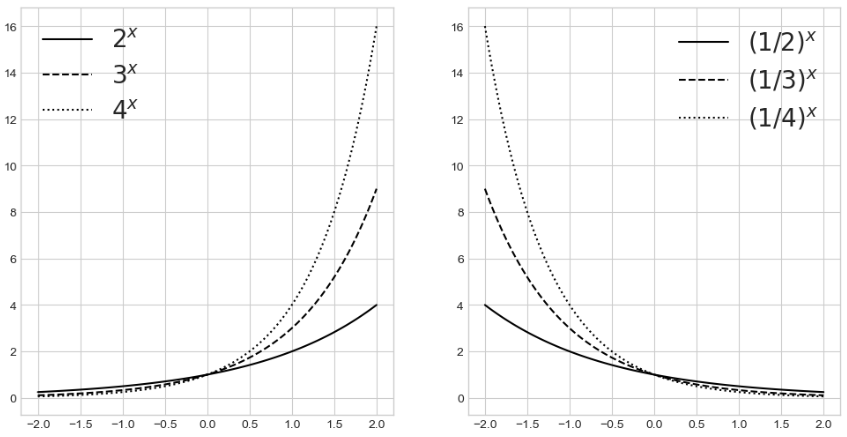
지수함수
- (1 + 1/x)^x = 2.71828(e)에 수렴
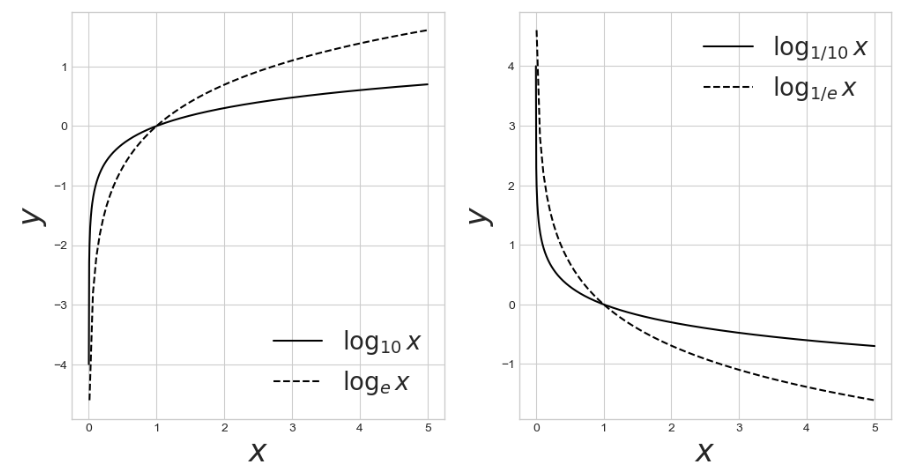
로그함수
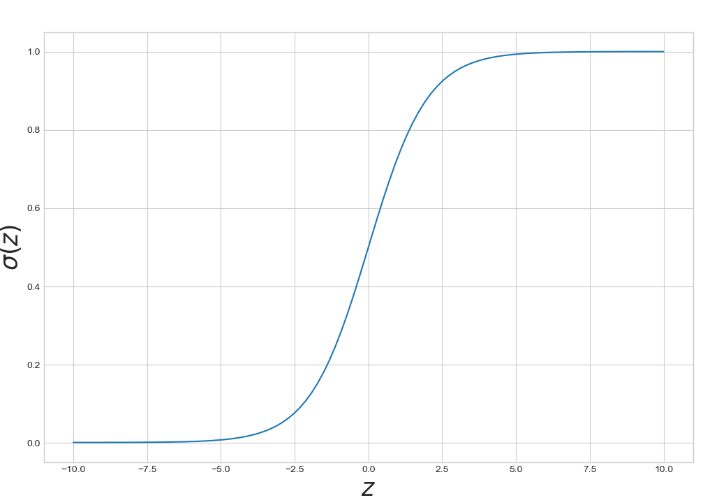
Sigmoid
0과 1 사이의 값을 가진다.
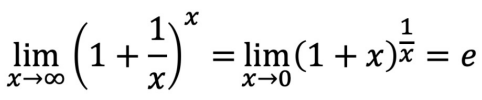
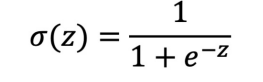
함수의 표현
벡터의 표현
스칼라 함수(단일 변수, 다중 변수)
다변수 벡터함수
함수의 합성
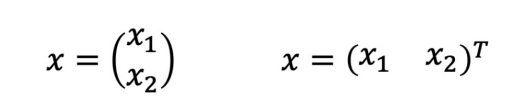
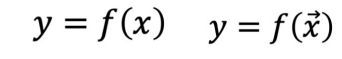
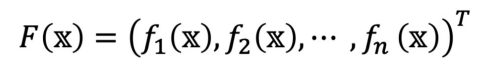
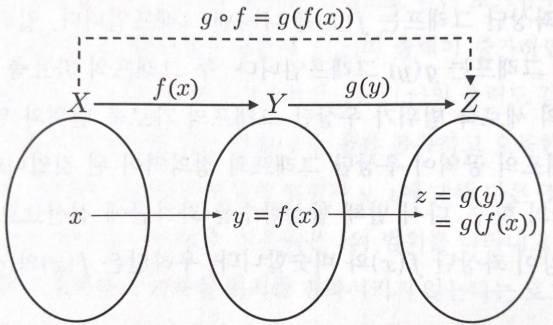
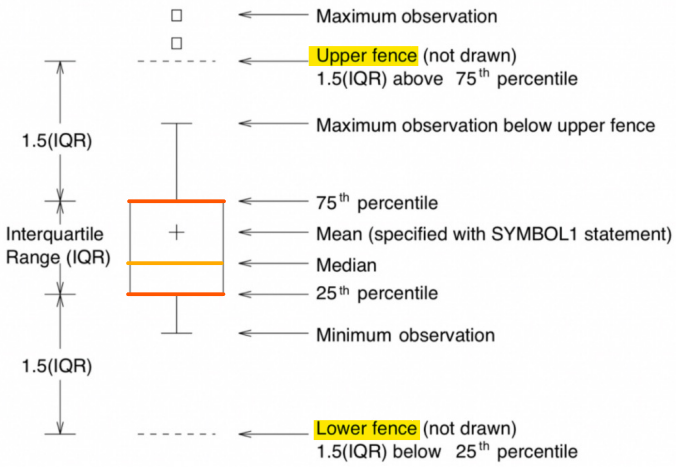
4) box plot
▷ 내일 학습 계획: 머신러닝 강의(10~11)
