▷ 오늘 학습 계획: 머신러닝 강의(5~7)
📖 Chapter 03_Preprocessing
1) encoder and scaler
label_encoder
문자를 숫자로 바꾼다.
df=pd.DataFrame({ 'A' : ['a', 'b', 'c', 'a', 'b'], 'B' : [1, 2, 3, 1, 0] })from sklearn.preprocessing import LabelEncoder le=LabelEncoder() le.fit(df['A']) le.classes_ #array(['a', 'b', 'c'], dtype=object)le.transform(df['A']) #array([0, 1, 2, 0, 1]) le.transform(['a','b']) #array([0, 1]) le.fit_transform(df['A']) #array([0, 1, 2, 0, 1]) le.inverse_transform([1,2,2,2]) #array(['b', 'c', 'c', 'c'], dtype=object)min-max scaler
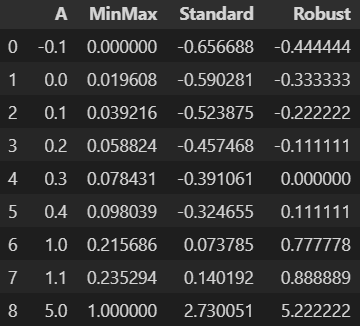
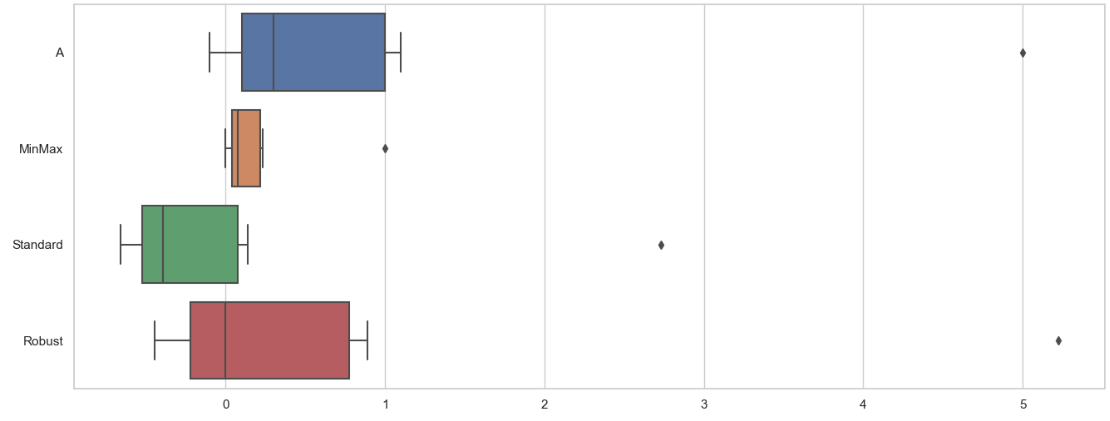
최솟값을 0, 최댓값을 1로 바꾼다. outlier의 영향을 크게 받는다.
df = pd.DataFrame({ 'A' : [10, 20, -10, 0, 25], 'B' : [1, 2, 3, 1, 0] })from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler() mms.fit(df)mms.data_max_, mms.data_min_, mms.data_range_ # (array([25., 3.]), array([-10., 0.]), array([35., 3.]))df_mms = mms.transform(df) mms.inverse_transform(df_mms) mms.fit_transform(df)array([[0.57142857, 0.33333333], [0.85714286, 0.66666667], [0. , 1. ], [0.28571429, 0.33333333], [1. , 0. ]])standard scaler
표준정규분포 → 평균을 0으로, 표준편차를 1로 바꾼다. outlier가 있으면 평균값에 영향을 주게 된다.
from sklearn.preprocessing import StandardScaler ss = StandardScaler() ss.fit(df)ss.mean_, ss.scale_ # (array([9. , 1.4]), array([12.80624847, 1.0198039 ]))df_ss = ss.transform(df) ss.fit_transform(df) ss.inverse_transform(df_ss)array([[ 0.07808688, -0.39223227], [ 0.85895569, 0.58834841], [-1.48365074, 1.56892908], [-0.70278193, -0.39223227], [ 1.2493901 , -1.37281295]])robust scaler
→ median을 0으로, Q3-Q1 = 1 로 만든다. outlier의 영향을 크게 받지 않는다.
df = pd.DataFrame({ 'A':[-0.1, 0., 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5] })from sklearn.preprocessing import RobustScaler rs = RobustScaler() rs.fit(df)df_rs = rs.transform(df) rs.fit_transform(df) rs.inverse_transform(df_rs)
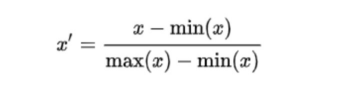

2) 와인 데이터 분석
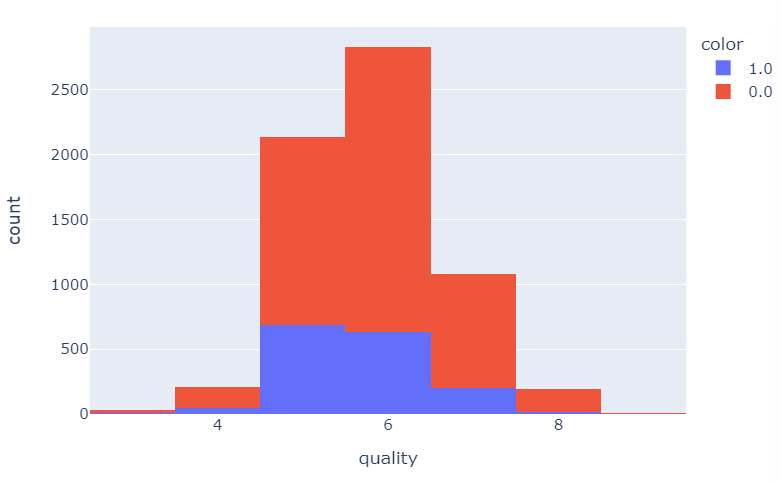
등급별 와인 종류(레드/화이트)에 따른 개수
fig = px.histogram(wine, x='quality', color='color') fig.show()
레드 와인 / 화이트 와인 분류기
# 라벨 분리 X = wine.drop(['color'], axis=1) y = wine['color']데이터 나누기: 훈련용/테스트용
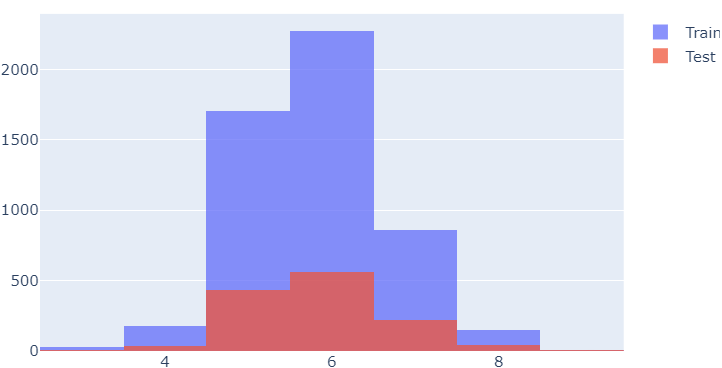
from sklearn.model_selection import train_test_split import numpy as np X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=13) np.unique(y_train, return_counts=True) # (array([0., 1.]), array([3913, 1284], dtype=int64))데이터가 어느정도 구분되었는지 확인
import plotly.graph_objects as go fig = go.Figure() fig.add_trace(go.Histogram(x=X_train['quality'], name='Train')) fig.add_trace(go.Histogram(x=X_test['quality'], name='Test')) fig.update_layout(barmode='overlay') fig.update_traces(opacity=0.75) fig.show()
결정나무 훈련
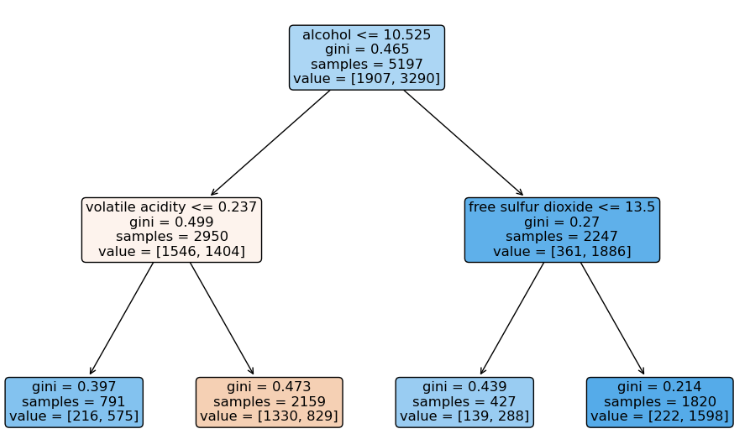
from sklearn.tree import DecisionTreeClassifier wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree.fit(X_train, y_train)학습 결과(accuracy)
from sklearn.metrics import accuracy_score y_pred_tr = wine_tree.predict(X_train) y_pred_test = wine_tree.predict(X_test) print('Train Acc : ', accuracy_score(y_train, y_pred_tr)) print('Test Acc : ', accuracy_score(y_test, y_pred_test)) # Train Acc : 0.9553588608812776 # Test Acc : 0.9569230769230769
데이터 전처리
컬럼들의 최대/최소 범위가 각각 다르고, 평균과 분산이 각각 다를 때 특성(feature)의 편향 문제는 최적의 모델을 찾는데 방해가 될 수도 있다.
→ MinMaxScaler, StandardScaler(어떤 것이 좋을지는 해봐야 안다.)
결정나무에서는 이런 전처리는 의미를 가지지 않고 주로 Cost Function을 최적화할 때 유효할 때가 있다.# 레드와인과 화이트와인을 구분하는 특성(maxdepth=2일 때) dict(zip(X_train.columns, wine_tree.feature_importances_))

와인 맛에 대한 분류(이진 분류)
# quality 컬럼 이진화 wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]# quality 컬럼, quality 컬럼으로 만든 taste 컬럼 제거 X = wine.drop(['taste', 'quality'], axis=1) y = wine['taste']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13) wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13) wine_tree.fit(X_train, y_train)y_pred_tr = wine_tree.predict(X_train) y_pred_test = wine_tree.predict(X_test) print('Train Acc : ', accuracy_score(y_train, y_pred_tr)) print('Test Acc : ', accuracy_score(y_test, y_pred_test)) # Train Acc : 0.7294593034442948 # Test Acc : 0.7161538461538461plt.figure(figsize=(12,8)) tree.plot_tree(wine_tree, feature_names=X.columns, rounded=True, filled=True);
3) Pipeline
from sklearn.pipeline import Pipeline from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScalerestimators = [('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())] pipe = Pipeline(estimators)# pipeline.steps pipe.steps pipe.steps[0] pipe.steps[1] # 스텝별로 객체 호출 pipe[0] pipe['scaler'] # set_params pipe.set_params(clf__max_depth=2) pipe.set_params(clf__random_state=13)Pipeline을 이용한 분류기 구성
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y) pipe.fit(X_train, y_train)from sklearn.metrics import accuracy_score y_pred_tr = pipe.predict(X_train) y_pred_test = pipe.predict(X_test) print('Train acc : ', accuracy_score(y_train, y_pred_tr)) print('Test acc :', accuracy_score(y_test, y_pred_test)) # Train acc : 0.9657494708485664 # Test acc : 0.9576923076923077
4) 교차검증
- 과적합: 모델이 학습 데이터에만 과도하게 최적화되어 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상
- train data와 test data로 나누는 것 → holdout
- k-fold cross validation
train data를 5등분(train data의 평균 → train data의 accuracy)
각각 나눈 데이터 중에 4개를 train, 1개를 validation으로 정해서
validation을 따로 시행(총 5번)하여 평균을 구함 → validation accuracy- stratified k-fold cross validation: class의 분포 상태를 유지
- 검증이 끝나면 test 데이터로 최종 평가
KFold
from sklearn.model_selection import KFold kfold = KFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)cv_accuracy = [] for train_idx, test_idx in kfold.split(X): X_train, X_test = X.iloc[train_idx], X.iloc[test_idx] y_train, y_test = y.iloc[train_idx], y.iloc[test_idx] wine_tree_cv.fit(X_train, y_train) pred = wine_tree_cv.predict(X_test) cv_accuracy.append(accuracy_score(y_test, pred)) # cv_accuracy: [0.6007692307692307, 0.6884615384615385, 0.7090069284064665, 0.7628945342571208, 0.7867590454195535]np.mean(cv_accuracy) # 0.709578255462782
StratifiedKFold
from sklearn.model_selection import StratifiedKFold skfold = StratifiedKFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)cv_accuracy = [] for train_idx, test_idx in skfold.split(X, y): X_train, X_test = X.iloc[train_idx], X.iloc[test_idx] y_train, y_test = y.iloc[train_idx], y.iloc[test_idx] wine_tree_cv.fit(X_train, y_train) pred = wine_tree_cv.predict(X_test) cv_accuracy.append(accuracy_score(y_test, pred)) # cv_accuracy: [0.5523076923076923, 0.6884615384615385, 0.7143956889915319, 0.7321016166281755, 0.7567359507313318]np.mean(cv_accuracy) # 0.6888004974240539
교차검증 간단한 방법
from sklearn.model_selection import cross_val_score skfold=StratifiedKFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13) cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)# train score 함께 조회하기 from sklearn.model_selection import cross_validate cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)
5) 하이퍼파라미터 튜닝
모델의 성능을 확보하기 위해 조절하는 설정 값
GridSearchCV
from sklearn.model_selection import GridSearchCV from sklearn.tree import DecisionTreeClassifierparams = {'max_depth' : [2,4,7,10]} wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13) gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5) gridsearch.fit(X, y)GridSearchCV 결과 확인하기
import pprint pp = pprint.PrettyPrinter(indent=4) pp.pprint(gridsearch.cv_results_)최적의 성능을 가진 모델
gridsearch.best_estimator_ gridsearch.best_score_ gridsearch.best_params_pipeline을 적용한 모델에 GridSearch 적용하기
from sklearn.pipeline import Pipeline from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScalerestimators=[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier(random_state=13))] pipe=Pipeline(estimators)param_grid=[{'clf__max_depth':[2,4,7,10]}] GridSearch=GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5) GridSearch.fit(X, y)# 성능 결과 정리하기(accuracy의 평균과 표준편차) score_df=pd.DataFrame(GridSearch.cv_results_) score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]
▷ 내일 학습 계획: 머신러닝 강의(8~9)
