▷ 오늘 학습 계획: 통계 강의(심화 5~6)
📖 10_분산분석
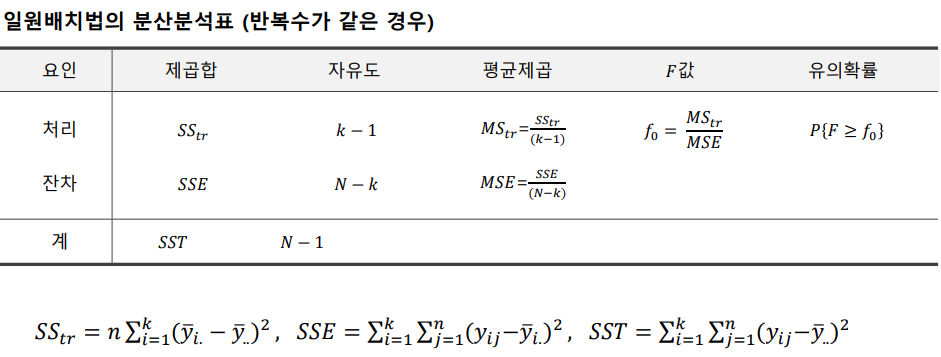
1) 분산분석((analysis of variance)
셋 이상의 모집단의 평균 차이를 검정
cf) t-test: 두개의 모집단의 평균 차이를 검정실험계획법(experimental design)
모집단의 특성에 대하여 추론하기 위해 특별한 목적성을 가지고 데이터를 수집하기 위한 실험 설계
반응변수: 관심의 대상이 되는 변수
요인/인자(Factor): 실험 환경 또는 조건을 구분하는 변수, 실험에 영향을 주는 변수
인자수준(처리, treatment): 인자가 취하는 개별 값분산분석의 기본 가정
각 모집단은 정규 분포를 따른다
각 모집단은 동일한 분산을 갖는다
각 표본은 독립적으로 추출되었다분산분석의 가설
각 집단의 평균은 동일하다 vs 각 집단의 평균에 차이가 있다
실험의 가정
반복의 원리: 실험을 반복해서 실행해야 함
랜덤화의 원리: 각 실험의 순서를 무작위로 해야함
블록화의 원리: 제어해야 할 변수가 있다면 인자에 영향을 받지 않도록 조건을 묶어서 실험해야 함일원 분산분석: 한가지 요인을 기준으로 집단간의 차이를 조사
이원 분산분석: 두 가지 요인을 기준으로 집단 간의 차이를 조사
다원 분산분석: 세 가지 이상의 요인을 기준으로 집단 간의 차이를 조사
2) One-way ANOVA
한 개의 반응 변수와 한 개의 독립 인자
반응 변수: 연속형 변수만 가능
독립 인자(변수): 이산형 또는 범주형 변수만 가능
사후 검정
평균이 다른건 알지만 어떤 처리 조건으로 평균 차이가 있는지 확인
(Bonferroni., scheffe, Duncan, Dunnett 등의 방법)
3) Two-way ANOVA
한 개의 반응 변수와 두 개의 독립 인자로 분석하는 방법
상호작용(Interaction effect): 한 독립변수의 main effect가 다른 독립변수의 level에 따라서 원래의 선형관계를 비선형관계로 변하는 경우가설 설정

📖 11_시계열분석
time series analysis: 시간의 흐름에 따라 기록된 자료를 분석하고 여러 변수들간의 인과관계를 분석
시계열 데이터는 연속 시계열과 이산 시계열 데이터로 구분시계열 분석의 목적
미래의 특정 시점에 대한 관심의 대상(반응변수)을 예측
경향(Trend), 주기, 계절성, 변동성(패턴) 등 관측치의 시계열 특성 파악전통 적인 시계열 분석 방법
- 이동 평균 모형(MA_moving average): 최근 데이터의 평균을 예측치로 사용하는 방법
- 자기 상관 모형(AR_Autocorrelation): 변수의 과거 값의 선형 조합을 이용하여 예측하는 방법
- ARIMA(Autoregressive Integrated Moving Average): 관측값과 오차를 사용해서 모형을 만들어서 미래를 예측하는 방법
- 지수평활법: 현재에 가까운 시점에 가장 많은 가중치 주고 멀어질수록 낮은 가중치를 주어서 미래를 예측하는 방법
시계열 요소
- 경향/추세(trend): 시계열 데이터가 장기적으로 증가(감소)할 때, 추세가 존재함
- 계절성(seasonality): 특정기간(1년 마다) 어떤 특정한 때나 1주일마다 특정 요일에 나타나는 것 같은 계절성 요인이 시계열에 영향을 줄 때
ex) 패션업종 매출, 요일 별 온라인 쇼핑몰 매출 등이 계절성의 대표적- 주기성(cycle): 일정한 주기(진폭)마다 유사한 변동이 반복되는 현상
보통 경기 순환(business cycle)과 관련이 있으며 지속기간은 2년
ex) 주가 업좀별 개별(업종) 주가- 불규칙요인(Irregular movements): 예측하거나 제어할 수 없는 요소
ex) 회귀분석의 오차와 같은 항목시계열 분석 방법
- 단기예측 → 지수평활법, 시계열 해법, Box-jenkins 방법
수학적 이론에 의존하고 시간에 따른 변동이 많은 시계열 자료에 적용- 장기예측 → 회귀분석 방법론
- 직관적 방법 → 지수평활법, 시계열 분해
시간에 따른 변동이 느린 데이터에 활용- 다중 시계열 → 회귀분석(계량경제)방법, 전이함수모형, 다변량 ARIMA
시계열데이터와 설명변수가 있는 경우참고) 엑셀 함수 'FORECAST'를 이용해서 예측 가능
이동 평균법
지수평활법
모든 관측값을 이용하면서 예측하는 시점에 가까울수록 비중을 둔다.
최근값 예측시 더 많은 기여를 하도록 만드는 방법
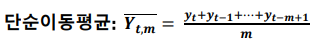
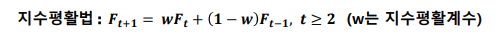
📖 12_Machine Learning
인공지능
사고나 학습 등 인간이 가진 지적 능력을 컴퓨터를 통해 구현하는 기술
머신러닝
인공 지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
컴퓨터가 스스로 학습하여 인공지능의 성능을 향상 시키는 기술 방법딥러닝
인간의 뉴런과 비슷한 인공신경망 방식으로 정보 처리
머신러닝의 세가지 요소: Task, Experience, Performance
Task를 달성하기 위해 Experience를 통해 Performance 개선
- 분석하고자 하는 목표 정의
- experience를 정의하기 위한 데이터 수집
- performance를 향상시키기 위한 measure 정의
Types of Machine Learning
Supervised Learning
Label이 있는 데이터 분석, 과거의 데이터로 미래 예측
Unsupervised Learning
Label이 없는 데이터 분석, 데이터를 나누거나 속성별로 분류할 때 사용
Reinforcement Learning
Machine Learning Model
Decision Tree
설명변수(X) 간의 관계나 척도에 따라 목표변수(Y)를 예측하거나 분류하는 문제에 활용되는 나무 구조의 모델
장점: 결과 해석이 쉽고 빠름, 선형/비선형에 적용 가능
단점: 과도적합의 문제, 분기점에서 오차 발생확률이 올라감앙상블 모형
- Bagging(boostrap aggregating)
데이터를 가방(bag)에 쓸어 담아 복원 추출하여 여러 개의 표본을 만들어 각각의 모델을 개발한 후에 결과를 하나로 합쳐 하나의 모델을 만들어 내는 것
ex) Randomforest- Boosting: 복원 랜덤 샘플링, 가중치를 부여한다는 차이점
Bagging이 병렬로 학습하는 반면, Boosting은 순차적으로 학습
학습이 끝나면 나온 결과에 따라 가중치 재분배
ex) AdaBoost, XGBoost, GradientBoost추천모형
Association, CF(Collaborative Filtering) 모형(사용자 기반/아이템 기반)
Deep Learning
인공신경망의 발전한 형태(Deep Learning 또는 Deep Neural Network)
인간의 뇌처럼 수많은 노드를 연결하여 이들의 노드 값을 훈련 시켜 데이터를 학습 시킴Convolutional Neural Network(CNN)
데이터 -> 특징(feature) -> 지식의 단계로 학습
Recurrent Neural Network
시계열 데이터 분석에 사용
매순간마다 인공신경망 구조를 쌓아 올린 형태
▷ 내일 학습 계획: EDA, SQL 학습과제
