데이터를 불러오고 그 데이터로 학습을 수행하는 것만큼이나 데이터의 시각화도 중요하다. 시각화가 잘 이루어져야 그 데이터에서 insight를 얻기가 쉬워진다.
Data Viz
Data
당연하게도 데이터 시각화는 데이터에서 출발한다. 데이터가 무엇인지, 데이터의 종류에는 무엇이 있는지를 알아야 한다.
데이터 종류에는 다음과 같은 것들이 있다.
- 정형 데이터
- 테이블 형태로 제공(.csv, .tsv)
- 시각화가 가장 쉽다.
- cf) 반정형 데이터 (html, json, etc.)
- 시계열 데이터
- 시간 흐름에 따른 데이터
- trend, seasonality, cycle 등을 살펴봐야 함
- ex) 기온, 주가
- 시간 흐름에 따른 데이터
- 지리 데이터
- 지도 정보와 연관된 데이터
- 관계형 데이터
- 객체와 객체 간의 관계를 시각화(Graph Viz, Network Viz)
- 객체(node), 관계(link), 객체와 관계의 가중치
- 계층적 데이터
- 포함관계가 분명한 데이터
- tree, sunburst, etc.
- 다양한 비정형 데이터
- 수치형(numerical)
- 연속형(continuous) ex) 길이, 무게, 온도
- 이산형(discrete) ex) 주사위 눈금, 사람 수
- 범주형(categorical)
- 명목형(norminal) ex) 혈액형, 종교
- 순서형(ordinal) ex) 학년, 별점, 등급
- 학년, 별점, 등급 등은 수치로 나타낼 수 있는데 왜 순서형일까?
→ 수치형으로 나타내는 데이터는 해당 수치 사이에 비례 관계가 성립할 때. 6학년이 1학년보다 6배 낫거나 하지는 않기 때문.
- 수치형(numerical)
Understanding Viz
- 마크(mark)는 이미지의 기본적 그래픽 요소이다.
- 점, 선, 면
- 채널(channel)은 마크를 나타내는 방식이다.
- 방향, 색, 모양, 기울기, 길이 등
- 전주의적 속성(pre-attentive attribute)이 있다.
- 주의를 기울이지 않아도 인지하게 되는 요소들이 있는데 데이터 시각화는 이러한 요소들을 잘 활용해야 한다.
- 예를 들어 강조하고 싶은 데이터의 색을 달리 하면 데이터를 하나하나 들여다보지 않아도 어떤 데이터에 주목해야 하는지 쉽게 알 수 있다.
- 특정 데이터에 대한 강조가 목적이기 때문에 여러 기법을 동시에 서로 다른 데이터에 사용하면 의도대로 데이터 시각화가 이루어지지 않을 수 있다.
- 적절히 사용해서 시각적 분리(visual popout) 효과를 얻어야 한다.
- 주의를 기울이지 않아도 인지하게 되는 요소들이 있는데 데이터 시각화는 이러한 요소들을 잘 활용해야 한다.
matplotlib, pyplot
파이썬에는 시각화를 위한 라이브러리인 matplotlib가 존재한다.
시각화를 위해 대개 다음 네줄의 코드로 시작하곤 한다.
import numpy as np
import pandas as pd
import matplotlib as mpl
import matploblib.pyplot as pltfigure, subplot
fig = plt.figure()
ax = fig.add_subplot(111)figure()는 큰 틀을 만든다. 시각화의 준비 단계라고 볼 수 있다.
fig.add_subplot(111)로 subplot을 만들 수 있다.
111은 세로 방향으로 1개, 가로 방향으로 1개의 subplot을 만들어 그 중 첫번째 subplot을 ax에 할당하겠다는 의미이다.
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)위와 같은 코드는 2x2 행렬의 각 원소 위치에 subplot을 각각 만들고 axn에 n번째 subplot을 배정하겠다는 말과 같다.
만약 하나의 subplot에 두가지 데이터를 같이 표현하고 싶다면?
fig = plt.figure()
ax = fig.add_subplot(111)
x1 = [1,2,3,4,5]
x2 = [5,4,3,2,1]
plt.plot(x1)
plt.plot(x2)
plt.show()
이런 방식도 가능하다.
fig, ax = plt.subplots(1,1)
ax.plot(x1)
ax.plot(x2)
plt.show()
(subplots에 주의! 뒤에 s가 붙는다. add_subplot과 비교)
만약 여러개의 subplot에 나눠서 시각화하고 싶다면?
fig, axes = plt.subplots(1,2)
axes[0].plot(x1)
axes[1].plot(x2)
plt.show()

(plt.subplots(1,2)의 output값을 찍어보면 위처럼 나온다.)
bar plot
막대 모양의 차트를 본 적이 있을 것이다. .bar()는 데이터를 그러한 방식으로 시각화할 수 있다.
(.bar()는 인덱스가 x축, 해당 인덱스에 대한 값이 y축에 표현된다. 인덱스를 y축에 표현하는 수평적 시각화를 원한다면 .barh()를 사용하면 된다,)
해당 함수는 파라미터로 x축 값들, y축 값들을 기본적으로 받고 color, width, label 등을 받는다.
이 부분에서는 pandas에서의 데이터 전처리 테크닉과 둘 이상의 데이터를 하나의 subplot에 표현하는 기법이 중요했다.
하나의 플롯에 동시에 서로 다른 데이터들을 나타내는 방법에는 다음과 같은 것들이 존재한다.
stacked bar plot
2개 이상의 그룹을 쌓아서 표현. 하나의 데이터를 시각화하는 막대 위에 다른 데이터 막대가 쌓인다.
.bar():bottom파라미터로 아래에 쌓일 데이터를 표시.barh():left파라미터로 왼쪽에 쌓일 데이터를 표시
fig, ax = plt.subplots(1,1)
idx = [i for i in range(5)]
x1 = [1,8,3,2,5]
x2 = [5,7,3,2,2]
ax.bar(idx, x1)
ax.bar(idx, x2, bottom=x1)
ax.set_ylim(0,17) # y축에 표현되는 값 0부터 17
plt.show()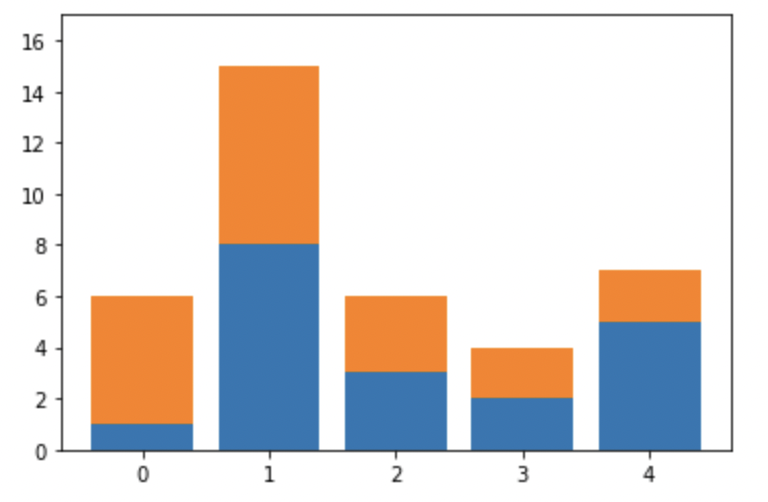
이를 응용하고 .text(), .spine[ ].set_visible() 등의 함수들을 이용하면 다음처럼 percentage stacked bar plot을 구현할 수 있다.
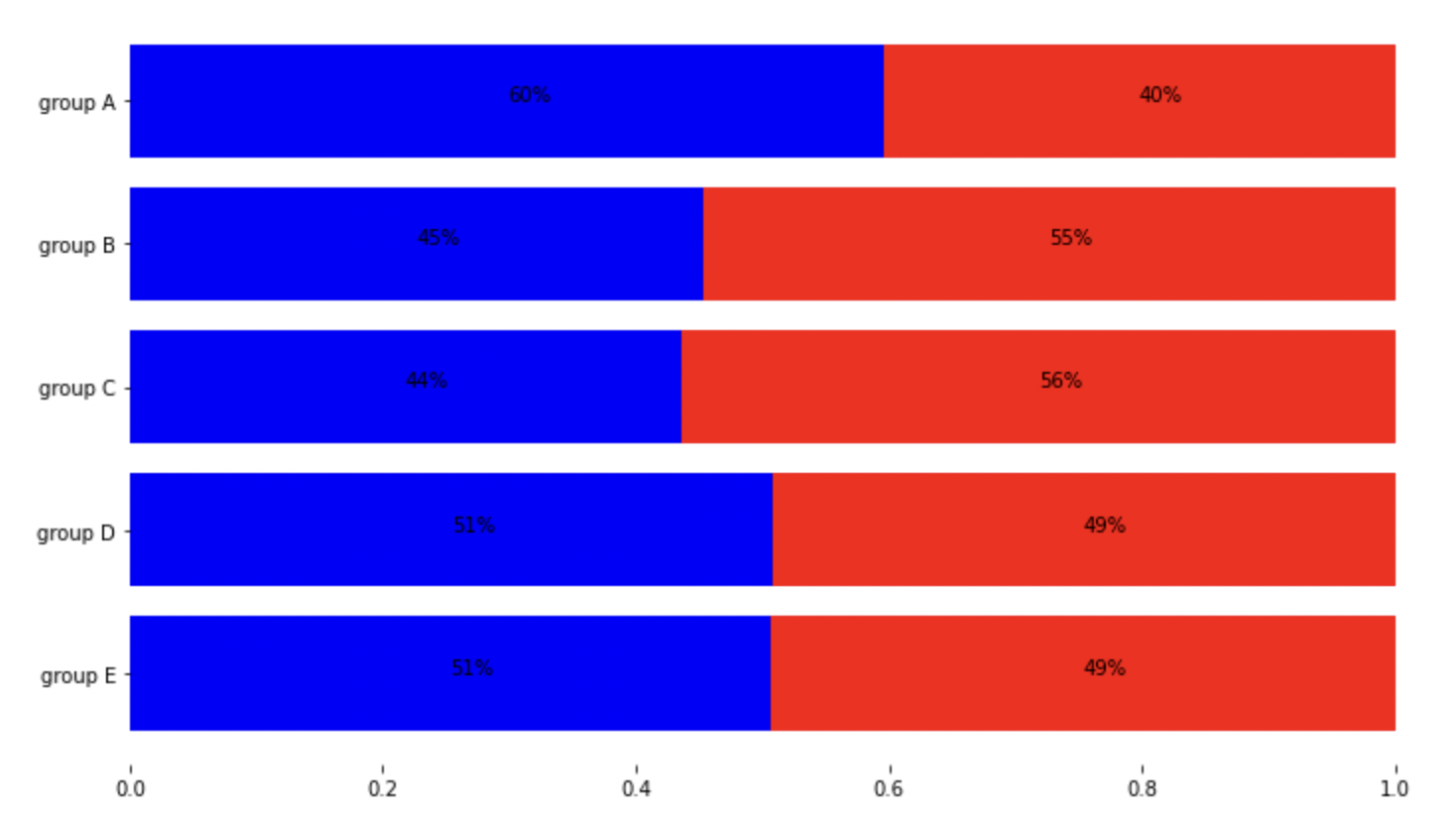
overlapped bar plot
겹쳐서 만들 수도 있다. alpha라는 투명도를 나타내는 파라미터를 이용한다.
fig, axes = plt.subplots(1,2)
idx = [i for i in range(5)]
x1 = [1,8,3,2,5]
x2 = [5,7,3,2,2]
axes[0].bar(idx, x1, alpha=0.5)
axes[0].bar(idx, x2, alpha=0.5)
axes[1].bar(idx, x1, alpha=0.7)
axes[1].bar(idx, x2, alpha=0.7)
plt.show()
보통 0.5나 0.7을 사용한다고 한다. 물론 원하는대로 바꿀 수 있다.
grouped bar plot
막대를 이웃되게 배치할 수 있다. 개인적으로 가장 보기에 좋아보이는데 위의 두 방법보다는 구현이 살짝 더 까다롭다.
x축이 index, y축이 해당 index에 따른 값이라고 해보자. indices가 [0,1,2,3,4]라고 한다면 지금까지는 막대의 중심이 정확히 0,1,2,3,4에 있었다. 하지만 두개 이상의 데이터에 대해 해당 데이터를 표현하는 막대들이 이웃하게 시각화하려면 막대의 중심을 이동시키고, 막대가 겹치지 않게 width를 조정하는 작업이 필요하다. 이와 관련해서는 다음과 같은 규칙을 생각해볼 수 있다.
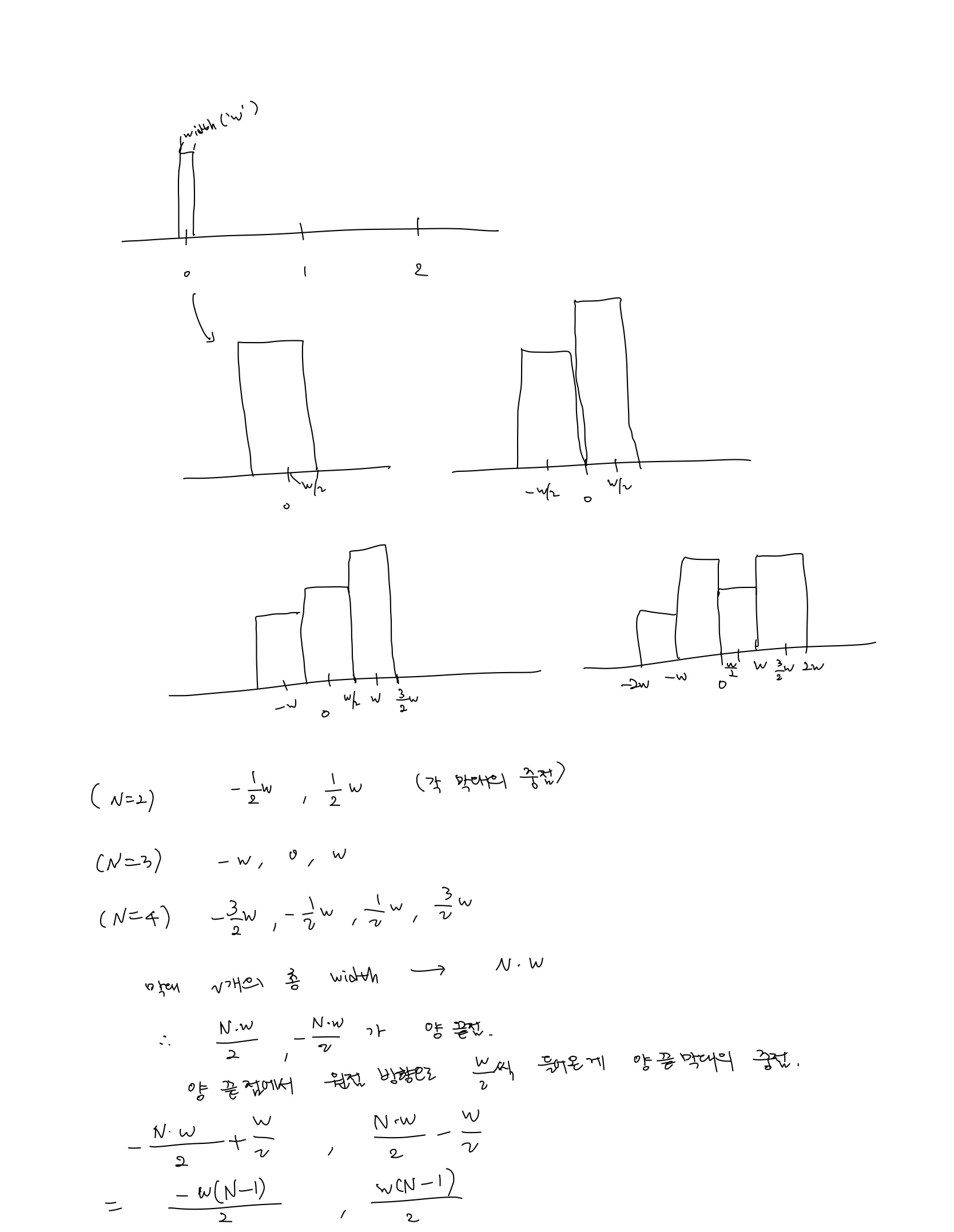

이를 이용하여 코드를 짜면 다음과 같다.
width를 적당한 값으로 설정해야 한다. (강의 자료를 보다보니)N개의 데이터를 이웃한 막대로 동시에 표현하고자 한다면 N\*width가 대략 0.7 정도 되게 값을 설정하는 것 같다.
fig, ax = plt.subplots(1,1)
x1 = np.random.rand(8)
x2 = np.random.rand(8)
x3 = np.random.rand(8)
x4 = np.random.rand(8)
x_idx=np.arange(8)
width = 0.15
x_values = [x1, x2, x3, x4]
for i in range(4):
ax.bar(x_idx+(-4+1+2*i)*width/2, x_values[i],
width=width,
label=f'x{i+1}')
ax.legend() # 정해놓은 label들을 범례로 보여줌.
plt.show()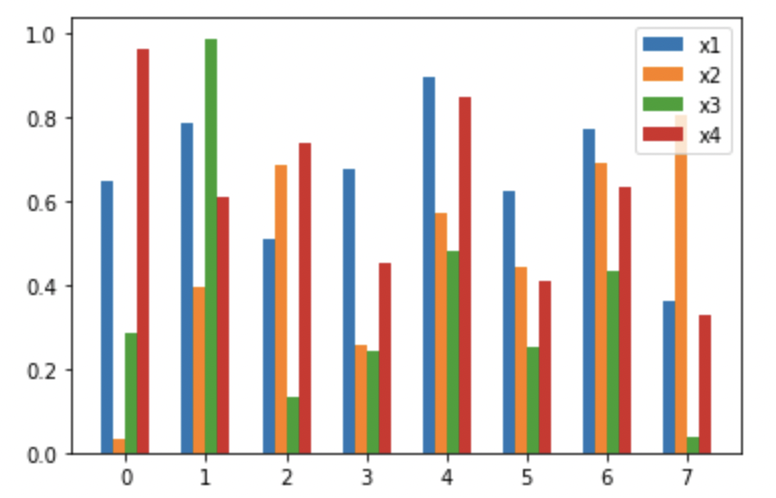
line plot
line plot은 대개 데이터를 점으로 찍은 후 순서대로 선으로 연결한 그래프 형태의 시각화 방법이다.
시간/순서에 대한 변화에 적합하여 trend를 살피기 좋다. 때문에 시계열 분석에 특화되어 있다.
.plot()으로 구현한다.
순서대로 데이터를 연결하기 때문에 데이터 순서에 따라 아래와 같은 형태를 보이기도 한다.
fig, axes = plt.subplots(1,2, figsize=(12,7))
x1 = [1,2,3,4,5]
x2 = [1,3,2,4,5]
y = [1,3,2,1,5]
axes[0].plot(x1, y)
axes[1].plot(x2,y)
plt.show()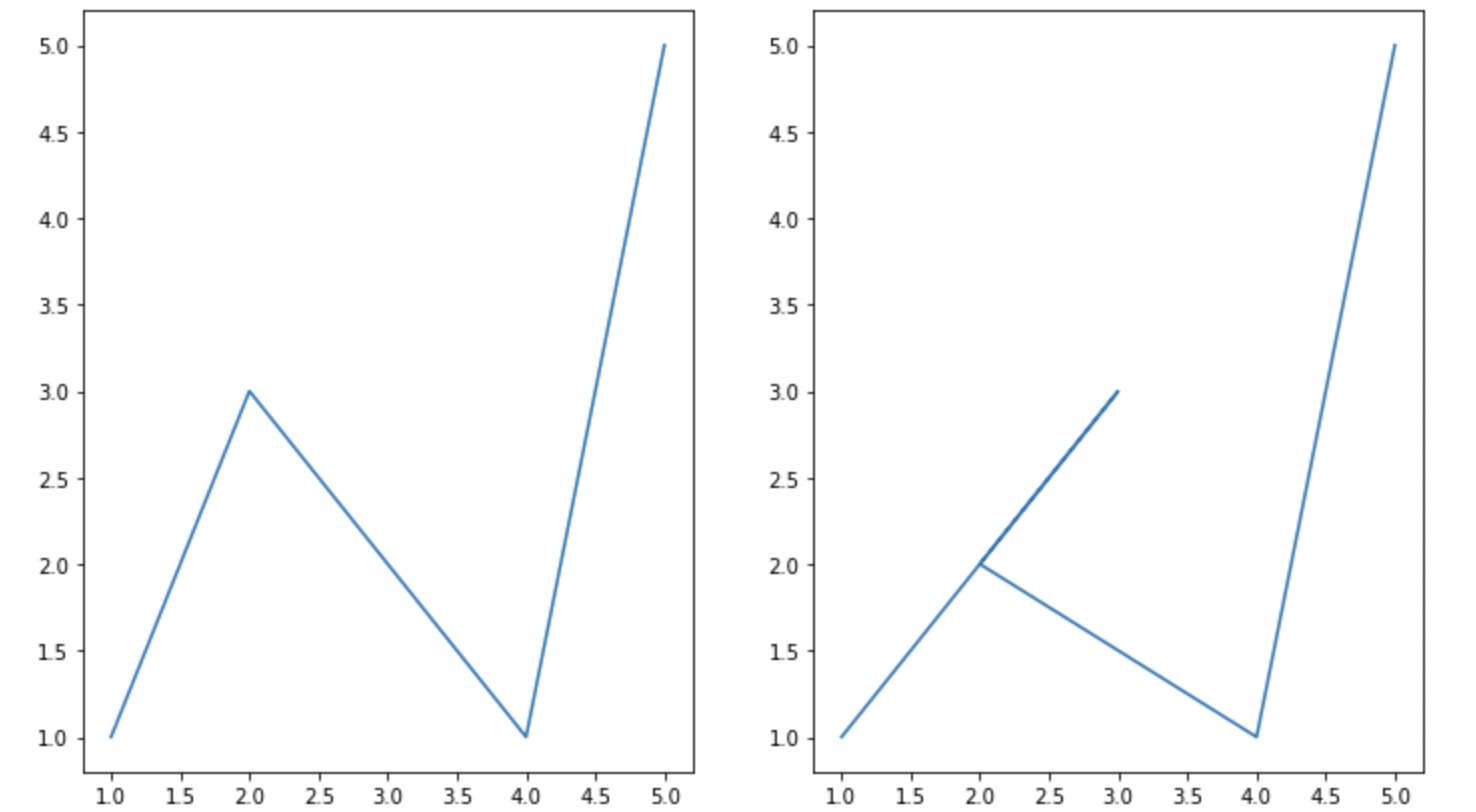
이동 평균(?)
A_rolling = A.rolling(window=~).mean()와 같은 방식으로 n-(*window*-1)번째 데이터부터 n번째 데이터까지 window 개수만큼의 데이터들의 평균값으로 그래프를 그린다. 그래프는 noise가 좀더 감소한 형태를 띄게 된다. trend 등에 집중하기 좋다.
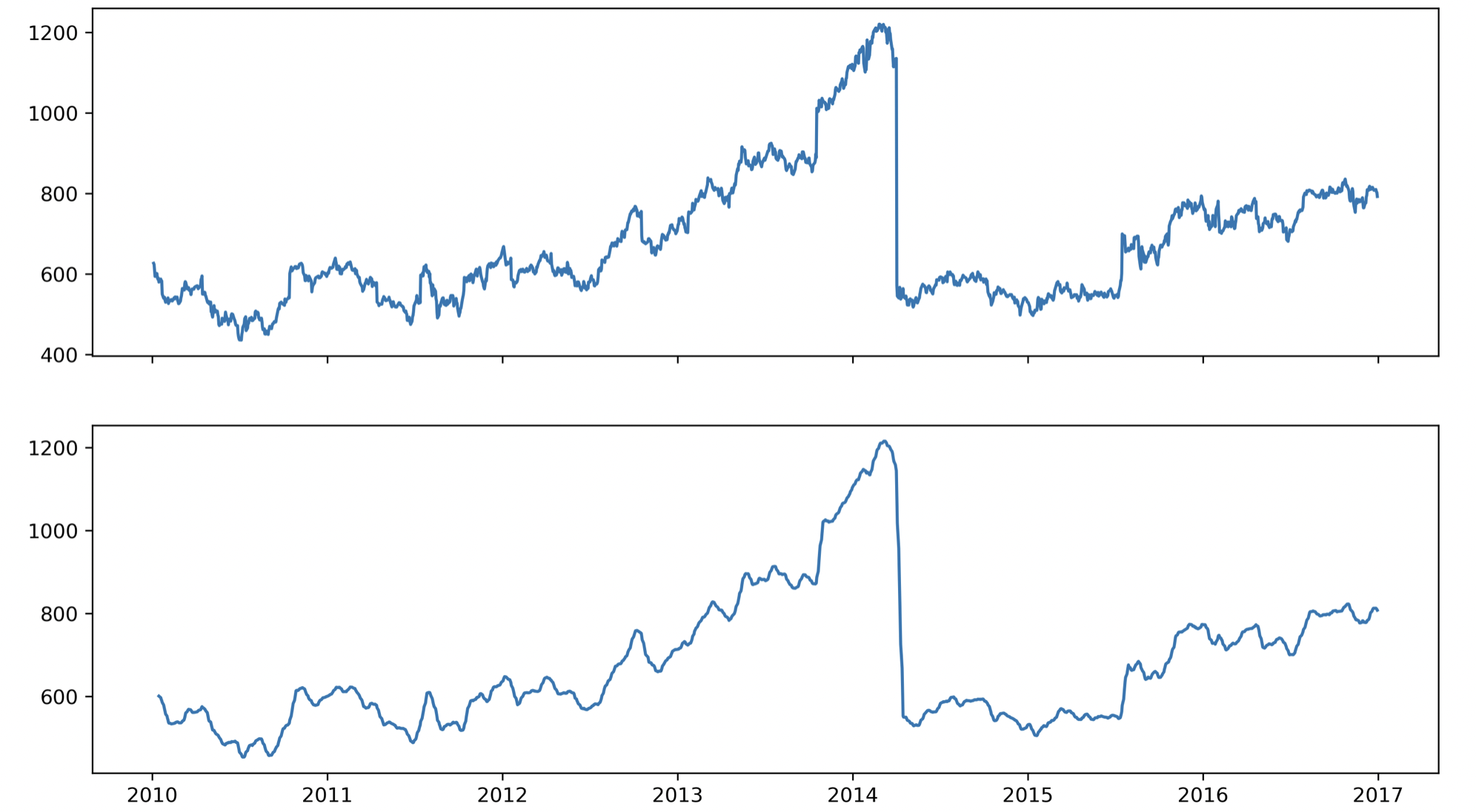
이중 축 사용(dual axis)
.twinx().secondary_xaxis(),.secondary_yaxis()
scatter plot
점으로 데이터를 표현한다. 관계를 파악하기에 좋다.
fig = plt.figure(figsize=(7,7))
ax = fig.add_subplot(111, aspect=1) # aspect는 각 축의 scale을 맞춤. 1이면 1:1을 의미.
x = np.random.rand(20)
y = np.random.rand(20)
ax.scatter(x,y)
plt.show()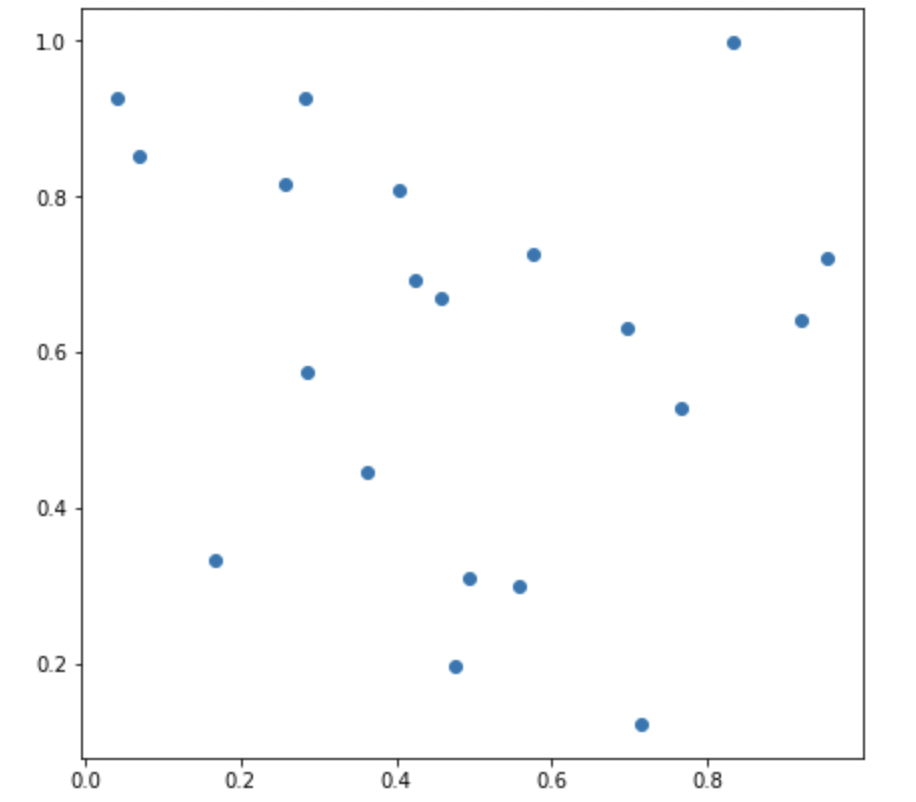
scatter의 파라미터로는 다음과 같은 것들이 존재한다.
ax1.scatter(x,y,
s=s, # s = np.arange(~)
c='white',
marker='^',
linewidth=1,
edgecolor='black') # s: size, c:colors는 각 점의 size인데 위처럼 순차적으로 사이즈를 적용할 수도 있다.
.bar(), .plot() 등에서 파라미터로 c는 안되고 color만 됐던걸로 기억하는데 scatter는 c도 사용할 수 있다.
ax.scatter(x=iris['SepalLengthCm'],
y = iris['SepalWidthCm'],
c = ['blue' if yy <= swc_mean else 'gray' for yy in iris['SepalWidthCm']])이런 식으로 color parameter에 조건을 달 수도 있다. 그러면 다음과 같은 이미지를 얻을 수 있다.
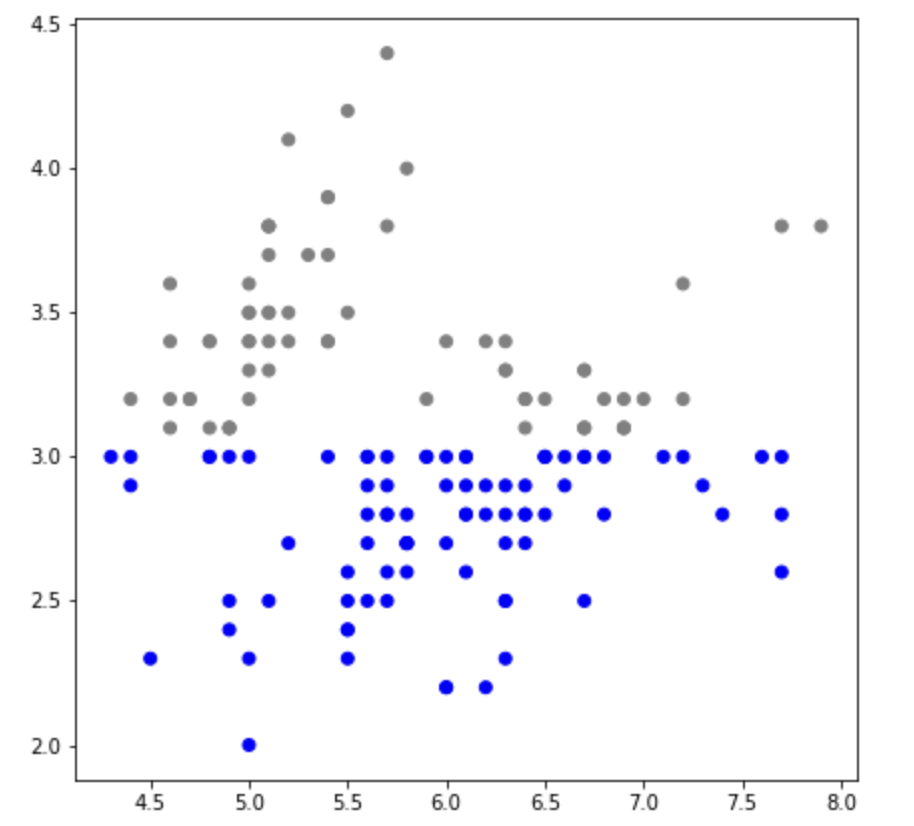
앞서 배운 방식들을 응용하면 여러 데이터를 동시에 표현하는 것도 가능하다.
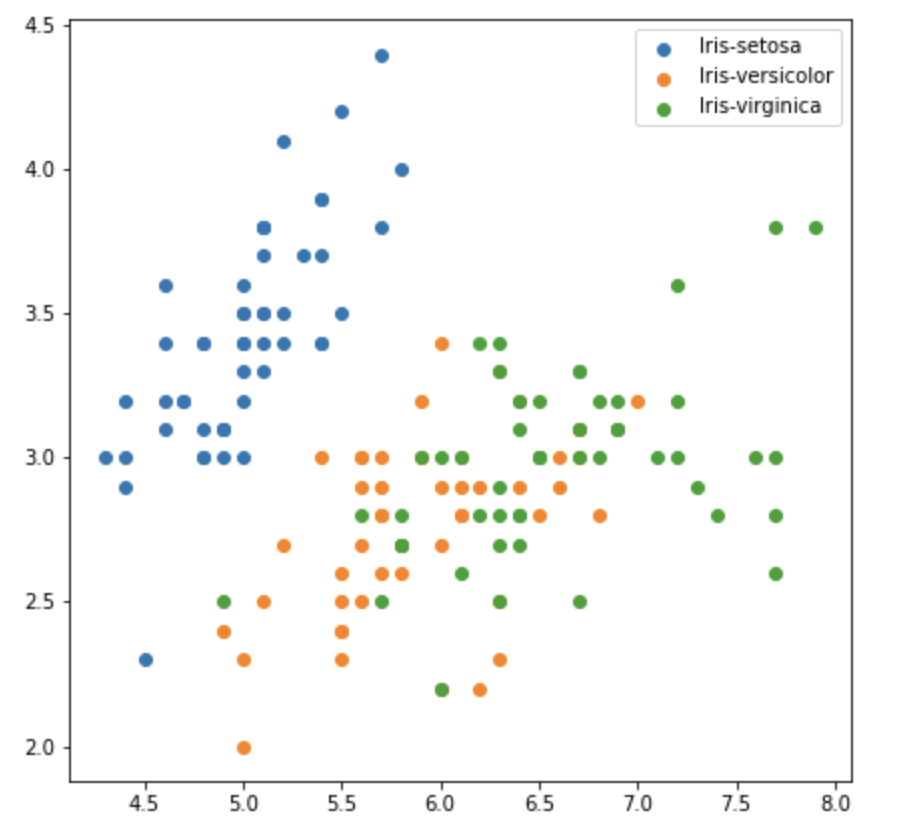
Questions
- 강의 자료 중에 주가 정보를 csv로 받아와서 전처리한 후 시각화하는 부분이 있었다. 전처리 중에서 'date' 정보를 '%Y-%d-%d'꼴로 변환하는 부분이 있는데 반드시 저 꼴로만 변환이 가능한지 궁금했다.
- data viz 부분은 몇가지 데이터셋을 가지고 계속 연습해봐야할 것 같다. 낯선 데이터셋을 구하고 그것을 이리저리 시각화해보며 insight를 얻는 방식으로 시도해봐야겠다.
회고
- 연휴에 너무 익숙해졌다. week1, week2에 대한 복습을 했어야 하는데 그러지 못했다. 이번주 주말을 활용해 복습을 해야겠다.
- 이번주부터 팀원들과 논문 리뷰도 해보기로 했다. 기초적인 부분에 대해 복습을 먼저 해야 논문을 이해하기가 수월할텐데 시간이 얼마 없어서 조금 걱정이다.
- 여전히 시간을 효율적으로 쓰지 못한다는 생각이 든다. 학습 정리에 소요되는 시간도 꽤 많다고 느껴진다. 매일 학습 정리를 하는 것이 과연 올바른 방법일까 의문이 든다. 주단위로 바꿔야 하는 것은 아닐까.
