파이썬
file, exception, log
exception
tryexceptelsefinally
file
- text file, binary file
- ASCII, unicode
f = open(~)- mode
- r,w, etc.
f.read()f.close()f.readline()- etc.
- mode
log
- log의 효용, 필요성
Pickleimport pickle- 파이썬 객체의 영속화
- logging level
- debug
- info
- warning
- error
- critical
python data handling
- csv(comma seperated values)
- html(hypertext markup language)
- regular expression(정규 표현식)
- xml
- json
numpy
- numerical python
- 데이터 분석과 인공지능 학습에 있어 핵심적인 라이브러리
- 행렬을 다루는 데 있어서 도움이 매우 많이 됨.
numpy.ndarray라는 type을 가짐.- list와는 다른 성질
- python의 dynamic typing 성질을 가지고 있지 않음.
- 자동으로 data type을 변경할 수는 없으나(각 원소들의 하나의 data type으로 통일되어 있음) C의 array 방식을 이용해 생성되어 list에 비해 효율적인 부분이 있음.
np.array()shape()reshape()nbyte()flatten()
- indexing, slicing
a[][],a[ , ]a[:][2,4],a[1:3][3]
arange()arange(10)arange(1,10,0.5)arange(10).reshape(5,2)
ones(),zeros(),empty()identity()eye()np.random.uniform(start, end, count)
균등분포 random samplingsum()- axis
axis=0: (2D array라고 할 때) 각 열의 모든 원소의 합을 원소로 갖는 행렬. 행번호가 증가하는 방향의 모든 원소를 더함.
반환된 행렬은 기존 행렬의 열의 개수만큼 원소를 가지고 있음.axis=1: 각 행의 모든 원소의 합을 원소로 갖는 행렬. 열번호가 증가하는 방향의 모든 원소를 더함.
반환된 행렬은 기존 행렬의 행의 개수만큼 원소를 가지고 있음.
- axis
mean(),std()transpose(),T- broadcasting
shape이 다른 배열 간의 연산. 단 행렬곱에서는 연산 규칙을 지켜야 함(앞 행렬의 열 개수 = 뒷 행렬의 행 개수) - *
%timeit- 속도 측정.
- comparison
np.any(a>5)np.all(a>5)
- etc.
math
신경망
- 비선형모델
선형모델 + 비선형함수
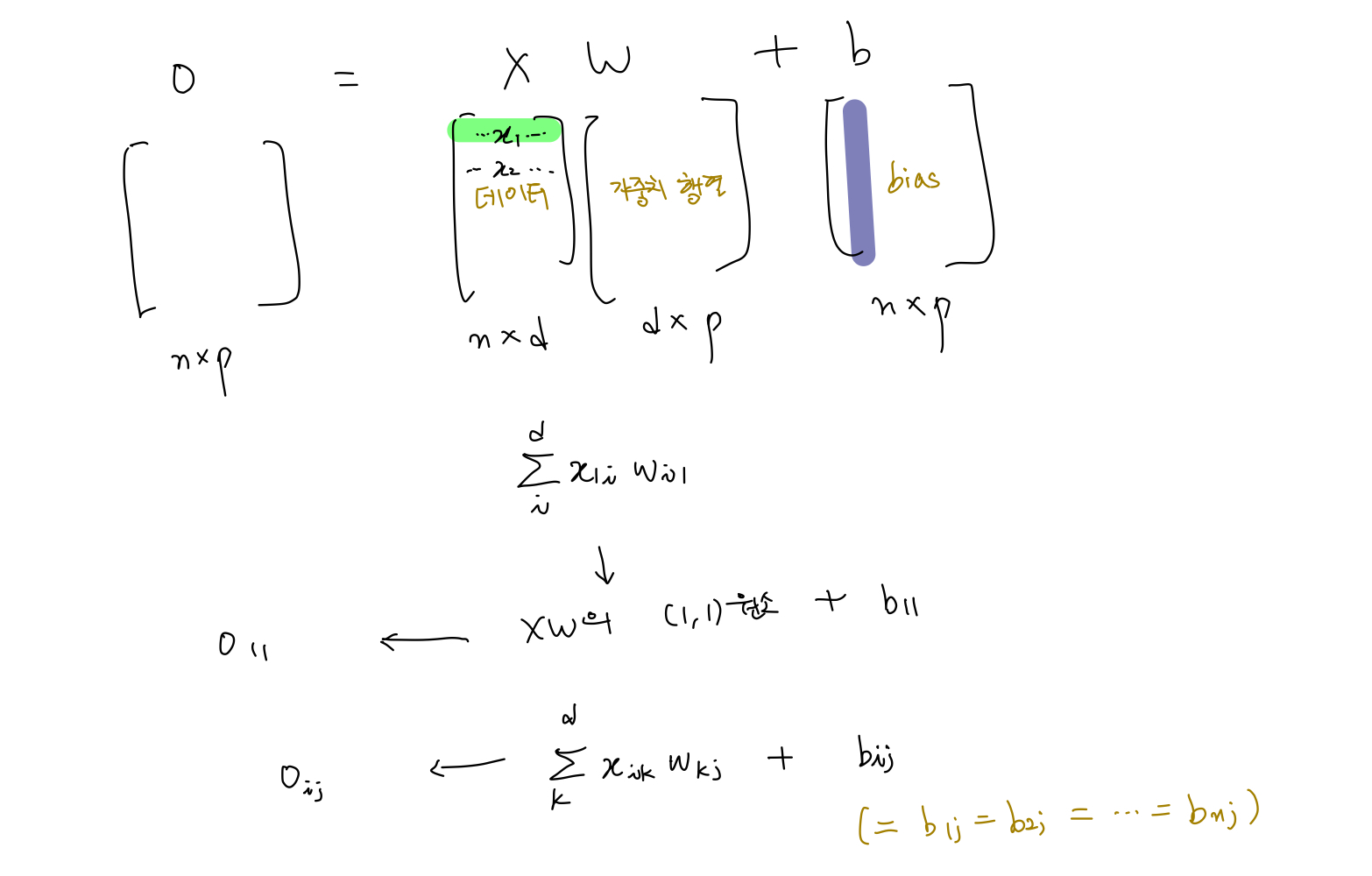
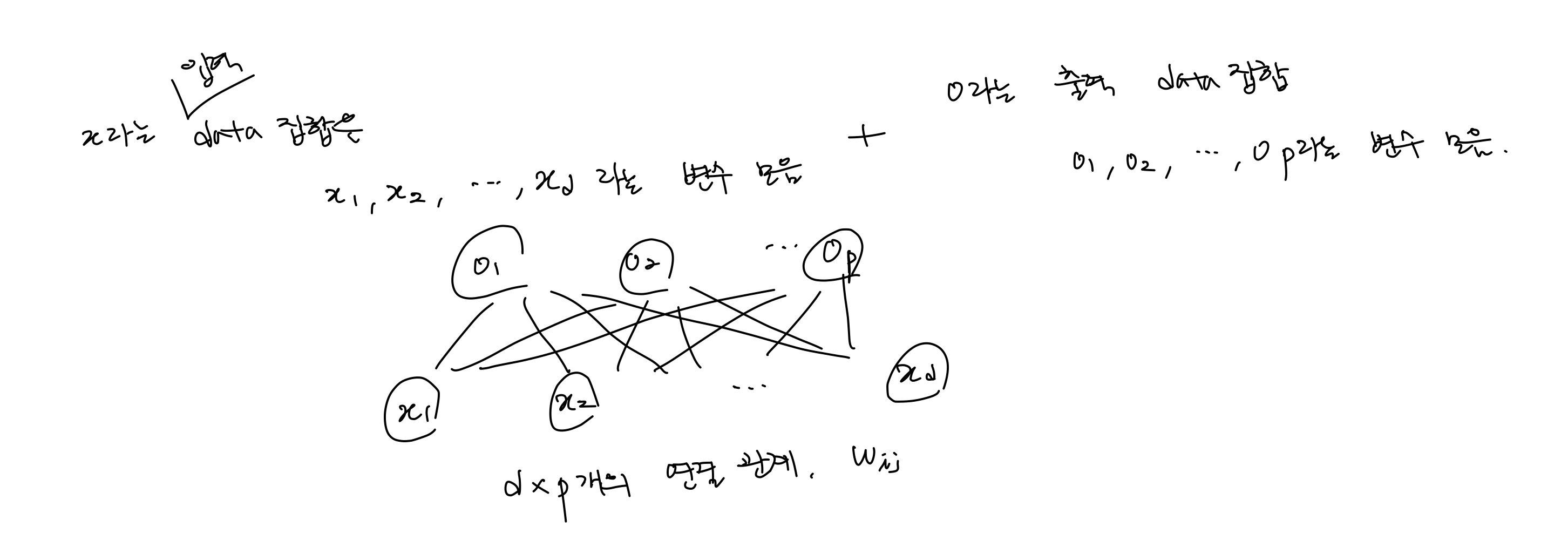
- 비선형함수의 필요성?
- 문제에 따라 적절한 함수를 선택할 필요가 있음.
- ex) softmax, sigmoid, tanh(x), ReLU
- MLP(Multi-Layered Perceptron)
- 층이 얕으면 필요 노드의 ↑
- 하지만 층이 깊어질수록 최적화 난이도 ↑
- forward-propagation
- back-propagation
- 딥러닝 학습 원리
- 연쇄법칙(chain-rule) 기반 미분
확률론
- 데이터 공간과 데이터 분포
- 이산확률변수, 연속확률변수
- 이산/연속 여부는 데이터 공간이 아닌 데이터 분포에 따라 결정됨.
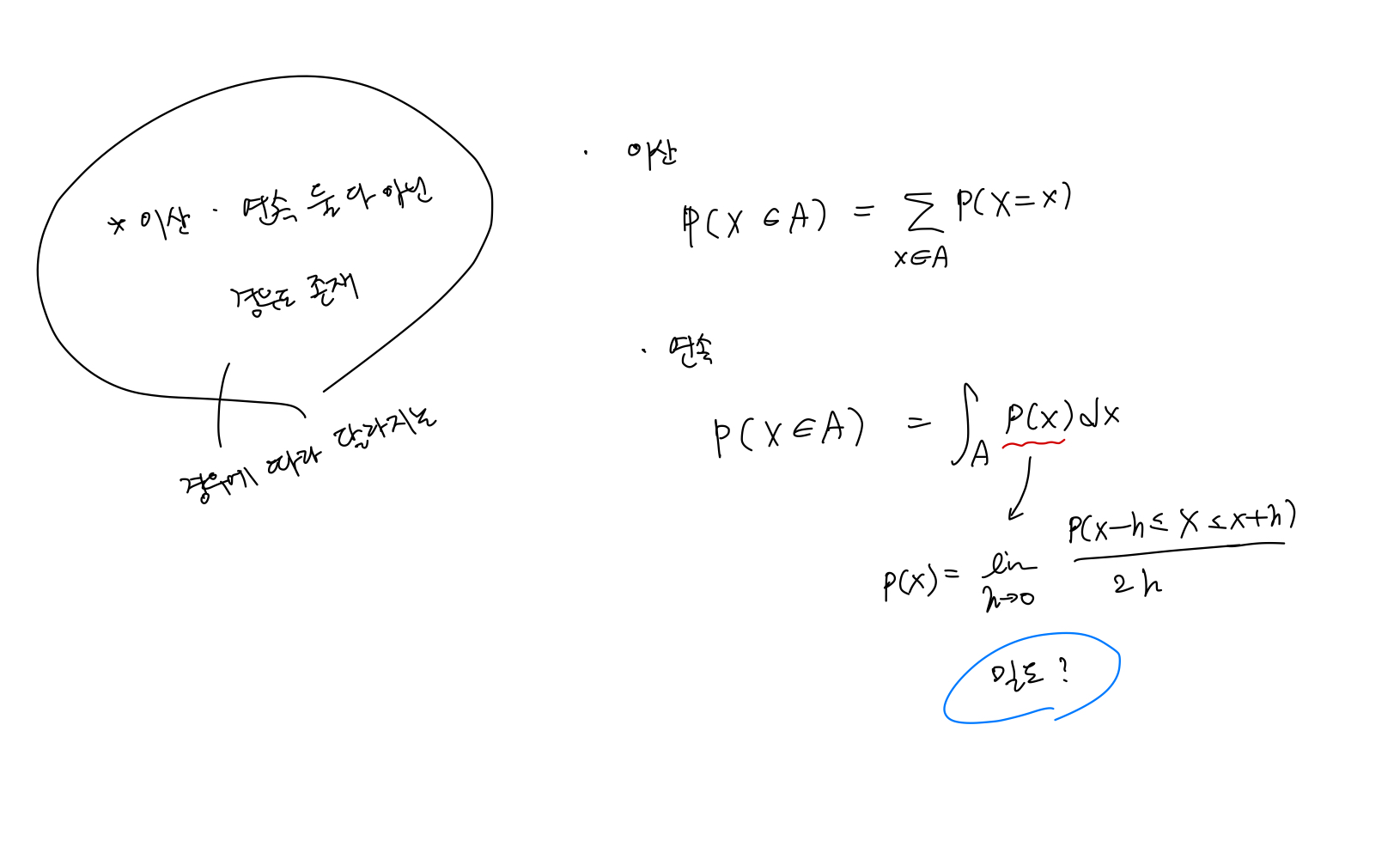
- 이산/연속 여부는 데이터 공간이 아닌 데이터 분포에 따라 결정됨.
통계학
- 모수란?
- 유한한 개수의 데이터 관찰로 모집단의 분포를 정확하게 알아낸다는 것은 불가 → 근사적으로 확률분포를 추정해야 함.
- 데이터가 특정 확률분포를 따른다고 선험적으로 가정한 후 그 분포를 결정하는 모수를 추정하는 방법 → 모수적 방법론
- 특정 확률분포 가정 없이 데이터에 따라 모델의 구조나 모수의 개수가 바뀌면 비모수 방법론
- 평균과 기댓값, 표본평균, 표본분산
- 표집분포
- 최대가능도 추정법(Maximum Likelihood Estimation, MLE)

- 데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화
- 왜 로그냐? 곱연산을 합연산으로 바꿀 수 있기 때문.
- 데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화
베이즈 통계학
- 조건부 확률
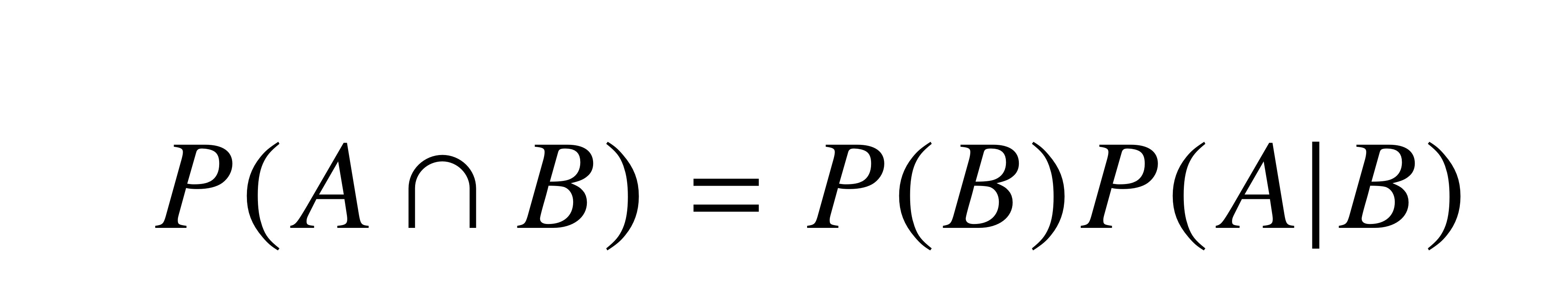
- 베이즈 정리

-
베이즈 정리를 통한 정보의 갱신
-
조건부 확률과 인과 관계
- 조건부 확률을 인과 관계 추론에 함부로 사용해서는 안됨.
Questions
- 비선형함수는 정확히 왜 필요한걸까?
- 그 전에 '선형'이란 건 정확하게 무슨 의미일까?
- MLP에서 층을 올라갈수록 데이터의 구성은 정확히 어떤 형태들로 달라지는가?
- 데이터 공간, 데이터 분포, 확률 변수 등의 용어는 정확히 어떤 뜻을 가지는가?
- 모수의 예시에는 무엇이 있는가?
- 최대가능도 추정법을 이용한 수식 전개, 행렬식의 형태
- 머신러닝 각 문제에서 추정된 확률 분포는 무엇이 있는가? 빈번하게 사용되거나 효과적인 분포가 있는가?
- 베이즈 정리의 시각화 이해가 더 필요하다. 문제가 주어졌을 때 문제의 정보들부터 사후확률, 가능도 등 각 부분을 알아내는 연습이 더 필요하다.
회고
지금까지 배운 수학적 기초에서 가장 중요한 부분은 선형대수일 것이다. 그리고 그 다음으로는 확률론과 통계학이 자리잡고 있을 것이다.
선형대수도 아직 부족하지만 확률과 통계 부분은 정말 아는 것이 거의 없는 것 같다. 설명을 보고 '대충 이런 느낌이구나'하는 생각은 들지만 구체적으로는 잘 모르겠다. 또 심화 문제를 풀다보니 이론을 실습에 적용해보는 데에 어려움을 많이 느꼈다.
아무래도 관련 자료를 찾아보면서 추가적인 공부가 필요할 것 같다. 기초적인 용어들도 모르고 있으니...
익숙해지자, 꾸준히 반복하자
라고 계속 다짐하고 있지만 조금은 지친 하루였다. 하지만 결국 왕도는 없을테고 다음 하루, 다음 일주일, 다음 한달 등 계속 나아가다 보면 익숙해지지 않을까.

BEST? BETTER!