AJAX 복습하기
스파르타피디아 API (GET)
http://spartacodingclub.shop/web/api/movie
스파르타피디아의 영화 리뷰 데이터를 받아와서 카드에 넣어볼 것이다.
$(document).ready(function () {
listing();
});
function listing() {
$('#mycards').empty();
$.ajax({
type: "GET",
url: "http://spartacodingclub.shop/web/api/movie",
data: {},
success: function (response){
let rows = response['movies']
for(let i = 0; i < rows.length; i++){
let title = rows[i]['title']
let desc = rows[i]['desc']
let image = rows[i]['image']
let star = rows[i]['star']
let comment = rows[i]['comment']
let star_image = '⭐'.repeat(star)
let temp_html = `<div class="col">
<div class="card">
<img src="${image}" class="card-img-top" alt="...">
<div class="card-body">
<h5 class="card-title">${title}</h5>
<p class="card-text">${desc}</p>
<p>${star_image}</p>
<p class="mycomment">${comment}</p>
</div>
</div>
</div>`
$('#mycards').append(temp_html)
}
}
})
}이미지에는 불러온 링크를 넣고 ${image}, 각각 알맞는 위치에 데이터를 넣었다. 별은 .repeat()함수를 이용하여 star의 개수만큼 ⭐이미지를 반복해주어서 넣었다.
Python과 웹 스크래핑, DB
Python
기초문법
변수
a = 3
b = 2
a = a + 1 #a에 a+1을 대입
num1 = a * b
num2 = 99
name = '철수'
last_name = '김'
print(name + last_name) #철수김변수에 문자열이 들어갈 수도, 정수가 들어갈 수도 있다. 다른 언어들처럼 세미콜론을 넣어 끝마침을 표시하지도 않는다.
List
a_list = ['사과', '배', '감']
a_list.append('귤')
a_list.append(['포도', '망고'])
print(a_list) #['사과', '배', '감', '귤', ['포도', '망고']]배열 안에 배열을 또 넣을 수도 있다.
배열에 값을 추가할 때는 append()함수를 사용한다.
dictionary형 (key : value)
a_dict = {
'name':'isabel',
'age':30
}
a_dict['height'] = 178 #dictionary형 추가
print(a_dict) #{'name': 'isabel', 'age': 30, 'height': 178}
print(a_dict['name']) #isabeldictionary형 + List배열
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
# people[0]['name']의 값은? 'bob'
# people[1]['name']의 값은? 'carry'
person = {'name':'john','age':7}
people.append(person)
# people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}]
# people[2]['name']의 값은? 'john'딕셔너리형과 리스트형을 조합하여 데이터를 저장할 수 있다.
함수 definition(def)
def sum(a,b):
return a+b
result = sum(1,2) #1+2의 리턴값을 result에 담는다
print(result) #return값 3을 출력한다파이썬에서는 들여쓰기가 중요하다고 한다. 들여쓰기에 따라서 결과값이 달라질 수 있다고,
그리고 중괄호를 쓰지 않고 들여쓰기와 ':'콜론을 사용하여 문장을 이어간다.
조건문(if... else...)
def is_adult(age): #매개변수 age를 받는 함수 is_adult를 선언
if age>20:
print('성인입니다.')
else:
print('미성년자입니다.')
is_adult(25) #trueif와 else, 실행문의 들여쓰기를 맞춰 주어야한다.
반복문(for)
파이썬에서 반복문은 리스트의 요소들을 하나씩 꺼내쓰는 형태로 사용된다.
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
for fruit in fruits:
print(fruit)
'fruit에 fruits리스트의 값을 한바퀴 다 돌면서 출력한다'는 의미로 보면 이해가 될 것 같다.
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0 #변수 count 선언
for fruit in fruits:
if fruit == '사과':
count += 1
print(count) # 2 출력반복문을 돌면서 fruit에 들어온 값이 '사과'와 같다면 count를 1씩 증가시킨다.
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
def count_fruits(target):
count = 0
for fruit in fruits:
if fruit == target:
count += 1
return count
subak_count = count_fruits('수박')
print(subak_count) #수박의 갯수
gam_count = count_fruits('감')
print(gam_count) #감의 갯수매개변수(target)를 각각 달리 받아서 조건과 일치하면 count하는 def를 만들 수도 있다.
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
# 모든 사람의 이름과 나이 출력
for person in people:
print(person['name'], person['age'])
# age가 25 초과이면 이름을 출력
for person in people:
if person['age']> 25:
print(person['name'])
딕셔너리형과 리스트형의 조합 데이터를 for반복문과 if조건문으로 선택하여 출력할 수 있다.
웹스크래핑(크롤링)
패키지? 라이브러리?
Python에서 패키지는 모듈(일종의 기능들 묶음)을 모아 놓은 단위를 말한다. 이런 패키지의 묶음을 라이브러리 라고 볼 수 있다.
- 가상환경(virtual environment)
같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않기 위해, 파이썬 배포 패키지들을 설치하거나 업그레이드하는 것을 가능하게 하는 격리된 실행 환경이다.
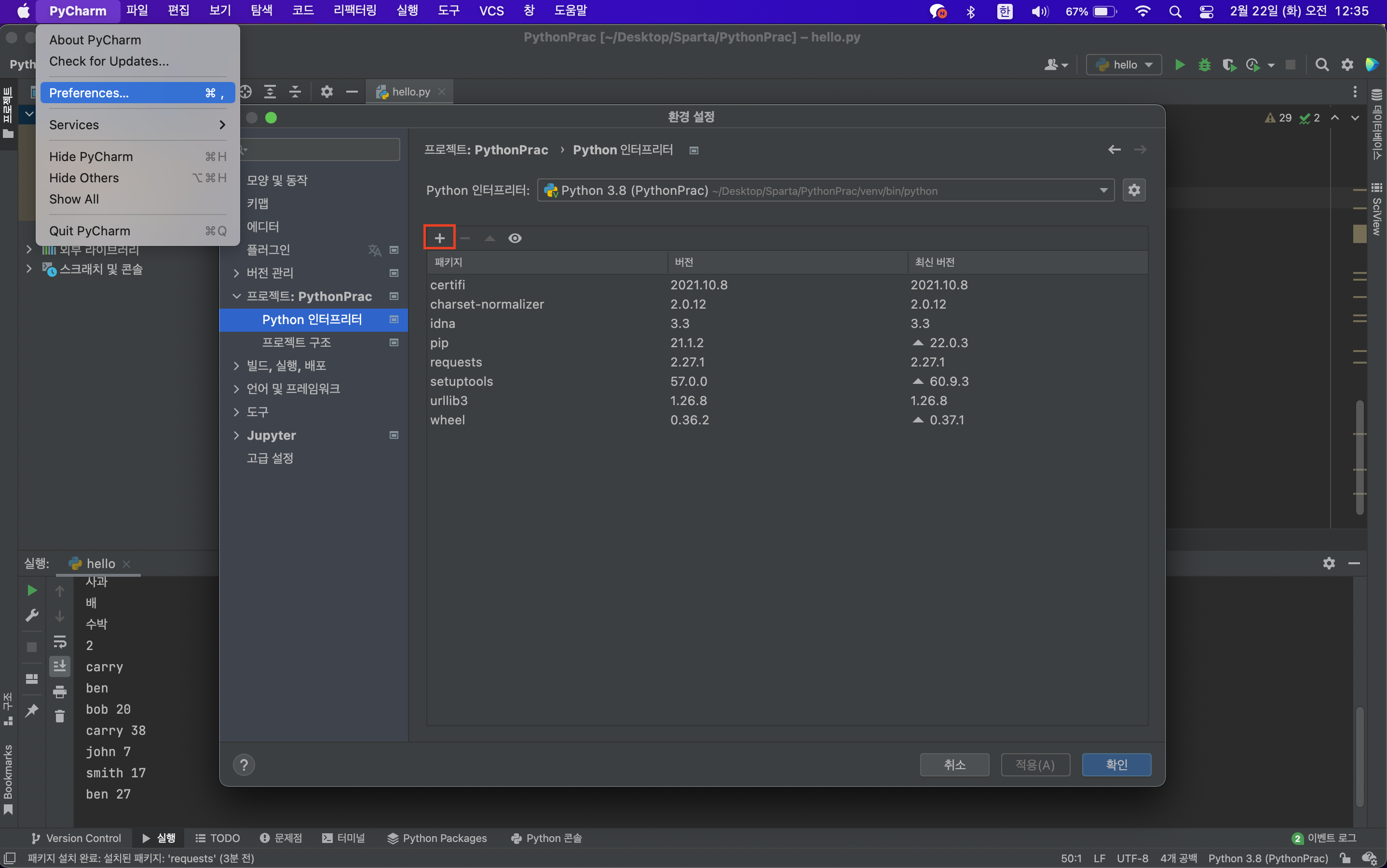
requests 패키지 설치하기
Pycharm - preferences - 프로젝트:PythonPrac - Python인터프리터 - '+'클릭 - requests 검색 - 설치

requests 사용해보기
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows:
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
if gu_mise < 55:
print(gu_name,gu_mise)AJAX처럼 requests 패키지를 이용하여 API 정보를 sort out해올 수 있다.
beautifulsoup4 패키지 설치하기
Pycharm - preferences - 프로젝트:PythonPrac - Python인터프리터 - '+'클릭 - bs4 검색 - 설치
크롤링 기본 셋팅
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "parsing 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
print(soup) #해당 url의 html을 출력
웹 스크래핑 연습 : '네이버 영화'에서 영화의 제목들 가져오기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#select_one을 이용해서 데이터를 가져온다
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title['href'], title.text)title['href']: 타이틀에 연결된 하이퍼링크 url을 불러와 출력한다.
title.text: 영화 제목만 불러와 출력한다.
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
print(a.text)for반복문을 이용하여 table list를 쭉 돌면서 영화 제목을 모두 출력한다.
-
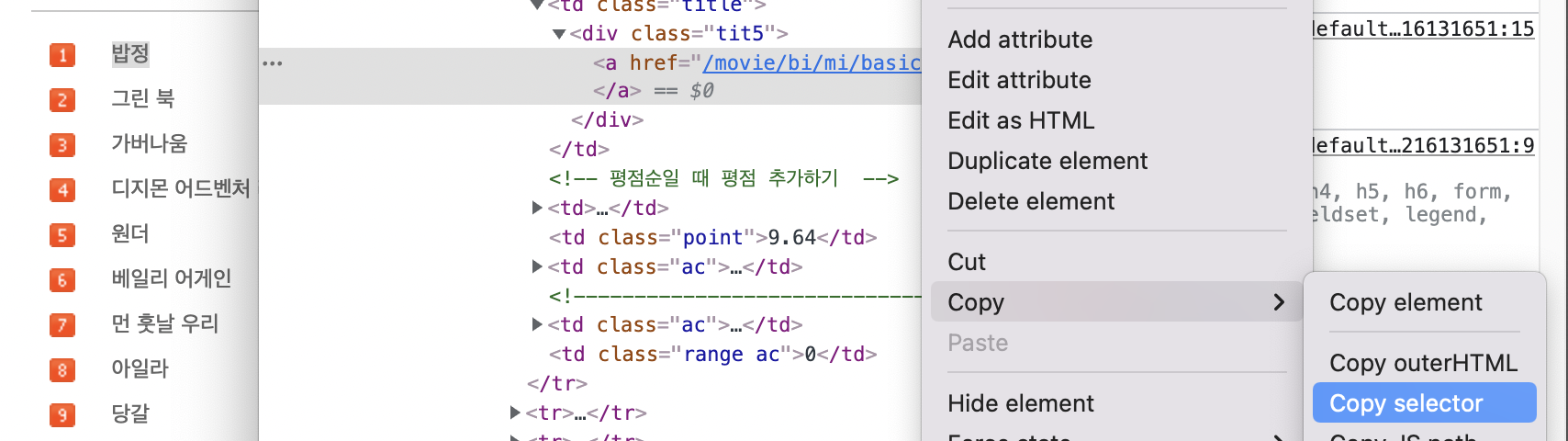
선택자를 사용하는 방법 (copy selector)
위의 예제에서는 크롬에서 개발자 도구에서 복사해 와서 사용하였다.
원하는 부분 선택 - 오른쪽 클릭 - 검사 - 오른쪽 클릭 - copy - copy selector
-
선택자를 사용하는 방법
- soup.select('태그명')
- soup.select('.클래스명')
- soup.select('#아이디명')
- soup.select('상위태그명 > 하위태그명 > 하위태그명')
- soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
- 태그와 속성값으로 찾는 방법
- soup.select('태그명[속성="값"]')
한 개만 가져오고 싶은 경우 - 1 - soup.select_one('태그명[속성="값"]')
웹 스크래핑 연습 : '네이버 영화'에서 순위와 제목, 별점 가져오기
중간중간에 내가 원하는 값이 맞는지 확인하기 위해 print(원하는 값)으로 출력해보기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title['href'], title.text)
movies = soup.select('#old_content > table > tbody > tr')
print(movies)
for movie in movies: #movies를 도는 반복문
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
#순위의 alt값 스크래핑해오기
rank = movie.select_one('td:nth-child(1) > img')['alt']
#별점의 Point값 텍스트로 스크래핑해오기
star = movie.select_one('td.point').text
#출력
print(rank, title, star)아직은 뒤에 ['alt']를 어떤 모양으로 어디에 붙여야 출력이 잘 되는지가 헷갈린다.
select와 select_one
위에서 예제들을 통해서 bs4을 가지고 select와 select_one으로 태그에 접근했다.
select와 select_one의 차이점은 select는 결과값이 리스트로 반환되고, select_one은 그렇지 않다 는 것이다.
위에서 select는 모든 tr 태그를 찾아 리스트에 담게 된다. select_one은 문서의 처음부터 시작해서 조건에 맞는 하나의 값만을 찾게 된다.
따라서 select_one은 ('td:nth-child(1) > img')['alt']를 적용할 수 있다. 하지만 select는 for문을 사용하여 다시 개별적으로 접근해야한다.
DB
SQL (관계형 DB)
SQL을 사용하면 관계형 데이터베이스 관리 시스템(relational database management system, RDBMS)에서 데이터를 저장, 수정, 삭제 및 검색을 할 수 있다. SQL은 두 가지 중요한 특징을 가진다.
- 데이터는 정해진(엄격한) 데이터 스키마 (= structure)를 따라 데이터베이스 테이블에 저장된다.
- 데이터는 관계를 통해서 연결된 여러개의 테이블에 분산된다.
데이터 스키마를 준수하지 않는 데이터는 추가할 수 없다. 또한 중복을 피하기 위해서 '관계'를 이용한다. 하나의 테이블에서 중복없이 하나의 데이터만을 관리하기 때문에, 다른 테이블에서 부정확한 데이터를 다룰 위험이 없다는 것이 장점이다.
NoSQL (비관계형 DB)
NoSQL에서는 스키마도 없고, 관계도 없다.
NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가할 수가 있다. 컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 합니다. 하지만 이렇게 되면 데이터가 중복되어 서로 영향을 줄 위험이 있다. 따라서 자주 변경되지 않는 데이터일 때 NoSQL을 쓰면 상당히 효율적이다.
대표적인 예로 MongoDB가 있다.
MongoDB
MongoDB에 연결하기
연결 셋팅 코드는 아래와 같다.
from pymongo import MongoClient
import certifi
client = MongoClient('mongodb+srv://isabel_noh:sparta@cluster0.0vjef.mongodb.net/Cluster0?retryWrites=true&w=majority',tlsCAFile=certifi.where())
db = client.dbsparta데이터 입력하기
db.users.insert_one({'name':'bob', 'age':25})
db.users.insert_one({'name':'john', 'age':34})
db.users.insert_one({'name':'isabel', 'age':30})
doc = {'name': 'christine', 'age': 34}
db.users.insert_one(doc)데이터 모두 읽어오기
all_users = list(db.users.find({})) #중괄호 안에 조건을 쓸 수 있음
for user in all_users:
print(user)
-------------------------------------------------------------
{'_id': ObjectId('6214bb1ee5e148044c495627'), 'name': 'bob', 'age': 27}
{'_id': ObjectId('6214bd1d6d9635e9a00f9065'), 'name': 'bobby', 'age': 27}
{'_id': ObjectId('6214bd1e6d9635e9a00f9066'), 'name': 'john', 'age': 25}
{'_id': ObjectId('6214bd1e6d9635e9a00f9067'), 'name': 'christine', 'age': 34} 조건을 정하지 않고 모든 데이터를 리스트 형태로 묶어서 불러왔다.
all_users = list(db.users.find({},{'_id':False}))
for user in all_users:
print(user)
-------------------------------------------------------------
{'name': 'bob', 'age': 27}
{'name': 'bobby', 'age': 27}
{'name': 'john', 'age': 25}
{'name': 'christine', 'age': 34}이번엔 _id값을 빼고 불러왔다.
값 하나만 불러오기
user = db.users.find_one({'name':'bobby'}, {'_id':False})
print(user)
-------------------------------------------------------------
{'name': 'bobby', 'age': 27}
user = db.users.find_one({'name':'bobby'})
print(user['age'])
-------------------------------------------------------------
27값 수정하기
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
user = db.users.find_one({'name':'bobby'})
print(user)
-------------------------------------------------------------
19값 삭제하기
db.users.delete_one({'name':'bobby'})스크래핑한 영화 정보 MongoDB에 insert하기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import certifi
client = MongoClient('mongodb+srv://isabel_noh:sparta@cluster0.0vjef.mongodb.net/Cluster0?retryWrites=true&w=majority',tlsCAFile=certifi.where())
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
doc = {
'title':title,
'rank':rank,
'star':star
}
db.movies.insert_one(doc)
DB를 확인해보면 아래처럼 movies라는 directory 안에 잘 들어온 것을 확인할 수 있다.

Quiz_웹스크래핑 결과 이용하기
1. 영화제목 '가버나움'의 평점 가져오기
from pymongo import MongoClient
import certifi
client = MongoClient('mongodb+srv://isabel_noh:sparta@cluster0.0vjef.mongodb.net/Cluster0?retryWrites=true&w=majority',tlsCAFile=certifi.where())
db = client.dbsparta
movie = db.movies.find_one({'title':'가버나움'})
print(movie['star'])
-------------------------------------------------------------
9.592. '가버나움'의 평점과 같은 평점의 영화 제목들을 가져오기
#나의 문제 풀이
movie = db.movies.find({'star':'9.59'})
for m in movie:
print(m['title'])
-------------------------------------------------------------
#답안
movie = db.movies.find_one({'title':'가버나움'})
star = movie['star']
all_movie = list(db.movies.find({'star':star}))
for m in all_movie:
print(m['title'])데이터를 모두 불러올 때는 list로 묶어야하는데 그걸 잊고 그냥 for문을 돌렸는데 해결이 되었다..?
그래도 까먹지 말 것.
list(db.____.find({조건})
3. '가버나움' 영화의 평점을 0으로 만들기
movie = db.movies.find_one({'title':'가버나움'})
db.movies.update_one({'title':'가버나움'},{'$set':{'star':'0'}})
9.59에서 0으로 잘 바뀐 걸 확인할 수 있다.
숙제: 지니뮤직의 1~50위 곡을 스크래핑하기
Phython의 strip()함수를 참고하여 숙제를 해결해보자
Python의 String은 다음 함수를 제공합니다.
- strip([chars]) : 인자로 전달된 문자를 String의 왼쪽과 오른쪽에서 제거합니다.
- lstrip([chars]) : 인자로 전달된 문자를 String의 왼쪽에서 제거합니다.
- rstrip([chars]) : 인자로 전달된 문자를 String의 오른쪽에서 제거합니다.
또 텍스트에서 앞 2글짜만 따올 때는 .text[0:2]
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
title = song.select_one(' td.info > a.title.ellipsis').text.strip()
rank = song.select_one(' td.number').text[0:2].strip()
singer = song.select_one(' td.info > a.artist.ellipsis').text.strip()
print(rank, title, singer)계속 똑같이 한 것 같은데 안 되길래 보니까
body-content > div.newest-list > div > table > tbody 뒤에 > tr을 빠트렸었다.
3주차도 완강!
