
해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
통계학(statistic)
- 산술적 방법을 기초로 하여, 다량의 데이터를 정리 및 분석하는 방법을 연구하는 수학의 한 분야
기술통계학(descriptive statistics)
- 데이터를 수집하고 쉽게 이해하고 설명할 수 있도록 정리 요약하는 방법론
추론통계학(inferential statistics)
- 모집단으로 부터 추출한 표본의 데이터를 분석하여 모집단의 여러가지 특성을 추측하는 방법론

1. 데이터와 그래프
변수
- 수학 : 정해지지 않은 값, 변하는 숫자
- 통계 : 조사 목적에 따른 관측값
양적자료(수치형데이터 = 이산형 + 연속형)
-
관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있음
-
숫자를 표현할 때 이산형과 연속형으로 구분됨
-
이산형
-
수치적이지만 소수점이 없어서 연속적으로 표현될 수 없음(정수로 떨어지는 수)
-
ex) 제품의 개수, 과목 수
-
-
연속형
-
소수점이 있어서 연속적으로 표현될 수 있음
-
ex) 몸무게, 길이, 과학적인 단위(시간, 힘 ...)
-
-
질적자료(범주형데이터 = 명목형 + 순서형)
-
관측된 데이터가 성별, 주소지 등 범주로 구분하여 표현할 수 있는 데이터
-
데이터 입력시 1은 남자, 2는 여자처럼 다른 의미로 사용할 수 있으나 크기의 의미는 없다.
-
명목형데이터
-
데이터간의 우열이 존재하지 않음
-
ex) 혈액형, 주소, 성별
-
-
순서형데이터
-
데이터간의 우열이 존재함
-
ex) 만족도, 성적등급
-
-
Exploratory Data Analysis(탐색적 데이터 분석)
- 데이터를 탐색하는 분석 방법으로 도표, 그래프, 요약 통계 등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법
- 목적
- 데이터 분석 프로젝트 초기에 가설을 수립하기 위해 사용
- 데이터 분석 프로젝트 초기에 적절한 모델 및 기법의 선정
- 변수 간 트렌드, 패턴, 관계 등을 찾고 통계적 추론을 기반으로 가정을 평가
- 분석 데이터에 적절한가 평가, 추가 수집, 이상치 발견 등에 활용

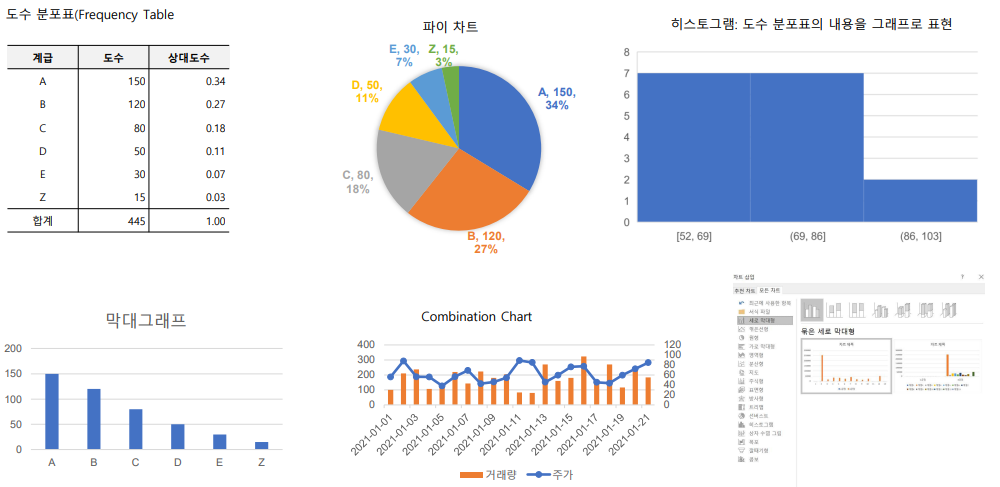
2. 데이터와 통계량
중심경향치
-
표본(데이터)를 이해하기 위해 표본의 중심을 설명하는 값을 대표값
-
대표적인 중심경향치 : 평균, 중앙값, 최빈값, 절사평균
-
평균(average)
-
수치적으로 중앙에 해당하는 값
-
가장 일반적인 경향치
-
-
중앙값(median)
-
관측치를 정렬했을 때, 가운데 위치하는 값
-
관측치가 짝수일 경우 가운데 두개의 산술평균 값
-
이상치가 포함된 데이터에서 사용
-
-
최빈값(mode)
-
관측치 중에서 가장 많이 관측되는 값
-
명목형 데이터의 경우 사용
-
-
절사평균(trimmed mean)
-
평균과 중앙값의 장점을 갖는 대푯값
-
관측치 중 일정 비율로 가장 큰 값과 작은 값을 제외한 산술평균
-
이상치가 포함된 데이터에서 사용
-
-
산포도
-
데이터의 흩어짐 정도를 의미함
-
대표적인 산포도 : 범위, 사분위수, 분산, 표준편차, 변동 계수 등
-
범위(Range)
- 데이터의 최대값과 최소값의 차이
-
사분위수(Quartile)
-
전체 데이터를 오름차순으로 정렬하여 4등분한 수
-
사분위수 범위

-
-
백분위수(Percentile)
-
전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값을 말하며, 제p백분위수는 p%에 위치한 자료 값을 말함
-
데이터를 오름차수로 배열하고 자료가 n개가 있을 때, 제(100*p) 백분위수는 아래와 같음
-
1) np가 정수이면, np번째와 (np + 1)번째 자료의 평균
-
2) np가 정수가 아니면, np보다 큰 최소의 정수를 m이라고 할 때 m번째 자료
-
-
분산(Variance)
-
데이터의 분포가 얼마나 흩어져 있는지 알 수 있는 대표적인 측도
-
, {}
-
-
표준 편차(standard deviation)
-
분산의 제곱근으로 정의하며 수식은 아래와 같음
-
-
참고사항 : 표준편차의 분모가 n-1인 이유 유튜브 12Math
-
모분산과 모표준편차
-
-
변동계수(Coefficient of Variation: CV)
-
평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용함
-
변동계수는 표준편차를 평균으로 나누어서 산출하여 단위나 조건에 상관 없이 서로 다른 그룹의 산포를 비교하며 실제 분석에서자주 사용함
-
cv = 표준편차 / 평균
-
-
왜도(Skew)
-
자료의 분포가 얼마나 비대칭적인지 표현하는 지표
-
왜도가 0이면 좌우가 대칭이고, 0에서 클수록 우측꼬리가 길고, 0에서 작을수록 좌측 꼬리가 김

-
-
첨도(Kurtosis)
-
확률분포의 꼬리가 두꺼운 정도를 나타내는 척도
-
첨도값(K)이 3에 가까우면 산포도가 정규분포에 가까움
-
3보다 작을 경우에는(K<3) 산포는 정규분포보다 꼬리가 얇은 분포로 생각할 수 있다, 첨도값이 3보다 큰 양수이면(K>3) 정규분포보다 꼬리가 두꺼운 분포로 판단
-
-

