1. 도메인 주도 설계란?
도메인 모델링이란?
모델은 현실에 일어나는 사건 혹은 개념을 추상화한 개념이다. 추상이란 여러 사물 혹은 개념에서 공통적인 것을 뽑하 파악하는 것으로, 현실의 모든 것을 반영하는 것이 아니다. 이렇게 사건 혹은 개념을 추상화하는 작업을 모델링이라고 한다. 그리고 모델링의 결과를 모델이라고 한다.
도메인 개념 <-> 도메인 모델 <-> 도메인 객체
이렇게 서로 상호 작용을 한다.
왜 지금 도메인 주도 설계가 필요한가?
도메인 주도 설계는 도메인에 주목해 요구사항 분석 부터 설계, 개발에 이르기까지 소프트웨어 개발 과정에 상호작용이 필요하다. 도메인 주도 설계의 진정한 가치가 드러나는 것은 변화에 대응해 소프트웨어를 수정할 때다. 예전에는 도메인 주도 설계가 기민하지 못하다고 평가 받았으나, 안정적으로 운영하는데서 가치가 있다.
2. 시스템 특유의 값을 나타내기 위한 "값 객체"
프로그래밍 언어에는 원시 데이터 타입이 있다. 이 원시 데이터 타입만 사용해 시스템을 개발할 수도 있지만, 때로는 시스템 특유의 값을 정의해야 할 때가 있다. 이러한 시스템 특유의 값을 표현하기 위해 정의하는 객체를 값 객체라고 한다.
값의 성질과 값 객체 구현
- 변하지 않는다
- 주고받을 수 있다
- 등가성을 비교할 수 있다.
값의 불변성
값을 수정할 수 있다면 안심하고 값을 사용할 수 없다. 1이라는 숫자가 값자기 0이되면 혼란이 야기된다. 1은 항상 1이다. 변수에 다른 값으로 수정하는 것과 다른 의미다.
교환 가능하다
값 객체는 불변이기 때문에 대입문을 통해 교환한다.
값 객체가 되기 위한 기준
시스템에서 사용되는 개념 중 어디까지 값 객체로 만들어야하는지는 어려운 문제다.
필자는 "규칙이 존재하는가"와 "낱개로 다루어야 하는가"를 중요한 점으로 본다.
성명에 관해 "성과 이름으로 구성된다"의 경우 "낱개로 다뤄지는" 정보다. 그렇다면 값 객체로 정의해야 할 개념이된다.
행동이 정의된 값 객체


값 객체는 결코 데이터를 담는 것만이 목적인 구조체가 아니다. 값 객체는 데이터와 더불어 그 데이터에 대한 행동을 한 곳에 모아둠으로써 자신만의 규칙을 갖는 도메인 객체가 된다.
3. 생애 주기를 갖는 객체 - 엔티티
도메인 주도 개발에서 말하는 엔티티는 도메인 모델을 구현한 도메인 객체를 의미한다. 앞서 2장에서 다룬 값 객체도 도메인 모델을 구현한 도메인 객체다. 이 두가지 객체의 차이는 동일성을 통해 식별이 가능한지 아닌지에 있다.
엔티티의 성질
엔티티는 속성이 아닌 동일성으로 식별되는 객체다. 반대로 동일성이 아닌 속성으로 식별되는 객체도 있다.
- 가변이다
- 속성이 같아도 구분할 수 있다
- 동일성을 통해 구별된다.
가변이다
값 객체는 불변성을 갖기 때문에 객체를 교환(대입)해 수정했지만, 엔티티는 수정을 위해 객체를 교환하지 않는다. 엔테테의 속성을 수정하려면 객체의 행동을 통해 수정하면 된다.
엔티티의 판단 기준 - 생애주기와 연속성
어떤 것을 값 객체로 정의하고 어떤 것을 엔테테로 정의할까? 생애주기 존재 여부와 그 생애주기의 연속성 여부가 중요한 판단 기준이 된다.
사용자는 시스템을 사용하려는 사람에 의해 생성된다. 사용자를 생성하는 동시에 태어나 삭제와 함께 죽음을 맞는다. 사용자는 말 그대로 생애주기를 가지며 연속성을 갖는 개념이다. 엔테테로 판단하기에 문제가 없다.
생애주기를 갖지 않거나 생애주기를 나타내는 것이 무의미한 개념이라면 값 객체로서 다루는 것이 좋다.
도메인 객체를 정의할 때의 장점
자기 서술적인 코드가 된다
UserName에 3 글자 이상이어야 한다 같은 코드가 있으면 도메인 모델과 관련된 규칙은 모두 도메인 객체로 옮겨지며 이들 규칙이 도메인 객체의 유효성을 보장한다.
도메인에 일어난 변경을 코드에 반영하기 쉽다.
사용자명이 6글자 이상으로 도메인의 규칙에 변경이 일어나면, 도메인 모델의 규칙이 기술된 코드를 명확히 구별할 수 있으므로 수정도 그만큼 쉽다.
4. 부자연스러움을 해결하는 도메인 서비스
서비스란?
소프트웨어 개발에서 말하는 서비스는 클라이언트를 위해 무언가를 해주는 객체를 말한다. 도메인 주도 설계에서 말하는 서비스는 크게 두 가지로 나뉜다. 첫 번째는 도메인을 위한 서비스고 두 번째는 애플리케이션을 위한 서비스다. 확실히 구분하기 위해 전자는 도메인 서비스, 후자는 애플리케이션 서비스라고 부르겠다.
도메인 서비스란?
값 객체나 엔티티 같은 도메인 객체는 객체의 행동을 정의할 수 있다. 그러나 시스템에는 값 객체나 엔티티로 구현하기 어색한 행동도 있다. 도메인 서비스는 이런 어색함을 해결해주는 객체다.
값 객체나 엔티티의 정의하기에 어색한 행동
사용자명에 중복을 허용하지 않는 것은 도메인의 규칙이며 따라서 도메인 객체에 행동으로 정의돼야 한다.
엔티티로 구현한 사용자 객체에 사용자명 중복 처리를 구현하는 것은 부자연스럽다. 이런 것을 도메인 서비스가 해결해준다.
물류 시스템의 도메인 서비스 예
도메인 서비스 중에는 데이터스토어와 같은 인프라스트럭처와 엮이지 않고 도메인 객체만 다루는 것도 있다. 오히려 그런 도메인 서비스가 진짜 도메인 서비스라고 할 수 있다.

운송을 위한 거점이다.

거점에서 거점으로 직접 화물이 이동하는 것은 부자연스럽다.

도메인 서비스로 운송을 맡을 별개의 서비스를 정의했다. 이렇게하면 훨씬 자연스럽다.
5. 데이터와 관계된 처리를 분리하자 - 리포지토리
소프트웨어로 도메인 개념을 표현했다고 해서 그대로 애플리케이션이 되는 것은 아니다. 프로그램을 실행할 때 메모리에 로드된 데이터는 프로그램을 종료하면 그대로 사라져버린다. 특히 엔티티는 생애주기를 갖는 객체이기 때문에 프로그램의 종료와 함께 객체가 사라져서는 안된다.
객체를 다시 이용하려면 데이터스토어에 객체 데이터를 저장 및 복원할 수 있어야 한다. 리포지토리는 데이터를 저장하고 복원하는 처리를 추상화하는 객체다.
객체 인스턴스를 저장할 때는 데이터스토어에 기록하는 처리를 직접 실행하는 대신 리포지토리에 객체의 저장을 맡기면 된다. 또 저장해 둔 데이터에서 다시 객체를 읽어 들일 때도 리포지토리에 객체의 복원을 맡긴다.
리포지토리의 책임
어떤 기술을 사용하든지 퍼시스턴시를 구현하는 코드는 특정 데이터스토어를 사용하기 위한 코드가 필요하기에 복잡하다. 이것을 퍼시스턴시 관련 처리를 뽑아내면 비즈니스 로직을 더운 순수하게 유지할 수 있다.
리포지토리의 인터페이스
사용자명 중복 확인과 같은 목적이 있다면 Exists 메서드를 리포지토리에 구현하는게 어떨까하는 생각도 있을 수 있다. 하지만 리포지토리의 책임은 객체의 퍼시스턴시까지다. 사용자명 중복 확인은 도메인 서비스가 주체가 되는 것이 옳다.
인프라를 다루는 처리를 도메인 서비스에 두는 것이 꺼려져 리포지토리에 사용자명 중복 확인을 정의하고 싶다면, 구체적인 중복 확인 키를 전달하는게 좋다.
인터페이스를 잘 활용하면 Program 클래스에서 퍼시스턴시와 관련된 구체적인 처리를 구현하지 않아도 객체 인스턴스를 데이터스토어에 저장할 수 있다.
6장. 유스케이스를 구현하기 위한 "애플리케이션 서비스"
애플리케이션 서비스의 의미
도메인 객체는 도메인을 코드로 옮긴 것이다. 도메인을 코드로 나타냈다고 해도 그것만으로는 이용자가 당면한 문제가 해ㅔ결되지 않는다. 도메인 객체를 조작해서 이용자의 목적을 달성하게 이끄는 객체가 애플리케이션 서비스다.
도메인 객체를 그대로 반환 값으로 사용하면 문제가 생긴다. 의도하지 않은 도에민 객체의 메서드 호출이 가능하다. 접근 제어 수정자도 한계가 있다. 그래서 클라이언트에 데이터 전송을 위한 객체 (DTO, Data Transfer Object)를 써서 반환한다.
도메인 규칙의 유출
애플리케이션 서비스는 도메인 객체가 수행하는 태스크를 조율하는 데만 전념해야 한다. 따라서 애플리케이션 서비스에 도메인 규칙을 기술해서는 안 된다. 도메인 규칙이 애플리케이션 서비스에 기술되면 같은 코드가 여러 곳에서 중복되는 현상이 나타난다.
예를 들어 사용자명의 중복을 금지하는 규칙은 도메인에 있어 중요도가 높은 규칙이다.
7장. 소프트웨어의 유연성을 위한 의존 관계 제어
프로그램에는 의존(dependency)이라는 개념이 있다. 의존은 어떤 객체가 다른 객체를 참조할 때 발생한다. 따라서 객체 간에 의존 관계가 생기는 것은 어찌 보면 당연한 일이다. 그러나 이 의존 관계를 주의해서 다루지 않으면 유연하지 못한 소프트웨어가 된다.
유연한 소프트웨어가 되려면 특정 기술에 대한 의존을 피하고, 변경의 주도권을 추상 타입에 둬야 한다.
의존 관계 역전 원칙(Dependency Inversion Principle)
A. 추상화 수준이 높은 모듈이 낮은 모듈에 의존해서는 안되며 두 모듈 모두 추상 타입에 의존 해야 한다.
B. 추상 타입이 구현의 세부 사항에 의존해서는 안 된다. 구현의 세부 사항이 추상 타입에 의존 해야 한다.
추상 타입에 의존하라
프로그램에는 추상화 수준이라는 개념이 있는데, 추상화 수준은 입.출력으로부터의 거리를 뜻한다. 추상화 수준이 낮다는 것은 기계와 가까운 구체적인 처리를 말하며, 추상화 수준이 높다는 것은 사람과 가까운 추상적인 처리를 말한다.
예를 들어 UserRepository를 다루는 UserApplicationService의 처리 내용보다는 데이터스토어를 다루는 UserRepository의 처리 내용이 기계와 더 가깝다. 추상화 수준을 따지면 UserRepository가 UserApplicationService보다 더 낮다. 추상 타입을 사용하지 않았다면 UserApplicationService는 특정 기술 기반에 비해 추상화 수준이 높은 모듈이면서도 데이터스토어를 다루는 낮은 추상화 수준의 모듈 UserRepository에 의존하는 셈이다. 이 상황은 '추상화 수준이 높은 모듈이 낮은 모듈에 의존해서는 안 된다'는 원칙에 위배된다.
IoC Container 패턴
Dependency Injection 패턴을 적용하면 의존 관계를 변경했을 때 테스트 코드 수정을 강제할 수 있다.
8. 소프트웨어 시스템 구성하기
9. 복잡한 객체 생성을 맡길 수 있는 "팩토리 패턴"
팩토리는 객체를 만드는 지식에 특화된 객체다. 복잡한 객체 생성 절차는 억지로 객체 안에 구현하는 것보다 객체 생성 과정 자체를 별도의 객체로 만들어 두면 코드의 의도를 더 명확히 할 수 있다.
번호 매기기를 구현해보자.
IUserFactory를 통해서 직접 DB에 접근하게하고, 거기;서 가져온 id를 부여해서 User를 생성할 수 있다.
DB의 자동 번호 매기기를 활용할 수도 있다. 다만 데이터 베이스에 객체를 저장할 때 ID가 부여되므로, 객초가 최초 생성될 때는 ID가 없는 상태다. 또한 세터도 열어둬야 한다. 이런 것들을 신경써야 한다.
10. 데이터의 무결성 유지하기
무결성이란 서로 모순이 없고 일관적이라는 것이다.
사용자명의 중복을 허용하지 않음에 중요한 문제가 있다.
어떤 사람이 새로 사용자 등록을 하려고 하는데, 그것을 처리 중에 다른 사용자가 사용자명 중복 체크를 시도하면 아직 인스턴스 저장이 끝나지 않았으므로 중복체크에서 걸리지 않는다.
유일 키 제약
사용자명이 중복되지 않게 데이터 무결성을 유지할 수 있는 방법으로 유일 키를 이용한 방법이 있다. 유일 키(unique key) 제약은 데이터베이스의 특정 칼럼값이 각각 유일한 값이 되게 보장하는 기능이다.
유일 키 제약에 중복 확인을 맡겼을 경우의 문제점
유일 키 제약 기능은 특정 데이터베이스의 기술이므로 특정 기술 기반에 의존하는 부분이 생기는 것도 문제다.
유일 키 제약은 규칙을 준수하는 주 수단이 아니라 안전망 역할로 활용해야 한다.
방법 2 - 트랜잭션
트랜잭션을 통해 데이터의 무결성을 확보할 수 있다. 동시에 같은 사용자명으로 사용자 등록을 시도하는 일이 벌어져도 한쪽만 등록되고 다른 한쪽은 등록에 실패할 것이다. 그러나 새로운 문제가 생긴다. UserApplicationService가 인라의 객체 SqlConnection에 대해 의존하게 됐다.
트랜잭션 범위를 사용하는 패턴
데이터 무결성을 확보하는 것 자체는 분명히 추상화 수준이 낮은 특정 기술 기반의 역할이다. 그러나 비즈니스 로직의 입장에서 생각하면 무결성을 지키는 수단이 무엇이냐는 그리 중요하지 않다. 데이터 무결성 자체가 특정 기술에 뿌리를 둘 만큼 추상화 수준이 낮은 개념이 아니다. 따라서 비즈니스 로직에서는 데이터 무결성을 확보하기 위한 구체적인 구현 코드보다는 "이 부분에서 데이터 무결성을 확보해야 한다"는 것을 명시적으로 보여주는 코드가 담겨야 한다.
AOP를 사용하는 패턴
AOP에서는 소스 코드를 수정하지 않고도 새로운 처리를 추가할 수 있다. @Transactional 애노테이션을 붙여주는 것이다. @Transactional 애노테이션은 트랜잭션 범위와 같은 기능을 제공한다. 메서드가 정상으로 종료되면 커밋을 실행하며 실행 도중 예외가 발생하면 롤백이 실행된다.
11. 애플리케이션 밑바닥부터 만들기
12. 애그리게이트란?
애그리게이트는 말하자면 변경의 단위다. 데이터를 변경하는 단위로 다뤄지는 객체의 모임을 애그리게이트라고 한다. 애그리게이트에는 루트 객체가 있고, 모든 조작은 이 루트 객체를 통해 이뤄 진다. 그러므로 애그리게이트 내부의 객체에 대한 조작에는 제약이 따르며 이로 인해 애그리겡트 내부의 불변 조건이 유지된다.
애그리게이트는 경계와 루트를 갖는다. 애그리게이트의 경계는 말 그대로 애그리게이트에 포함되는 대상을 결정하는 경계다. 그리고 루트는 애그리게이트에 포함되는 특정한 객체다.
외부에서 애그리게이트를 다루는 조작은 모두 루트를 거쳐야 한다. 애그리게이트에 포함되는 객체를 외부에 노출하지 않음으로써 불변 조건을 유지할 수 있다.
애그리게이트를 말로만 설명하자니 어려운 개념처럼 느껴지지만, 사실 우리는 애그리게이트를 이미 접한적이 있다. User와 Circle 같은 객체가 이미 애그리게이트의 정의를 만족한다.
애그리게이트의 기본 구조
애그리게이트는 서로 연관된 객체를 감싸는 경계를 통해 정의된다.
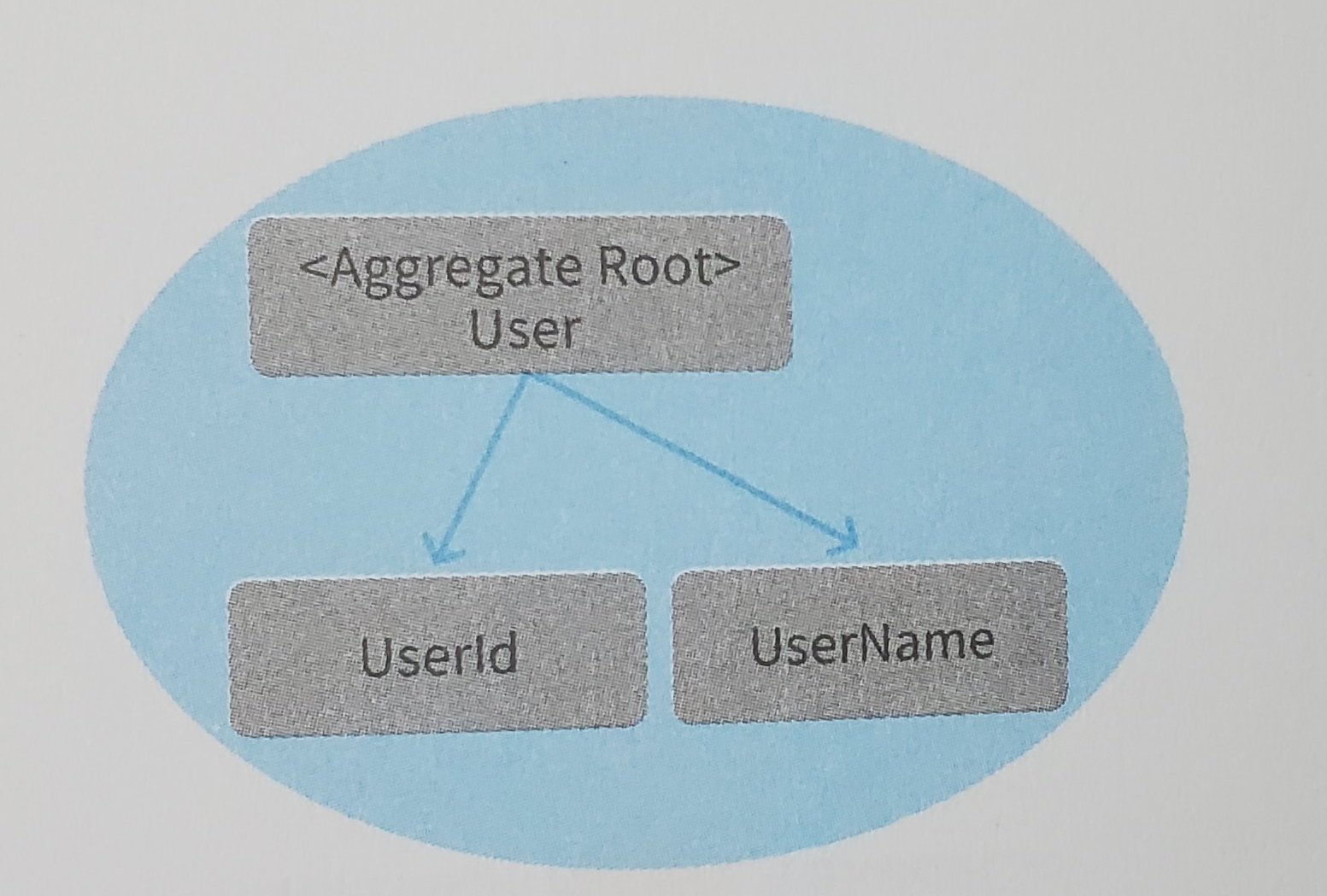
외부에서는 애그리게이트 내부에 있는 객체를 조작할 수 없다. 애그리게이트를 조작하는 직접적인 인터페이스가 되는 객체는 애그리게이트 루트(aggregate root)뿐이다. 따라서 사용자명 변경도 User 객체에 요청하는 형태를 취해야 한다.
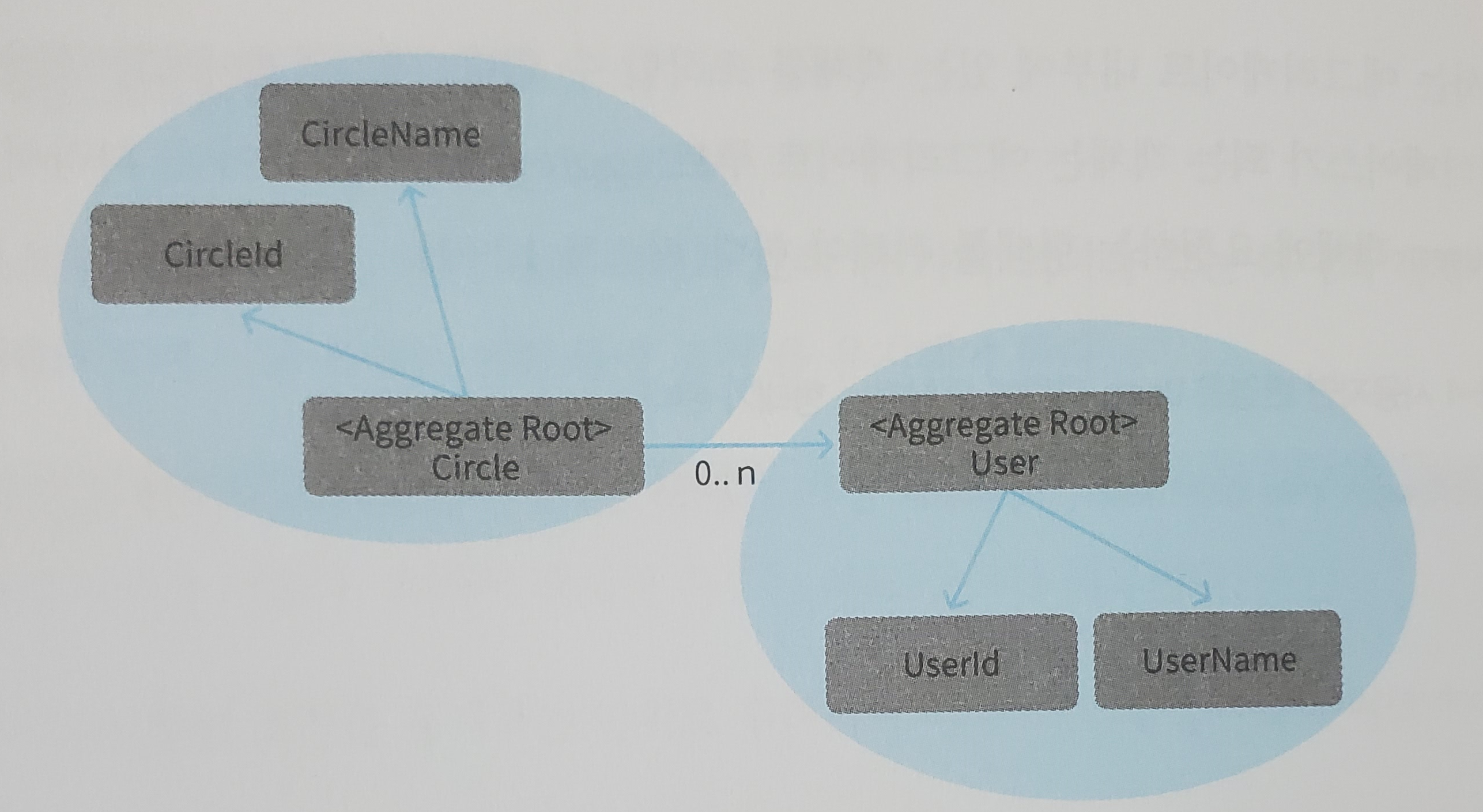
사용자 애그리게이트는 서클 애그리게이트에 포함되지 않으므로 사용자 애그리게이트의 정보를 수정하는 조작은 서클 애그리게이트를 통하지 않는다. 그러나 서클에 사용자를 구성원으로 추가하는 처리는 서클 애그리게이트가 담당한다.
circle.Members.Add(member);이 코드는 애그리게이트의 규칙을 위반하는 코드다. 서클 애그리게이트에 포함되는 Members에 대한 조작은 애그리게이트의 루트인 Circle 객체를 통해야 한다.
객체를 다루는 조작의 기본 원칙
객체 간의 어떤 질서 없이 메서드를 호출하면 불변 조건을 유지하기 어렵다. '데메테르의 법칙'은 객체 간의 메서드 호출에 질서를 부여하기 위한 가이드라인이다.
데메테르 법칙은 어떤 컨텍스트에서 다음 객체의 메서드만을 호출할 수 있게 제한한다.
- 객체 자신
- 인자로 전달받은 객체
- 인스턴스 변수
- 해당 컨텍스트에서 직접 생성한 객체
circle.Members.Add(member);Circle 객체의 인스턴스 변수인 Members를 직접 조작하기 때문에 데메테르의 법칙에 어긋난다.
데메테르의 법칙을 잘 준수하지 않으면 로직이 여기저기 흩어지게 된다.
게터를 만들지 말아야 할 이유가 여기에 있다. 게터를 통해 필드를 공개하면 객체에 구현돼야 할 규칙이 다른 곳에서 중복 구현되는 일을 완전히 막을 수 없다.
애그리게이트의 경계를 어떻게 정할 것인가
애그리게이트의 경계를 정하는 원칙 중 가장 흔히 쓰이는 것은 "변경의 단위"다.
서클을 변경할 때는 서클 애그리게이트 내부로 변경이 제한되어야 하고, 사용자를 변경할 때도 사용자 애그리게이션 내부의 정보만 변경돼야 한다.
애그리게이트에 대한 변경은 해당 애그리게이트 자신에게만 맡기고, 퍼시스턴시 요청도 애그리게이트 단위로 해야 한다.
식별자를 이용한 컴포지션
애그리게이트의 경계를 넘지 않는다는 불문율을 만드는 것보다 더 나은 방법은 없을까? 바로 인스턴스를 갖지 않는 것이다. 인스턴스를 실제로 갖지는 않지만, 그런 것처럼 보이게 하는 것 바로 식별자다.
서클 애그리게이트가 사용자 애그리게이트를 직접 포함하는 대신, 사용자 애그리게이트의 식별자를 포함하게 코드를 수정할 수 있다.
애그리게이트의 크기와 조작 단위
트랜잭션은 데이터에 로크를 건다. 애그리게이트의 크기가 크면 클 수록 이 로크의 적용 범위도 비례해 커진다.
애그리게이트의 크기가 지나치게 커지면 그만큼 애그리게이트르르대상으로 하는 처리가 실패할 가능성도 높다. 따라서 애그리게이트의 크기는 가능한 작게 유지하는 것이 좋다. 또, 한 트랜잭션에서 여러 애그리게이트를 다루는 것도 가능한 피해야 한다. 여러 애그리게이트를 걸친 트랜잭션은 범위가 큰 애그리게이트와 마찬가지로 광범위한 데이터에 로크를 걸 가능성인 높다.
13. 복잡한 조건을 나타내기 위한 "명세"
객체를 평가하는 절차가 단순하다면 해당 객체의 메서드로 정의하면 되겠지만, 복잡한 평가 절차가 필요할 수도 있다. 결국 이러한 객체 평가 절차는 애플리케이션 서비스에 구현되기 마련인데, 객체에 대한 평가는 도메인 규칙 중에서도 중요도가 높은 것으로 서비스에 구현하기에 걸맞은 내용이 아니다.
명세는 어떤 객체가 그 객체의 평가 기준을 만족하는지 판정하기 위한 객체다.
서클의 최대 인원을 확인하는 것은 도메인의 규칙을 준수하기 위한 것이다. 지금까지 설명했듯이, 서비스는 도메인 규칙에 근거한 로직을 포함해서는 안된다. 이를 그대로 허용하면 도메인 객체가 제 역할을 빼앗기고 서비스 코드 이곳저곳에 도메인의 주요 규칙이 중복해서 작성된다.
도메인 규칙은 도메인 객체에 정의돼야 한다. 최대 인원 확인을 Circle 클래스의 isFull 메서드에 정의할 방법을 찾아보자. 이렇게 하려고 보니 이번에는 Cricle 클래스가 사용자 정보를 식별자만 가지고 있다는 점이 문제가 된다. 식별자 만으로 사용자 정보를 얻으려면 어떻게든 사용자 리포지토리를 전달받아야 한다.

이런 방법은 좋지 않다. 리포지토리는 도메인 설계에 포함된다는 점에서는 도메인 객체라고 할 수 있지만, 도메인 개념에서 유래한 객체는 아니다. Circle 클래스 사용자 리포지토리를 갖게 되면 도메인 모델을 나타내는데 전념하지 못하게 된다.
엔티티나 값 객체가 모델을 나타내는 데 전념할 수 있으려면 리포지토리를 다루는 것은 가능한 한 피해야 한다.
이 문제의 해결책 - 명세
명세라는 객체를 이용하면 엔티티나 값 객체가 리포지토리를 다루지 않으면서도 이 문제를 해결할 수 있다.

명세는 객체가 조건을 만족하는지 확인하는 역할만을 수행한다. 평가 대상 객체가 복잡한 평가 절차 코드에 파묻히는 일 없이 원래의 의도를 잘 드러낼 수 있다.

복잡한 객체 평가 코드를 캡슐화해서 객체의 의도를 잘 드러낼 수 있게 됐다.
리포지토리를 되도록 사용하지 않기
명세도 엄연한 도메인 객체이므로 내부에서 일어나는 입출력(리포지토리 사용)을 최대한 억제해야 한다는 의견도 있다. 이런 경우 일급 컬렉션을 이용하는 방법을 생각해 볼 수 있다. 일급 컬렉션(first-class collection)은 List등의 제네릭 컬렉션 객체 대신 특화된 컬렉션 객체를 이용하는 패턴이다.
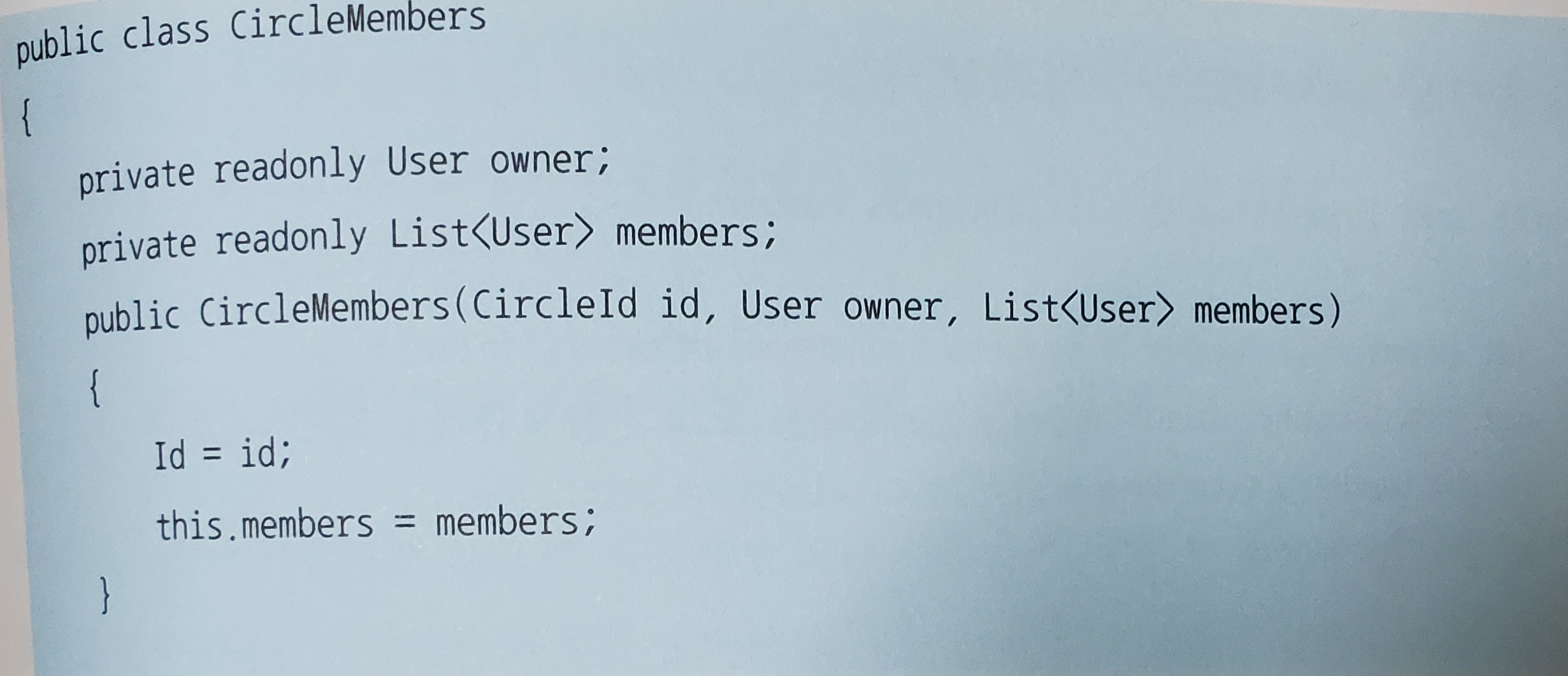
CircleMembers는 일반적으로 사용되는 List등과 달리 서클의 식별자와 이에 소속된 사용자의 정보를 모두 저장한다. 그리고 독자적인 계산 처리를 메서드로 정의할 수 있다.
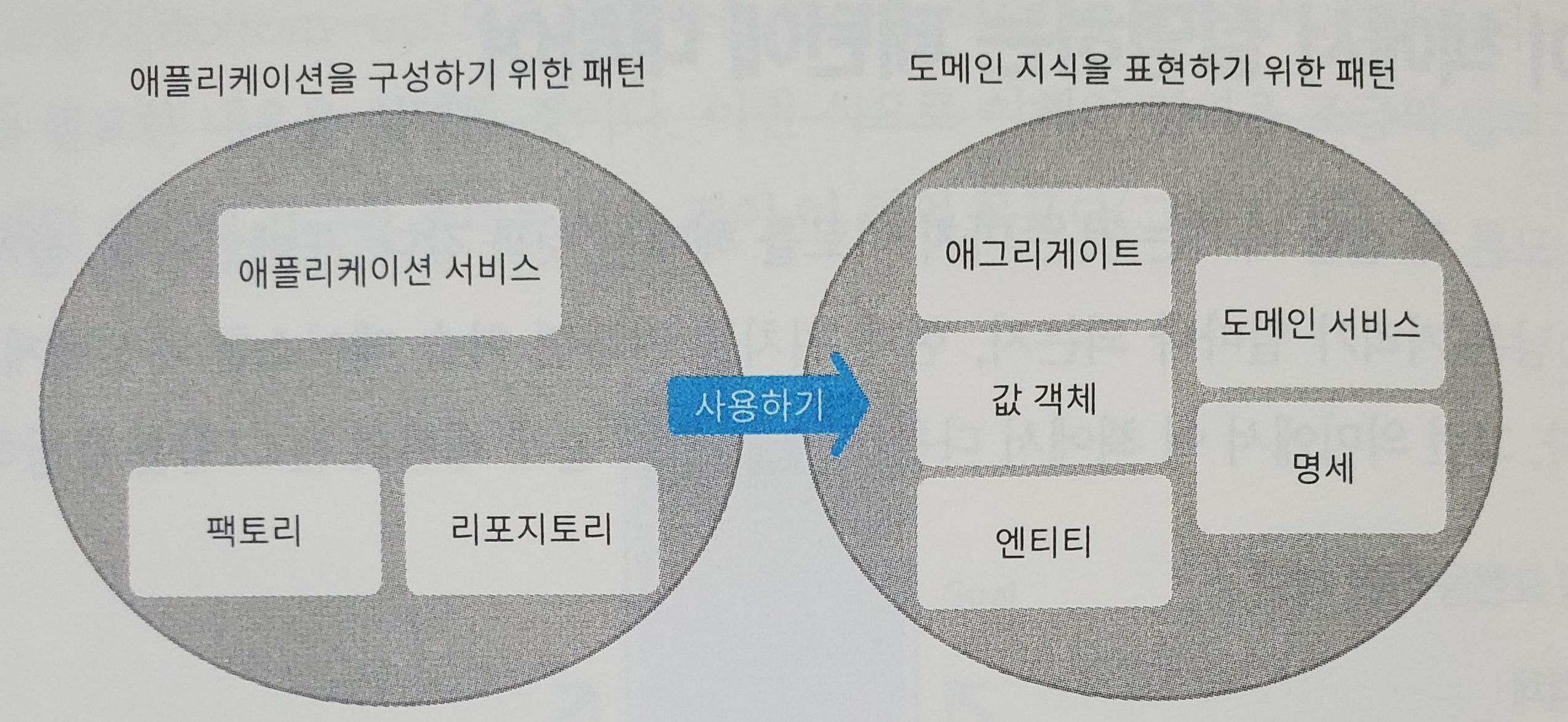
아키텍처
아키텍처는 지식을 표현한 코드를 적재적소에 배치하는 원칙이다. 아키텍처를 통해 도메인 규칙이 제자리를 벗어나는 것을 방지함과 동시에 한 곳에 모이게 할 수 있다.
아키텍처는 간단히 말해 코드를 구성하는 원칙이다. 어떤 내용을 구현한 코드가 어디에 배치돼야 하는지에 대한 답을 명확히 제시하며 로직이 무질서하게 흩어지는 것을 막는다.
도메인 주도 설계가 아키텍처에게서 원하는 것은 도메인 객체가 서로 얽힌 레이어를 분리해 소프트웨어 구현에 필요한 사정으로부터 도메인 객체를 지켜내는 것이다. 이것이 가능하다면 어떤 아키텍처를 사용해도 무방하다.
