
피벗이라고 합시다 우린 그걸 피벗이라고 부르기로 했어요
여기 여러 학생들의 여러 과목 성적에 대한 데이터가 있다.
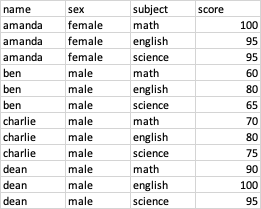
score라는 하나의 컬럼에 모든 과목의 점수가 일렬로 기록돼 있고 나는 이걸 아래 이미지처럼 '점수' 컬럼을 '수학 점수', '영어 점수', '과학 점수' 컬럼으로 나누고(열을 전개하고) 싶다.
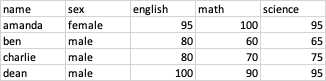
이것을 피버팅(피벗)이라고 한다.
아래는 이 어휘가 생각이 안나서 일하다 말고 했던 삽질

pd.DataFrame.pivot()
데이터프레임에서 피버팅을 하는 방법은 매우 간단하다.
애초에 pivot() 메소드가 존재한다.
data에서 subject 컬럼의 데이터인 math, english, science 등을 각각의 컬럼으로 전개하고 해당 과목의 점수인 score 컬럼의 데이터는 새로 전개한 열의 데이터로 따라가게 할 것이다.
직관적으로 columns={쪼갤 기준의 컬럼}, values={쪼갤 값의 컬럼} 정도로 생각해보자.
>>> data = pd.read_csv("./grades.csv")
>>> pivoted_data = data.pivot(index=['name', 'sex'], columns='subject', values='score')
>>> pivoted_data
subject english math science
name sex
amanda female 95 100 95
ben male 80 60 65
charlie male 80 70 75
dean male 100 90 95피버팅은 잘 됐다.
피버팅 자체는 이게 끝이다.
끗
원하던 모양이 아닌데요
물론 뭔가 잘못됐다.
피버팅은 잘 됐지만 내가 원하던 바는 아니다.
>>> pivoted_data.columns
Index(['english', 'math', 'science'], dtype='object', name='subject')아무래도 뭔가 이상하다.
이것은 구글링해서 찾은 방법인데 대충 리-인덱싱을 해서 해결한 것 같다.
여기엔 솔루션만을 기록하겠다.
>>> pivoted_data.columns = pivoted_data.columns.values
>>> pivoted_data
english math science
name sex
amanda female 95 100 95
ben male 80 60 65
charlie male 80 70 75
dean male 100 90 95
>>> pivoted_data.columns
Index(['english', 'math', 'science'], dtype='object')
>>> pivoted_data.reset_index(inplace=True)
>>> pivoted_data
name sex english math science
0 amanda female 95 100 95
1 ben male 80 60 65
2 charlie male 80 70 75
3 dean male 100 90 95
>>> pivoted_data.columns
Index(['name', 'sex', 'english', 'math', 'science'], dtype='object')음 이제서야 내가 원하던 폼의 DataFrame이 만들어졌다.
나의 최종적인 코드는 아래와 같다.
def pivot_data():
data = pd.read_csv("./grades.csv")
pivoted_data = data.pivot(index=['name', 'sex'], columns='subject', values='score')
pivoted_data.columns = pivoted_data.columns.values
pivoted_data.reset_index(inplace=True)니체가 말했지
"Google knows everything."

An optimist who becomes pessimistic while working