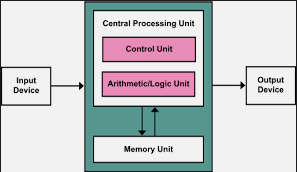
Pipelining
명령어 파이프라인은 명령어를 읽어 순차적으로 실행하는 프로세서에 적용되는 기술로, 한 번에 하나의 명령어만 실행하는 것이 아니라 하나의 명령어가 실행되는 도중에 다른 명령어를 실행하는 식으로 동시에 여러개의 명령어를 실행하는 기법이다
현대의 프로세서는 single-cycle을 사용하지 않는데, 왜냐하면 single-cycle에서는 clock period가 가장 긴 delay(load)에 맞추어야 하기 때문에, 실행시간이 짧은 연산도 이 시간동안 기다려야 하기 때문에 시간이 낭비된다. 이를 해결하기 위해 현대의 프로세서는 병렬처리를 통해 동시에 여러개의 작업을 수행하는 방식으로 성능을 개선하였다.
파이프라이닝을 적용하면 각각의 작업에 소요되는 시간은 줄일 수 없지만 여러 작업을 수행할 때 짧은 시간동안 처리되는 작업의 수를 높일 수 있어 throughput이 향상된다.
MIPS Pipelining
MIPS에서 명령어의 실행은 5가지 스테이지로 나눌 수 있다.
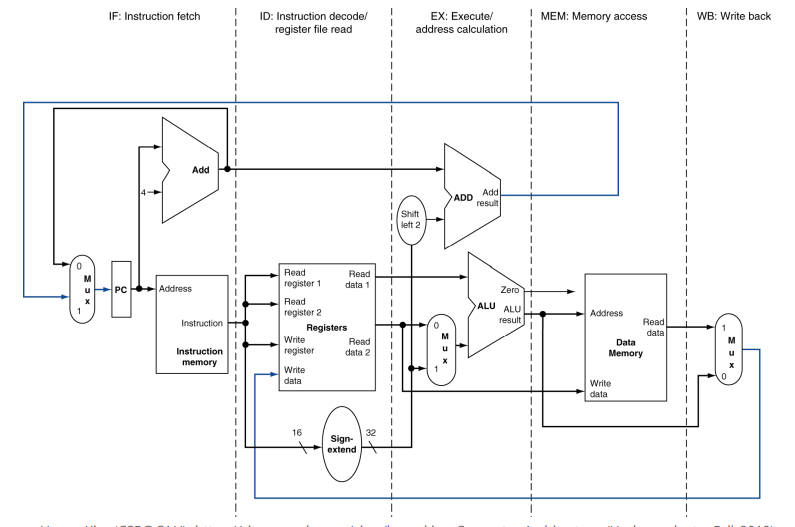
- IF(Instruction Fetching) : 메모리로부터 명령을 불러옴
- ID(Instruction Decoding) : 명령을 해석하고 레지스터를 읽음
- EX(Executing) : 연산 수행 및 주소 계산
- MEM(Memory) : 메모리에 접근
- WB(Write Back) : 레지스터에 결과를 저장
Pipelining을 적용하였을 때 프로그램이 동작하는 방식은 아래 그림과 같다
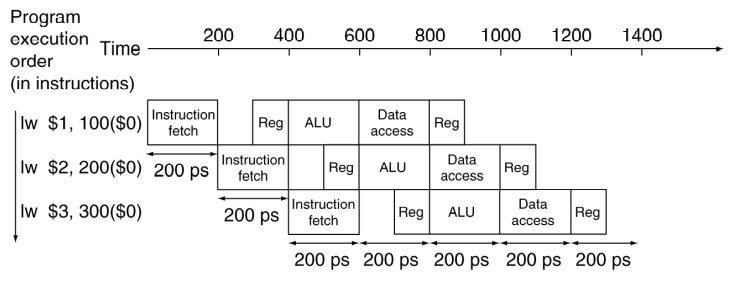
이 때 전체 작업에 소요되는 시간은
가장 긴 stage의 소요시간 * (명령의 수 + 스테이지의 수 - 1)
이지만, pipeline을 적용하지 않았을 때 소요되는 시간은
가장 긴 instruction의 소요시간 * 명령의 수
이다. 현대에서 프로그램이 돌아가는데 필요한 instruction의 수는 셀 수 없이 많기 때문에 결과적으로 pipeline을 적용하면 instruction time / stage time만큼의 성능향상이 일어나게 된다.
MIPS의 구조는 파이프라인을 통한 이점을 극대화 할 수 있도록 설계되었는데, 세부적인 내용은 다음과 같다.
- 모든 명령의 길이가 32bit로 같다 -> IF stage time 감소
- 소수의 정형화된 명령어 형식 -> ID stage time 감소
- 메모리 연산은 load와 store밖에 없다 -> stage의 수 감소
- 데이터는 메모리에 순차적으로 저장되어있다 -> MEM stage time 감소
Pipeline Hazards
파이프라이닝 과정에서 몇가지 이유로 다음 스테이지로 진행이 불가능한 경우가 발생하는데, 이를 Pipeline Hazard라고 한다.
- Structural Hazard : 필요한 리소스가 사용중인 경우
- Data Hazard : 이전 명령의 결과로 나오는 데이터를 기다려야 하는 경우
- Control Hazard : 이전 명령의 결과를 통해 control을 결정해야 하는 경우
Structural Hazard
다른 명령에서 사용중인 리소스가 필요한 경우 발생
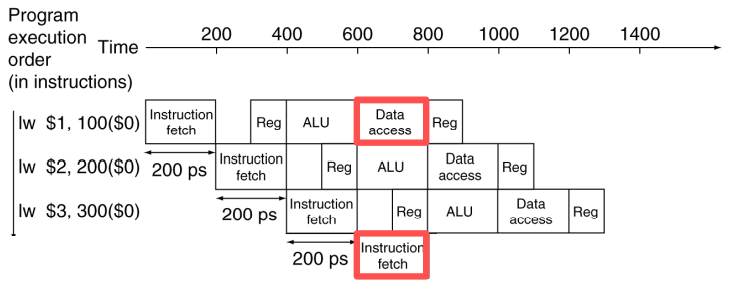
MIPS에서 instruction과 data는 같은 메모리에 저장되어있기 때문에 IF와 MEM 스테이지는 동시에 같은 리소스에 접근하려는 요청을 보낼 수 있는데, 이 때 pipline bubble이 발생할 수 있다.
- pipeline bubble : 클락사이클이 도는 동안 작업을 진행하지 못하는 상황
이를 해결하기 위해서는 Instruction memory와 Data memory를 분리하여 설계해야 한다.
Data Hazard
명령이 이전 명령의 결과로 나오는 데이터에 의존하는 경우
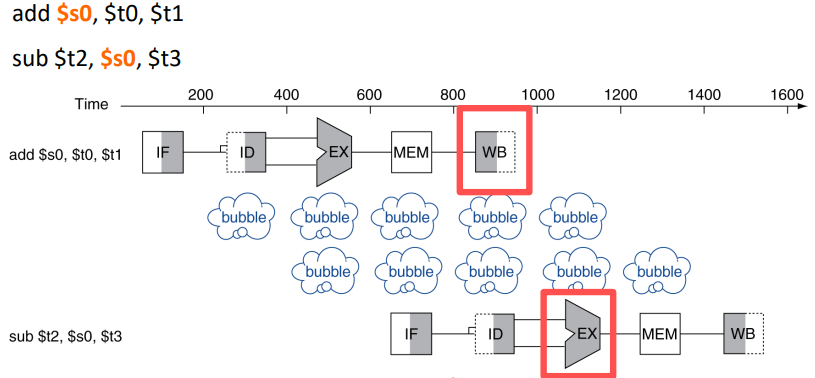
위의 그림에서 sub연산은 $s0에 저장된 값을 일어와야 하는데 이는 add연산의 WB stage이후에 가능하므로 그 사이에 bubble이 생긴다.
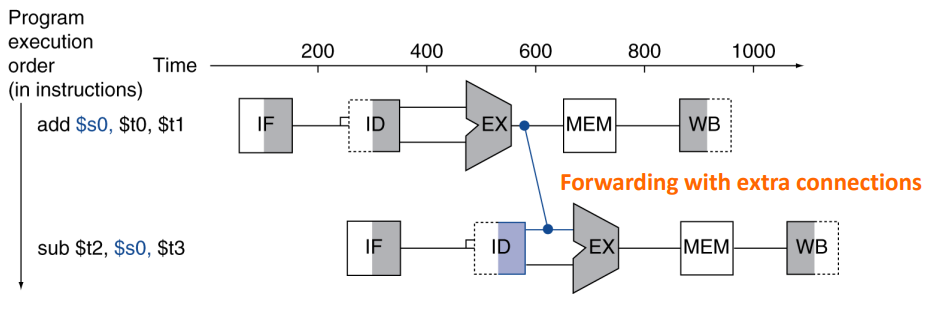
이를 해결하기 위해서는 Forwarding이 필요하다
- Forwarding(Bypassing) : 추가적인 연결을 만들어 데이터가 레지스터에 저장되는것을 기다리지 않고 필요한 리소스에 값을 넘겨주는 방법
Load-use Data Hazard
하지만 특정 상황에서는 Forwarding을 해도 bubble이 발생하는 경우가 있다
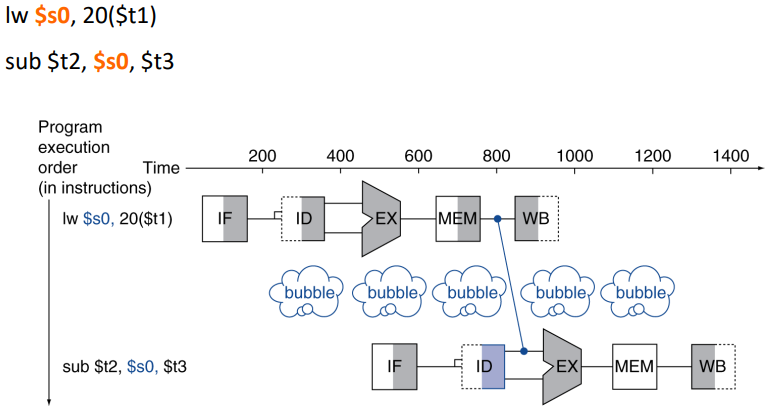
이 경우 메모리로부터 $s0에 데이터를 불러온 다음 sub연산을 진행해야 하는데, 이는 MEM stage이후에 Forwarding이 가능하므로 bubble이 발생하게 된다.
이 문제는 Code Scheduling을 통해 해결이 가능하다
- Code Scheduling : 컴파일러에 의해 수행되는 작업으로, 명령의 순서를 바꾸어 Load-use data hazard를 방지하는 기법
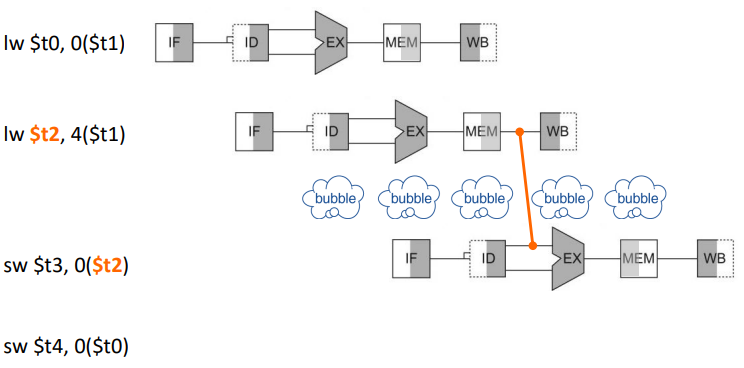
code scheduling 이전에는 $t2에 대한 lw연산 이후에 바로 sw연산이 이어서 나오기 때문에 forwarding을 해도 bubble이 발생했다
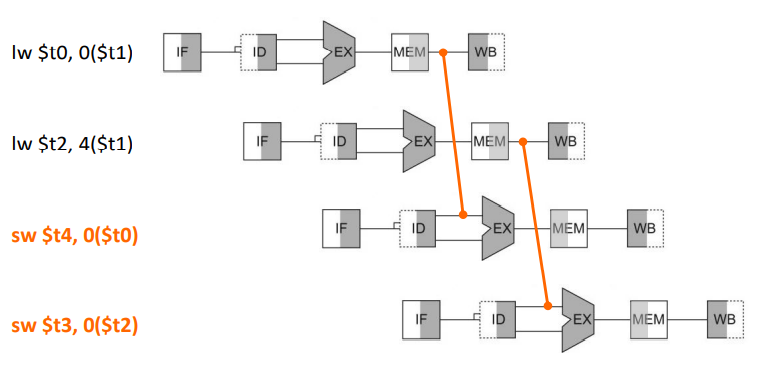
하지만 code scheduling을 적용하여 두 sw연산의 순서를 바꾼 결과 bubble이 발생하지 않고 진행되는 것을 볼 수 있다.
Control Hazard
Branch instruction에서 이전 명령의 결과가 나와야 다음 명령의 IF stage를 진행할 수 있는 경우
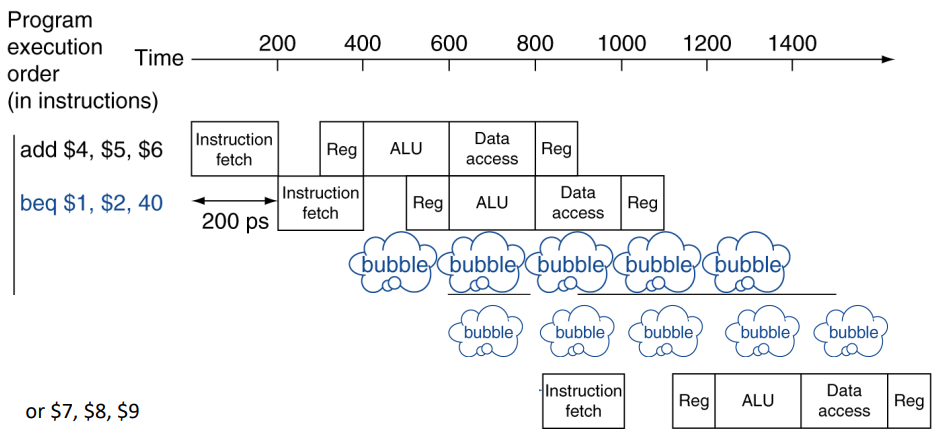
위 상황에서 beq명령의 결과가 나와야 다음 명령을 불러올 수 있기 때문에 bubble이 발생한다.
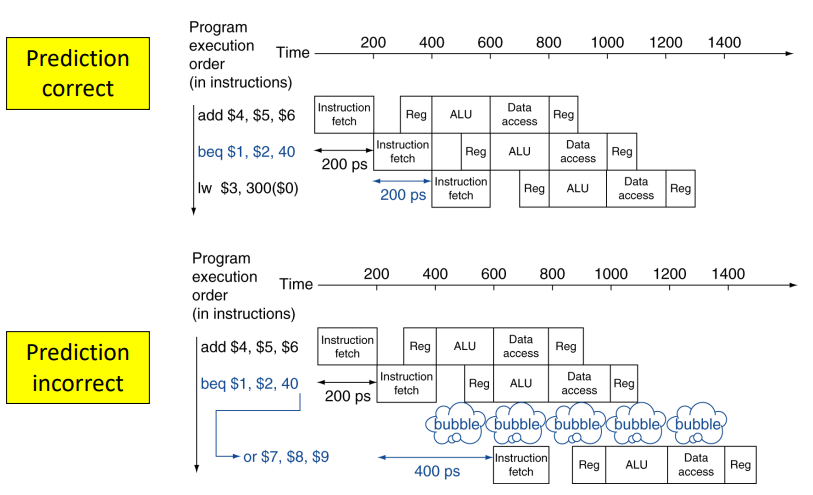
이를 해결하기 위해 Branch Prediction기법을 활용한다.
- Branch Prediction : ID stage에 하드웨어를 추가하여 비교연산을 수행하고, branch의 결과를 예측한다. 이 방법을 통해 예측의 결과가 맞으면 bubble이 발생하지 않고, 예측이 틀릴 경우에만 bubble이 발생하게 된다.
Pipelined Datapath
Single-cycle datapath에 pipeline을 적용하기 위해서는 각 스테이지 사이에 레지스터를 두어 이전 스테이지의 상태를 저장하는 과정이 필요하다
각 스테이지에서는 작업을 마친 뒤 레지스터에 값을 저장하고 다음 스테이지에서 이 값을 사용하는 방식으로 작업을 이어나간다. 이러한 구조를 통해 각 스테이지는 bubble이 발생하지 않는 한 쉬지않고 작업을 수행할 수 있다.
또한, instruction을 decoding하여 얻은 control정보는 control정보가 사용되는 스테이지의 레지스터까지 순차적으로 전달되어 작업을 수행한다.

Data Hazard
Pipelined Datapath에서 Data Hazard를 처리하기 위해서는 hazard가 발생하였을 때 이를 감지하고 forwading을 수행하여야 하는데, 구체적인 과정은 다음과 같다.
- 파이프라인을 따라 레지스터 번호를 넘겨준다(Rd, Rs, Rt : destination, first source, second source)
- Data Hazard 조건을 체크한다
- EX/MEM.RegisterRd == ID/EX.RegisterRs, EX/MEM.RegisterRd == ID/EX.RegisterRt
- MEM/WB.RegisterRd == ID/EX.RegisterRs, MEM/WB.RegisterRd == ID/EX.RegisterRt
- Data Hazard가 발생하면 Forwarding을 통해 데이터를 넘겨준다
- RegWrite가 1인 경우에만 forward(레지스터에 저장하지 않는 경우 data hazard가 발생하지 않음)
Data Hazard는 발생하는 스테이지에 따라 EX Data Hazard와 MEM Data Hazard로 나눌 수 있는데, 두 스테이지에서 동시에 Hazard가 발생하는 경우 Double Data Hazards라고 한다.
Double Data Hazard는 가장 최근의 값(EX/MEM 레지스터에 저장된 값)을 사용함으로써 해결할 수 있다.
Load-use Data Hazards
Forwarding을 활용해도 특정 상황에서는 bubble을 피할 수 없다. 주로 load-use hazard가 발생할 때 bubble이 발생하는데, Pipelined Datapath에서 load-use hazard를 감지하여 bubble을 발생시키는 과정은 다음과 같다
- Load-use Data Hazard 조건을 확인한다
- ID/EX.MemRead == 1 && (ID/EX.RegisterRt == IF/ID.RegisterRs || ID/EX.RegisterRt == IF/ID.RegisterRt)
- hazard가 감지되었다면 nop를 삽입하여 bubble을 발생시킨다
- PC와 IF/ID의 변경을 막기 위해 ID/EX의 컨트롤 시그널을 0으로 세팅함
또한 Load-use data hazard를 방지하기 위해서는 Code Scheduling을 통해 명령의 순서를 재구성해야 하는데, 이때 명령의 순서를 재구성하여도 원래 버전과 결과가 달라지면 안된다.
Control Hazard
Control Hazard는 Branch Prediction을 통해 방지할 수 있는데, 구체적으로 두 가지 방법이 있다.
- Static Branch Prediction : Branch에 걸리지 않을 것을 예측하여 분기문 다음에 바로 다음 명령을 실행
- 예측이 맞으면 bubble이 발생하지 않지만 예측이 틀리면 3번의 bubble이 발생
- bubble의 발생을 줄이기 위해 ID stage에서 비교연산을 진행하여 branch의 결과를 앞당기면 예측이 틀릴 경우에 1번의 bubble이 발생한다.
- Dynamic Branch Prediction : Branch Prediction Table에 이전 결과를 저장하여 사용
- 2bit predictor를 통해 분기문의 결과를 예측하고 분기의 결과로 나온 명령의 주소를 branch target buffer에 캐싱하여 빠르게 접근
다만, Branch 안에서 Data Hazard가 발생 할 수도 있는데 그 경우는 Code Scheduling을 통해 해결한다.
Code Scheduling
Load-use Data Hazard 혹은 Branch문 안에서 Data Hazard가 발생한 경우 Code Scheduling을 통해 명령의 순서를 재구성하여 bubble을 방지해야하는데, Code Scheduling이 작동하는 기본적인 순서는 다음과 같다.
- Load-use Hazard가 있는지 검사 : load의 destination레지스터가 다음 명령의 source레지스터로 사용되는 경우
- hazard가 있다면 순서를 바꿀 수 있는 명령이 있는지 검사 : 코드의 재구성을 통해 프로그램의 결과가 바뀌면 안되기 때문에 instruction의 dependencies를 고려해야 함
- Instruction Depedencies : 명령어 사이에 순서가 지켜져야 하는 의존관계
- Read after Write
- Write after Read
- Write after Write
Exceptions
Exception이란 프로세서에서 발생한 예상치 못한 이벤트로 별도의 처리가 필요하다.
참고로 Exception과 Inturrupt 모두 프로세서가 예상하지 못한 이벤트라는 점에서 비슷하지만 이벤트가 발생하는 위치에 따라 구분된다.
- Exception : 프로세서 내부에서 발생
- Inturrupt : 외부 I/O컨트롤러로부터 발생
프로세서에서 Exception이 발생하면 아래의 순서에 따라 예외를 처리한다
- EPC(Exception Program Counter)에 예외를 일으킨 명령의 주소를 저장한다
- Cause register에 예외의 원인을 저장한다
- Exception handler(0x80000180)로 이동한다
혹은 2번과 3번을 합쳐 다음과 같이 동작할 수도 있다.
- 예외를 일으킨 원인에 맞는 Exception handler로 이동한다
- 상황에 맞는 작업을 수행한다
- 복구가 가능하면 복구한 뒤 EPC에 저장된 주소를 통해 프로그램으로 복귀
- 복구가 불가능하면 프로그램을 멈추고 error report 제출
Pipelined Datapath에서 예외처리를 하기 위해서 flush를 제어하는 control signal과, EPC 및 Cause register를 추가한다
Hazard와 Forwarding, Exception을 처리하는 최종적인 Pipelined Datapath의 모습은 아래 그림과 같다.

