
Deep Signer 프로젝트를 진행하면서, 수어를 인식하는 모델에 대해서 먼저 개발하게 되었다.
실시간 Cam영상을 기반으로 수어를 인식하는 것이었다. 여러 방법이 있겠지만, 2D CNN-LSTM모델을 적용하기에는 리소스 문제로, 최대한 가볍게 구현하기위해서 Mediapipe를 이용해서 Pose Keypoint를 추출해서, 이를 통해, RNN계열의 모델을 시도해 볼 예정이다.
📝 Process
- 데이터셋 수집
- 영상 길이 통합(Padding)
- MediaPipe Pose Keypoint 추출
- 데이터 분할 및 학습
💾 Dataset
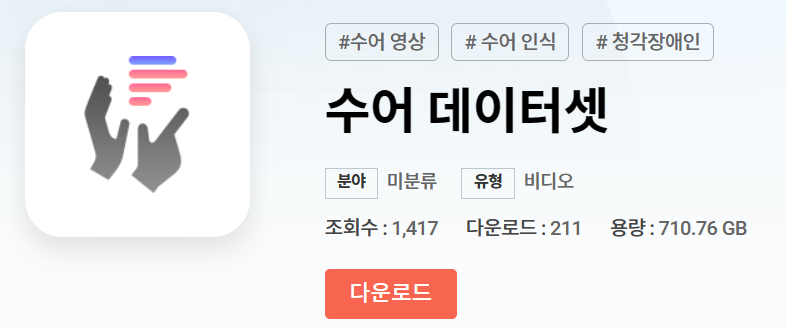
Dataset은 AIhub 플랫폼에서, 수어 영상과 그에 따른 클래스로 단어와 문장이 섞여, 구성되어있는 데이터셋을 사용할 예정이다.
🎬 영상 길이 통합(Padding)
모든 영상이 각각의 의미에 따라 길이가 천차만별이다. 시계열 데이터 학습 모델에 이를 사용하기위해서는, 모든 영상의 길이를 하나의 기준으로 맞춰줄 필요가 있다. 이를 Padding이라고 한다. 방법은 여러가지가 있다.
Idea 1. 모든 영상길이의 평균을 구함, 평균을 기준으로 모든 영상의 길이를 조정.
Idea 2. 가장 긴 영상을 기준으로 Padding을 진행하되, 부족한 영상 프레임은 영상의 가장 마지막 프레임으로 Padding을 진행한다.
Idea 3. 가장 긴 영상을 기준으로 Padding을 진행하되, 부족한 영상 프레임을 Zero-Padding을 통해 padding을 진행한다.
영상을 padding할 때, 보통은, Idea 3과 같이 zero-padding을 주로 사용하는 것 같다. 하지만, zero-padding보다 마지막 프레임으로 패딩하는것이 인식에 대한 측면에서 조금 더 좋은 퍼포먼스를 보일수 있지 않을까??
🦴 MediaPipe Pose Keypoint 추출
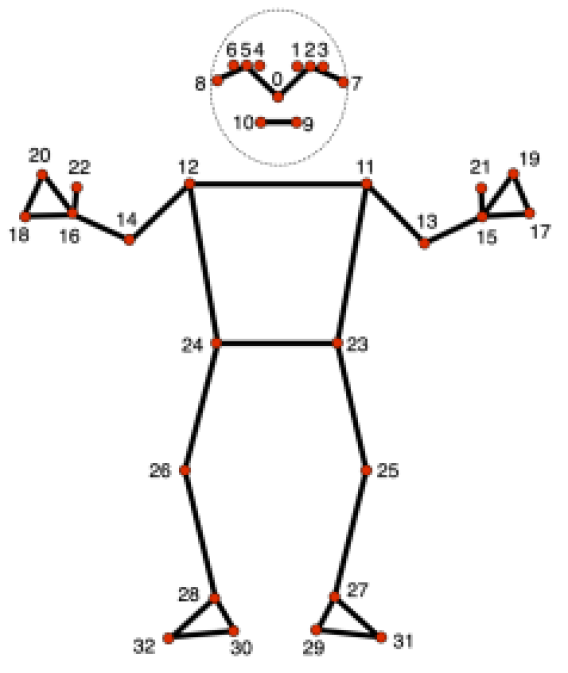
MediaPipe의 Pose Skeleton Detection 모델에는 총 32개의 point를 인식하게 된다. 이를 서로 연결해서, 우리가 아는 인간의 뼈대 형태를 구성하고있다.
X, Y, Z를 저장할 것이며, 32개의 포인트를 인식하기에, (영상길이, 33, 3)의 형태를 가지게 된다. 아래는 간단히 x,y,z를 npy파일로 저장하는 코드이다.
import os
import cv2
import threading
import numpy as np
import mediapipe as mp
from tqdm import tqdm
path = input("Source Path :") # define paths
output_path = input("Dest Path :")
def extract_keypoints(filename, dest_path):
mp_pose = mp.solutions.pose # define mediapipe pose model
cap = cv2.VideoCapture(filename)
with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
pose_keypoints_list = []
while True:
opened, image = cap.read()
if not opened:
break
pose_results = pose.process(image)
if pose_results.pose_landmarks:
pose_landmarks = pose_results.pose_landmarks
pose_keypoints = []
for landmark in pose_landmarks.landmark:
pose_keypoints.append([landmark.x, landmark.y, landmark.z])
pose_keypoints_list.append(pose_keypoints)
pose_keypoints_array = np.array(pose_keypoints_list)
np.save(f'{dest_path}\{os.path.splitext(os.path.basename(filename))[0]}_p.npy', pose_keypoints_array)
cap.release()
def working_threads():
threads = []
for filename in tqdm(os.listdir(path), colour='green'):
thread = threading.Thread(target=extract_keypoints, args=(filename, output_path))
threads.append(thread)
thread.start()
print("file listup finish. Threading Start...")
for thread in tqdm(threads, colour='blue'):
thread.join()
working_threads()이를 통해, 영상 약 40000개를 처리한다. ~~ 40000개를 빠르게 처리하기위해 Threading 모듈을 사용해서 멀티코어로 이 작업을 가속화할 수 있다. 멀티코어 활용은 나중에 따로 포스팅으로 다뤄보겠다.
✔️ Trouble Shooting
Trouble 1. 3000개의 파일을 전처리하는 과정에서 2719개로, 일부가 처리되지않는 문제가 생김.
- 여러 Thread가 동시에 작업을 하면서, 동일한 변수에 여러 Thread가 접근하면서 Thread간의 충돌이 의심.
- 리소스 부족? -> 리소스가 부족이라면, 일반적으로 작업이 멈추고 응답이 없음, 그렇지않음.
Shooting 1. 여러 thread를 생성하여, 작업하던 working_threads 함수의 thread를 ThreadPoolExecutor를 이용하여 문제 해결.
def working_threads():
executor = ThreadPoolExecutor(max_workers=8)
futures = []
for filename in tqdm(os.listdir(path), colour='green'):
full_filename = os.path.join(path, filename)
future = executor.submit(extract_keypoints, full_filename, output_path)
futures.append(future)
print("file listup finish.. threads start..")
for future in tqdm(futures, colour='blue'):
future.result()
executor.shutdown()
working_threads()여러 thread가 동시에 변수에 접근하여 thread가 충돌하는것으로 예상되어, 여러 thread가 동시에 충돌나지않도록, ThreadPoolExecutor를 사용하여, 이를 해결할 수 있었다.
📖 학습
- 학습은 다음 포스팅에서 자세하게 다뤄보겠다.
References
수어 동작 인식모델 만들기 - jihyeon
손 제스처 인식 딥러닝 인공지능 학습시키기 - 빵형의 개발도상국

정보 감사합니다.