아래의 논문을 읽고 학습한 내용을 바탕으로 정리합니다.
논문 링크 : simswap
개요
본 논문에서는 고화질의 Face swap 이미지를 만들기 위한 프레임워크를 제안합니다.
ID Injection Module을 이용해 임의의 얼굴에 대해서도 face swapping task가 가능하도록 했고,
Weak Feature Matching Loss를 이용해 얼굴의 속성을 잘 보존할 수 있도록 했습니다.
크게 위의 두가지 기능을 이용해서 성능을 향상시켰습니다.
Terms
본격적으로 논문을 소개하기 전에,
논문에서 쓰이는 주요 용어에 대해 정리하도록 하겠습니다.
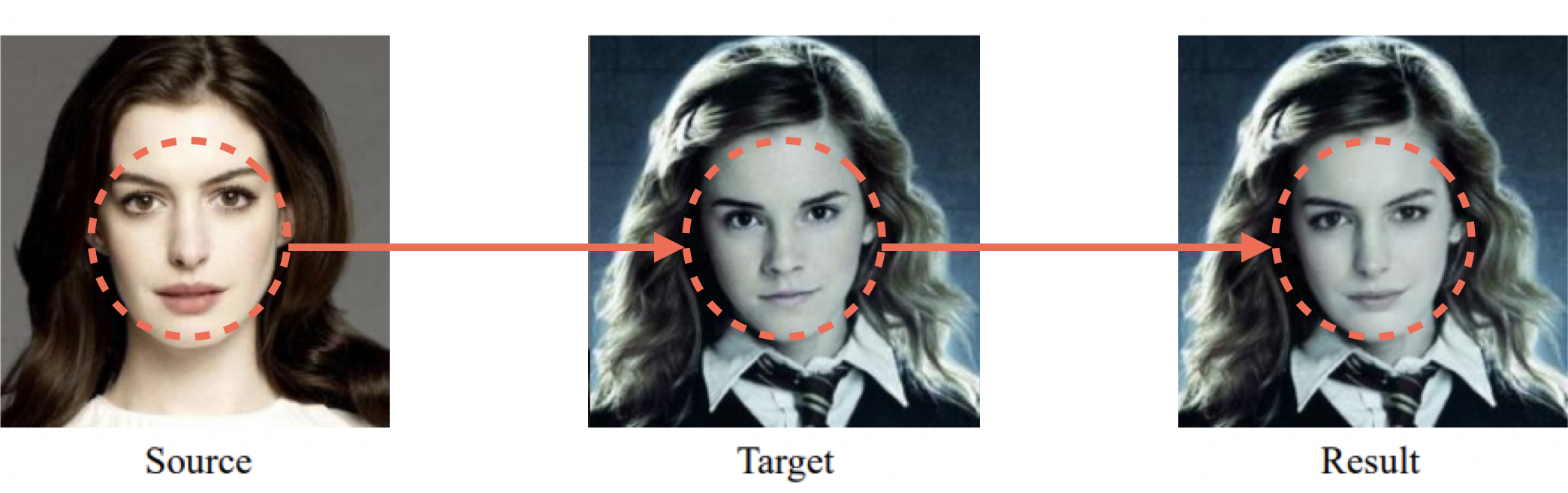
- Face Swap
"Target" 이미지에 "Source"의 얼굴을 입히는 기술 - Identity
얼굴을 알아보고 구분할 수 있는 고유의 생김새 - Attribute
표정, 포즈, 조명, 눈동자방향 등의 속성
Face swap model
Face swap 모델의 목표는 target face의 attribute들을 잘 보존하면서,
동시에 임의의 source face의 identity를 임의의 target face에 입히는 것입니다.
따라서 잘 동작하는 face swap 모델이라면,
- 임의의 face에 대해서 swap이 가능하고,
- result 이미지와 source 이미지의 생김새(identity)가 유사하고,
- result 이미지와 target 이미지의 속성(attribute)이 일관되게 나타나야 합니다.
Two types of face swapping method
1. Source oriented method
- Image level의 source face에서 동작
- Target face에서 source face로 attribute를 transfer한 뒤,
다시 source face를 target image로 blend하는 방식 - Source image에 민감해서 과장된 표정이나 자세 등이 퍼포먼스에 큰 영향을 미침
2. Target oriented method
- Feature level의 target face에서 동작
- Neural net을 이용해 target image에서 feature를 추출,
추출한 feature를 수정한 다음,
다시 이미지로 복구시켜 swapping image를 반드는 방식(e.g. DeepFake, FaceShifter) - DeepFake모델은 specific한 identity에 대해서만 swap이 가능
- FaceShifter는 attribute가 잘 보존되지 않는 경우가 있어 expression mismatch 문제가 있음
DeepFake
본 논문은 DeepFake 아키텍처로부터 확장하여,
임의의 identity에 대해서도 동작할 수 있도록 적용했습니다.
따라서 간단하게 DeepFake의 원리를 살펴보고, 한계점을 확인하도록 하겠습니다.
Image source : Deep Learning for Deepfakes Creation and Detection: A Survey,SSRN Electronic Journal, 2022
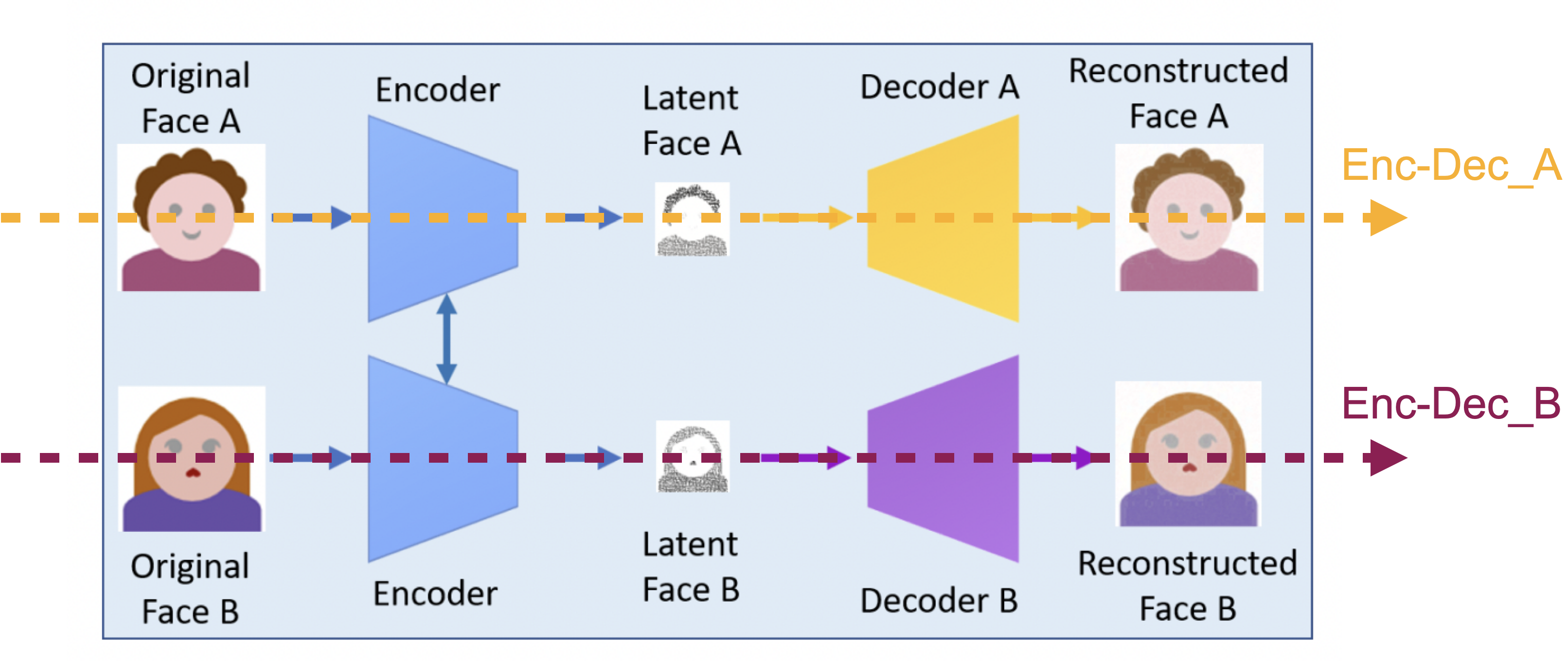
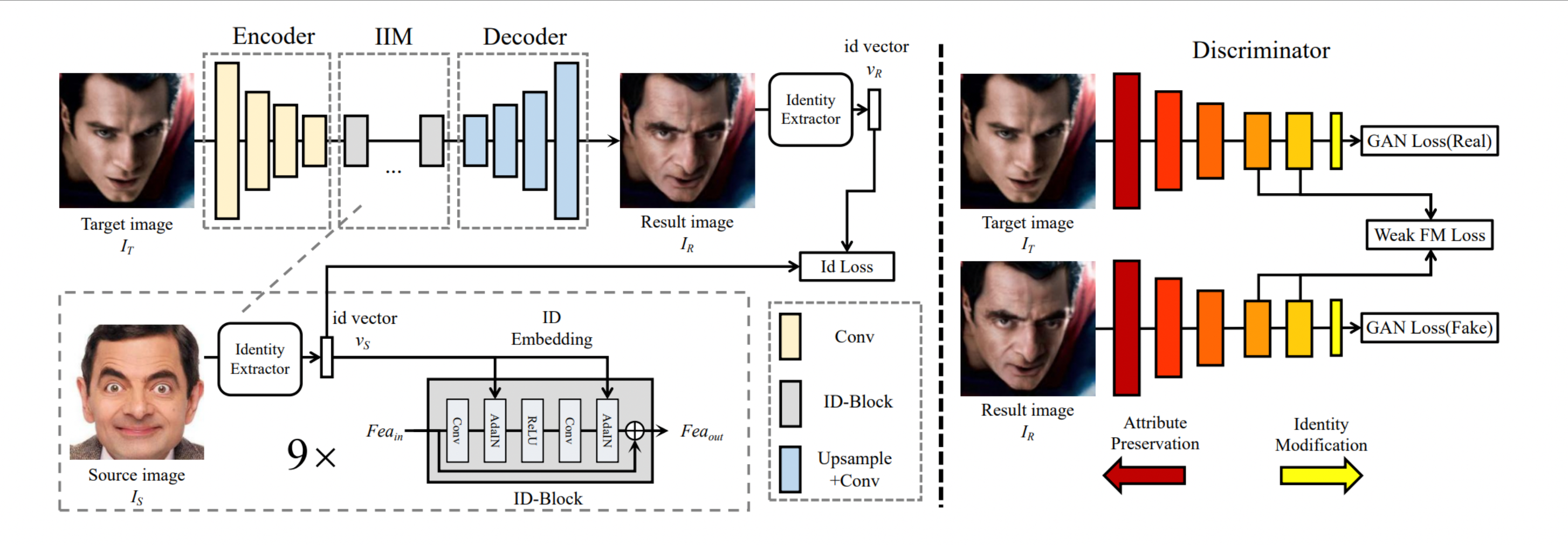
DeepFake의 구조는 위와 같이 동일한 하나의 인코더와,
두개의 identity specific한 Decoder로 구성되어 있습니다.
Training 단계에서 Enc-Dec_A는 Face_A 이미지를 input으로 받아 feature vector로 추출 후 다시 원본 이미지를 복원하는 방향으로 학습됩니다.
동일하게 Enc-Dec_B 또한 마찬가지로 동일한 작업을 Face_B 에 대해 수행합니다.
Image source : Deep Learning for Deepfakes Creation and Detection: A Survey,SSRN Electronic Journal, 2022
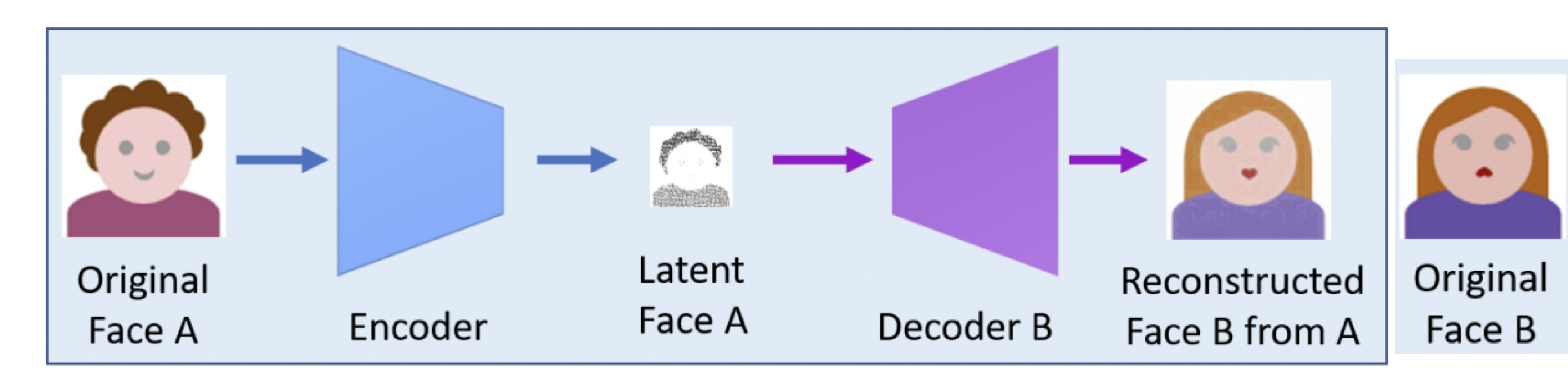
그리고 test stage에서 Face_A 이미지를 Enc-Dec_B 로 보내서 swapped face를 얻게 됩니다.
이때 Encoder는 Face_A 이미지에서 identity와 attribute가 포함된 feature 정보를 추출합니다.
그리고 Decoder_B는 Face_A 이미지의 feature를 Face_B 이미지의 identity로 변경합니다.
이게 가능하려면 Decoder_B에는 반드시 Face_B의 정보가 녹아들어 있어야 합니다.
위와 같은 이유로 DeepFake는 specific한 identity에 대해서만 수행할 수 있습니다.
즉, 이런 한계를 극복하기 위해서는 Decoder로부터 identity정보를 분리시켜야
전체적인 구조가 identity로부터 일반화 될 수 있습니다.
본 논문에서는 Encoder와 Decoder 사이에 ID Injection Module을 추가하여 구조를 개선했습니다.
Simswap framework
이제 본격적으로 본 눈문의 프레임워크에 대해 살펴보도록 하겠습니다.
Encoder part
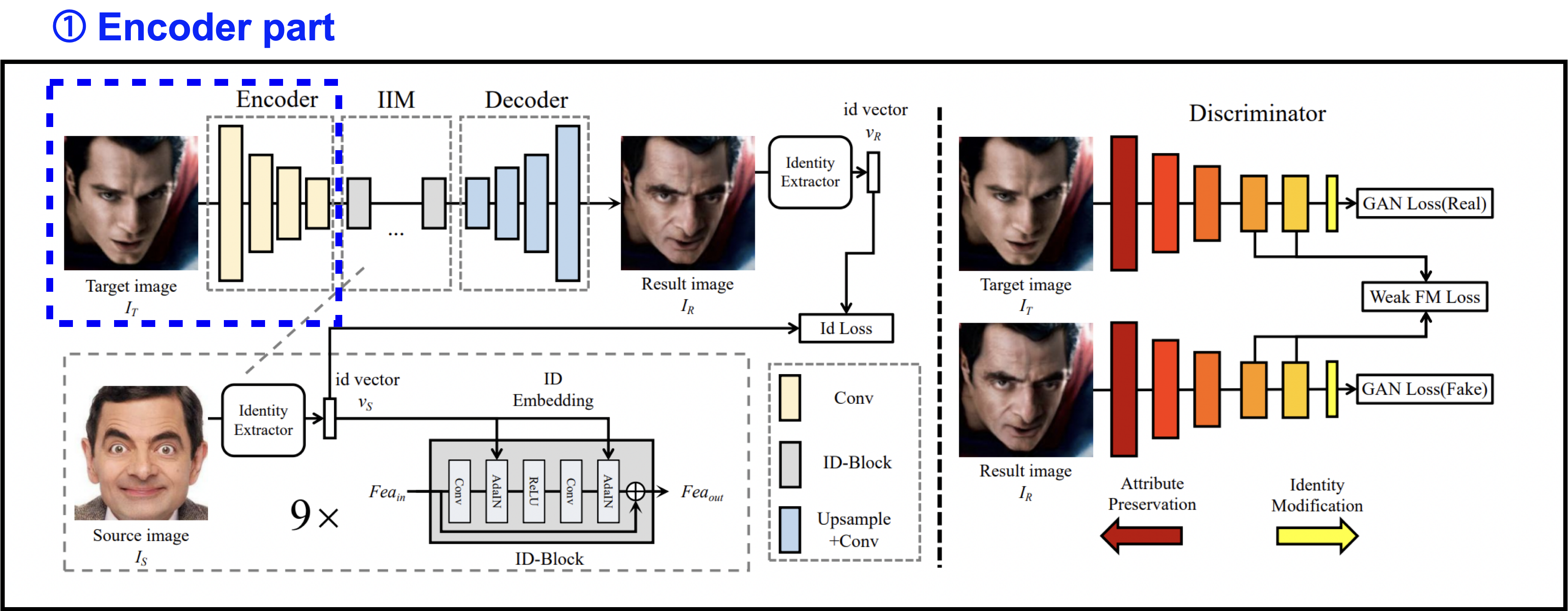
먼저 Encoder part 입니다.
여기서는 target image 를 encoder에 통과시켜 를 추출합니다.
우리의 목적은 target face를 source face로 swap하는 것이기 때문에,
에 있는 identity의 정보를, attribute 정보는 변하지 않게 하면서 source face의 identity로 갈아끼워주면 됩니다.
하지만 에 있는 identity와 attribute정보는 서로 얽혀있기 때문에, 잘라내듯이 딱 분리할 수가 없습니다.
따라서 본 논문에서는 전체 에 대해 수정을 거친 다음,
여러 training loss를 사용해서 에서 어떤 부분이 바뀌어야 하고,
어떤 부분이 유지되어야 하는지 implicit하게 학습할 수 있도록 설계했습니다.
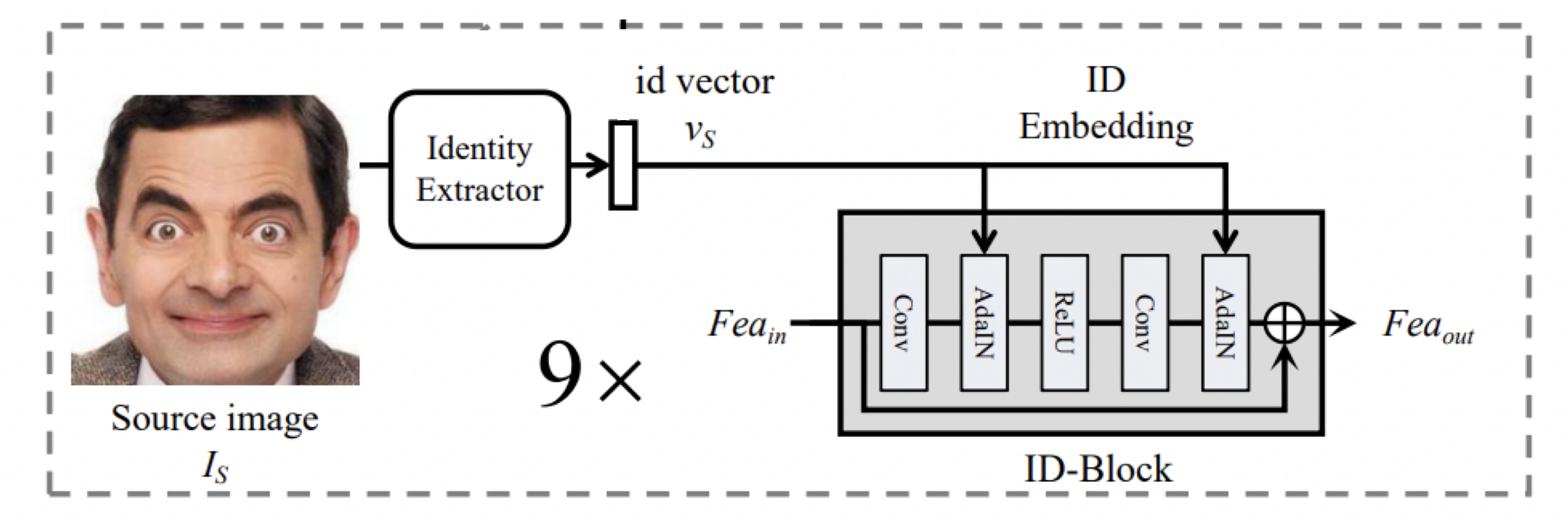
ID injection module (IIM)
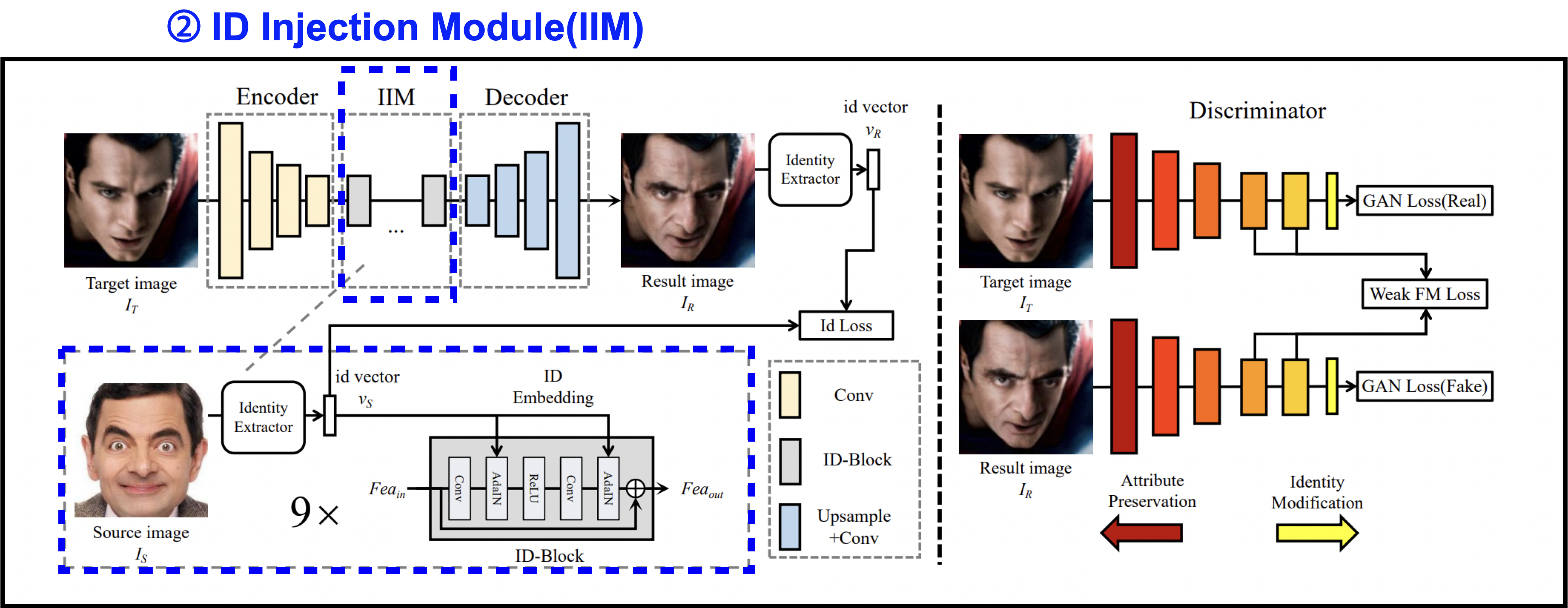
다음으로 ID injection module입니다.
ID injection module에서는 의 identity 정보가 source face의 identity가 되도록 변경합니다.
IIM은 identity extraction파트와, embedding파트로 구성됩니다.
-
Extraction part
먼저 identity extraction 파트에서는 identity와 attribute정보를 모두 포함하고 있는 source 이미지 를 처리합니다.
우리는 의 identity 정보만 필요로 하기 때문에,
face recognition network인 ArcFace모델을 이용해서 identity vector인 를 추출합니다. -
Embedding part
그다음 embedding 파트에서는 ID-Block를 사용해서 에 를 주입합니다.
ID-Block은 Residual Block을 수정한 것으로,
기존의 BatchNorm layer를 Adaptive Instance Normalization으로 대체한 구조입니다.
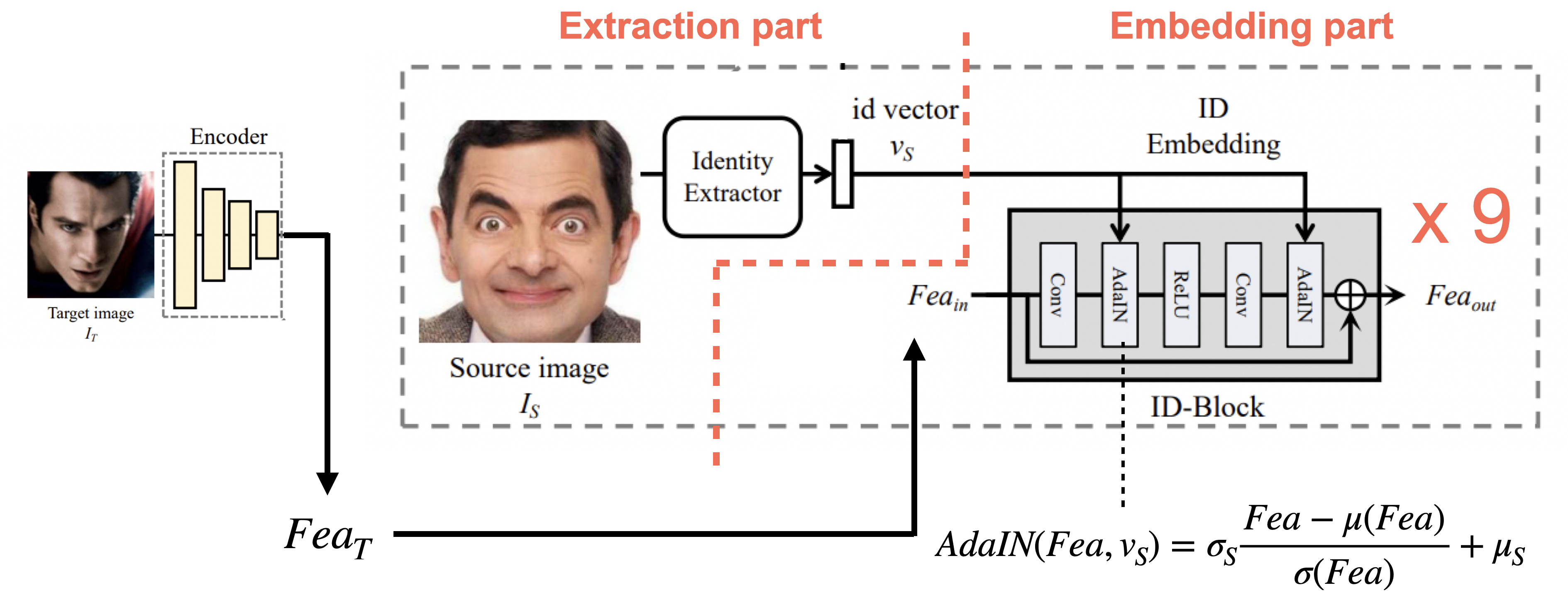
그리고 충분한 identity를 보증하기 위해서 9개의 ID-Block을 사용합니다.Adaptive Instance Normalization
Adaptive instance norm은 feature space상에서 평균과 분산이 style에 영향을 미친다면,
이 요소들을 뽑아서 즉석에서 교환해주는 방식입니다.즉, 보존해야 하는 content(attribute)를 담고있는 target 이미지의 feature인 에서
target image의 style(identity)를 뽑아내고,
우리가 원하는 source image의 style(identity)을 넣어주는 방식으로 수행됩니다.따라서 위 그림의 식에서 의 평균을 빼고 표준편차를 나눠준 부분이 style을 빼는 부분이고,
의 표준편차를 곱하고, 평균을 더해주는 부분이 style을 넣어주는 부분입니다.
정리하면 그냥 정규화를 하는게 아니라, 원하는 identity를 살리면서 정규화를 하는 것으로 이해하면 됩니다.
Decoder part
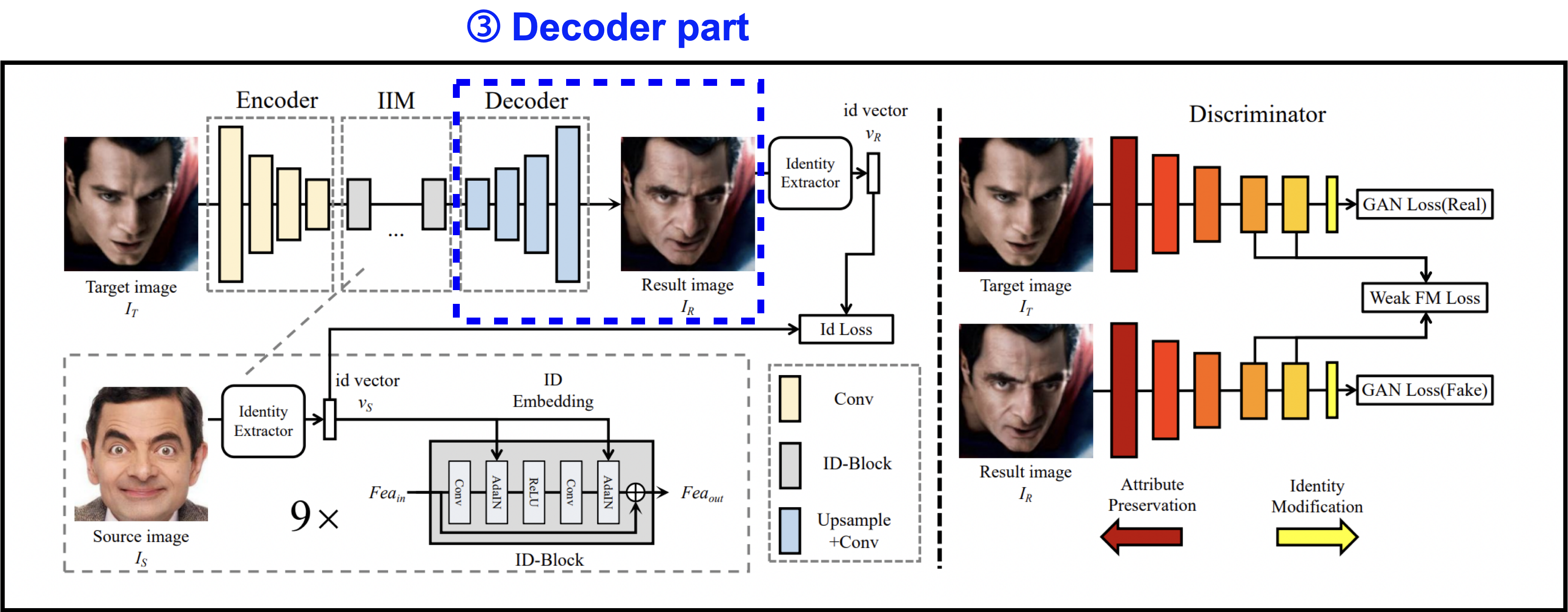
다음은 Decoder part입니다.
앞에서 identity information을 주입한 뒤,
이 수정된 feature를 decoder에 통과시켜 결과 이미지 을 만들어냅니다.
Source image는 학습 과정에서 다양한 identity를 사용하기 때문에,
decoder는 specific한 identity에 제한되지 않습니다.
따라서 decoder는 어떤 feature로부터 이미지를 만들어내는 것에만 오롯이 집중하고,
identity를 수정하는 역할은 모두 IIM에게 맡깁니다.
이렇게 위에서 말했던 것처럼 identity를 decoder로부터 분리시켜
임의의 identity에 대해서 동작할 수 있게 되었습니다.
Identity Loss & Adversarial training
이어서 학습에서 사용하는 추가적인 테크닉에 대해 기술하겠습니다.
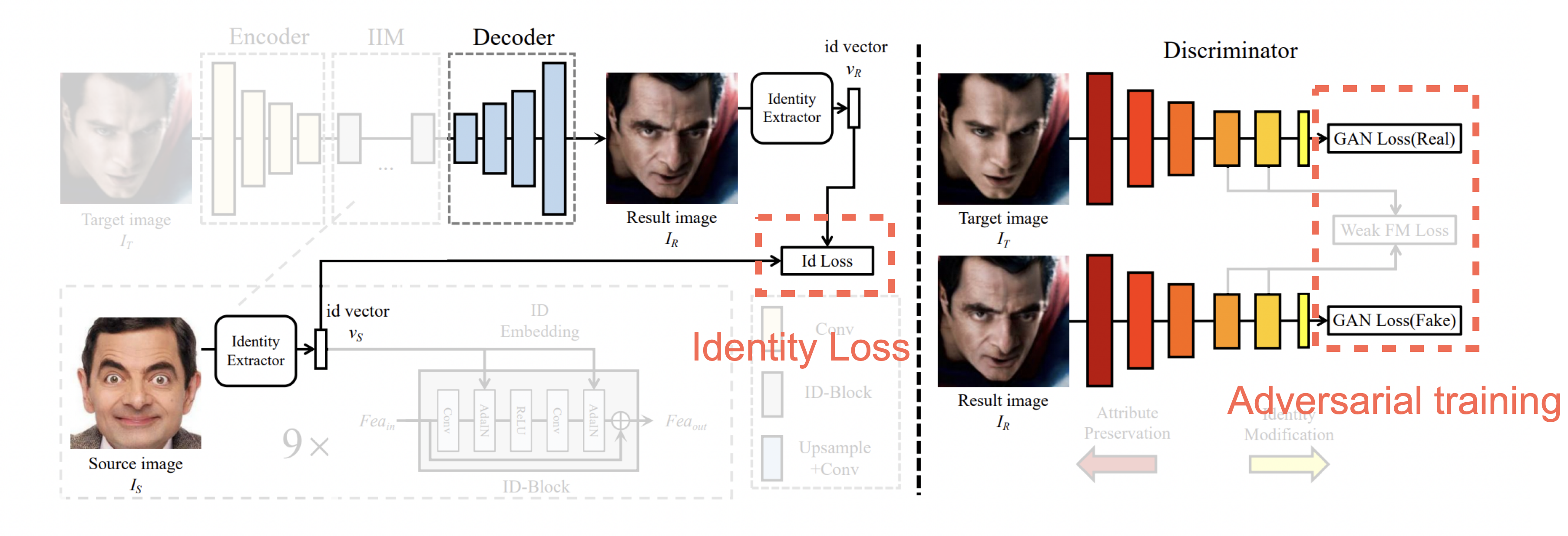
-
Identity Loss
Training 과정에서 만들어지는 결과 이미지 의 identity vector인 을 추출합니다.
이 벡터는 결과 이미지와 source 이미지의 identity가 얼마나 다른지 측정하기 위해 사용됩니다.
정리하면 source identity 와 result identity 의 코사인 유사도를 측정하여 둘 사이의 identity 거리를 줄여나가는 방향으로 학습하기 위한 함수가 identity loss 함수입니다. -
Adversarial training
위에서 identity loss를 사용하면 source 이미지와 result 이미지의 거리가 최소화 되는 방향으로 학습됩니다.
그렇게 identity loss만 사용하게 되면 source face에 오버피팅 될 수 있고,
target의 attribute를 잘 보존할 수 없게 됩니다.
따라서 target 이미지와 result 이미지의 차이도 최소화 할 수 있도록
target 이미지를 real 이미지, result 이미지를 fake 이미지로 설정하고 adversarial training을 활용합니다.
논문에서는 discriminator로 patchGAN을 사용했다고 나와 있습니다.PatchGAN
patchGAN의 discriminator는 특정 크기의 patch 단위로 이미지의 진위 여부를 판별하는 discriminator입니다.
그래서 상대적으로 적은 부분만을 확인하기 때문에 파라미터의 수가 적고,
연산시간이 짧고, 또한 전체 이미지의 크기에 영향을 받지 않기 때문에 구조적으로도 유연하다는 장점이 있습니다.
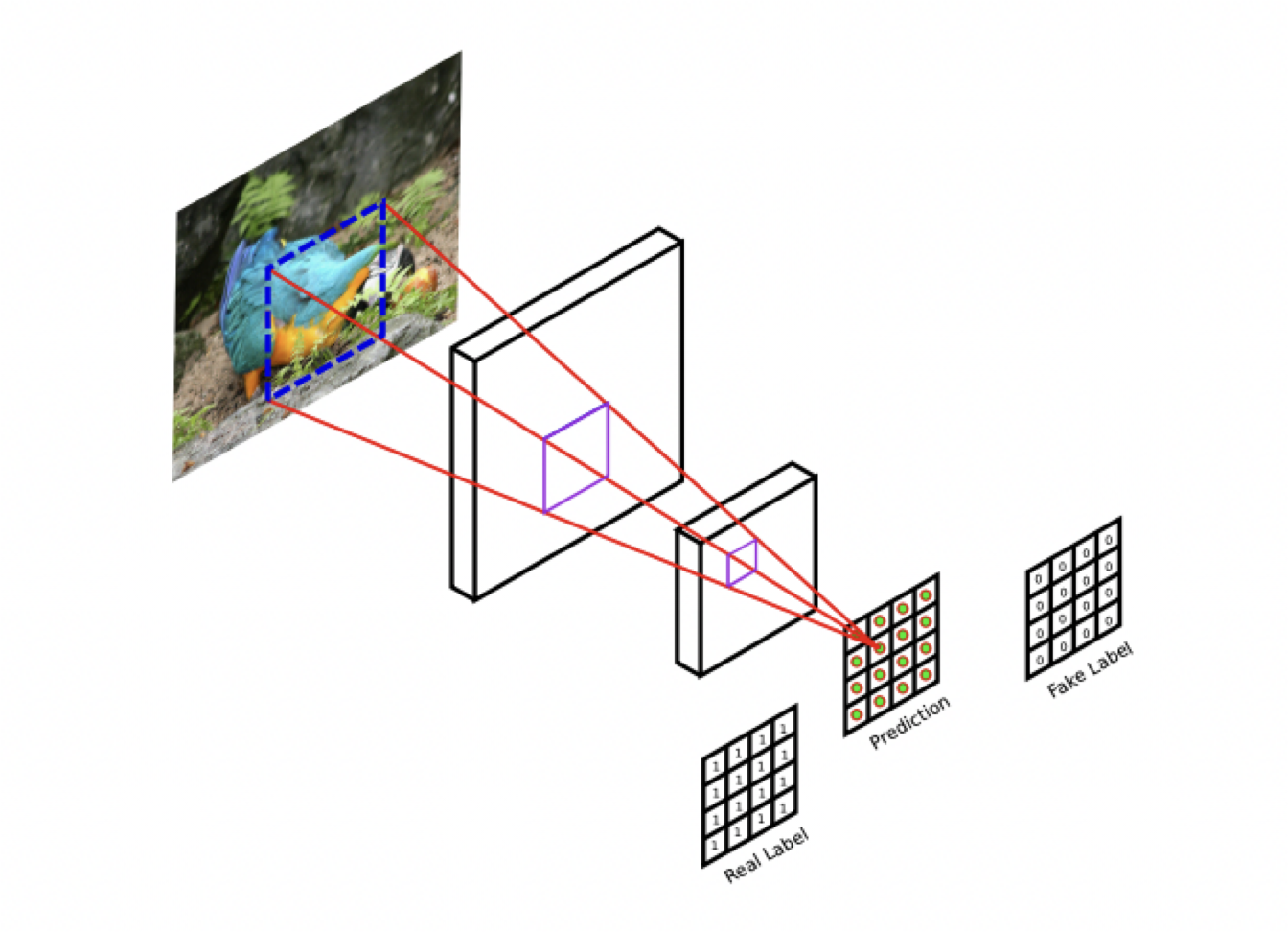
Image source : Patch-Based Image Inpainting with Generative Adversarial Networks, ArXiv, 2018
Weak Feature Matching Loss
여기서는 본 논문의 중요 내용인 Weak Feature Matching Loss에 대해 다루겠습니다.
잠시 앞으로 돌아가서,
face swapping task에서는 attribute feature는 유지하면서,
identity feature를 수정해야 한다고 했습니다.
하지만 앞의 IIM에서는 전체에 대해서 수정할 수 밖에 없었고,
따라서 target의 attribute 정보는 IIM의 embedding part에 의해서 영향을 받을 수 있습니다.
그런 attribute정보를 잘 보존하기 위해 또다른 training loss를 사용합니다.
여기서 각 attribute를 명시적으로 제한해버리면,
결국 각 attribute에 대해서 하나의 네트워크를 학습 시켜야 합니다.
하지만 deepfake 설명에서 언급했듯, 이건 우리가 바라는 방법이 아닙니다.
따라서 저자는 attribute를 implicit하게 보존하기 위해
Weak feature matching loss를 제안했습니다.
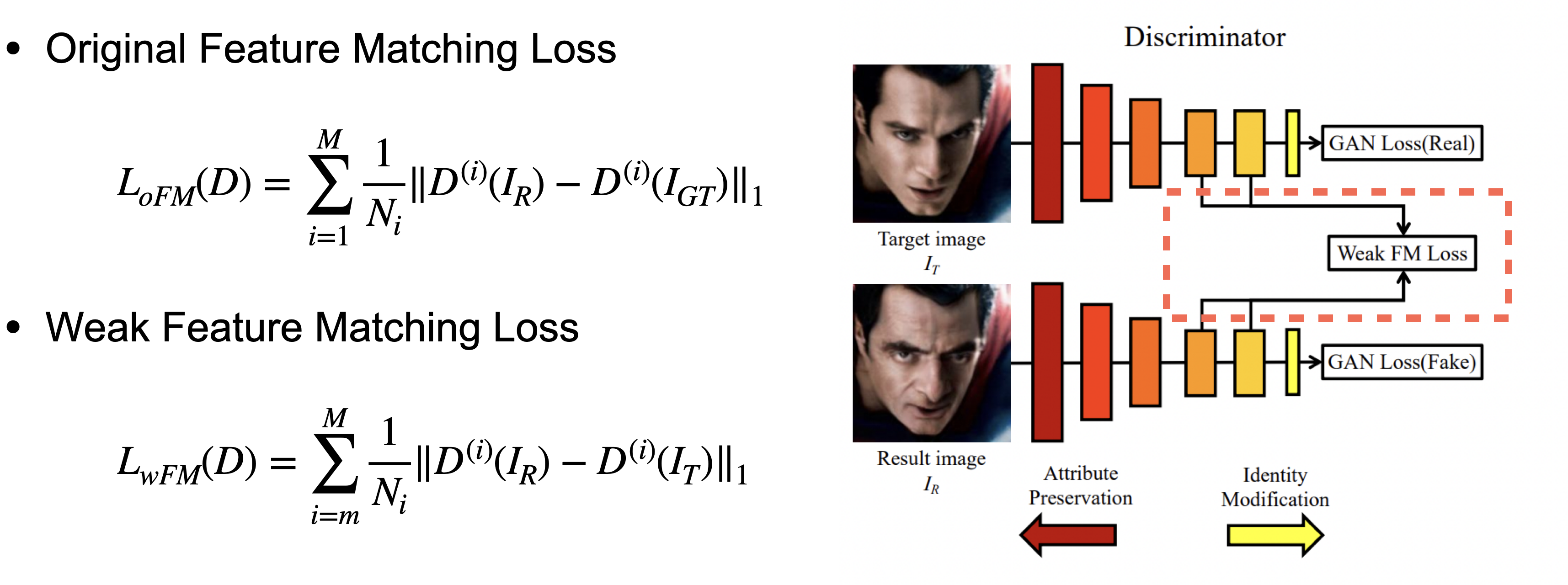
Feature matching loss는 ground-truth와 result이미지의 여러 layer에서 feature를 뽑아 discriminator를 이용해 비교하는 방법입니다.
위의 original fm loss 식의 각 요소는 다음과 같습니다.
- : discriminator의 번째 레이어 feature extractor
- : 번째 레이어의 element 수
- : 총 레이어의 수
- : 생성된 결과 이미지
- : ground-truth 이미지
Face swapping task에서는 ground-truth가 없기 때문에,
저자는 ground-truth대신 target image를 사용했습니다.
또한 face swapping task에서는 target image의 정보가 너무 많이 비교되도록 하면,
결과가 target image하고 너무 비슷하게 많들어 질 수 있습니다.
이렇게 되면 IIM에서 수행한 identity 수정이 잘 반영될 수 없기 때문에,
마지막 몇개의 layer만 사용해서 비교합니다.
사실 이 loss는 attribute를 제한하는 것이 목적인데,
attribute는 high semantic한 정보이기 때문에 주로 깊은 layer의 feature에 녹아 있기 때문입니다.
이렇게 weak feature match loss를 사용하여
target face의 attribute를 어떻게 보존할것인지 implicit하게 학습하게 됩니다.
Overall loss function
전체적인 Loss 함수들은 다음과 같습니다.
- Identity Loss
Identity Loss는 result image의 identity vector와 source image의 identity vector의 코사인 유사도 측정하여 Loss가 작아지는 방향으로 학습합니다.

- Reconstruction Loss
Reconstruction Loss는 source와 target이 같은 self-swapping의 경우에만 사용합니다.
만약 source face와 target face가 같은 identity를 갖고 있다면,
result face와 target face가 같아야 합니다.
따라서 그 차이를 줄이는 방향으로 학습합니다.
이 loss는 source와 target이 다른 경우 0을 사용합니다.

- Adversarial Loss and Gradient penalty
앞에서 설명한 adversarial loss를 사용하고,
gradient penalty term을 사용하여 gradient explosion을 방지하였습니다.
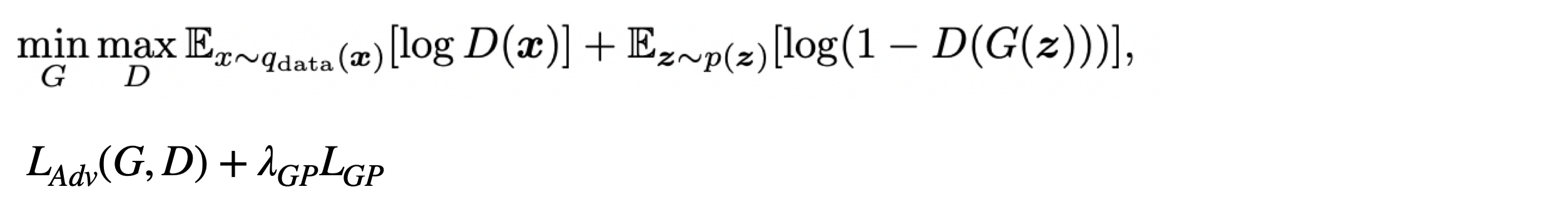
- Weak feature matching Loss
Multi-scale discriminator를 사용했기 때문에,
모든 discriminator에 대해 weak feature matching loss를 구해줍니다.
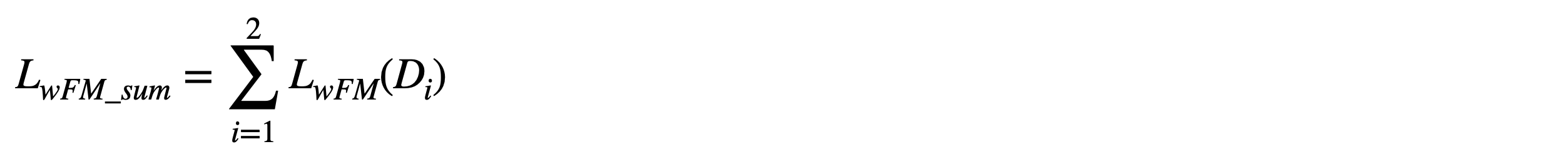
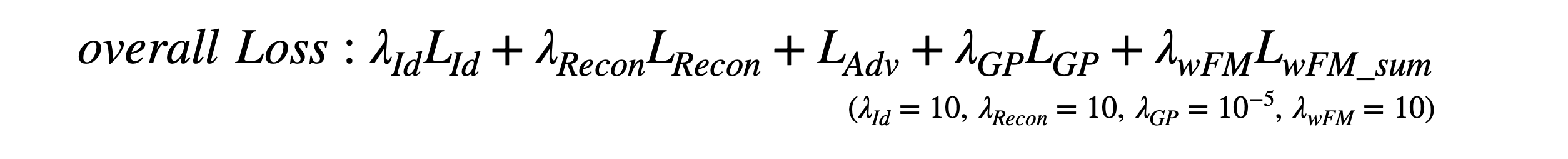
Experiments
Implementation detail
- Dataset : VGGFace2
- Remove smaller than 250x250
- Align and crop with size 224x224
- For face recognition model in the IIM,
use a pretrained Arcface model(dataset: InsightFace-v2) - Use Adam optimizer (default )
- Pair one batch for images with same identity
another batch for images with different identities - More than 500 epochs
주목할 만한 사항으로 Adam optimizer의 베타값과,
배치마다 같은 identity의 source, target
다른 identity의 source, target에 대해 학습하도록 한 것이 있습니다.
Qualitative face swapping results
결과 이미지를 확인하도록 하겠습니다.

결과를 보면 attribute를 잘 보존한 상태에서 identity를 잘 transfer한 이미지들을 확인할 수 있습니다.
실제 논문에는 8개의 target 이미지에 대한 결과가 나와있고, 눈여겨 볼 경우만 따로 잘라내어 첨부하였습니다.
위의 결과에서 첫번째와 두번째 행을 보면 과장된 표정이나 얼굴에 stripe가 있는 경우에도 표정이 잘 보존된것을 볼 수 있습니다.
그리고 세번째 행을 보면 조명 효과에 대한 attribute가 잘 보존되어 있으며,
마지막 행은 정면이 아닌 경우에도 face swap이 잘 수행됨을 볼 수 있습니다.
Comparison with other methods
다음으로는 target oriented method를 사용한 DeepFake와 FaceShifter 모델과 비교를 통해, simswap 모델의 성능을 확인하겠습니다.

왼쪽의 이미지를 보면 우선 DeepFake의 결과는 mismatch가 심한것을 볼 수 있습니다.
또한 보라색으로 표시한 사진을 보면 Simswap 모델이 FaceShifter 모델에 비해 표정이 잘 보존되고 있습니다.
오른쪽 이미지는 FaceShifter 모델과의 추가적인 비교를 한 결과입니다.
특히 두번째 행을 보면 target face는 눈을 가운데로 모은 표정을 짓고 있는데,
FaceShifter 모델의 결과를 보면 source의 identity에 더 큰 영향을 받은 것으로 보입니다.
Analysis of simswap
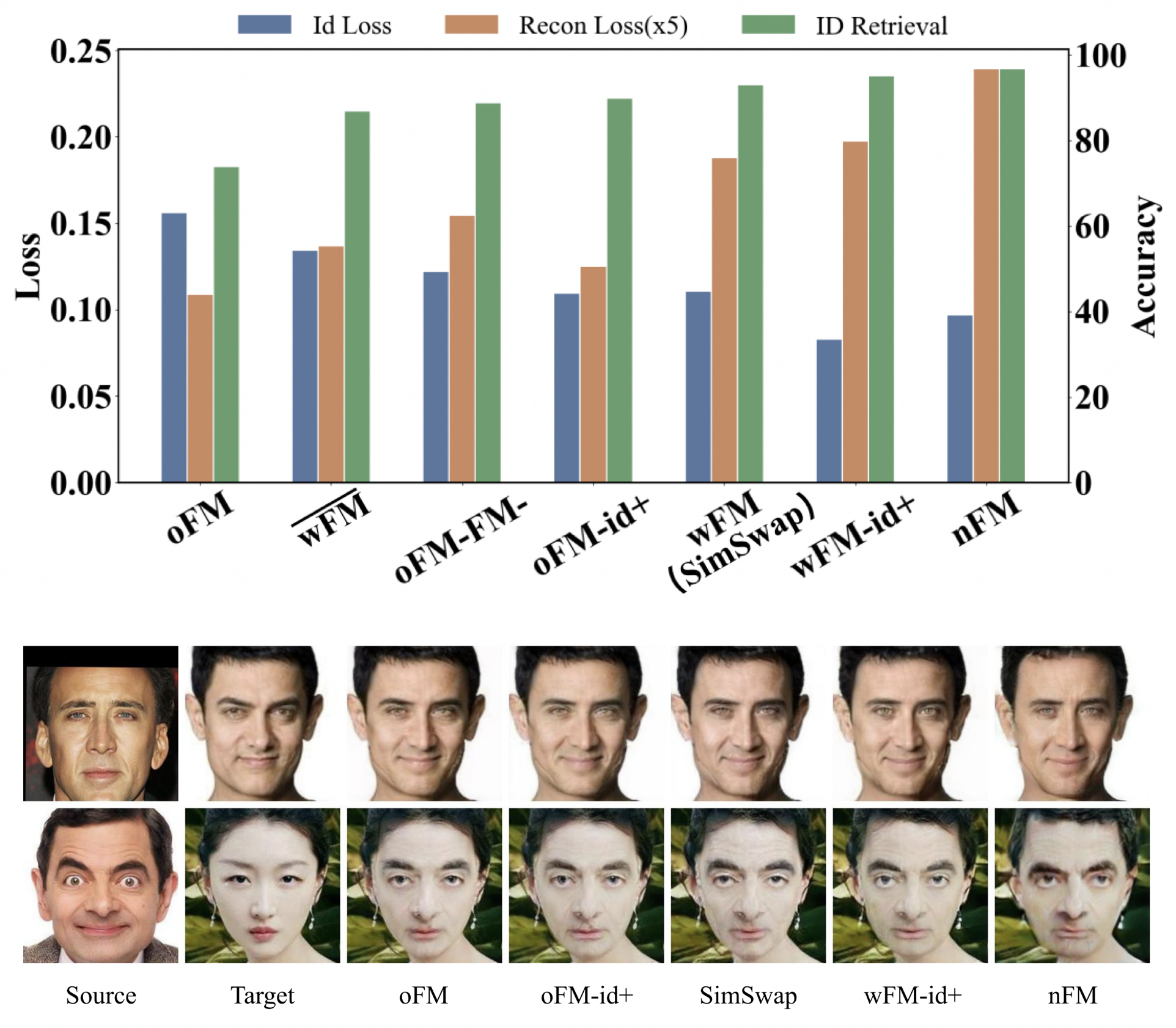
마지막으로 identity와 attribute간의 균형을 맞추는 부분입니다.
Simswap의 IIM은 target image로부터 추출한 feature 전체에 대해 source identity를 주입하기 때문에, 어쩔수없이 attribute를 보존하는데에 영향을 미칠 수 밖에 없습니다.
따라서 identity를 수정하는 정도와, attribute를 보존하는 정도의 최적의 균형을 찾아야 합니다.
Simswap 프레임워크에서는 이 둘을 조절할 수 있는 방법이 두가지가 있습니다.
먼저, ID-Loss에 곱해지는 값을 명시적으로 키워주면,
identity를 반영하는 능력이 더 커질 수 있습니다.
두번째로, feature matching loss에 반영되는 feature의 양을 조절하는 방법입니다.
따라서 저자는 여러 테스트를 통해 좋은 균형을 찾고자 하였고,
관련한 결과는 위의 그래프와 같습니다.
