1. Classification (분류)
말 그대로 분류를 뜻하는 Classification은 Supervised learning 지도학습의 일종으로 기존에 존재하는 데이터의 Category 관계를 파악하고, 새롭게 관측된 데이터의 Category를 스스로 판별하는 과정이다.
다중 분류는 비지도학습의 Clustering과 비슷하지만, 가장 큰 차이점은 Category의 도메인이 정의되어있는가 그렇지 않은가이다.
지도학습의 Classification은 이미 정해진 카테고리(레이블) 안에서 학습하여 새로운 데이터를 분류하지만,
비지도학습의 Clustering은 정해지지 않은 카테고리(레이블)를 원하는 만큼 생성하여, 분류하는 것이 가장 큰 차이점이다.
예시
이진 분류
Q: 이 글은 스팸이야?
A: True / False 결과
다중 분류
Q: 이 동물은 뭐야?
A: 고양이 또는 사자 또는 강아지 등으로 분류된 결과
2. Classification(분류) 알고리즘 종류
일련의 데이터가 포함되는 기존 카테고리들을 학습하고, 이것을 기반으로 컴퓨터는 데이터의 범주를 구분하여 경계를 나누는 것을 학습한다. 따라서 모델에 입력된 새로운 데이터는 해당 점이 어느 곳에 위치하느냐에 따라 가까운 카테고리 혹은 학습된 알고리즘에 의해 분류하게 된다.
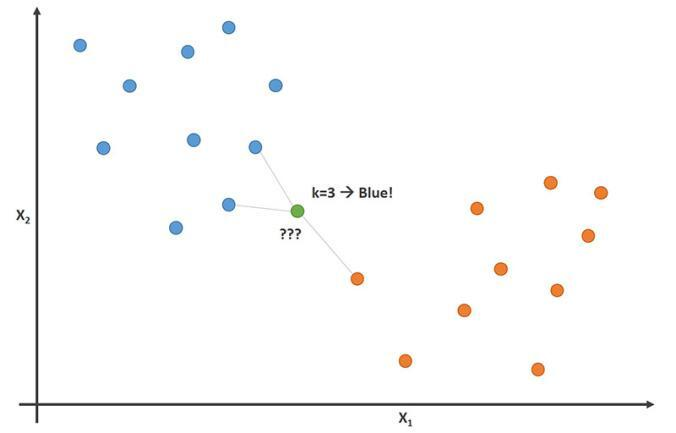
(1) KNN(K-nearest neighbor)
-
다양한 레이블의 데이터 중에서, 자신과 가까운 데이터를 찾아 자신의 레이블을 결정하는 방식
-
단순히 "주변에 가장 가까이 있는게 무엇인가?"가 아닌 "주변에 가장 가깝고, 많이 있는 것이 무엇인가?"라는 방식을 사용한다.
-
데이터의 분포를 신경쓰지 않는다.
-
회귀문제, 분류 문제 등에 적용 가능하다.
1. 회귀 문제 : knn의 값을 평균 내어 값 예측
2. 분류 문제 : knn 중에서 가장 많은 항목 선택
-
모든 데이터 열을 이처럼 같은 방식으로 처리하면 생각하지 못한 변수에 의해 오류가 생길 수 있으므로 거리의 제곱을 합산하기 전 각 카테고리에 대한 평균 거리를 빼고 계산하는 방식과 같은 다양한 거리 계산 알고리즘에 대한 논의가 필요하다.
-
예를 들어 실수 데이터의 경우 유클리드 거리 측정 방식을 사용하고, 범주형 혹은 이진 데이터와 같은 유형의 데이터는 해밍 거리 측정 방식을 사용한다.
예제

- 2차원 평면 상에 3개의 레이블(세모, 동그라미, 네모)이 놓여있다고 가정
- 별표가 들어왔을 때 어떤 레이블에 가까운지 판단
- 여기서는 빨간색 2개와 파란색 1개와 가깝기 때문에 빨간색으로 라벨링한다
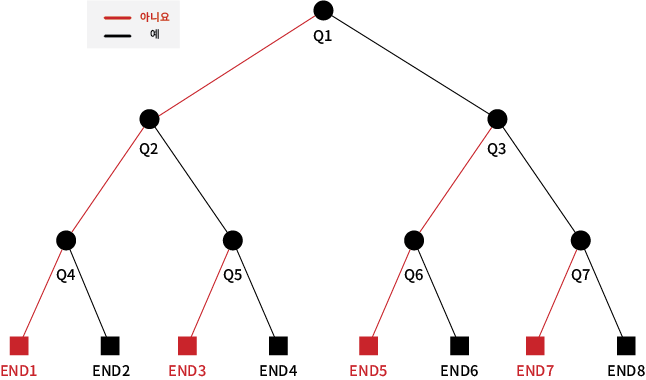
(2) Decision Tree (의사결정트리)
-
가장 단순한 분류 모델 중 하나로, decision tree와 같은 도구를 활용하여 모델을 그래프로 그리는 매우 단순한 구조로 되어 있다.
-
이 방식은 root에서부터 적절한 node를 선택하면서 진행하다가 최종 결정을 내리게 되는 model이다.
-
이 트리의 장점은 누구나 쉽게 이해할 수 있고, 결과를 해석할 수 있다
-
가지고 있는 데이터의 feature를 분석해서 tree를 build하는 과정이 제일 중요하다
-
해석이 쉬워서 해석이 필요한 산업에서 많이 쓰이는 모형이다
-
지도 학습의 분류 모델이나 회귀 모델 둘 다에 적용할 수 있다.
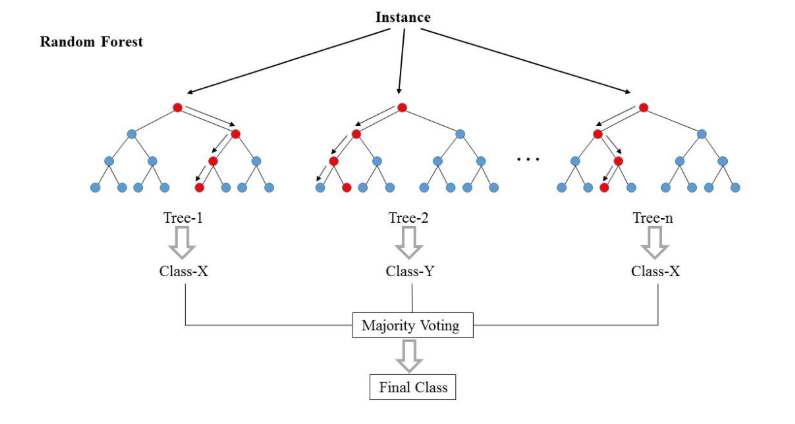
(3) Random Forest
-
Decision tree가 여러개 모여 Forest를 이룬 것이다.
-
Decision tree보다 작은 tree가 여러개 모이게 되어, 모든 트리의 결과들을 합하여 더 많은 값을 최종 결과로 본다
(4) Naive Bayes (나이브 베이즈)
- 나이브 베이즈는 확률을 사용한다.
예시
만약, 심슨에 대한 Feature에 대해 age와 sex 2개가 존재하는 상황에서,
심슨의 나이, 성별에 따라 survive할 확률(결과)은 얼마인지를 Naive Bayes의 이론에 따라 계산하게 된다

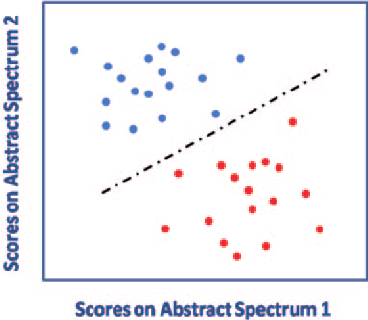
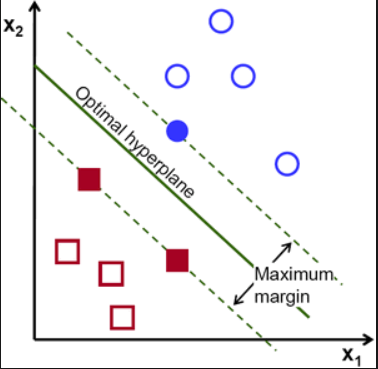
(5) SVM (Support Vector Machine)
-
서포트 벡터 머신은 기본적으로 Decision Boundary라는 직선이 주어진 상태이다.
-
주로 다루려는 데이터가 2개의 그룹으로 분류될 때 많이 사용된다.
-
SVM은 학습 데이터가 벡터 공간에 위치하고 있다고 생각하며 학습 데이터의 특징(feature) 수를 조절함으로써 2개의 그룹을 분류하는 경계선을 찾고, 이를 기반으로 패턴을 인식하는 방법이다.
-
두 그룹을 분류하는 경계선은 최대한 두 그룹에서 멀리 떨어져 있는 경계선을 구하게 되며, 이는 두 그룹과의 거리(margin)를 최대로 만드는 것이 나중에 입력된 데이터를 분류할 때 더 높은 정확도를 얻을 수 있기 때문이다.
-
이러한 SVM은 필기체 인식이나 이미지 분류 등에서 학습하는 데이터의 양을 줄일 수 있도록 도와준다.
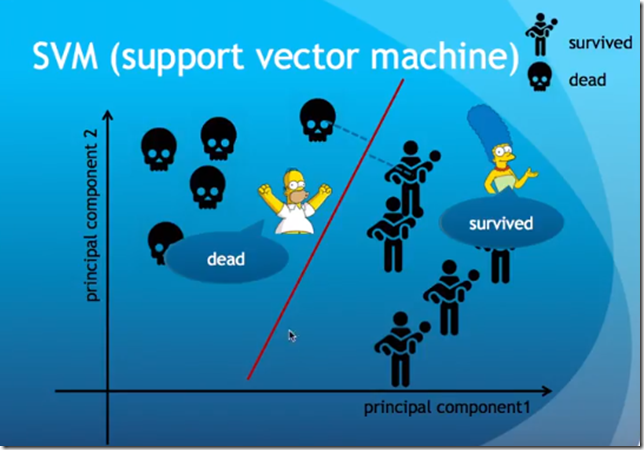
예시
심슨은 Decision Boundary보다 위에 있으므로 죽었다고 예측되고,
심슨부인은 Decision Boundary보다 아래에 있으므로 살았다고 예측된다.
참고
http://www.tcpschool.com/deep2018/deep2018_machine_algorithm
https://wooono.tistory.com/category/AI/Machine%20Learning
https://bangu4.tistory.com/99?category=904392
유튜브 Minsuk Heo 허민석
유튜브 나동빈
