강화학습(Reinforcement Learning)
지도 학습과 비지도 학습이 학습 데이터가 주어진 상태에서 환경에 변화가 없는 정적인 환경에서 학습을 진행했다면, 강화 학습은 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태(state)를 관찰하여 선택할 수 있는 행동(action)들 중에서 가장 최대의 보상(reward)을 가져다주는 행동이 무엇인지를 학습하는 것입니다.
강화 학습은 주체(agent)가 환경으로부터 보상을 받음으로써 학습하기 때문에 지도 학습과 유사해 보이지만, 사람으로부터 학습을 받는 것이 아니라 변화되는 환경으로부터 보상을 받아 학습한다는 점에서 차이를 보입니다.
이러한 강화 학습은 사람이 지식을 습득하는 방식 중 하나인 시행착오를 겪으며 학습하는 것과 매우 흡사하여 인공지능을 가장 잘 대표하는 모델로 알려져 있습니다.
강화 학습의 동작 순서
강화 학습은 일반적으로 다음과 같은 순서대로 학습을 진행하게 됩니다.
- 정의된 주체(agent)가 주어진 환경(environment)의 현재 상태(state)를 관찰(observation)하여, 이를 기반으로 행동(action)을 취합니다
- 이때 환경의 상태가 변화하면서 정의된 주체는 보상(reward)을 받게 됩니다.
- 이 보상을 기반으로 정의된 주체는 더 많은 보상을 얻을 수 있는 방향(best action)으로 행동을 학습하게 됩니다.
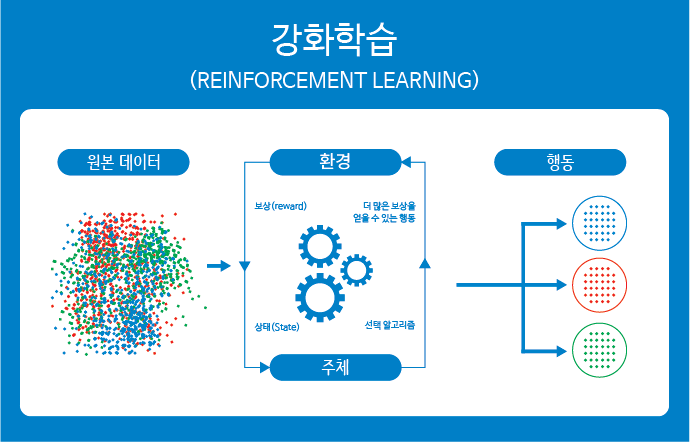
강화 학습에서의 '관찰-행동-보상'에 이르는 일련의 과정을 경험(experience)이라고 부를 수 있습니다.
이용(exploitation)과 탐험(exploration) 사이의 균형
경험을 통해 학습하는 강화 학습에서 최단 시간에 주어진 환경의 모든 상태를 관찰하고, 이를 기반으로 보상을 최대화할 수 있는 행동을 수행하기 위해서는 이용(exploitation)과 탐험(exploration) 사이의 균형을 적절히 맞춰야 합니다.
이용(exploitation)이란 현재까지의 경험 중 현 상태에서 가장 최대의 보상을 얻을 수 있는 행동을 수행하는 것을 의미하고, 이러한 다양한 경험을 쌓기 위해서는 새로운 시도가 필요한데 이러한 새로운 시도를 탐험(exploration)이라고 부릅니다.
탐험을 통해 얻게 되는 경험이 언제나 최상의 결과일 수는 없기에 이 부분에서 낭비가 발생하게 됩니다. 즉, 풍부한 경험이 있어야만 더 좋은 선택을 할 수 있게 되지만, 경험을 풍부하게 만들기 위해서는 새로운 시도를 해야 하고 이러한 새로운 시도는 언제나 위험 부담을 가지게 됩니다.

예를 들어, 빵집에 가서 지금까지 자신이 먹어본 빵 중 가장 맛있는 빵을 고르는 것이 이용(exploitation)이 되며, 한 번도 먹어보지 못한 다른 빵을 고르는 것이 탐험(exploration)이 됩니다. 만약 새로 고른 빵이 가장 맛있다고 느껴지면 다음 번 선택에서 이용될 수 있으나, 만약 맛이 없었다면 한 번의 기회를 낭비하게 된 것입니다.
따라서 이용과 탐험 사이의 적절한 균형을 맞추는 것이 강화 학습의 핵심이 되는 것입니다.
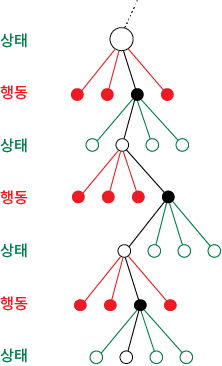
마르코프 결정 프로세스(Markov Decision Process, MDP)
강화 학습에서 보상을 최대화할 수 있는 방향으로 행동을 취할 수 있도록 이용과 탐험 사이의 적절한 균형을 맞추는데 사용되는 의사결정 프로세스가 바로 마르코프 결정 프로세스입니다.
MDP에서 행위의 주체(agent)는 어떤 상태(state)를 만나면 행동(action)을 취하게 되며, 각 상태에 맞게 취할 수 있는 행동을 연결해 주는 함수를 정책(policy)이라고 합니다. 따라서 MDP는 행동을 중심으로 가치 평가가 이루어지며, MDP의 가장 큰 목적은 가장 좋은 의사결정 정책(policy) 즉 행동에 따른 가치(value)의 합이 가장 큰 의사결정 정책을 찾아내는 것입니다.
강화 학습의 활용
강화 학습은 프로세스 제어, 네트워크 관리, 로봇공학 등 현재 다양한 분야에서 활용되고 있습니다.
