Poetry
Change poetry python version
강의(nomad)와 동일한 개발 환경 구축을 위해 가상환경에서 파이썬 버전을 3.10에서 3.11로 변경한다.
python3.11을 wsl에 설치하고 poetry init 중 python version을 3.11로 하면 기존 3.10이 3.11에 호환이 되지 않아 poetry shell 명령어가 동작하지 않는다.
구글링을 통해 pyenv를 사용하거나 sudo update-alternatives --config python 명령어를 사용해 python default version을 설정하는 등의 방법을 알아보았지만 default version은 유지한 채 가상환경에서만 설치한 파이썬 버전 중 원하는 버전을 사용하는 방법을 쓰기로 했다.
먼저 사용할 python 버전이 있는 path를 which 명령어를 통해 알아낸다. (which python3.11)
기존 동작하지 않은 poetry init을 한 작업 폴더에서 pyproject.toml 파일의 파이썬 버전을 사용할 버전으로 수정한다. (내 경우 마이크로 버전이 달라서 수정함)
작업 폴더 터미널에서 poetry env use (which 명령어를 사용해 나온 path)를 하면 성공
poetry shell 명령어로 가상환경 진입 성공

터미널에서 python 명령어를 사용하면 기존의 3.10버전으로 실행

requirements.txt -> pyproject.toml
설치할 패키지가 매우 많으면 하나하나 poetry add 명령어로 설치하는데에는 시간이 많이 걸린다.
처음엔 requirements 의 내용을 복사하여 toml에 붙여넣었지만 서식이 달라서 실패 (requirements: black==23.9.1, toml: black = "23.9.1")
해결 방법으로는 requirements.txt 파일을 작업 파일에 생성하고(내용 포함) cat requirements.txt | xargs poetry add 명령어를 사용하면 requirements 파일을 읽어 poetry에 설치해준다.
Jupyter NoteBooks
파일이름.ipynb
extension에서 jupyter 설치 (+확장팩)
wsl 사용하면 wsl에서 사용하도록 설치 -> 그래야 wsl 가상환경 python 인식함
파일이름.ipynb 파일을 보면 우측 상단에 커널 선택항목을 눌러서 작업 환경의 python으로 설정(작업 환경에 설치된 패키지를 사용하기 위함)
단축키(windows)
| 단축키 | 의미 |
|---|---|
| ESC | "셀 편집 모드"에서 "셀 선택 모드"로 전환 |
| Enter | 선택된 셀 편집(커서) |
| Ctrl+Enter | 현재 셀 코드 실행 |
| Shift+Enter | 셀을 실행하고 새로운 셀 생성 |
| D D | 선택된 셀 삭제 |
| A or B | 선택된 셀 위 또는 아래에 새로운 셀 생성 |
파이썬 문법 심화
코드 컨벤션
코드 스타일을 통일하자는 "약속" (안해도 코드는 잘 동작함)
파이썬에서는 PEP-8이라는 컨벤션 가이드를 제공
네이밍 컨벤션
표기법
python code style
Pascal
각 단어를 대문자로 구별
PythonCodeStyleCamel
Pascal과 동일하지만 첫 문자가 소문자로 시작
pythonCodeStyleSnake
python_code_style
변수, 함수 - Snake 표기법 사용
Class - Pascal
상수를 표기할 땐 모든 문자를 대문자로 표현
list, 또는 복수인 자료를 표현할 때는 "복수형 단어" 또는 "변수_list"와 같이 사용한다.
이름만 보고 해당 코드가 어떤걸 의미하는지 추측할 수 있도록 네이밍한다.
자주 사용하는 모듈
pprint()
pretty print의 약자
기존 print는 형식없이 값만을 출력, pprint는 가독성이 높도록 출력
from pprint import pprint
sample_data = {
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{"id": "1001", "type": "Regular"},
{"id": "1002", "type": "Chocolate"},
{"id": "1003", "type": "Blueberry"},
{"id": "1004", "type": "Devil's Food"}
]
},
"topping":
[
{"id": "5001", "type": "None"},
{"id": "5002", "type": "Glazed"},
{"id": "5005", "type": "Sugar"},
{"id": "5007", "type": "Powdered Sugar"},
{"id": "5006", "type": "Chocolate with Sprinkles"},
{"id": "5003", "type": "Chocolate"},
{"id": "5004", "type": "Maple"}
]
}
pprint(sample_data)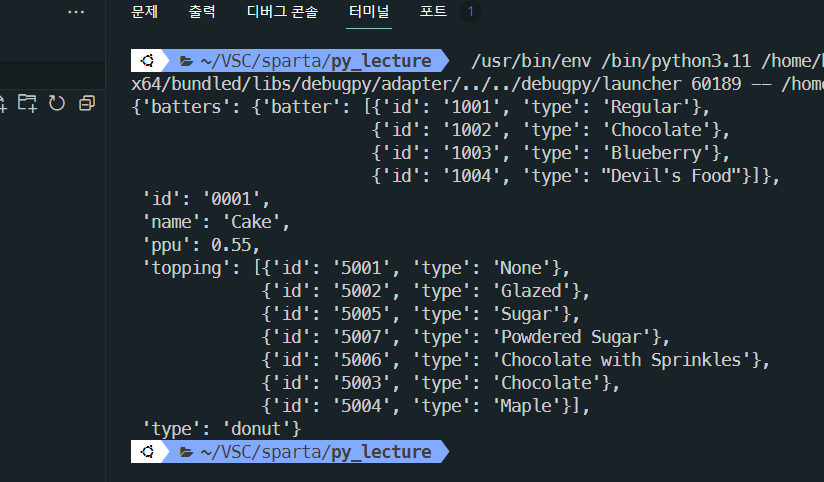
random
랜덤한 로직이 필요할 때 사용
# 난수 생성, 임의의 번호 생성 등 랜덤한 동작이 필요할 때 사용
import random
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
random.shuffle(numbers) # 카드 셔플처럼 numbers를 무작위하게 섞기
random_number = random.randint(1, 10) # 1 ~ 10 사이의 무작위 번호 생성time
시간과 관련된 로직이 필요할 때
import time
start_time = time.time() # 현재 시간 저장
time.sleep(1) # 코드를 1초간 대기
end_time = time.time()
# 코드 실행 시간 구하기 (단위 : 초)
print(f"코드 실행 시간 : {end_time-start_time:.5f}")datetime
날짜와 관련된 로직을 필요할 때
from datetime import datetime, timedelta
# 현재 날짜 및 시간
print(datetime.now())
# datetime의 format code
'''
%y : 두 자리 연도 / 20, 21, 22
%Y : 네 자리 연도 / 2020, 2021, 2022
%m : 두 자리 월 / 01, 02 ... 11 ,12
%d : 두 자리 일 / 01, 02 ... 30, 31
%I : 12시간제 시간 / 01, 02 ... 12
%H : 24시간제의 시간 / 00, 01 ... 23
%M : 두 자리 분 / 00, 01 ... 58, 59
%S : 두 자리 초 / 00, 01 ... 58, 59
'''
# string -> datetime
string_datetime = "23/12/25 13:20"
datetime_ = datetime.strptime(string_datetime, "%y/%m/%d %H:%M")
print(datetime_)
# datetime -> string
now = datetime.now()
string_datetime = datetime.strftime(now, "%y/%m/%d %H:%M:%S")
print(string_datetime)
# 3일 전 날짜 구하기
three_days_ago = datetime.now() - timedelta(days=3)
print(three_days_ago)날짜 데이터는 보기에는 string처럼 보이지만 string이 아니기 때문에 날짜를 사용한 로직을 하려면 format을 해야 한다.
조건문 심화
all() & any()
-
all()
and를 응용한 함수 -
any()
or을 응요한 함수
# all() : 요소들이 모두 True일 경우 True 리턴
if all([True, True, True, False, True]):
print("통과!")
# any() : 요소들 중 하나라도 True일 경우 True 리턴
if any([False, False, False, True, False]):
print("통과!")정규표현식(regex)
regular expression의 약자
문자열이 특정 패턴과 일치하는지 판단하는 형식 언어
대중적으로 많이 사용되는 정규표현식은 구글링을 통해 찾는 것이 좋다.
from pprint import pprint
import re
# rstring : backslash(\)를 문자 그대로 표현(compile과 정규표현식 사이에 있는 r)
# ^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$ : 이메일 검증을 위한 정규표현식 코드
email_regex = re.compile(r"^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$")
def verify_email(email):
return bool(email_regex.fullmatch(email))
test_case = [
"apple", # False
"sparta@regex", # False
"$parta@regex.com", # False
"sparta@re&ex.com", # False
"spar_-ta@regex.com", # True
"sparta@regex.co.kr", # True
"sparta@regex.c", # False
"sparta@regex.cooom", # False
"@regex.com", # False
]
result = [{x: verify_email(x)} for x in test_case]
pprint(result)파일, 디렉터리 다루기
glob
from pprint import pprint
import glob
# ./는 현재 python 파일이 위치한 경로
# ./venv/*은 venv 폴더 내 모든 파일들을 의미
path = glob.glob("./venv/*")
pprint(path)
# **은 해당 경로 하위 모든 파일을 의미하며, recursive 플래그와 같이 사용
# recursive를 True로 설정하면 디렉토리 내부의 파일들을 재귀적으로 탐색
path = glob.glob("./venv/**", recursive=True)
pprint(path)
# *.py와 같이 작성 시 특정 확장자를 가진 파일들만 볼 수 있습니다.
# ./venv/**/*.py는 venv 하위 모든 폴더들을 재귀적으로 탐색하며 .py 확장자 파일을 탐색
path = glob.glob("./venv/**/*.py", recursive=True)
pprint(path)
open
# "w" : 파일을 쓰기 모드로 엽니다. 만약 파일이 없다면 새로 생성합니다.
# r 모드는 파일을 읽기 모드로 엽니다.
# a 모드는 기존 내용을 유지한 상태로 추가합니다.
# encoding : 파일의 encoding 형식을 지정합니다.
f = open("file.txt", "w", encoding="utf-8")
f.write("파이썬 파일 쓰기 테스트!\n")
# open 함수를 실행하면 python 스크립트가 끝날때 까지 파일이 열려있음
# 파일에 대한 작업이 끝나면 close()를 사용
f.close()
# with를 사용할 떄는 별도로 close 해주지 않아도 됨
with open("file.txt", "r", encoding="utf-8") as r:
# readlines는 파일의 모든 내용을 list 자료형으로 한번에 읽음
print(r.readlines())
with open("file.txt", "r", encoding="utf-8") as r:
while True:
# readline은 파일을 한 줄 씩 읽음
line = r.readline()
# 파일 끝까지 텍스트를 읽어들였다면 반복문을 중지
if not line:
break
# 텍스트의 줄바꿈 문자 제거
# 안하면 텍스트 마지막에 '\n이 출력
line = line.strip()
print(line)
itertools
효율적인 루핑을 위한 이터레이터를 만드는 함수
특정 패턴이 무한 반복되는 배열, 배열의 값을 일괄적으로 계산한는 등의 이터레이터가 존재
from itertools import product, permutations, combinations, combinations_with_replacement
sample = ["A", "B", "C"]
sample2 = [1, 2, 3, 4]
# 데카르트곱
# 행 / 열을 구분하여 프린트 하기 위해 enumerate 사용
for i, v in enumerate(product(sample, sample2), 1):
print(v, end=" ")
if i % len(sample2) == 0:
print("")
# 원소의 개수가 n개인 순열 (n=3)
for i in permutations(sample, 3):
print(i)
# 원소의 개수가 n개인 조합 (n=2)
for i in combinations(sample, 2):
print(i)
# 원소의 개수가 n개인 중복을 허용한 조합 (n=3)
for i in combinations_with_replacement(sample, 3):
print(i)
json
javascript Object Notation의 약자
데이터를 저장하거나 데이터 통신을 할 때 주로 사용
key: value 쌍으로 이루어져 dict 형태와 매우 유사하다. 따라서 json -> dict, dict -> json으로 변경할 수 있다.
import json
import requests
# 해당 사이트는 요청에 대한 응답을 json 형태의 문자열로 내려줌
url = "https://jsonplaceholder.typicode.com/"
r = requests.get(f"{url}users/1")
# json을 dictionary 자료형으로 변경
response_content = json.loads(r.text)
print(type(response_content))
# dict 자료형이기 때문에 key를 사용해 value를 확인
print(f"사용자 이름은 {response_content['name']} 입니다.")CSV
comma-separated values의 약자
텍스트에 쉼표를 사용해 필드를 구분한다.
-
csv 파일 읽기
list: csv.reader()
dict: csv.DictReader()import csv csv_path = "sample.csv" # csv를 list 자료형으로 읽기 csv_file = open(csv_path, "r", encoding="utf-8") csv_data = csv.reader(csv_file) for i in csv_data: print(i) csv_file.close() # csv를 dict 자료형으로 읽기 csv_file = open(csv_path, "r", encoding="utf-8") csv_data = csv.DictReader(csv_file) for i in csv_data: print(i) csv_file.close()
-
csv 파일 쓰기
import csv csv_path = "sample.csv" # newline='' 옵션을 줘서 중간에 공백 라인이 생기는 것을 방지 csv_file = open(csv_path, "a", encoding="utf-8", newline='') csv_writer = csv.writer(csv_file) # csv에 데이터를 추가 csv_writer.writerow(["lee@sparta.com", '1989', "lee", "Seoul"]) csv_file.close()
데코레이터
파이썬의 함수를 장식해주는 역할
함수 위에 @decorator 형태로 작성, 해당 함수가 실행될 때 데코레이터가 같이 실행
함수를 인자로 받는다.
# 호출 할 함수를 인자로 받도록 선언
def decorator(func):
def wrapper():
# func.__name__는 데코레이터를 호출 한 함수의 이름
print(f"{func.__name__} 함수에서 데코레이터 호출")
func()
print(f"{func.__name__} 함수에서 데코레이터 끝")
return wrapper
@decorator
def decorator_func():
print("decorator_func 함수 호출")
decorator_func()
# result
"""
decorator_func 함수에서 데코레이터 호출
decorator_func 함수 호출
decorator_func 함수에서 데코레이터 끝
"""