
💻 프로젝트 소개
kaggle의 전력소비량 데이터를 이용하여 여러 예측 ML model을 학습시킨 후 전력소비량을 예측해보려고 한다.
[데이터셋 출처]
https://www.kaggle.com/datasets/srinuti/residential-power-usage-3years-data-timeseries
📁 데이터셋
[데이터셋 구성]
- Date: 날짜
- kWh: 전력소비량
- Temp_avg: 평균 기온
- Dew_avg: 평균 이슬점
- Hum_avg: 평균 습도
- Wind_avg: 평균 바람세기
- Press_avg:평균 기압
- Precipit: 강수량
[EDA]
- 각 칼럼들의 그래프를 그려보면 아래와 같았다.
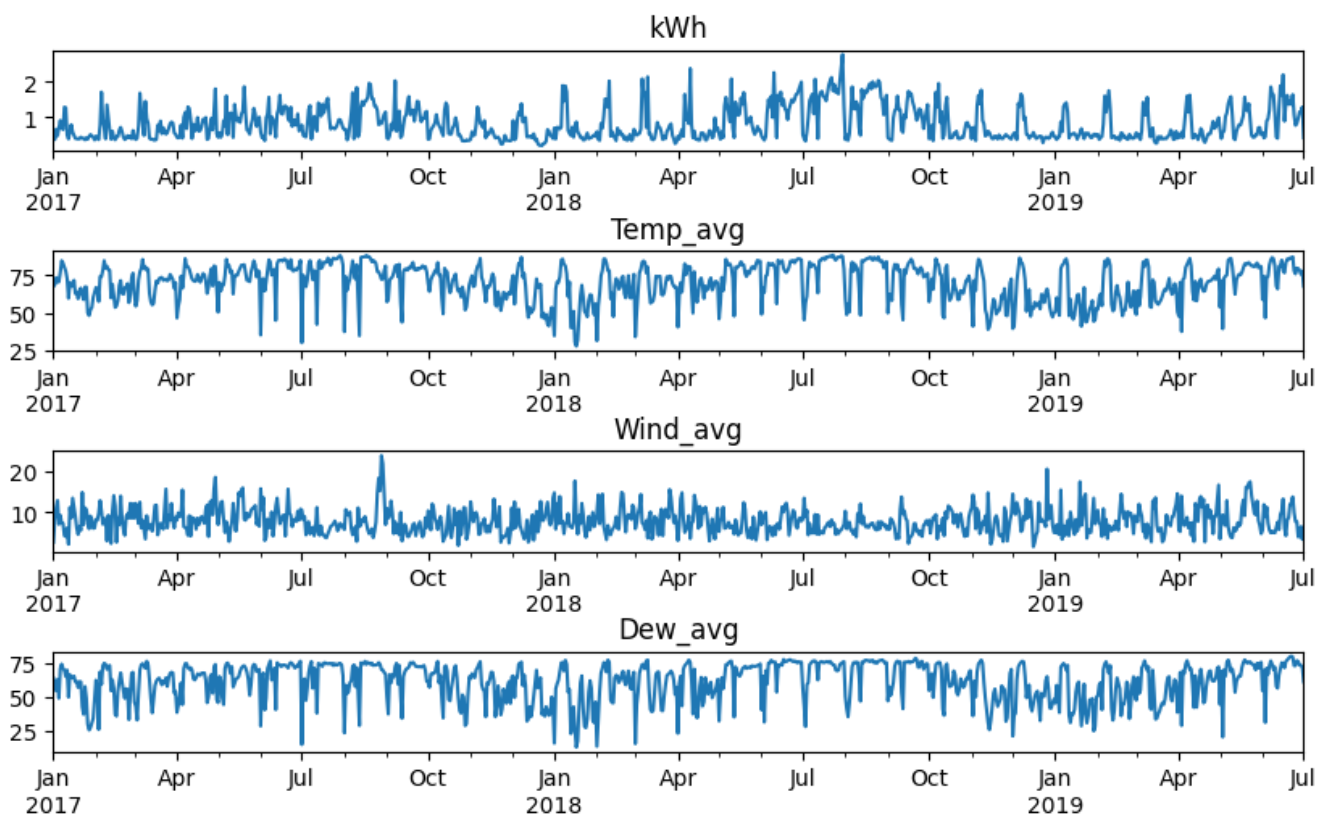 | 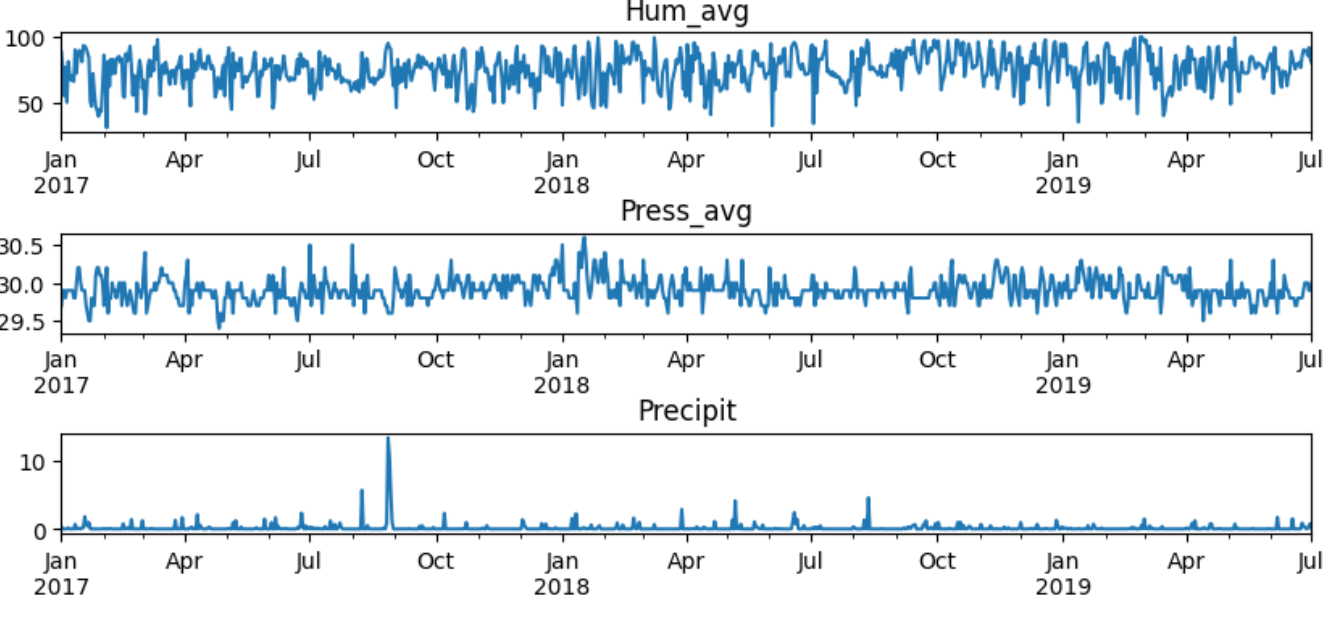 |
|---|
-
칼럼들의 정상성을 확인해보았을 때, 습도 칼럼을 제외하고는 모두 정상성을 갖고 있었다.

-
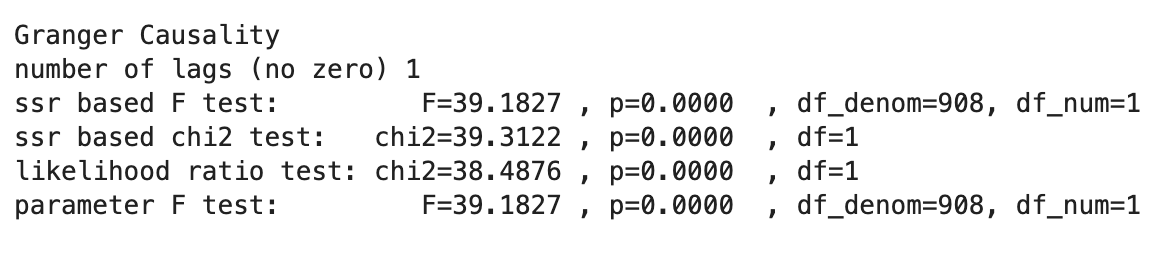
전력소비량에 대해 각 칼럼의 Granger Causality Test를 진행해보았다.
이때 Granger Causality는 x와 y 두 시계열 데이터가 주어졌을 때, y를 예측하는데 x의 과거 데이터가 유용하게 사용된다면 둘 사이에 인과관계가 있다고 보는 방법이다.-
Temp_avg: 전력소비량과 인과관계가 있다고 볼 수 있다.
-
Dew_avg: 전력소비량과 인과관계가 있다고 볼 수 있다.

-
Press_avg: 전력소비량과 인과관계가 있다고 볼 수 있다.

-
Wind_avg: 전력소비량과 인과관계가 없다고 볼 수 있다.

-
Hum_avg: 전력소비량과 인과관계가 없다고 볼 수 있다.

-
Precipit: 전력소비량과 인과관계가 없다고 볼 수 있다.

-
-
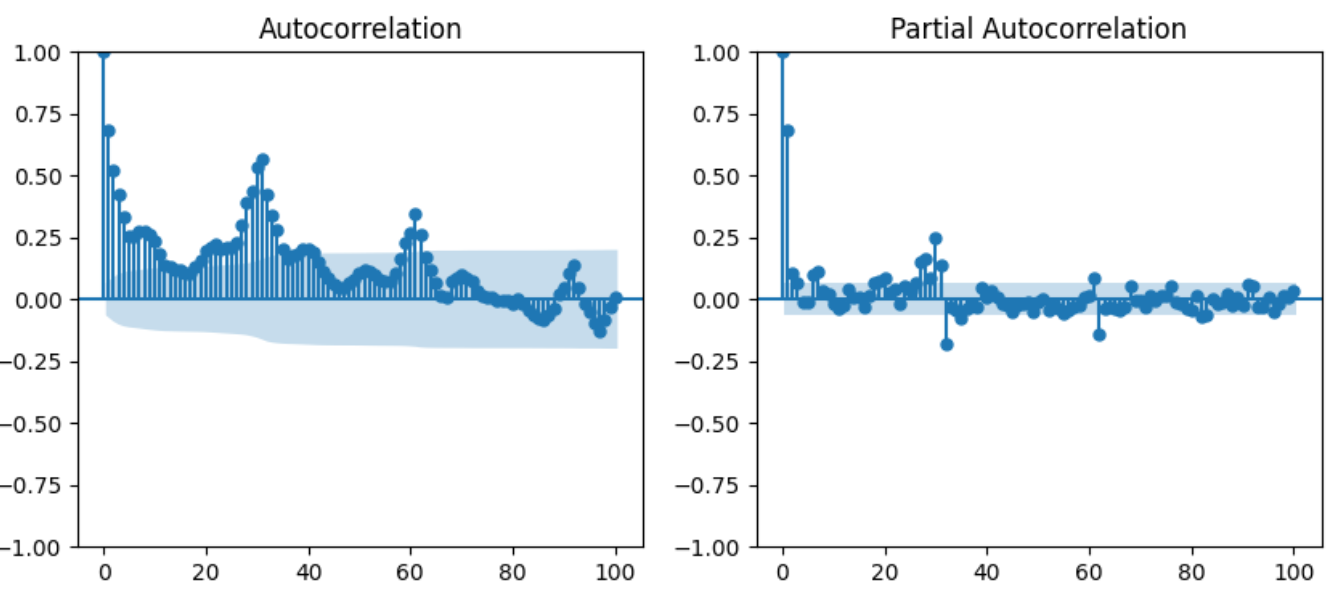
전력소비량의 계절성을 확인해보았을 때 약 30일의 주기를 갖고 있었다.
🔨 Machine Learning
AR Model
- 실제 test set와 AR로 예측한 결과 그래프를 보면 뒤로 갈수록 예측 정확도가 크게 떨어지고 있었다.
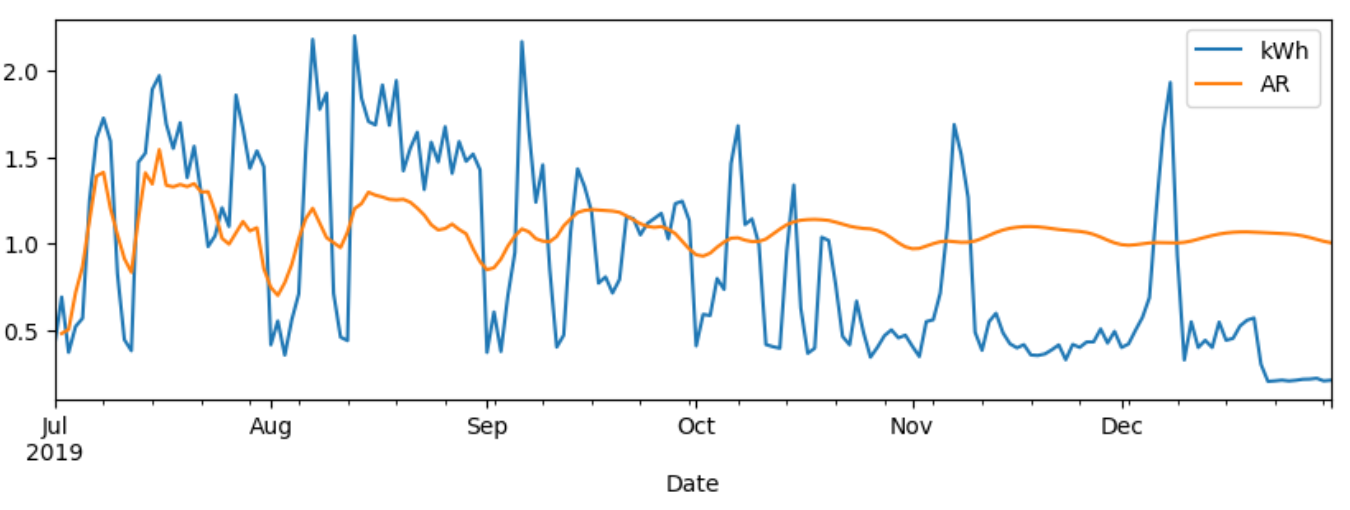
- RMSE score는 아래와 같았다.

VAR Model
- [Temp_avg]
- Temp_avg만 넣어 VAR 모델을 학습시켰을 때는 AR 모델의 예측 결과와 크게 다르지 않은 예측 정확도를 보였다.
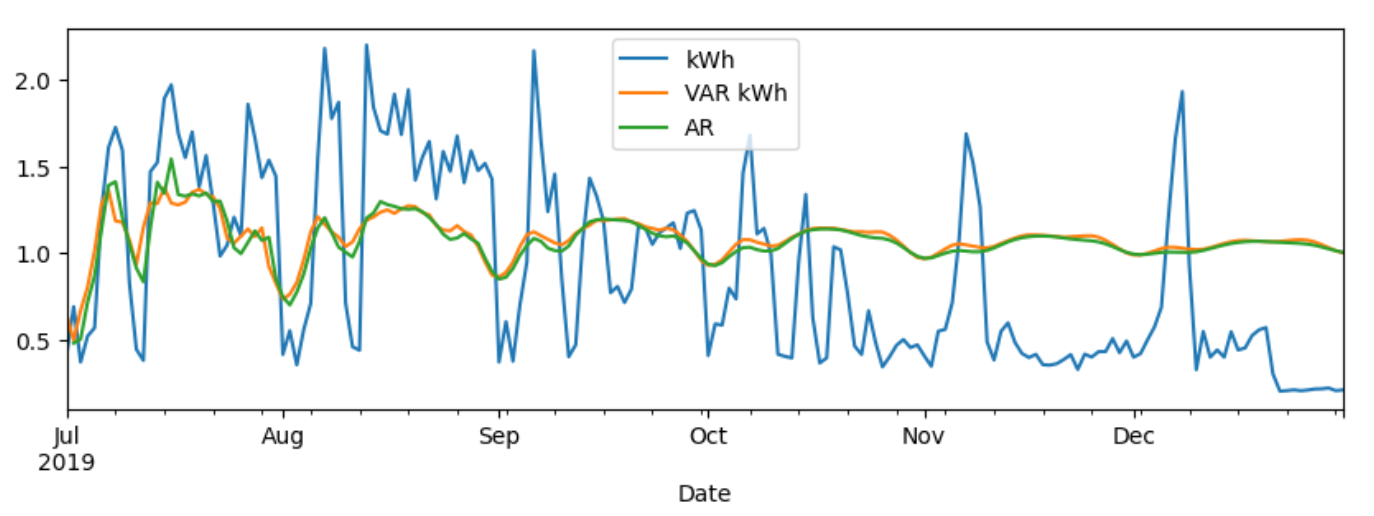
- AR 모델에 비해 train set의 rmse는 조금 낮아졌지만, test set의 rmse는 오히려 조금 높아졌다.
- Temp_avg만 넣어 VAR 모델을 학습시켰을 때는 AR 모델의 예측 결과와 크게 다르지 않은 예측 정확도를 보였다.
| [AR] | [VAR/Temp] |
|---|
- [Temp_avg, Dew_avg, Press_avg]
- 위에서 전력소비량과 인과관계를 갖는다고 나온 모든 칼럼을 넣고 VAR 모델을 학습시킨 결과 AR 모델에 비해 향샹된 예측 정확도를 보였다.
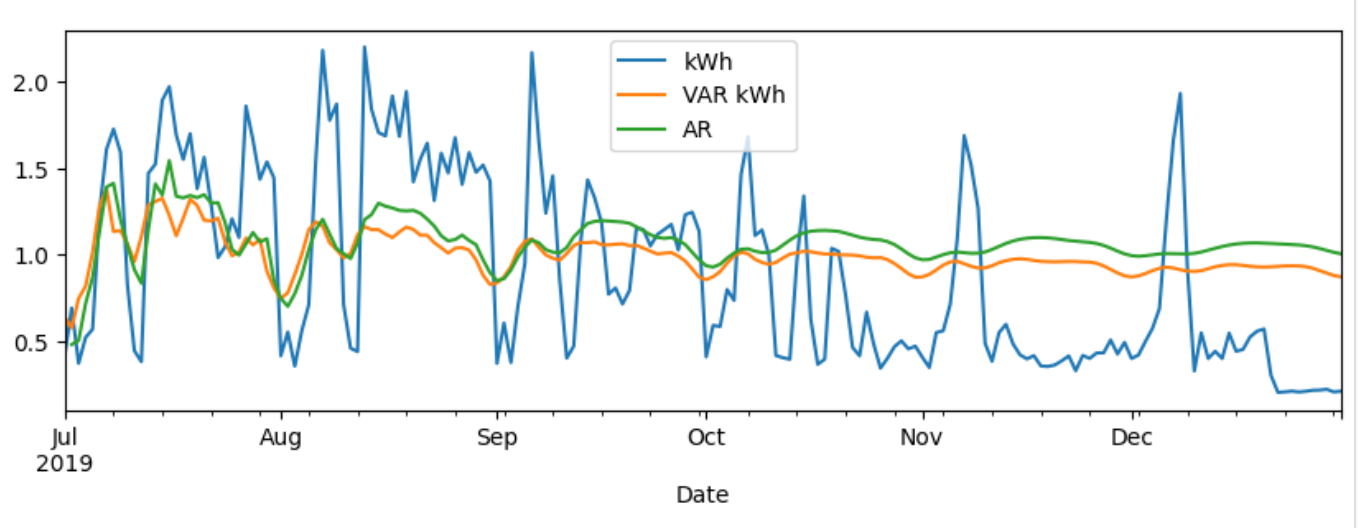
- 실제로 rmse가 AR 모델에 비해 낮아진 것을 확인할 수 있다.
- 위에서 전력소비량과 인과관계를 갖는다고 나온 모든 칼럼을 넣고 VAR 모델을 학습시킨 결과 AR 모델에 비해 향샹된 예측 정확도를 보였다.
| [AR] | [VAR/Temp_avg, Dew_avg, Press_avg] |
|---|
SARIMA
- 일반 SARIMA를 사용하여 test set과 예측 결과 그래프를 그려보았을 때 스래프 상에서는 위의 AR, VAR 모델에 비해 정확도가 높아보였다.
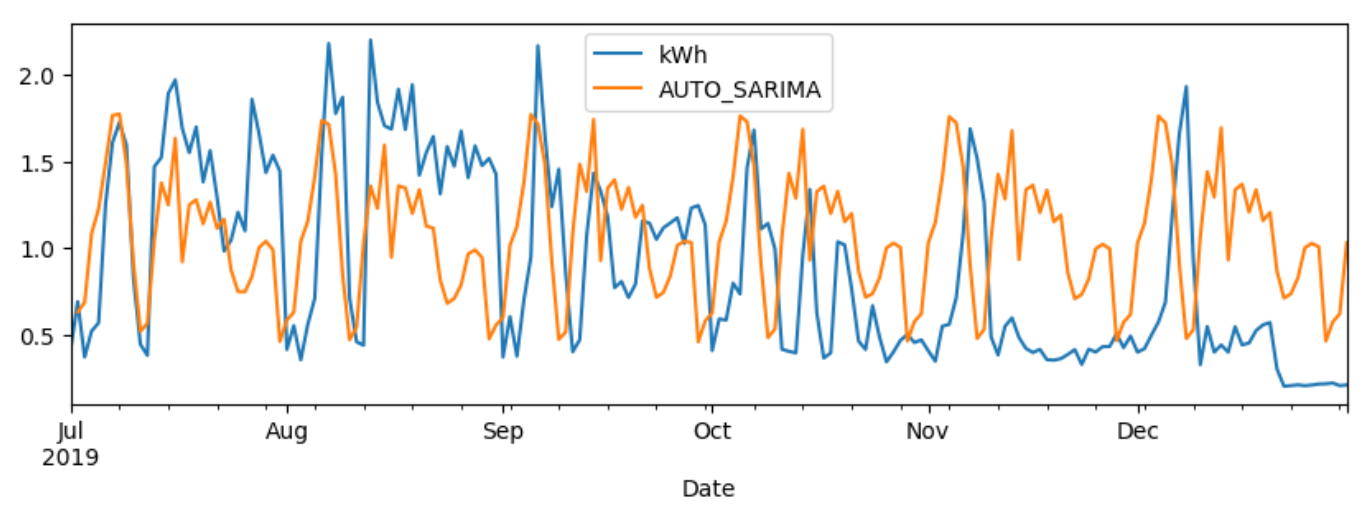
- 그러나 rmse 값을 확인해보니 위의 모델들 중 가장 형편없는 수치가 나왔다.

SARIMAX
-
[Temp_avg, Dew_avg, Press_avg] 칼럼을 모두 넣어 SARIMAX 모델을 학습시킨 결과 그래프이다. 일반 SARIMA 보다 예측 정확도가 높아보였다.
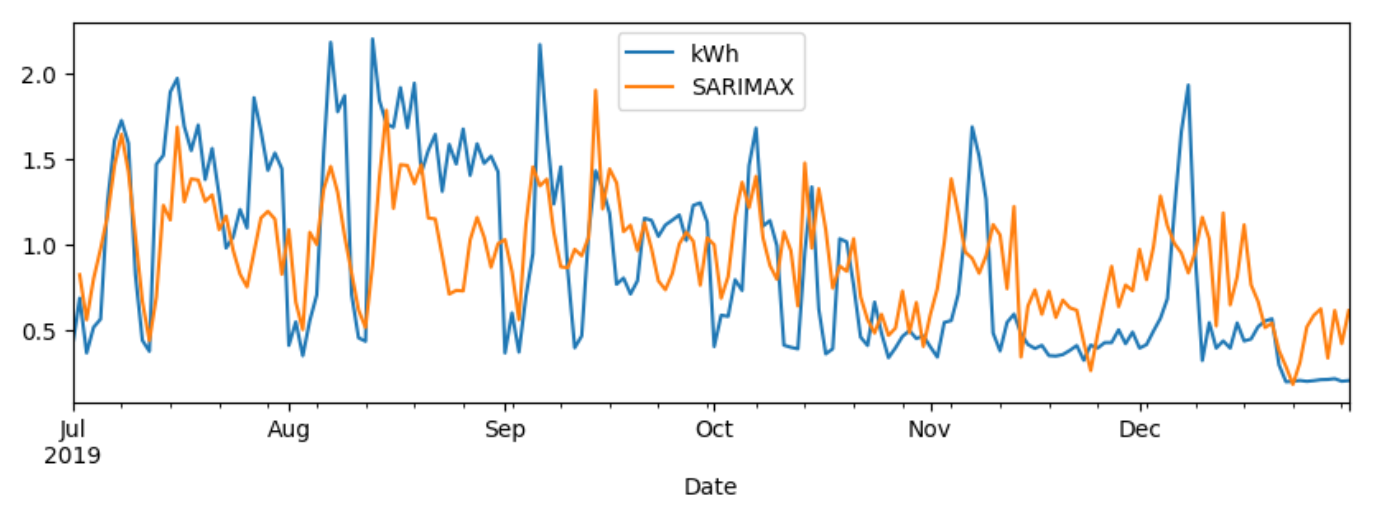
-
실제로 test set의 rmse 값도 모델들 중 가장 낮게 나왔다.
그러나 이상하게 train set의 rmse 값이 크게 나왔다.

-
train_set의 그래프를 확인해보았더니 1월 한달간의 예측 데이터가 이상하게 나타났다.
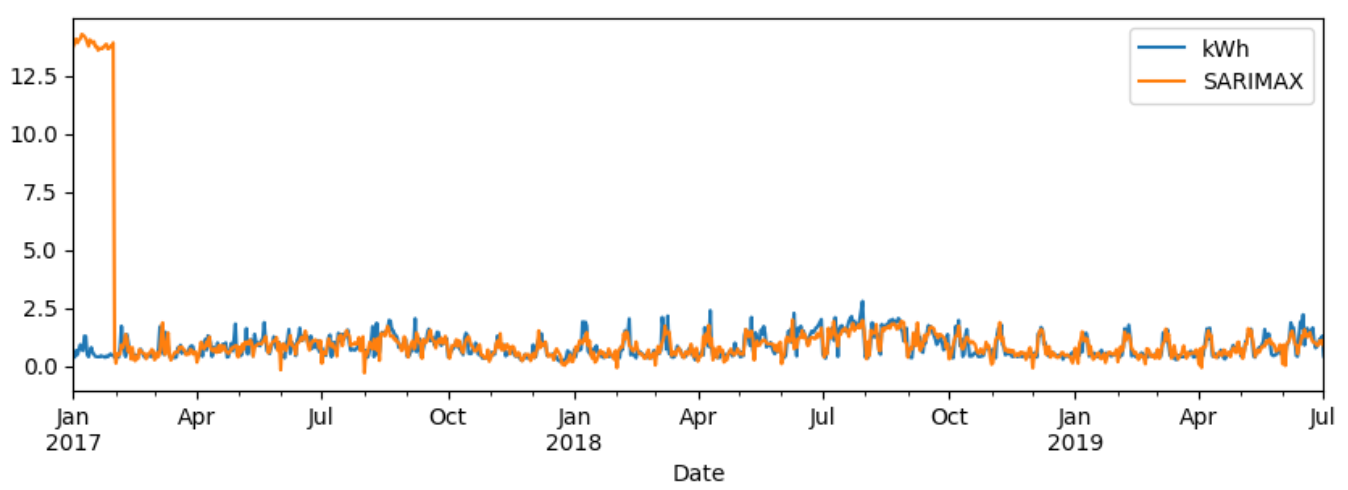
-> 따라서 시작 한달 정도의 데이터를 제외하고 rmse값을 확인해보니 위의 모델들과 크게 차이나지 않는 수치가 나왔다.
아마 자동으로 찾아넣은 최적의 파라미터에 문제가 있었던 것 같다.
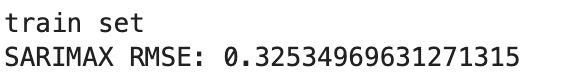
💡 Insight
- SARIMA 모델이 가장 성능이 좋았지만 VAR도 꽤나 좋은 성능을 보여주었다.
따리서 변수 간의 관계를 분석하고 예측을 수행하고자 하는 경우에는 VAR 모델이 유용하고, 단일 시계열 변수의 예측에 더 초점을 둔 경우에는 SARIMAX 모델이 적합하기 때문에 용도에 따라 선택해서 사용하면 될 것 같다.
