
💻 프로젝트 소개
- 이번 프로젝트에서는 박스오피스의 영화관련 데이터를 이용하여 다양한 기법의 머신러닝을 학습시켜본 뒤 가장 정확도가 높은 모델을 채택하여 해당 모델을 기반으로 개봉 전 영화 관객수를 예측해주는 웹어플리케이션을 개발했다.
이때 웹어플리케이션 사용자 타겟은 일반인이 아닌 영화 투자자들과 영화 관계자들이었다.
따라서 웹어플리케이션의 예측결과를 이용하여 해당 영화에 투자할 것인지, 출연진으로 누구를 선택할 것인지 등의 결정에 기반이 될 수 있도록 만들었다.
📁 데이터셋
[데이터 수집]
-
데이터는 영화진흥위원회(Kofic) API 크롤링과 네이버 스크래핑을 이용하여 수집하였다.
Kofic의 데이터 중 전국 집계가 가능해진 2004년을 기준으로 2004년 부터 데이터 수집을 시작한 2023년 07월 12일까지의 데이터를 사용했다. -
Kofic: 제목, 개봉일, 관객수, 스크린수, 배우, 장르, 등급, 국가, 감독
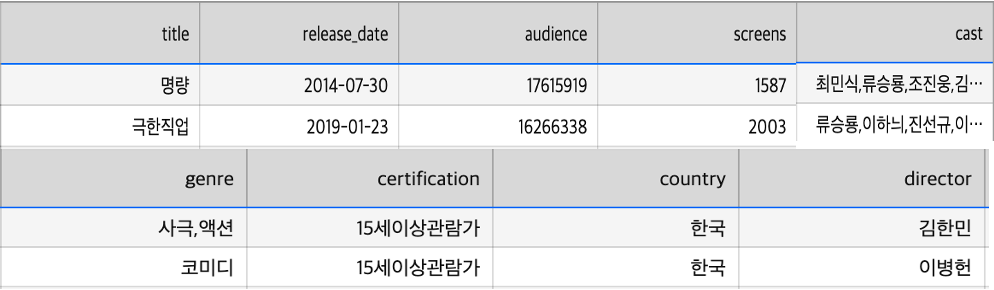
- 네이버: 러닝타임, 주연배우, 각본가, 원작자, 시리즈, 평점, 평점 참여자수
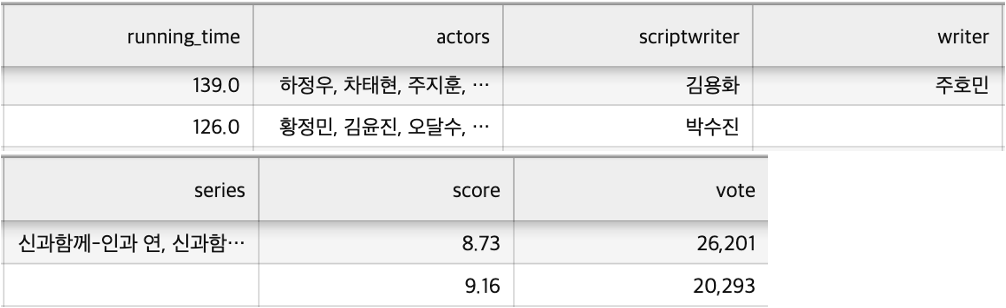
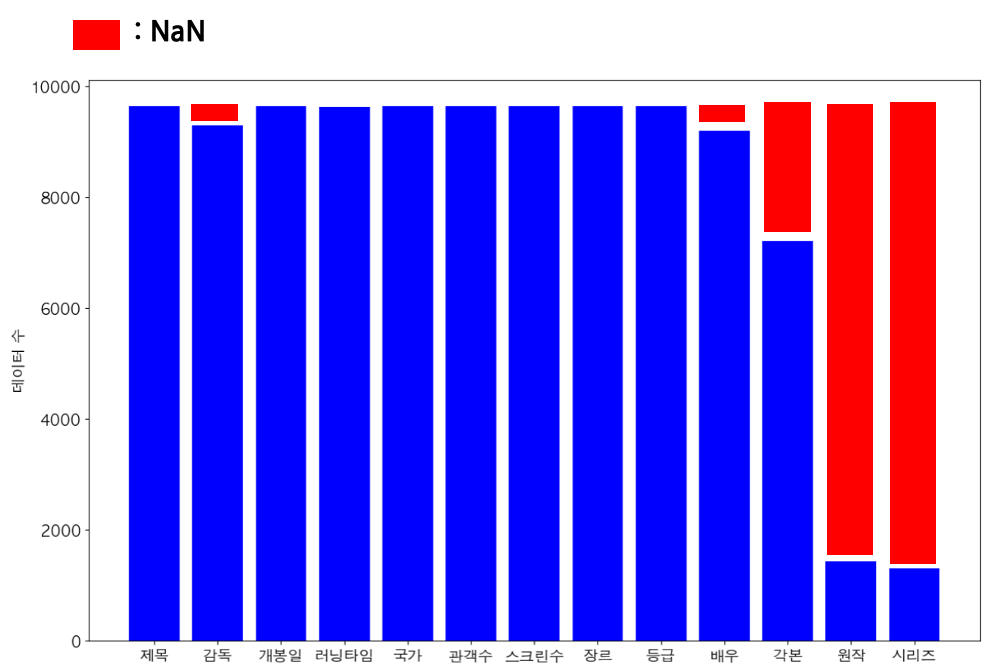
- 네이버에서 스크래핑한 평점과 평점 참여자수 데이터는 이미 데이터가 있는 영화의 관객수를 맞추는데는 긍정적인 영향을 주지만 프로젝트의 목표인 개봉전의 영화 관람객수를 예측하는데는 적합한 데이터가 아니라고 판단하여 총 13개의 칼럼으로 구성된 데이터셋을 만들게 되었다.
이때 감독, 배우, 각본, 원작, 시리즈에 결측치가 있었다.
[EDA]
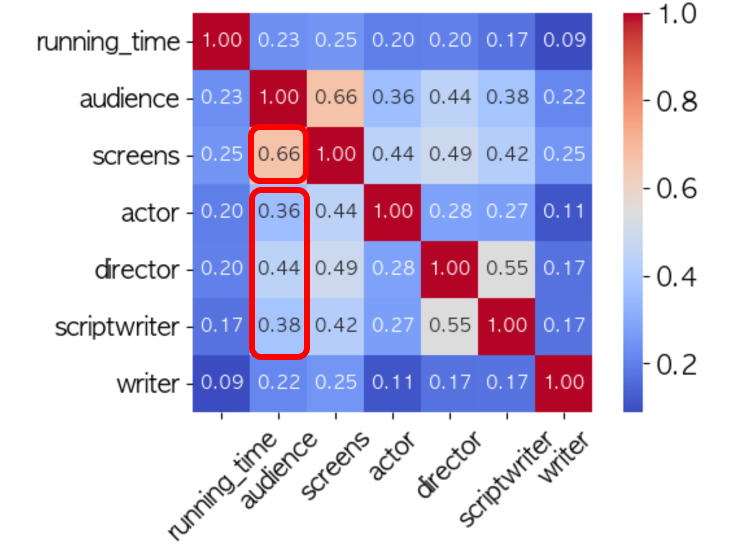
- 관객수와 가장 상관계수가 높은 항목은 스크린수(상영극장수)였고, 감독, 각본가, 배우 순으로 상관계수가 높았다.
- 스크린수 분포 그래프를 보면 중앙값은 54, 평균은 180으로 데이터셋의 영화들 중 절반은 54개 이하의 극장에서 상영되었음을 알 수 있다.
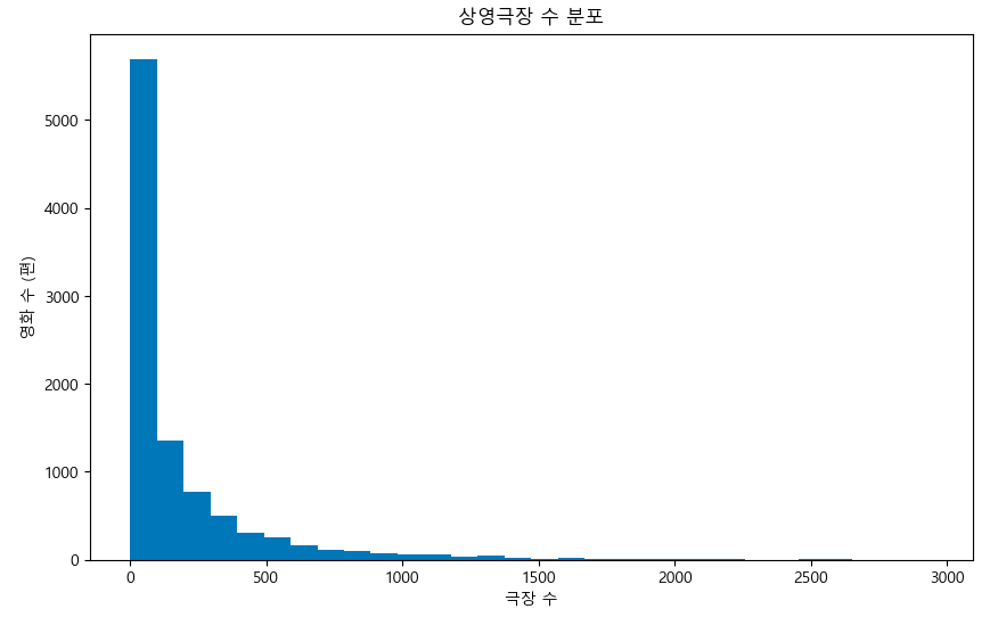
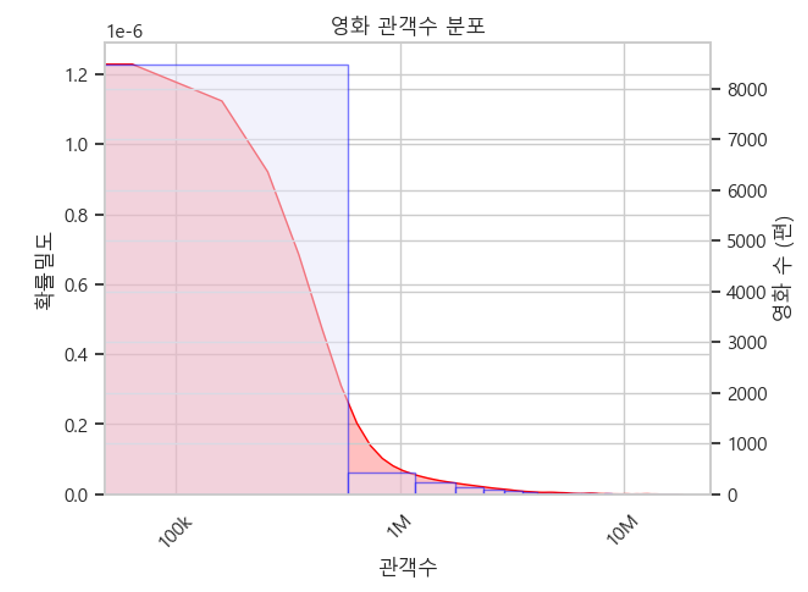
- 관객수 분포 그래프를 보면 관객수 중앙값은 9,815명으로 데이터셋 영화의 절반 이상이 관객수가 1만명 밑에 존재하고 있다.
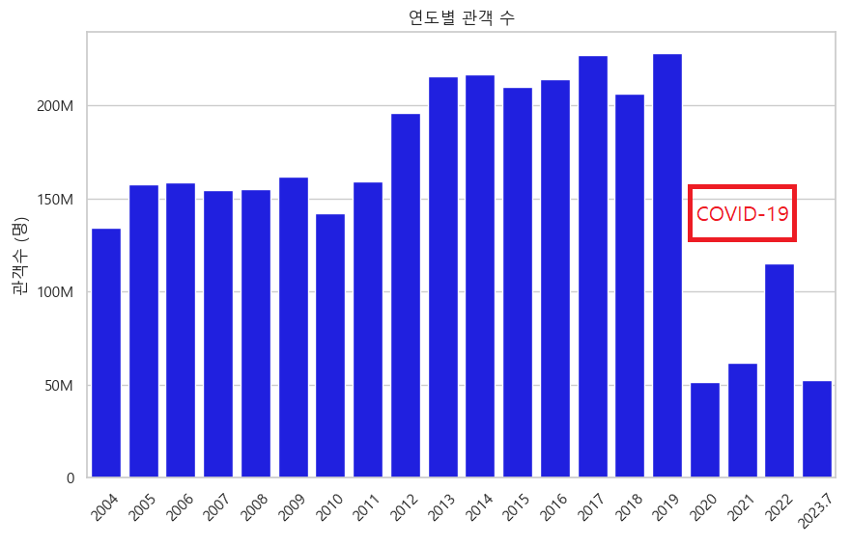
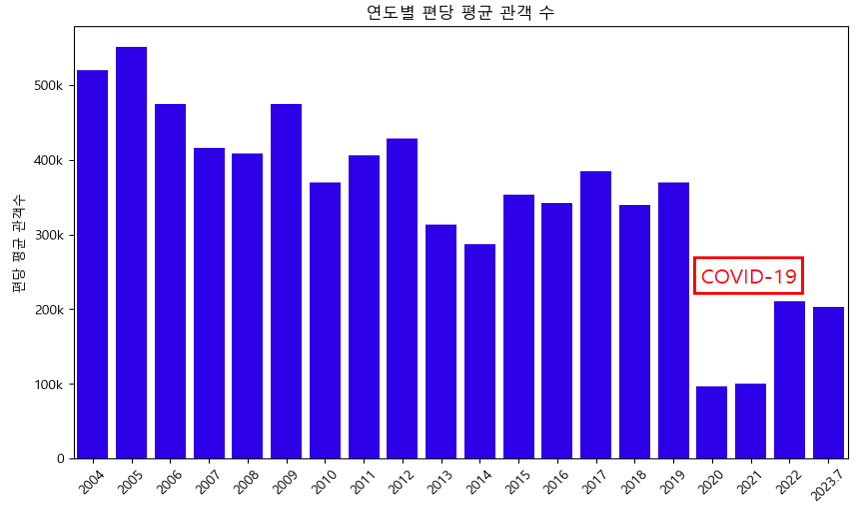
- 연도별 관객수 그래프와 연도별 편당 평균 관객수 그래프를 보면 코로나 19로 인해 2020.03.22~2022.04.24 사이의 사회적 거리두기와 다중이용시설 집합금지 조치로 인해 영화 관객수가 급감했다.
 |  |
|---|
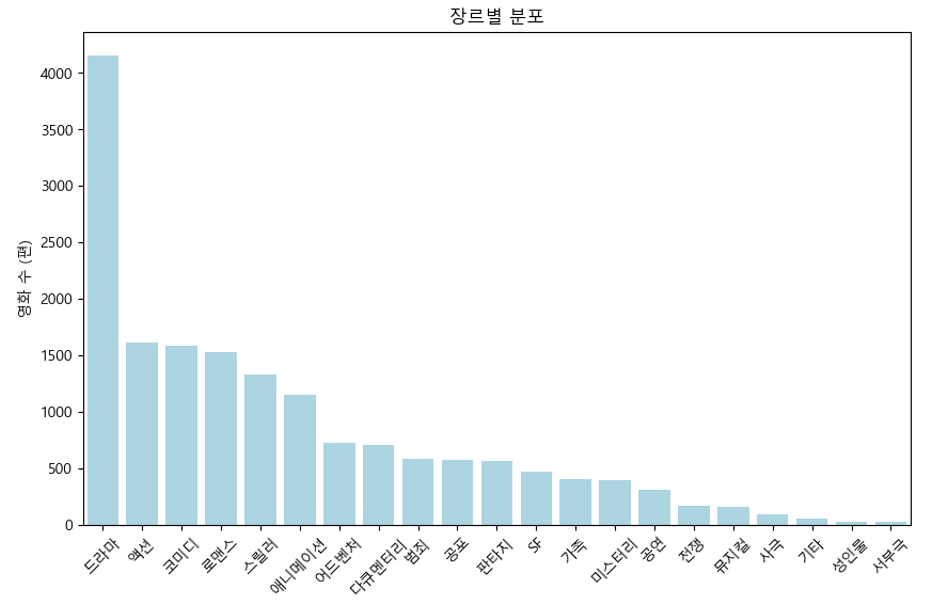
- 장르 분포를 보면 드라마가 가장 많았고 액션, 코미디, 로맨스 순으로 많았다.
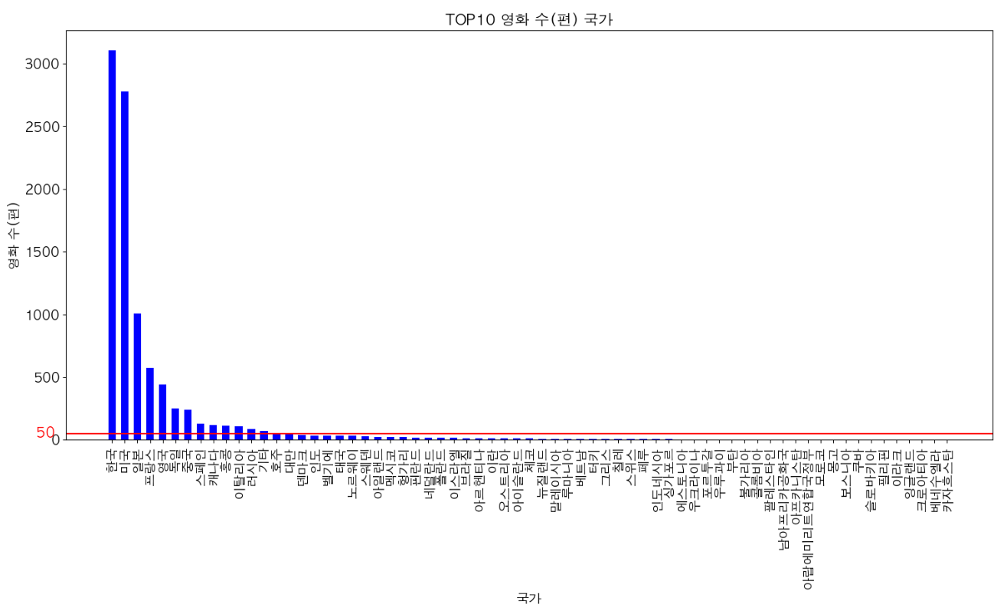
- 데이터셋에 총 67개 국가의 영화가 있었고, 대부분의 국가가 50편보다 적은 수의 영화 수를 갖고 있었다.
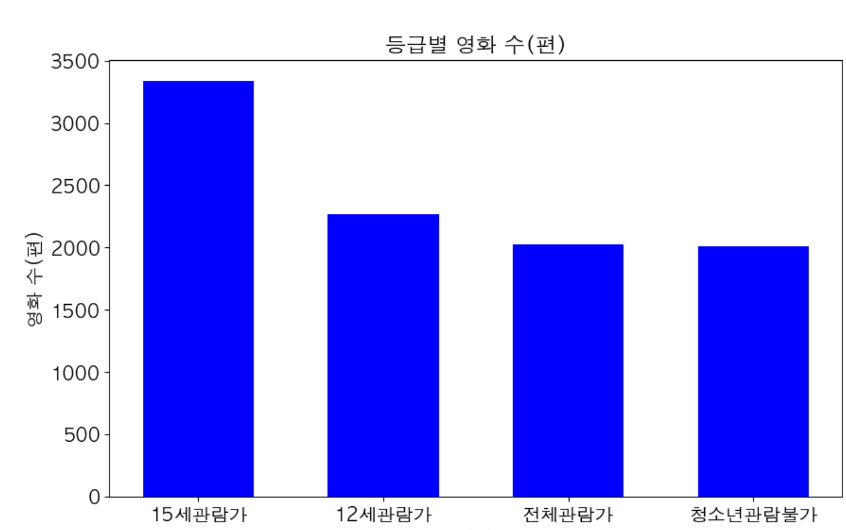
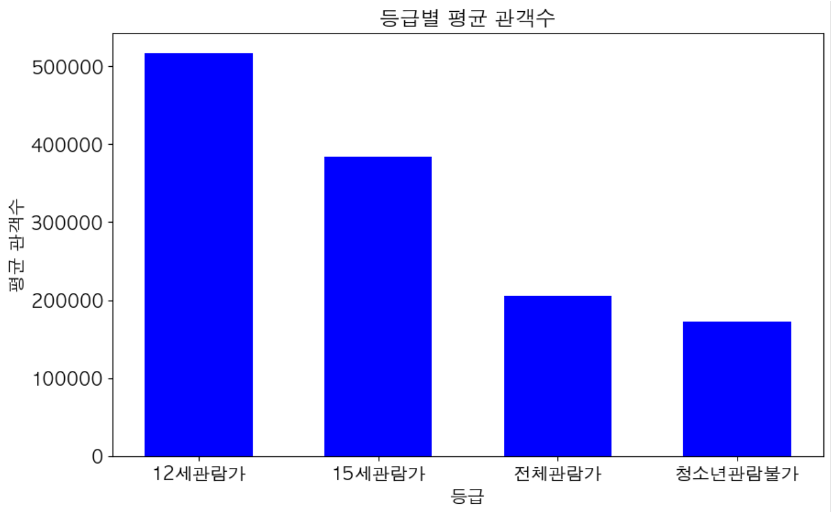
- 등급별 평균 관객수를 보면 총 영화의 수는 15세 관람가가 가장 많았으나, 등급별 평균 관객수로 보면 12세 관람가가 가장 높았다.
 |  |
|---|
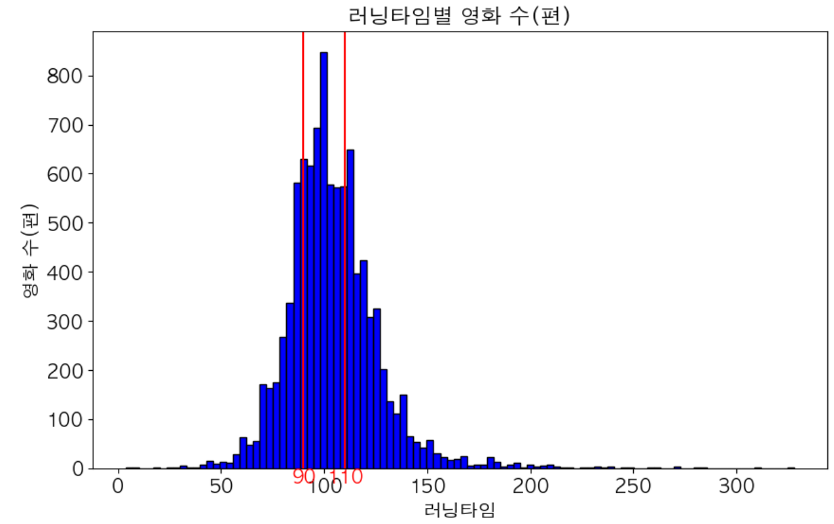
- 러닝타임 분포를 보면 러닝타임이 90-110분 사이인 영화들이 많은 것을 확인할 수 있다.
🔨 전처리
[인코딩]
-
상영등급: 전체관람가, 12세관람가, 15세관람가, 18세 관람가 총 4개 나누어 원-핫 인코딩을 해주었다.
-
러닝타임: 90분 미만, 90-110분, 110분 초과 총 3개로 나누어 라벨 인코딩을 해주었다.
-
국가: 한국, [미국+캐나다], 일본, 유럽, [중국+대만+홍콩], 기타 총 6개로 나누어 원-핫 인코딩을 해주었다.
-
장르: 총 21종류가 있었고 모두 원-핫 인코딩을 해주었다.
-
시리즈: 시리즈물 여부로 원-핫 인코딩
[수치화]
-
감독, 배우, 각본가와 원작가 데이터를 수치화해주었다.
이때 해당 데이터의 값들이 시점 별로 달라지는 평균 관객수 값을 갖을 수 있도록 아래와 같이 수치화했다.
수치화 공식 = 직전까지 나온 영화의 총 관객수 ÷ 영화수 -
감독: 한 영화에 감독이 2명 이상인 경우 유니크한 1명의 감독으로 취급했다.
-
배우: 데이터셋에 최소 4편 이상 출현 배우들만 남긴 후 영화 한 편당 최대 3명까지 수치화된 배우의 값을 더해주었다.
-> 결과
Before | After |
|---|
[결측치]
-
감독, 배우, 각본가: 영화 관객수 중앙값이 9,815로 대체하였다.
-
원작가: 원작가가 없는 영화에 대해서 0으로 대체해주었다.(원작가가 있는 영화를 프리미엄으로 봄)
[코로나 19 기간 보정]
- 코로나19 집합금지 기간이었던 2020.03.22~2022.04.24에 급감한 관객수를 보정하기 위해 코로나 19기간과 나머지 기간의 편당 평균 관객수 차이인 4.3배를 코로나기간에 속하는 영화 관객수에 곱해주었다.
📝 Machine Learning
[R2 Score 비교]
- XGboost: 0.574
- Random Forest Regressor: 0.570
- Gradient Boosting: 0.564
- Lasso: 0.523
-> 이중 Random Forest Regressor가 가장 안정적이고 현식적인 예상치를 보여주었기 때문에 채택했다.
🎉 Result
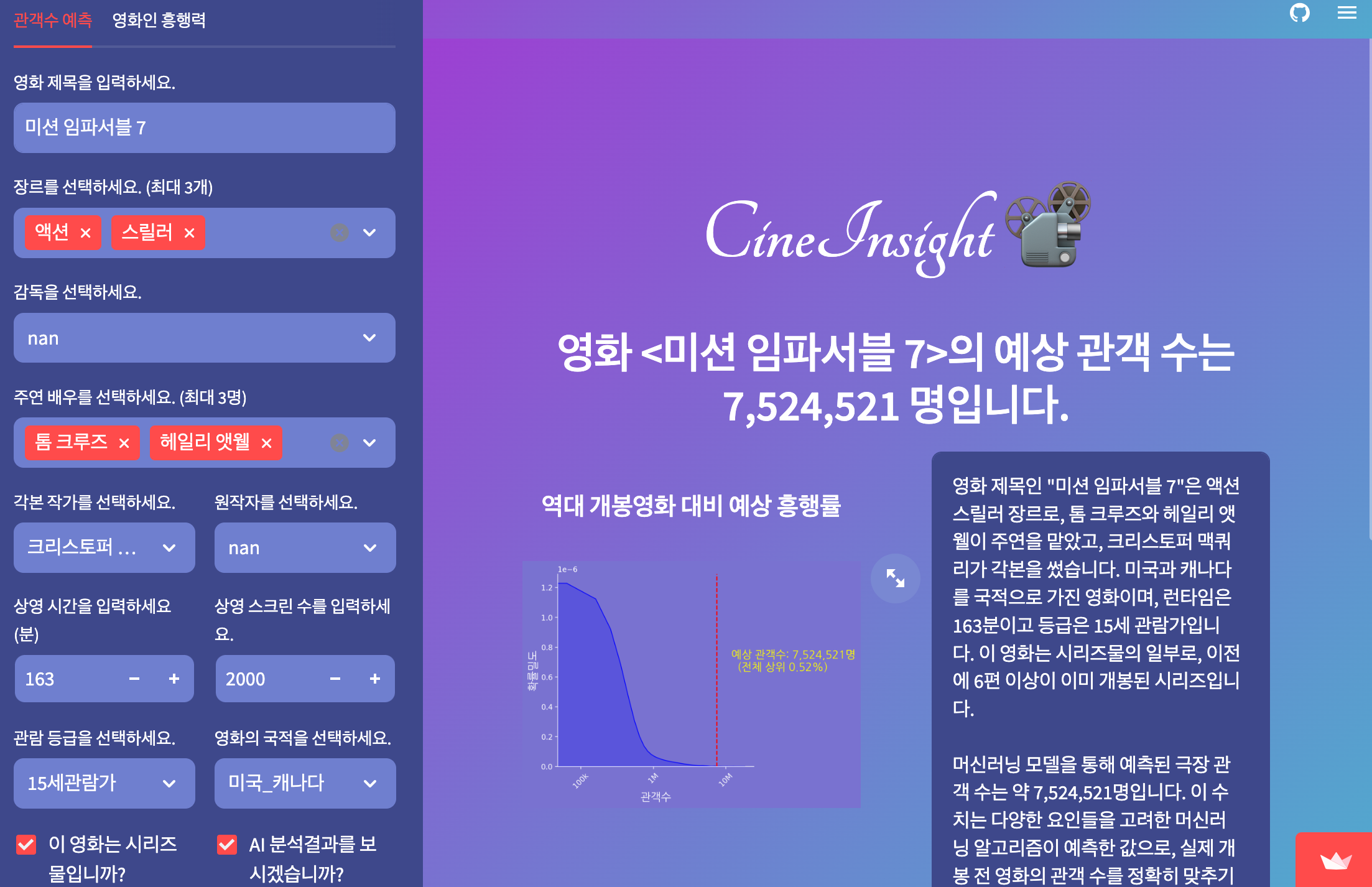
- 위의 ML으로 학습한 후 데이터를 피클로 저장하여 관객수를 예측해주는 "CineInsight"라는 이름의 웹어플리케이션을 개발했다.
Streamlit address:
https://movie-audience-predictor.streamlit.app/
-> 아래와 같이 제목, 장르, 감독, 배우, 각본가, 원작자, 상영시간, 스크린수, 상영등급, 국적, 시리즈물여부를 입력하면 예상관객수 값과 어느정도의 흥행력을 갖고 있는지 그래프를 보여준다.
또한 AI 분석에 체크를 하면 해당 영화 정보에대해 AI가 해석해서 반환해준다.
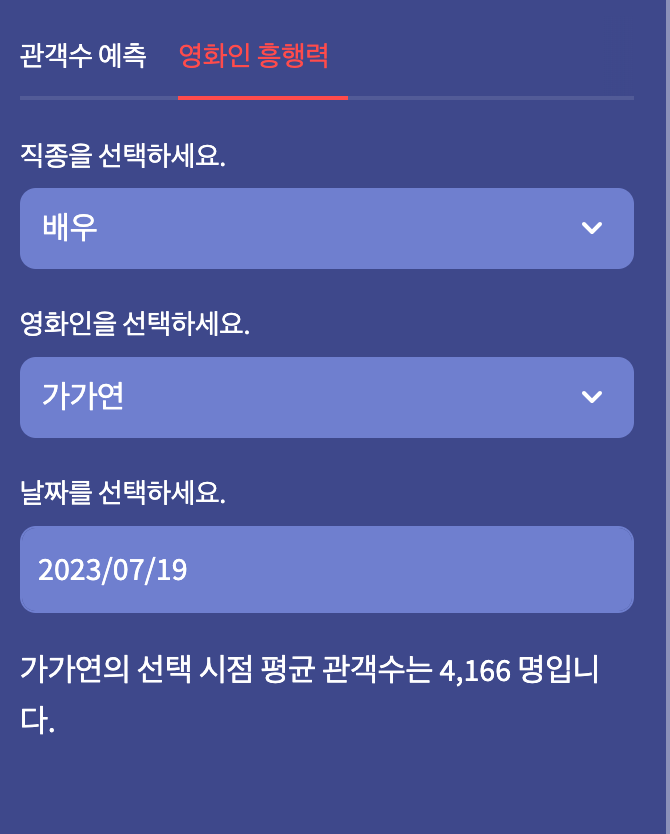
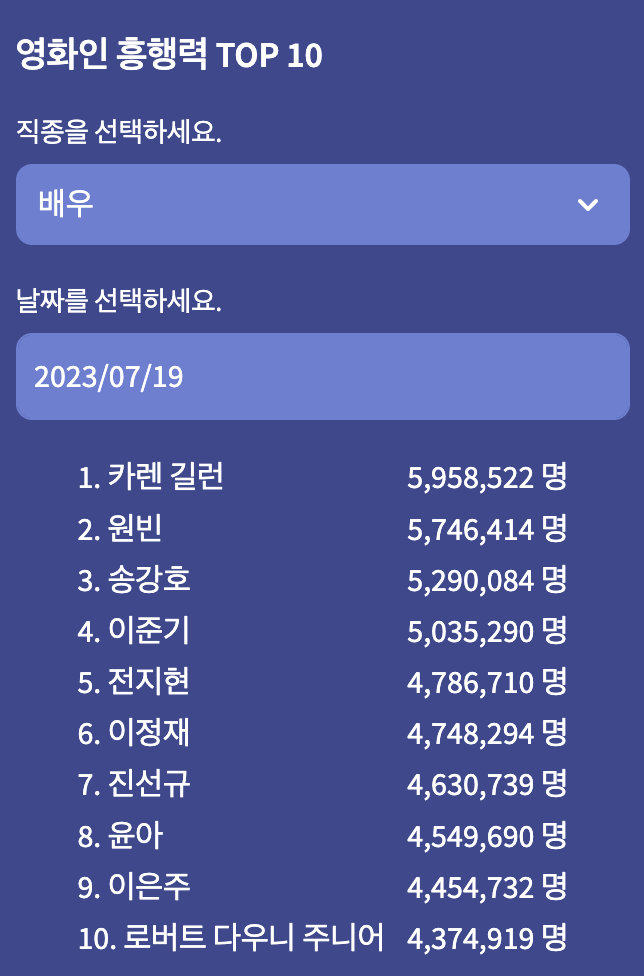
- 인물을 검색하면 원하는 시점에서의 해당 인물의 흥행력도 조회가 가능하며, 원하는 시점에서 흥행력 TOP10 순위도 조회가 가능하다.
 |  |
|---|
💡 insight
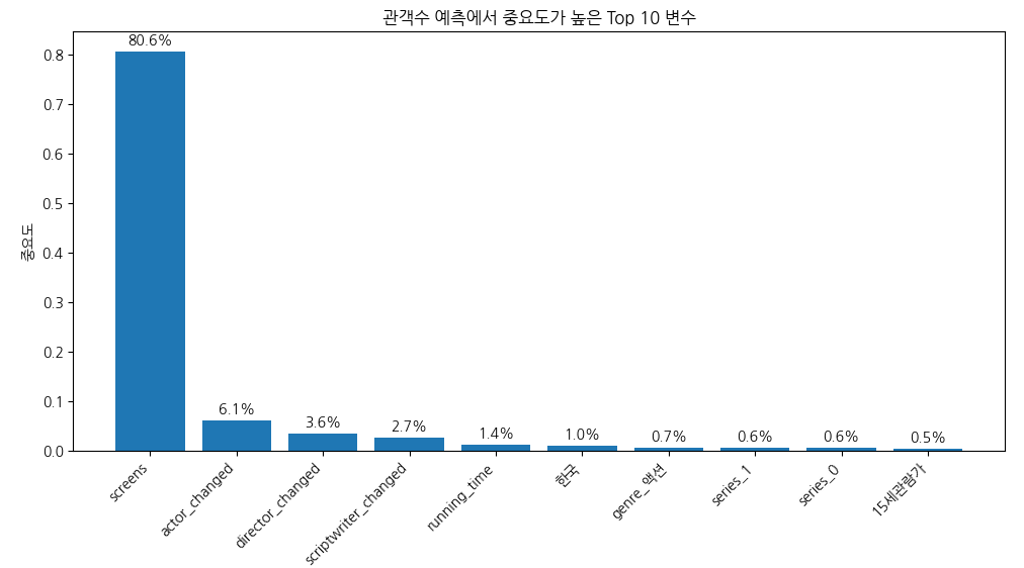
- 관객수를 예측하는데 가장 영향력이 높은 항목은 스크린수였다.
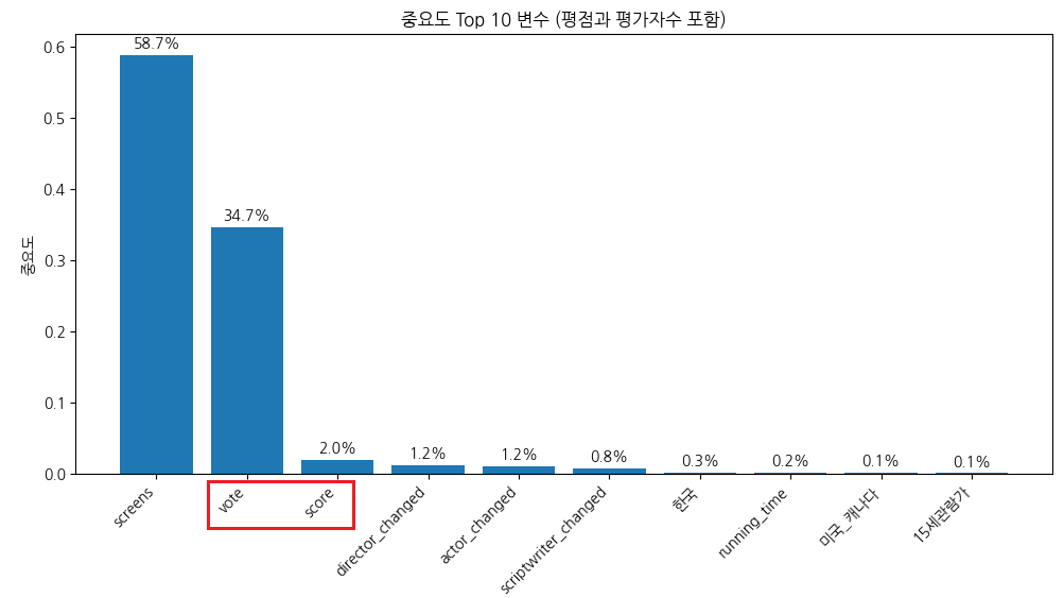
- 관객수를 예측하는 머신러닝 학습에 넣으면 안된다고 판단하여 제거했던 평점, 평가자수 데이터를 넣으면 R2 Score가 0.723까지 상승하며 평가자수가 2번째로 영향력이 높은 항목인것을 확인할 수 있다.
📍 한계점
-
항상 정제되어 있던 데이터셋만을 다루다가 처음으로 현실 데이터를 다루어보았는데, 데이터셋 모으는 것도 정리하는 것 모두 예상했던 것보다 어렵다는 것을 느꼈다.
-
머신러닝 모델을 학습시킴에 있어 영향력이 큰 요소가 스크린수 밖에 없었기 때문에 예측 정확도로 최대 57% 정도에 그치게 되었다.
개봉전 영화의 소셜미디어 노출 횟수 등 관객수 예측에 있어 영향력이 클 것 같은 요소들이 있었다면 보다 정확도가 높은 모델을 만들 수 있었을 것 같아 아쉬웠다.

소중한 정보 감사드립니다!