
데이터 소개
- 다양한 다이아몬드의 특징을 이용하여 다이아몬드의 가격을 예상하는 데이터셋이다.
이를 이용하여 다이아몬드의 각 특징들이 가격과 어떤 관계를 갖는지 분석해보려고 한다.
데이터 전처리 방법
[데이터 구성]
- price: 가격
carat: 무게
cut: 커팃의 퀄리티
color: 색
clarity: 투명도(I1 (worst), SI2, SI1, VS2, VS1, VVS2, VVS1, IF (best))
x: 길이
y: 너비
z: 깊이
table: 다이아몬드 상단의 너비
총 [53940 rows × 9 columns]로 구성.
[전처리]
- 가장 먼저 컬럼별 데이터 타입과 결측 데이터 양을 확인해 보았다.
그 결과 carat, color, table 칼럼에 결측치가 있는 것을 확인했다.
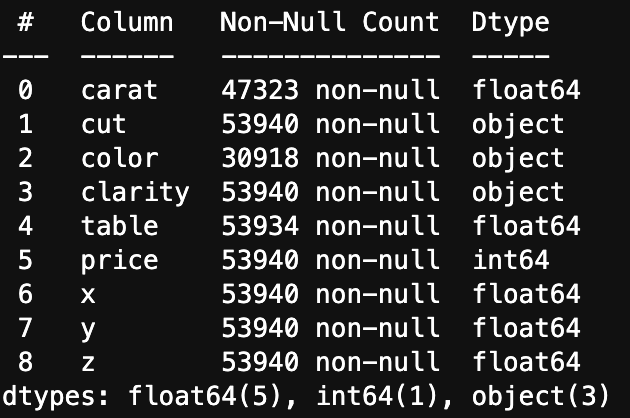
-
결측 데이터가 2만개가 넘고 가격과 다른 데이터와 크게 연관이 없어보이는 color 컬럼을 삭제했다.
-
깊이를 나타내는 데이터인 depth를 z/mean(x,y)를 이용하여 구해준 뒤, depth 칼럼에 넣어주었다.
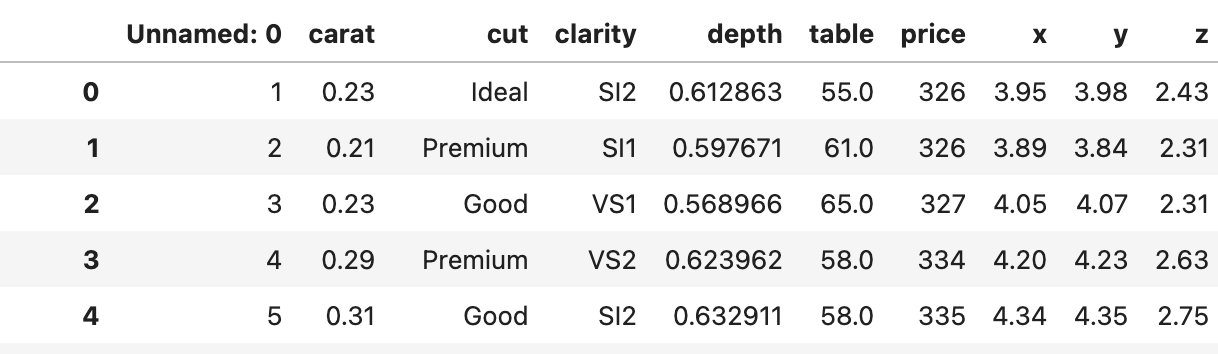
- table 칼럼의 결측치가 6개 존재했는데, 결측치의 수가 6개로 전체 데이터셋에 비해 극소량이며 다른 요소와의 상관계수가 모두 낮은 편이었기 때문에 table의 평균치로 대치했다.
-
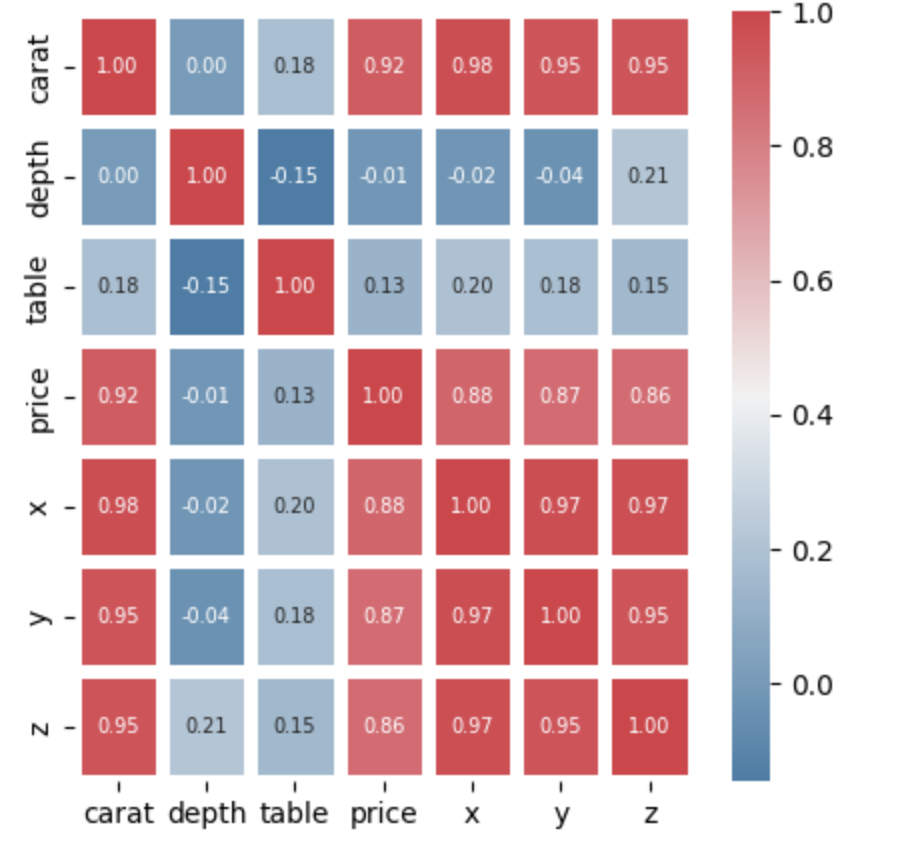
가장 결측치 처리에 고민이 많았던 칼럼이 carat이었다. 결측치의 수가 적지 않았을 뿐만 아니라 위의 상관관계를 보면 가격과 가장 관계성이 높은 데이터였기 때문이다. 따라서 가격을 기준으로 carat들의 평균을 모두 구하여 각 가격에 해당하는 carat의 무게를 넣어주었다.
-
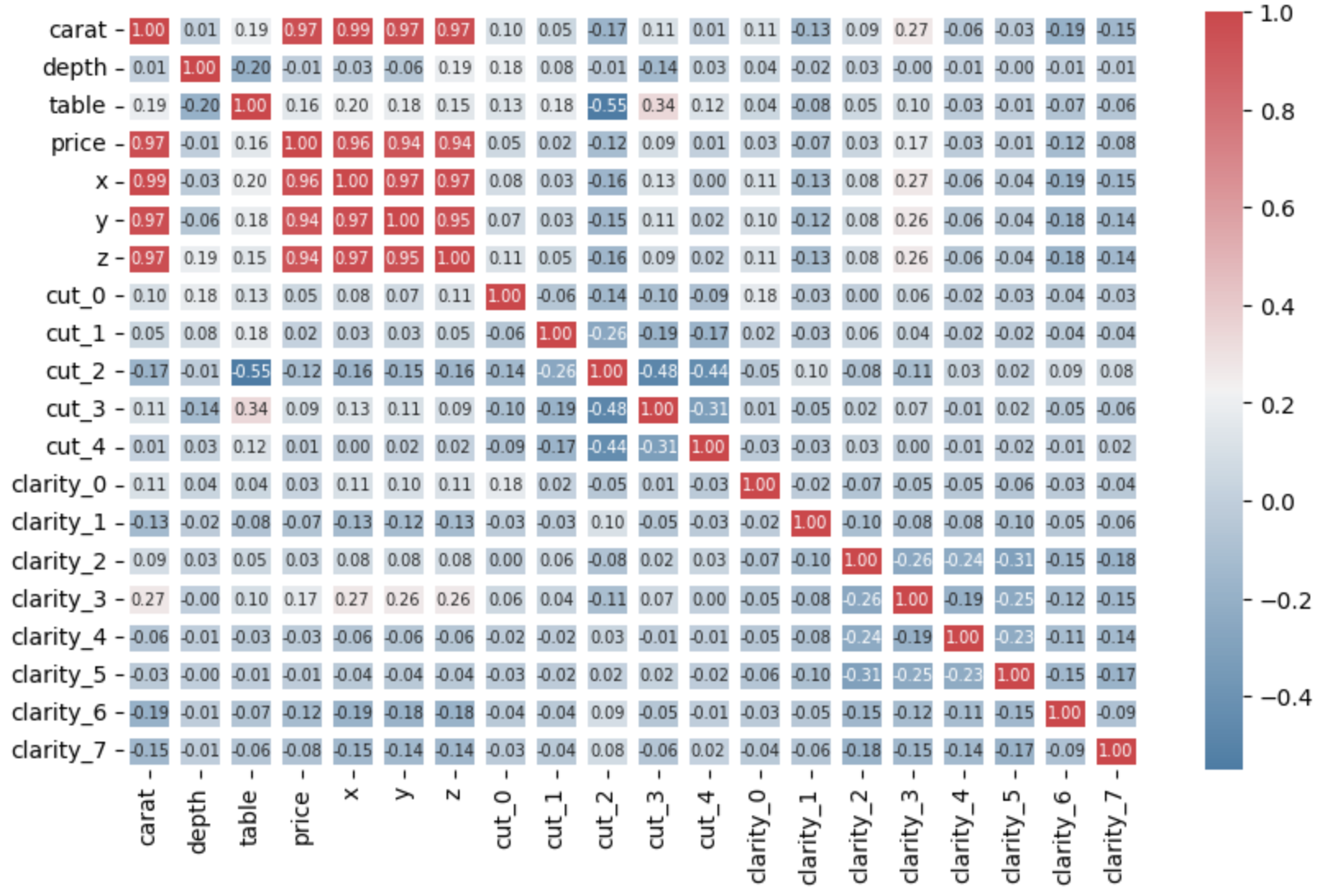
카테고리형 칼럼인 cut과 clarity는 LabelEncoder를 이용하여 더미 변수로 변경해준뒤, 나머지 연속형 변수는 StandardScaler, MinMaxScaler를 사용하여 조정해주었다.
데이터 분석 및 결과
- 아래의 피어슨 상관계수 히트맵과 같이 다이아몬드의 가격에 강력한 영향을 미치는 요소는 carat, x, y, z라고 할 수 있으며, 이들과의 관계가 양의 상관관계인 것으로 보아 다이아몬드의 무게가 무겁고 크기가 클수록 가격이 높아짐을 알 수 있었다.
또한 분석전에는 다이아몬드의 가격을 정하는데에 다이아몬드의 색이나 컷팅의 정교함이 크게 영향을 줄 것이라고 생각했는데, 분석결과 거의 상관이 없음을 알게된 점이 흥미로웠다.
한계점 및 개선 방향
- 데이터들을 이용하여 파생변수를 만들어 carat을 예측할 방법을 생각하지 못한 것이 아쉽다. 파생변수를 만들지 않고 주어진 데이터만을 이용하여 carat의 결측치를 처리하려다 보니 가격 데이터를 이용해서 넣는 방법뿐이었다. x, y, z 칼럼을 이용하여 밀도를 구해서 carat의 결측치를 처리했다면 실제 값에 가까운 carat 데이터를 예측할 수 있었을 것 같다.

💻🐜💡