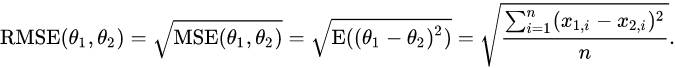참고 사이트
- 강의 사이트
프로그래머를 위한 머신러닝
⚠ 위의 강의에서는 fast.ai 0.7.0 을 이용하는 강의입니다.
설정하다 실패해 Kaggle Notebook을 복사해 실습했습니다.
- 데이터 사이트
Blue Book for Bulldozers
정리
'Blue Book for Bulldozers'는 중장비의 경매 판매 가격을 예측하는 데이터이다.
또한 이 kaggle의 평가 지표는 실제 경매 가격과 예측 경매 가격 사이의 RMSLE(루트 평균 제곱 로그 오차)이다.
RMSLE
root mean squared log error
RMSE 는 예측값과 실제값의 차(더하기/빼기) 각각을 제곱(square)한 값을 평균(mean)을 내서, 루트(root)를 씌운 것이다.
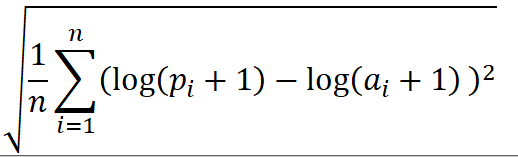
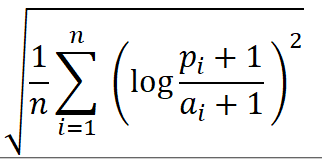
출처: 알락블록
판매 가격에 log를 취하는 함수 :
df_raw.SalePrice = np.log(df_raw.SalePrice)
1. 초기 과정
bulldozer 데이터에는 범주형 데이터와 연속적 데이터가 혼합이 되어있다. 범주형 구성을 위해 전체 날짜 시간에서 세분화 필드로 추출해야 한다.
add_datepart(df_raw, 'saledate')- 함수 실행 결과
(이때 A는 컬럼 명)
범주형 데이터는 문자열로 저장되어 숫자로 코드화가 필요하다. 그러기 위해서 pandas 범주로 변환해야 한다.AYear AMonth AWeek ADay ADayofweek ADayofyear AIs_month_end AIs_month_start AIs_quarter_end AIs_quarter_start AIs_year_end AIs_year_start AElapsed 0 2000 3 10 11 5 71 False False False False False False 952732800 1 2000 3 10 12 6 72 False False False False False False 952819200 2 2000 3 11 13 0 73 False False False False False False 952905600
다음과 같이 범주형 변수에 순서를 지정할 수 있다.train_cats(df_raw)df_raw.UsageBand.cat.set_categories(['High', 'Medium', 'Low'], ordered=True, inplace=True)
일반적으로, pandas는 내부적으로 정수형 데이터로 다루면서 화면에는 문자열 데이터를 계속 표시할 것입니다. 선택적으로, 문자열 데이터를 정수형 데이터로 바꿀 수 있다.
df_raw.UsageBand = df_raw.UsageBand.cat.codes지금 데이터에 NAN값이 있으므로 변환이 필요하다.
display_all(df_raw.isnull().sum().sort_index()/len(df_raw))- df_raw.isnull() : 값의 NAN인지 아닌지 boolean 값으로 변환한다. NAN일 경우 True
- df_raw.isnull().sum() : True일 경우 1이기 때문에 NaN의 개수 파악이 가능하다.
- df_raw.isnull().sum().sort_index() : 라벨 순으로 정렬 = 컬럼 명 순으로 정렬
2. 전처리
범주형 데이터를 숫자 코드로 바꾸고 NAN 값을 처리하여 종속 변수를 별도의 변수로 분할한다.
df, y, nas = proc_df(df_raw, 'SalePrice')proc_df
- proc_df는 데이터 프레임을 가져와서 반응 변수를 분할합니다.
- df를 완전히 숫자 데이터 프레임으로 변경합니다.
만약 모든 데이터를 사용한다면 overfitting이 발생할 가능성이 높다. 따라서 학습 세트와 검증 세트로 데이터를 나눈다.
def split_vals(a,n): return a[:n].copy(), a[n:].copy()
n_valid = 12000 # same as Kaggle's test set size
n_trn = len(df)-n_valid
raw_train, raw_valid = split_vals(df_raw, n_trn)
X_train, X_valid = split_vals(df, n_trn)
y_train, y_valid = split_vals(y, n_trn) # y는 saleprice array
X_train.shape, y_train.shape, X_valid.shape3. Random Forests
위에서 분리한 학습 세트와 검증 세트를 사용해 모델을 다시 사용해보자.
아래의 내용은 검증에 필요한 함수.
def rmse(x,y): return math.sqrt(((x-y)**2).mean())
def print_score(m):
res = [rmse(m.predict(X_train), y_train), rmse(m.predict(X_valid), y_valid),
m.score(X_train, y_train), m.score(X_valid, y_valid)]
if hasattr(m, 'oob_score_'): res.append(m.oob_score_)
print(res)실제 Random Forests 사용.
m = RandomForestRegressor(n_jobs=-1) # -1로 입력하면 회귀 기능은 각 CPU에 별도의 프로세스로 부여되어 분산 작업을 하게 된다. 이 옵션은 항상 켜두는 것이 좋다.
%time m.fit(X_train, y_train) # 훈련세트로부터 RandomForest 만들기
print_score(m) # 결과의 성능 평가성능 평가 점수는 1에 가까울수록 좋다.
rmse
- 평균 제곱근 편차
- 예측 값과 실체 관찰되는 값의 차이를 다룰 때 흔히 사용하는 방법
- 정밀도를 표현하는데 적합하다.