퍼셉트론으로 복잡한 함수도 표현 가능
가중치를 설정하는 작업(원하는 결과를 출력하도록 가중치 값을 적절히 정하는 작업)은 여전히 사람이 수동으로 수행
예를 들어, AND, OR 게이트의 진리표를 보면서 적절한 가중치 값을 선정
하지만, 퍼셉트론과 달리 신경망은 가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력이 중요한 성질
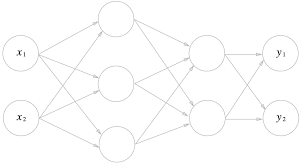
퍼셉트론에서 신경망으로
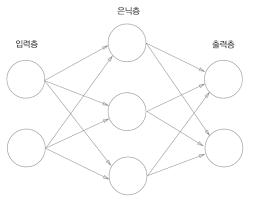
가장 왼쪽 줄을 입력층
맨 오른쪽 줄을 출력층
중간 줄을 은닉층
입력층에서 출력층 방향으로 차례로 0층, 1층, 2층
가중치를 갖는 층은 2개뿐이기 때문에 '2층 신경망'이라고 부름
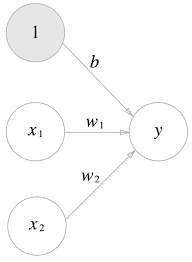
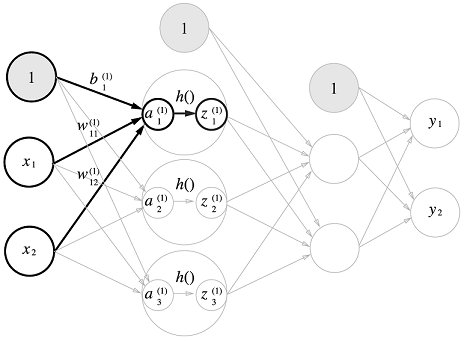
기존 퍼셉트론 네트워크에서는 편향이 보이지 않았기 때문에 편향을 명시
이 퍼셉트론은 , 1 이라는 3개의 신호가 뉴런에 입력되어, 각 신호에 가중치를 곱한 후, 다음 뉴런에 전달
다음 뉴런에서는 신호들의 값을 더하여, 그 합이 0을 넘으면 1을 출력하고 그렇지 않으면 0을 출력
위 식을 더 간결하게 표현하면, 함수를 라 하여 다음과 같은 식으로 표현 가능
와 같은 함수를 입력 신호의 총합을 출력 신호로 변환하는 활성화 함수라 부름
활성화 함수는 입력 신호의 총합이 활성화를 일으키는지를 정하는 역할
1) 가중치가 곱해진 입력 신호의 총합을 계산하고,
2) 그 합을 활성화 함수에 입력해 결과를 내는 2단계로 처리
a는 가중치가 달린 입력 신호와 편향의 총합을 계산
a를 함수 에 넣어 y를 출력하는 흐름
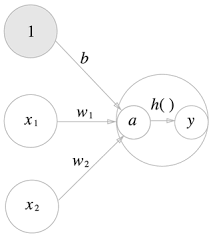
위 그림은 기존 뉴런의 원을 키우고, 그 안에 활성화 함수의 처리 과정을 명시적으로 표현
가중치 신호를 조합한 결과가 a라는 노드가 되고,
활성화 함수를 를 통과하여 y라는 노드로 변환되는 과정
활성화 함수
활성화 함수로 쓸 수 있는 여러 후보 중에서 퍼센트롭은 계단 함수를 채용
계단 함수에서 다른 함수로 변경하는 것이 신경망의 세계로 나아가는 열쇠
시그모니드 함수
신경망에서 자주 이용하는 활성화 함수
는 를 뜻하며, 는 자연상수
신경망에서는 활성화 함수로 시그모이드 함수를 이용하여 신호를 변환
그 변환된 신호를 다음 뉴런에 전달
계산 함수 구현하기
계단 함수는 입력이 0을 넘으면 1을 출력하고, 그 외에는 0을 출력하는 함수
def step_function(x):
if x > 0:
return 1
else:
return 0인수 x에 넘파이 배열도 받기 위해서 다음과 같이 수정
def step_function(x):
y = x > 0
return y.astype(np.int)위 코드는 넘파이 배열에 부등호 연산을 하면()배열의 원소 각각에 부등호 연산을 수행한 bool 배열이 생성되는 것을 이용
배열 의 원소 각각이 0보다 크면 True로, 0 이하면 False로 변환하는 새로운 배열 y가 생성
하지만, 원하는 계단 함수는 0이나 1의 int형을 출력해야 하므로 y.astype을 이용하여 원소를 bool에서 int형으로 변경
계단 함수의 그래프
matplotlib 라이브러리를 사용한 계단 함수 그래프
import numpy as np
import matplotlib.pylab as plt
def step_funtion(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1) # -5.0에서 5.0 전까지 0.1 간격의 넘파이 배열을 생성 [-5.0, -4.9, ..., 4.9]
y = step_function(x) # 인수로 받은 넘파이 배열의 원소 각각을 인수로 계단 함수를 실행해, 그 결과를 다시 배열로 만들어 돌려준다.
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
계단 함수는 0을 경계로 출력이 0에서 1(또는 1에서 0)으로 변화
시그모이드 함수 구현하기
시그모이드 함수 구현
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.array([-1.0, 1.0, 2.0])
sigmoid(x)
array([0.26894142, 0.73105858, 0.88079708])시그모이드 함수 그래프
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()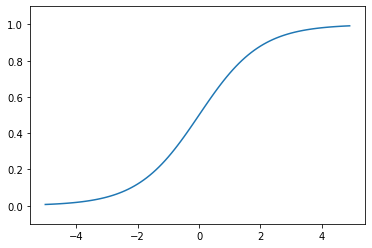
시그모이드 함수와 계단 함수 비교
시그모이드 함수는 부드러운 곡선
입력에 따라 출력이 연속적으로 변화
시그모이드 함수의 이 매끈함이 신경망 학습에서 아주 중요한 역할
반면, 계단 함수는 0을 경계로 출력이 갑자기 변화
퍼셉트론에서는 뉴런 사이에 0 혹은 1이 흘렀다면, 신경망에서는 연속적인 실수가 흐름
두 함수 모두 입력이 작을 때의 출력은 0에 가깝고, 입력이 커지면 출력이 1에 가까워지는 구조
즉, 입력이 중요하면 큰 값을 출력하고 입력이 중요하지 않으면 작은 값을 출력
입력이 아무리 작거나 커도 출력은 0에서 1사이라는 것도 공통점
비선형 함수
변환기에 무언가 입력했을 때 출력이 입력의 상수배만큼 변하는 함수를 선형 함수
수식으로는 이고, 이 때 와 는 상수
비선형 함수는 직선 1개로는 그릴 수 없는 함수
신경망에서는 선형 함수를 이용하면 신경망의 층을 깊게 하는 의미가 없어지기 때문에 사용하지 않음
예를 들어, 선형 함수인 를 활성화 함수로 사용한 3층 네트워크의 경우 이를 식으로 나타내면
이 계산은 처럼 곱셈을 세 번 수행하지만, 실은 와 똑같은 식, 과 동일
즉, 은닉층이 없는 네트워크로 표현됨
ReLU 함수
시그모이드 함수는 신경망 분야에서 오래전부터 이용해왔으나, 최근에는 ReLU(Rectified Linear Unit) 함수를 주로 이용
ReLU는 입력이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하이면 0을 출력
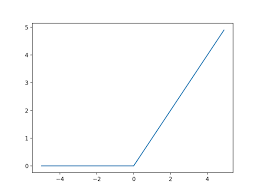
ReLU 수식
다음과 같이 쉽게 구현 가능
def relu(x):
return np.maximum(0, x) # 두 입력 중 큰 값을 선택해서 반환다차원 배열의 계산
넘파이를 사용한 다차원 배열
import numpy as np
A = np.array([1, 2, 3, 4])
print(A)
[1 2 3 4]
print(np.ndim(A))
1
print(A.shape) # 배열의 형상, 튜플 반환하는 것에 주의
(4,) # 1차원 배열이라도 다차원 배열일 때와 통일된 형태로 결과를 반환하기 위함
print(A.shape[0])
4'3x2'배열
2차원 배열은 특히 행렬(matrix)라고 부름
배열의 가로 방향을 행
배열의 세로 방향을 열
B = np.array([[1, 2], [3, 4], [5, 6]])
print(B)
[[1 2]
[3 4]
[5 6]]
print(np.ndim(B))
2
print(B.shape)
(3, 2)행렬의 곱
예를 들어, 2 x 2 행렬의 곱은 아래처럼 계산
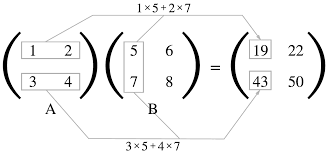
행렬 곱은 왼쪽 행렬의 행(가로)과 오른쪽 행렬의 열(세로)을 원소별로 곱하고 그 값들을 더해서 계산
A의 1행과 B열의 1열을 곱한 값은 결과 행렬의 1행 1번째 원소
import numpy as np
A = np.array([[1, 2], [3, 4]])
print(A.shape)
(2, 2)
B = np.array([[5, 6], [7, 8]])
print(B.shape)
(2, 2)
print(np.dot(A, B))
[[19 22]
[43 50]]np.dot은 1차원 배열이면 벡터를, 2차원 배열이면 행렬 곱을 계산
np.dot(A, B)와 np.dot(B, A)는 다른 값이 될 수 있다는 점 주의
행렬의 곱에서는 피연산자의 순서가 다르면 결과도 다를 수 있음
다음은 2 x 3 행렬과 3 x 2 행렬의 곱
이 때 행렬의 형상(shape)에 주의
행렬 A의 첫 번째 차원의 원소 수(열 수, dim1)와 행렬 B의 0 번째 차원의 원소 수(행 수, dim0)가 동일해야 함
A = np.array([[1, 2, 3], [4, 5, 6]])
print(A.shape)
(2, 3)
B = np.array([[1, 2], [3, 4], [5, 6]])
print(B.shape)
(3, 2)
print(np.dot(A, B))
[[22 28]
[49 64]]3 x 2 행렬 A와 2 x 4 행렬 B를 곱해 3 x 4 행렬 C를 만드는 예
행렬 A와 행렬 B의 대응하는 차원의 원소 수가 같아야 함
행렬 C의 shape은 행렬 A의 행 수와 행렬 B의 열 수로 구성
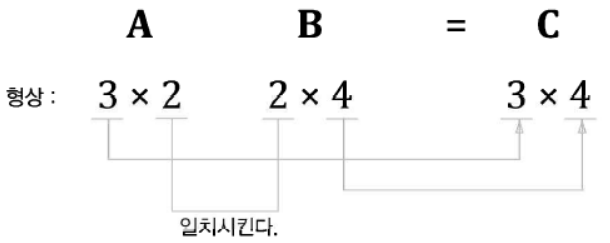
A가 2차원 행렬이고 B가 1차원 행렬인 경우에도 동일한 규칙 적용
A = np.array([[1, 2], [3, 4], [5, 6]])
print(A.shape)
(3, 2)
B = np.array([7, 8])
print(B.shape)
(2,)
print(np.dot(A, B))
[23 53 83]신경망에서의 행렬 곱
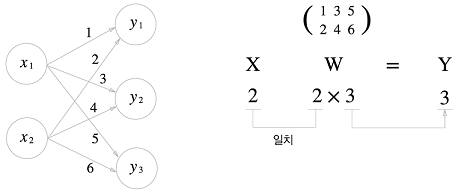
import numpy as np
X = np.array([1, 2])
print(X.shape)
(2,)
W = np.array([[1, 3, 5], [2, 4, 6]])
print(W)
[[1 3 5]
[2 4 6]]
print(W.shape)
(2, 3)
Y = np.dot(X, W)
print(Y)
[ 5 11 17]다차원 배열의 스칼라곱을 구해주는 np.dot 함수를 사용하면 이처럼 단번에 결과 Y를 계산할 수 있음
Y의 원소가 100개든 1,000개든 한 번의 연산으로 계산
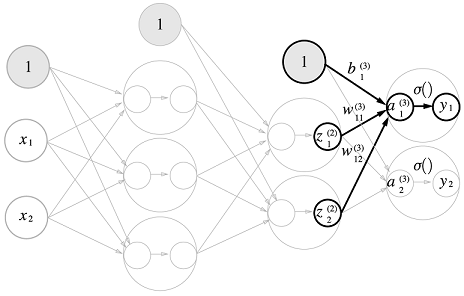
3층 신경망 구현하기
입력층(0층)은 2개
첫 번째 은닉층(1층)은 3개
두 번째 은닉층(2층)은 2개
출력층(3층)은 2개의 뉴런으로 구성
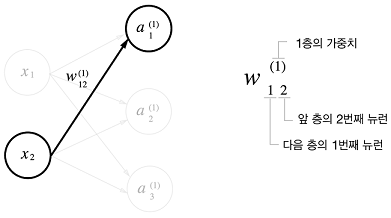
표기법
각 층의 신호 전달 구현하기
편향을 뜻하는 뉴런인 1이 추가
을 수식으로 표현 :
행렬의 곱을 이용하면 1층의 '가중치 부분'을 다음 식처럼 간소화
import numpy as np
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape)
(2, 3)
print(X.shape)
(2,)
print(B1.shape)
(3,)
A1 = np.dot(X, W1) + B1
print(A1)
[0.3 0.7 1.1]W1은 2 x 3 행렬, X는 원소가 2개인 1차원 배열
W1과 X의 대응하는 차원의 원소 수가 일치(W1의 1차원, X의 0차원)
은닉층에서 가중치 합(가중 신호와 편향의 합)을 로 표기하고 활성화 함수 로 변환된 신호를 로 표기
Z1 = sigmoid(A1) # 앞에서 정의한 함수
print(A1)
[0.3 0.7 1.1]
print(Z1)
[0.57444252 0.66818777 0.75026011]1층에서 2층으로 가는 과정
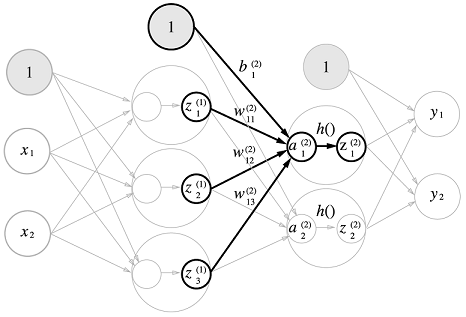
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape)
(3,)
print(W2.shape)
(3, 2)
print(B2.shape)
(2,)
A2 = np.dot(Z1, W2) + B2
print(A2)
[0.51615984 1.21402696]
Z2 = sigmoid(A2)
print(Z2)
[0.62624937 0.7710107 ]2층에서 출력층으로의 신호 전달
조금 전 구현과 동일
활성화 함수만 항등 함수인 identity_function() 사용
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
print(W3.shape)
(2, 2)
print(B3.shape)
(2,)
A3 = np.dot(Z2, W3) + B3
print(A3)
[0.31682708 0.69627909]
Y = identity_function(A3)
print(Y)
[0.31682708 0.69627909]구현 정리
def init_network(): # 가중치와 편향 초기화
network = {} # 딕셔너리 변수
network['W1'] = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 입력층에서 1층
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 1층에서 2층
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# 2층에서 출력층
a3 = np.dot(z2, W3) + b3
y = identity_function(z2)
return y
network = init_network()
print(network)
{'W1': array([[0.1, 0.3, 0.5],
[0.2, 0.4, 0.6]]), 'b1': array([0.1, 0.2, 0.3]), 'W2': array([[0.1, 0.4],
[0.2, 0.5],
[0.3, 0.6]]), 'b2': array([0.1, 0.2]), 'W3': array([[0.1, 0.3],
[0.2, 0.4]]), 'b3': array([0.1, 0.2])}
x = np.array([1.0, 0.5])
print(x)
[1. 0.5]
y = forward(network, x)
print(y)
[0.62624937 0.7710107 ]출력층 설례하기
신경망은 분류와 회귀 모두에 이용 가능
일반적으로
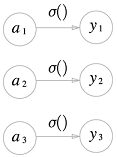
회귀에는 항등 함수를 사용하고,
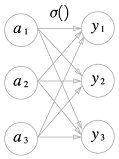
분류에는 소프트맥스 함수를 사용
Machine Learning 문제 구분
분류 : 데이터가 어느 클래스에 속하느냐(사진 속 인물의 성별을 분류하는 문제)
회귀 : 입력 데이터에서 (연속적인) 수치를 예측하는 문제(사진 속 인물의 몸무게를 예측)
항등 함수와 소프트맥스 함수 구현하기
항등 함수는 입력을 그대로 출력
소프트맥스 함수의 식
은 출력층의 뉴런 수, 는 그 중 k번째 출력
소프트맥스의 출력은 모든 입력 신호로부터 화살표를 받음
출력층의 각 뉴런이 모든 입력 신호에서 영향을 받기 때문
import numpy as np
a = np.array([0.3, 2.9, 4.0])
exp_a = np.exp(a)
print(exp_a)
[ 1.34985881 18.17414537 54.59815003]
sum_exp_a = np.sum(exp_a)
print(sum_exp_a)
74.1221542101633
y = exp_a / sum_exp_a
print(y)
[0.01821127 0.24519181 0.73659691]파이썬 함수로 정의
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y소프트맥스 함수 구현 시 주의점
소프트맥스는 Overflow 결함 존재
가령 은 20,000이 넘고 은 0이 40개 넘는 큰 값으로 큰 값끼리 나눗셈을 하면 결과 수치가 '불안정'
소프트맥스 함수 구현을 개선
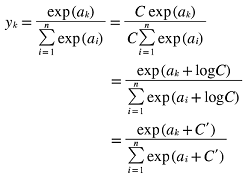
1) C라는 임의의 정수를 분자와 분모 양 쪽에 곱하고
2) C를 지수 함수 exp() 안으로 옮겨 logC로 변환
3) 마지막으로 logC를 C로 치환
소프트맥스의 지수 함수를 계산할 때 어떤 정수를 더해도 결과는 바뀌지 않음
C에 어떤 값을 대입해도 상관없지만, Overflow를 막는 목적으로는 입력 신호 중 최댓값을 이용하는 것이 일반적
소프트맥스 함수 Overflow 예제
a = np.array([1010, 1000, 990])
print(np.exp(a) / np.sum(np.exp(a)))
[nan nan nan] # not a number의 약자
# /usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:2: RuntimeWarning: overflow encountered in exp
c = np.max(a) # 넘파이 배열에서 최댓값
print(c)
1010
print(a - c)
[ 0 -10 -20]
print(np.exp(a - c) / np.sum(np.exp(a - c)))
[9.99954600e-01 4.53978686e-05 2.06106005e-09] # c를 빼줘서 올바르게 계산 가능개선한 소프트맥스 함수
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y소프트맥스 함수의 특징
소프트맥스 함수를 이용한 신경망의 출력
import numpy as np
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y)
[0.01821127 0.24519181 0.73659691] # 0에서 1.0 사이의 실수
np.sum(y) # 소프트맥스 함수의 총합
1.0소프트맥스 함수의 출력은 0에서 1.0 사이의 실수
소프트맥스 출력의 총합은 1
소프트맥스의 출력은 '확률'로 해석
의 확률은 0.018(1.8%)
의 확률은 0.245(24.5%)
의 확률은 0.737(73.7%)
--> 2번째 원소의 확률이 가장 높으니, 답은 2번째 클래스
즉, 소프트맥스 함수를 이용함으로써 문제를 확률적(통계적)으로 대응
소프트맥스 함수를 적용해도 각 원소의 대소 관계는 변하지 않음
이는 지수 함수 가 단조 증사 함수이기 때문
예를 들어, a에서 가장 큰 원소는 2번째 원소이고, y에서 가장 큰 원소도 2번째 원소
결과적으로 신경망으로 분류할 때는 출력층의 소프트맥스 함수를 생략해도 됨
현업에서도 지수 함수 계산에 드는 자원 낭비를 줄이고자 출력층의 소포트맥스 함수는 생략하는 것이 일반적
Machine Learning의 문제 풀이는 학습과 추론의 두 단계
학습 단계에서 모델을 학습하고, 추론 단계에서 앞어 학습한 모델로 미지의 데이터에 대해서 추론(분류)을 수행
추론 단계에서는 출력층의 소프트맥스 함수를 생략하는 것이 일반적
출력층의 뉴런 수 정하기
출력층의 뉴런 수는 분류하고 싶은 클래스 수로 설정하는 것이 일반적
예를 들어, 입력 이미지를 숫자 0부터 9 중 하나로 분류하는 문제라면 출력층의 뉴런을 10개로 설정
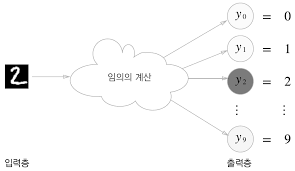
뉴런의 회색 농도가 해당 뉴런의 출력 값의 크기를 의미
위 예에서는 색이 가장 짙은 뉴런이 가장 큰 값을 출력
이 신경망이 선택한 클래스는 , 즉 입력 이미지를 숫자 '2'로 판단
손글씨 숫자 인식
이미 학습된 매개변수를 사용하여 학습 과정은 생략하고, 추론 과정만 구현
이 추론 과정을 신경망의 순전파라고 함
Machine Learning과 마찬가지로 신경망도 두 단계를 거쳐 문제를 해결
1) 먼저 훈련 데이터(학습 데이터)를 사용해 가중치 매개변수를 학습
2) 추론 단계에서는 앞서 학습한 매개변술즐 사용하여 입력 데이터를 분류
MNIST 데이터셋
MNIST는 Machine Learning 분야에서 아주 유명한 데이터셋
MNIST 데이터셋은 0부터 9까지의 숫자 이미지로 구성
훈련 이미지가 60,000장
시험 이미지가 10,000장
훈련 이미지들을 사용하여 모델을 학습하고, 학습한 모델로 시험 이미지들을 얼마나 정확하게 분류하는지를 평가
MNIST의 이미지 데이터는 28x28 크기의 회색조 이미지(1채널)
각 픽셀은 0에서 255까지의 값
각 이미지에는 그 이미지가 실제 의미하는 숫자가 레이블로 기재
책에서 제공하는 MNIST 데이터섹을 내려받아 이미지를 넘파이 배열로 변환해주는 Python Script 이용
mnist.py 파일에 정의된 load_mnist() 함수를 이용
최초 실행 시에는 인터넷에 연결하여 MNIST 데이터셋을 받아오고,
두 번째부터는 로컬에 저장된 파일(pickle 파일)을 읽음
%cd /content/drive/MyDrive/temp/dataset
/content/drive/MyDrive/temp/dataset
#!python3 mnist.py
from mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
print(x_train.shape)
(60000, 784)
print(t_train.shape)
(60000,)
print(x_test.shape)
(10000, 784)
print(t_test.shape)
(10000,)load_mnist 함수는 읽은 MNIST 데이터를 (훈련 이미지, 훈련 레이블), (시험 이미지, 시험 레이블) 형식으로 반환
인수로는
normalize(입력 이미지의 픽셀 값을 0.0~1.0 사이의 값으로 정규화)
flatten(입력 이미지를 1차원 배열로 만들지를 결정, True로 설정하면 784개의 원소로 이루어진 1차원 배열로 저장))
one_hot_label(True일 때는 레이블을 정답을 뜻하는 원소만 1로 저장)
읽어온 MNIST 이미지를 화면으로 로드
# coding: utf-8
#import sys, os
#sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
!pwd
/content/drive/MyDrive/temp/dataset
import numpy as np
from mnist import load_mnist
from PIL import Image
import matplotlib.pyplot as plt
def img_show(img):
pil_img = Image.fromarray(np.uint8(img)) # 넘파이로 저장된 이미지 데이터를 PIL용 데이터 객체로 변환을 Image.fromarray()가 수행
#pil_img.show() show 명령은 기본 OS에 깔린 유틸리티로 이미지를 열게 해주는 기능인데,온라인 기반 IPython에는 그런 실행이 불가능(https://lapina.tistory.com/81)
plt.imshow(pil_img)
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
# flatten=True로 설정하여 읽어들인 이미지는 1차원 넘파이 배열로 저장
img = x_train[0]
label = t_train[0]
print(label) # 5
5
print(img.shape) # (784,)
(784,)
img = img.reshape(28, 28) # 형상을 원래 이미지의 크기로 변형
print(img.shape) # (28, 28)
(28, 28)
img_show(img)
신경망의 추론 처리
입력을 뉴런을 784개, 출력층 뉴런을 10개로 구성
은닉층은 총 2개
첫 번째 은닉층에는 50개의 뉴런(임의의 수)
두 번째 은닉층에는 100개의 뉴런을 배치(임의의 수)
# coding: utf-8
%cd /content/drive/MyDrive/temp/ch03
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
# normalize를 True로 설정, 0~255 범위인 각 픽셀의 값을 0.0~1.0 범위로 변환
# 이처럼 데이터를 특정 범위로 변환하는 처리를 "정규화"
# 신경망의 입력 데이터에 특정 변화를 가하는 것을 "전처리"
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
# MNIST 데이터셋을 얻고
network = init_network()
# 네트워크를 생성
# for 문을 돌며 x에 저장된 이미지 데이터를 1장씩 꺼내 predict() 함수로 분류
accuracy_cnt = 0
for i in range(len(x)):
print(i)
y = predict(network, x[i]) # [0.1, 0.3, 0.2, ..., 0.04] 같은 배열이 반환 --> 이미지가 숫자 '0'일 확률이 0.1, '1'일 확률이 0.2 식으로 해석
print(y)
p= np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
print(p)
if p == t[i]: # 신경망이 예측한 답변(p)과 정답 레이블(t[i])을 비교하여 맞힌 숫자를 세고, 이를 전체 이미지로 나누어 정확도 산출
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))배치 처리
위에서 구현한 신경망 각 층의 가중치 shape 확인
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
print(x.shape)
(10000, 784)
print(x[0].shape)
(784,)
print(W1.shape)
(784, 50)
print(W2.shape)
(50, 100)
print(W3.shape)
(100, 10)다차원 배열의 대응하는 차원의 원소 수가 일치
원소 784개로 구성된 1차원 배열이 입력되어 마지막에는 원소가 10개인 1차원 배열이 출력
이는 이미지 데이터를 1장만 입력했을 때의 처리 흐름
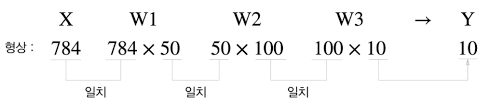
가령 이미지 100개를 묶어 predict() 함수에 한 번에 넘기는 경우
x의 형상을 100x784로 바꿔서 100장 분량의 데이터를 하나의 입력 데이터로 표현
입력 데이터의 형상은 100x784
출력 데이터의 형상은 100x10
x[0]와 y[0]는 0번째 이미지와 그 추론 결과
x[1]과 y[1]에는 1번째 이미지와 그 추론 결과가 저장되는 식

이처럼 하나로 묶은 입력 데이터를 배치라 함
배치 처리의 이점
1) 수치 계산 라이브러리 대부분이 큰 배열을 효율적으로 처리할 수 있도록 고도로 최적화
2) 배치 처리를 함으로써 데이터 전송 버스에 주는 부하를 줄임(I/O를 통해 데이터를 읽는 횟수 감소)
x, t = get_data()
# MNIST 데이터셋을 얻고
network = init_network()
# 네트워크를 생성
# for 문을 돌며 x에 저장된 이미지 데이터를 1장씩 꺼내 predict() 함수로 분류
batch_size = 100 # 배치 크기
accuracy_cnt = 0
for i in range(0, len(x), batch_size): # (start, end, step) start에서 end-1까지 step 간격으로 증가하는 정수 반환
# i는 0, 100, 200, ...
# batch_size가 100이므로 x[0:100], x[100:200], ...와 같이 앞에서부터 100장씩 묶어서 꺼냄
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p= np.argmax(y_batch, axis=1) # axis=1 인수 추가, 이는 100x10의 배열 중 1번째 차원을 구성하는 각 원소에서 최댓값의 인덱스를 찾도록 한 것
accuracy_cnt += np.sum(p == t[i:i+batch_size]) # p도 100개, t[0:100]도 100개, 100개씩 비교해서 True/False로 반환하고 True의 개수만 np.sum으로 합산
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))