DBSCAN 알고리즘
가장 널리 알려진 밀도기반 군집 알고리즘 입니다.
k- means에서 k값을 지정함으로써 군집을 했다면 DBSCAN은 밀도 기반으로 군집을 하기 때문에 k값 설정의 고민을 덜어줍니다. 또한 밀도 기반이기때문에 원 모양의 군집이 아닌 불특정한 형태의 군집도 찾을 수 있습니다.
DBSCAN
- epsilson : 클러스터의 반경
- minPts : 클러스터를 이루는 개체의 최솟값
- core point : 반경 epsilon 내에 minPts 개 이상의 점이 존재하는 중심점
- border point : 군집의 중심이 되지 못하지만 군집에 속하는 점
- noise point : 군집에 포합되지 못하는 점
알고리즘 진행 순서
- 임의의 p점을 설정하고 그 반경에 있는 점들을 센다.
- 원에 minPts 개 이상의 점이 포함되어 있으면 해당 점 p를 core point로 간주하고 원에 포함된 점들을 하나의 클러스터로 묶습니다.
- 해당 원에 minPts 개 미만의 점이면 pass
- 모든 점을 돌아가면서 반복을 진행하고 새로운 p가 core point에 속하면 두 대 클러스터는 연결되어 있다고 하며 하나의 클러스터로 묶는다.
- 모든 클러스터링과정을 어떤 점을 중심으로 해도 클러스터에 속하지 못하면 noise라 간주하며 특정 군집에 속하지만 core point가 아닌 점들을 border point라고 한다.
적용해보기
from sklearn.datasets import make_blobs
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
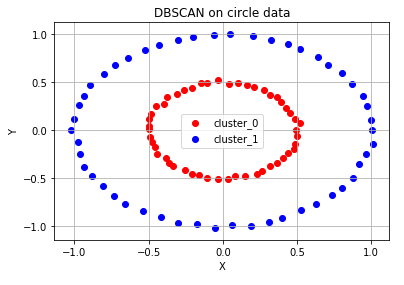
# DBSCAN으로 circle, moon, diagonal shaped data를 군집화한 결과
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_circles
# 원형 분포 데이터 생성
circle_points, circle_labels = make_circles(n_samples=100, factor=0.5, noise=0.01) # 원형 분포를 가지는 점 데이터 100개를 생성합니다.
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'} # n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정하는 color dictionary
# 원형 분포 데이터 plot
epsilon, minPts = 0.2, 3 # 2)와 3) 과정에서 사용할 epsilon, minPts 값을 설정
circle_dbscan = DBSCAN(eps=epsilon, min_samples=minPts) # 위에서 생성한 원형 분포 데이터에 DBSCAN setting
circle_dbscan.fit(circle_points) # 3) ~ 5) 과정을 반복
n_cluster = max(circle_dbscan.labels_)+1 # 3) ~5) 과정의 반복으로 클러스터의 수 도출
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {circle_dbscan.labels_}')
# DBSCAN 알고리즘의 수행결과로 도출된 클러스터의 수를 기반으로 색깔별로 구분하여 점에 색칠한 후 도식
for cluster in range(n_cluster):
cluster_sub_points = circle_points[circle_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on circle data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()of cluster: 2
DBSCAN Y-hat: [0 1 0 0 0 1 1 1 0 0 1 0 1 0 1 0 1 1 0 0 1 0 1 1 0 0 1 0 0 1 1 0 1 1 1 1 0
0 1 1 1 1 0 1 1 1 1 0 0 0 0 1 1 1 0 0 0 0 1 0 0 0 0 1 1 0 1 0 0 1 1 1 0 0
1 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1]
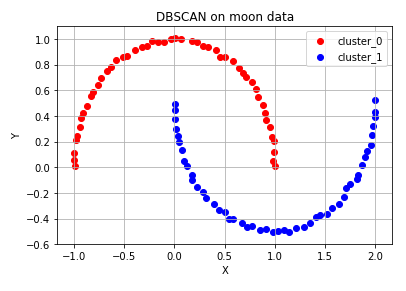
# K-means algorithm이 잘 동작하지 않는 예시 (2) 달 모양 분포
from sklearn.datasets import make_moons
# 달 모양 분포의 데이터 생성
moon_points, moon_labels = make_moons(n_samples=100, noise=0.01) # 달 모양 분포를 가지는 점 데이터 100개를 생성합니다.
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'} # n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정하는 color dictionary
epsilon, minPts = 0.4, 3
moon_dbscan = DBSCAN(eps=epsilon, min_samples=minPts)
moon_dbscan.fit(moon_points)
n_cluster = max(moon_dbscan.labels_)+1
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {moon_dbscan.labels_}')
for cluster in range(n_cluster):
cluster_sub_points = moon_points[moon_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on moon data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()of cluster: 2
DBSCAN Y-hat: [0 1 0 1 1 1 0 1 0 0 1 1 1 0 0 0 0 0 0 1 1 1 0 0 0 1 0 0 0 1 0 0 1 0 0 1 1
0 1 1 0 1 0 1 1 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 1 1 1 0
1 1 1 0 0 0 1 1 0 1 1 1 1 0 0 0 0 1 0 1 1 1 0 1 0 1]
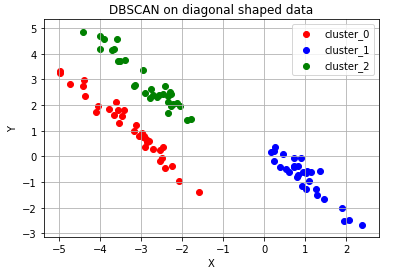
from sklearn.datasets import make_circles, make_moons, make_blobs
# 대각선 모양 분포의 데이터 생성
diag_points, _ = make_blobs(n_samples=100, random_state=170) #대각선 분포를 가지는 점 데이터 100개를 생성합니다.(현재는 무작위 분포)
transformation = [[0.6, -0.6], [-0.4, 0.8]] #대각선 변환을 위한 대각 행렬
diag_points = np.dot(diag_points, transformation) #본 과정을 통해 무작위 분포의 점 데이터를 대각선 분포로 변환합니다.
# 대각선 모양 분포 데이터 plot - 위와 같은 과정 반복
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'} # n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정하는 color dictionary
epsilon, minPts = 0.7, 3
diag_dbscan = DBSCAN(eps=epsilon, min_samples=minPts)
diag_dbscan.fit(diag_points)
n_cluster = max(diag_dbscan.labels_)+1
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {diag_dbscan.labels_}')
for cluster in range(n_cluster):
cluster_sub_points = diag_points[diag_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on diagonal shaped data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()of cluster: 3
DBSCAN Y-hat: [ 0 1 1 0 0 2 2 0 1 2 2 2 0 2 0 1 2 2 2 1 1 1 1 1
2 2 0 1 0 2 1 0 2 1 2 0 0 0 0 0 1 0 1 0 0 2 1 1
0 2 1 1 2 1 0 2 -1 2 0 0 2 0 0 1 0 1 1 2 2 2 -1 0
2 0 0 0 1 2 2 -1 2 2 1 2 0 0 2 1 1 2 1 1 2 0 -1 1
0 0 0 1]