글 배경
최근 회사 홈페이지의 검색 최적화를 개선하는 작업을 맡게 되었다.
기존에는 검색 결과에 불필요한 페이지가 노출되거나, 원하는 연관 페이지가 추천되지 않는 문제가 있었다.
이를 해결하기 위해 검색 엔진이 사이트를 더 잘 이해하고, 유저에게 더 보기 좋은 UI로 노출될 수 있도록 사이트맵(Sitemap), robots.txt 그리고 구조화된 데이터(Structured Data)를 최적화하는 작업을 진행하였다.
이 과정에서 직접 조사하고 적용한 SEO 최적화 방법을 정리해보았다.
SEO가 중요한 이유
SEO(Search Engine Optimization)는 단순히 검색 엔진에서 상위에 노출되는 것을 넘어, 웹사이트 트래픽 증가, 브랜드 신뢰도 향상, 전환율(Conversion Rate) 상승 같은 중요한 효과를 가져온다.
특히, 검색 결과에서 더 나은 UI로 표시되면 클릭률(CTR, Click-Through Rate)이 높아져 방문자 수 증가로 이어질 가능성이 크다.
SEO 최적화를 위해 가장 중요한 3가지 요소를 정리했다.
1. 사이트맵(sitemap) -검색 엔진의 길잡이
사이트맵은 웹사이트의 지도를 만들어 검색 엔진이 어디를 방문해야 하는지 알려주는 역할을 한다.
검색 엔진이 사이트맵을 통해 웹사이트 구조를 쉽게 이해할 수 있도록 함으로써, 검색 엔진이 어디를 먼저 방문해야 하는지, 어떤 페이지가 중요한지 파악하는 데 도움을 준다.
특히, 수천 개의 페이지를 보유한 이커머스 사이트나 뉴스 사이트에서는 사이트맵이 없으면 새로운 페이지가 검색 결과에 반영되기까지 오랜 시간이 걸릴 수 있다.
사이트맵의 역할
- 검색 엔진이 중요한 페이지를 더 빠르게 인식하고 색인(indexing)할 수 있도록 한다.
- 관련 페이지들이 검색 결과에 더 잘 노출될 가능성을 높인다.
- 내부 링크가 부족한 페이지도 검색 엔진이 쉽게 찾을 수 있도록 보완한다.
사이트맵 파일 예시 (XML 형식)
// sitemap.xml
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://example.com/</loc>
<lastmod>2025-02-16</lastmod>
<priority>1.0</priority>
</url>
<url>
<loc>https://example.com/about</loc>
<lastmod>2025-02-14</lastmod>
<priority>0.8</priority>
</url>
</urlset>사이트맵 등록 방법
sitemap.xml을 생성하고 웹사이트 루트 디렉토리에 업로드한다. (https://example.com/sitemap.xml)- Google Search Console → 색인 → 사이트맵 → 새 사이트맵 추가
- 네이버 웹마스터 도구에서도 동일한 방식으로 등록 가능
🧐 구글의 사이트맵은 어떻게 되어있을까?
사이트맵은 검색 엔진이 접근할 수 있도록 설정된 공개 문서이므로, ${도메인}/sitemap.xm로 쉽게 확인이 가능하다.
만약 구글의 사이트맵 구조를 보고 싶다면, https://www.google.com/sitemap.xml 이렇게 ${도메인}/sitemap.xml 로 접근할 수 있다.
구글과 같이 일부 사이트는 여러 개의 사이트맵을 포함하거나 특정 카테고리 별로 사이트맵을 관리하기 위해 사이트맵 색인 파일을 관리하기도 한다.
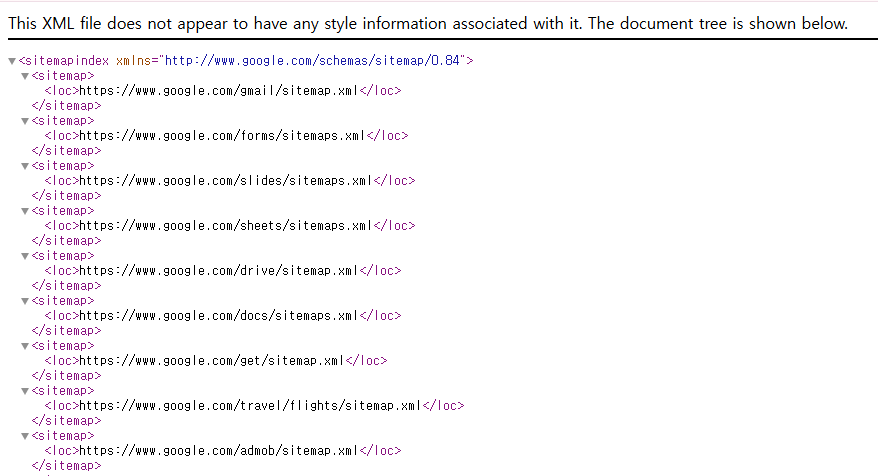
(출처: Google Sitemap.xml 일부)
2. robots.txt - 크롤링 제어 역할
robots.txt는 검색 엔진이 웹사이트에서 크롤링할 수 있는 페이지와 차단해야 하는 페이지를 정하는 규칙이다.
robots.txt를 잘 활용하면 검색 엔진이 중요하지 않은 페이지를 크롤링하는 시간을 줄이고, SEO 점수를 높이는 데 도움을 줄 수 있다.
✅ 하지만 색인(Indexing)을 막는 것은 아니고, 크롤링만 차단하는 기능을 한다.
색인을 완전히 막으려면 meta robots 태그에서 noindex를 설정하여, 특정 페이지가 검색 결과에 인덱싱이 되지 않도록 해야 한다.
<head>
<meta name="robots" content="noindex, nofollow">
</head>위 코드를 추가하면 해당 페이지가 검색 엔진에 색인되지 않으며, 내부 링크도 따라가지 않도록 제한된다.
robots.txt 작성 방법
// robots.txt
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml- User-agent: 크롤러(검색 엔진 봇) 지정 (예:
Googlebot,AdsBot-Google등) - Disallow: 특정 페이지 또는 디렉토리 크롤링 차단
- Allow: 특정 페이지 또는 디렉토리 크롤링 허용
- Sitemap: 검색 엔진에 사이트맵 위치를 제공하여 색인 최적화
# 특정 크롤러(Googlebot)만 차단
User-agent: Googlebot
Disallow: /
# 모든 크롤러 차단 (AdsBot-Google 제외)
User-agent: *
Disallow: /특정 디렉토리 차단 vs 특정 패턴 차단
Disallow: /terms/ # /terms/ 및 모든 하위 경로 차단
Disallow: /private/* # /private/로 시작하는 모든 경로 차단
Disallow: /*.pdf # .pdf 확장자 파일 차단robots.txt 생성 조건
- 파일 이름은 robots.txt로 지정해야 한다.
- 사이트에는 robots.txt 파일이 하나만 있어야 한다.
- robots.txt 파일은 파일이 적용되는 웹사이트 호스트의 루트에 있어야 한다.
- 예를 들어,
https://www.example.com/아래 모든 URL에 관한 크롤링을 제어하려면 robots.txt 파일이https://www.example.com/robots.txt에 있어야 한다.
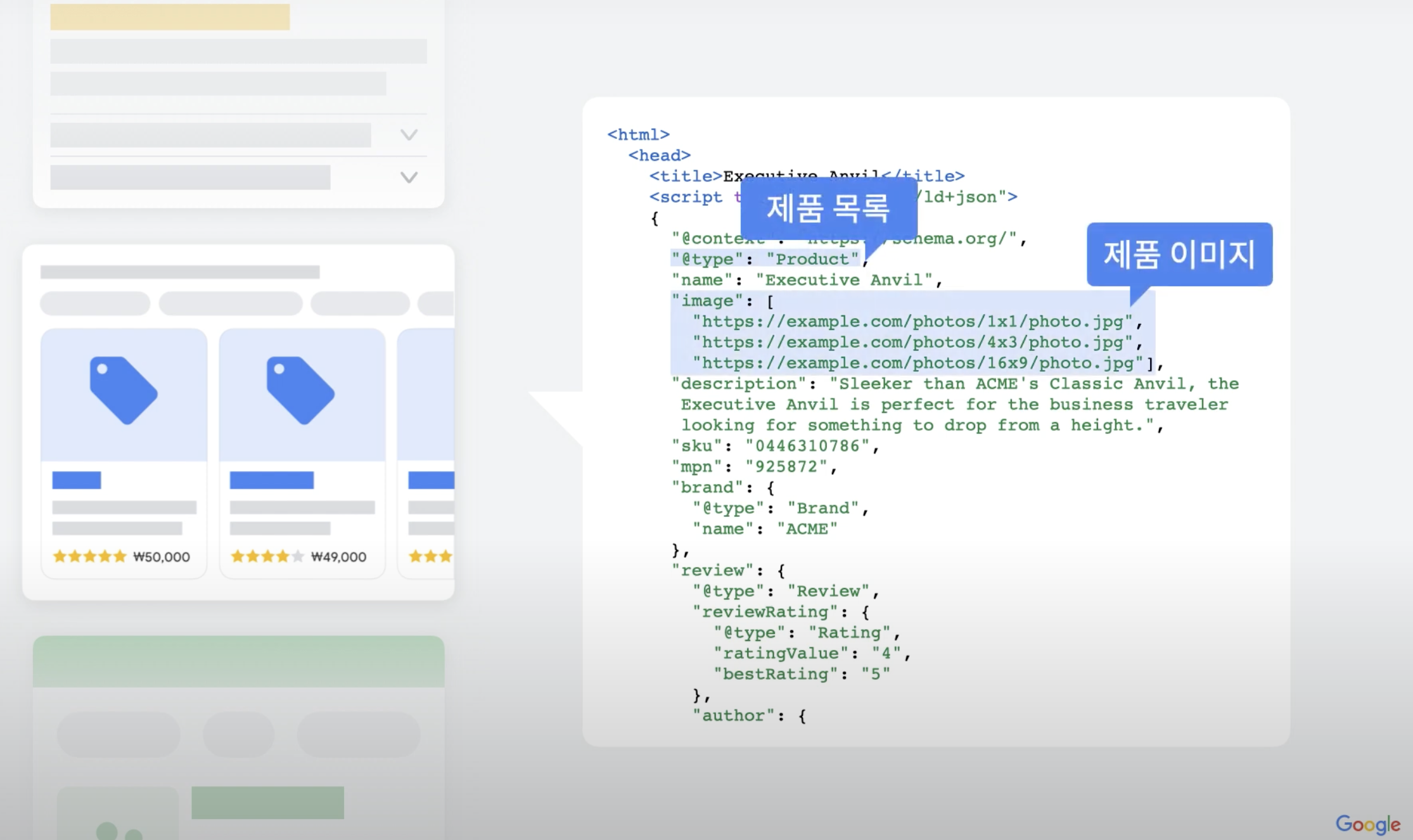
3. 구조화된 데이터(Structured Data) - 검색 결과 UI 향상
구조화된 데이터는 검색 엔진이 웹페이지의 콘텐츠를 더 쉽게 이해하도록 돕고, 검색 결과에서 더욱 풍부한 UI(리치 스니펫)로 노출되도록 하는 웹표준 기술이다.
예를 들어, 쿠팡 같은 쇼핑몰 검색 결과에서 가격, 리뷰, 별점 등이 바로 보이는 것이 구조화된 데이터 덕분이다.
Google에서는 웹에서 찾은 구조화된 데이터를 사용하여 페이지의 콘텐츠를 파악할 뿐 아니라 마크업에 포함된 개인, 책, 회사에 관한 정보 등 웹 및 전반적인 세상에 관한 정보를 수집한다.
구조화된 데이터의 역할
- 구글 검색 결과에서 리치 결과(탭, 카드, 캐러셀 등)로 노출 가능
- 검색 엔진이 페이지의 맥락을 더 잘 이해하도록 도움
- 네이버 등 다른 검색 엔진에서도 사용 가능
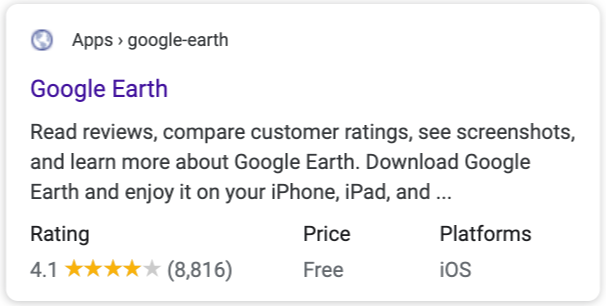
리치 결과 (다채로운 UI)
구글에서는 구조화된 데이터를 사용하여 페이지의 콘텐츠를 파악하고, 검색 결과에서 해당 콘텐츠를 캐러셀, 레시피 등 다채로운 방식으로 UI 상 노출하며 이를 리치 결과라고 한다.
사이트가 이러한 리치 결과로 표시되도록 하려면 사이트에서 각 유형별로 구조화된 데이터를 구현하는 방법에 관한 가이드를 따르어, 마크업을 완성시켜야 한다.
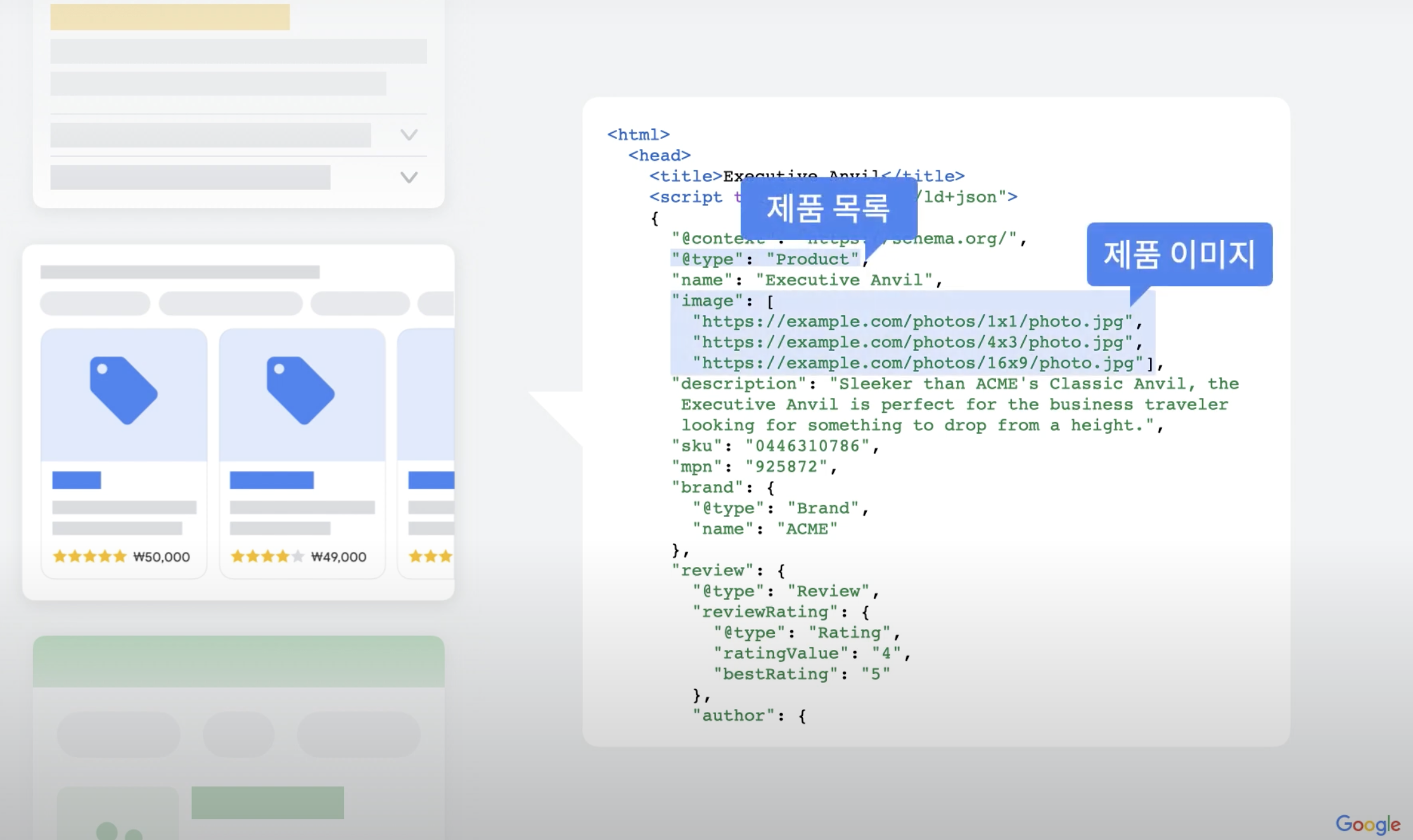
예를 들어, 웹페이지 본문에 소프트웨어 애플리케이션 정보를 알릴 수 있는 필드들로 채운 구조화된 데이터를 작성하게 되면, 다음과 같이 검색 결과에 앱 세부 정보를 더욱 리치하게 표시할 수 있다.
구조화된 데이터 파일 예시 (JSON-LD 형식)
다음은 웹 애플리케이션 정보로 표시될 수 있으며 앱 이름, 설치가능한 OS, 카테고리, 평점, 가격 등 세부정보를 설명하는 구조화된 JSON-LD 데이터 스니펫이다.
<html>
<head>
<title>Angry Birds</title>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "SoftwareApplication",
"name": "Angry Birds",
"operatingSystem": "ANDROID",
"applicationCategory": "GameApplication",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": 4.6,
"ratingCount": 8864
},
"offers": {
"@type": "Offer",
"price": 1.00,
"priceCurrency": "USD"
}
}
</script>
</head>
<body>
</body>
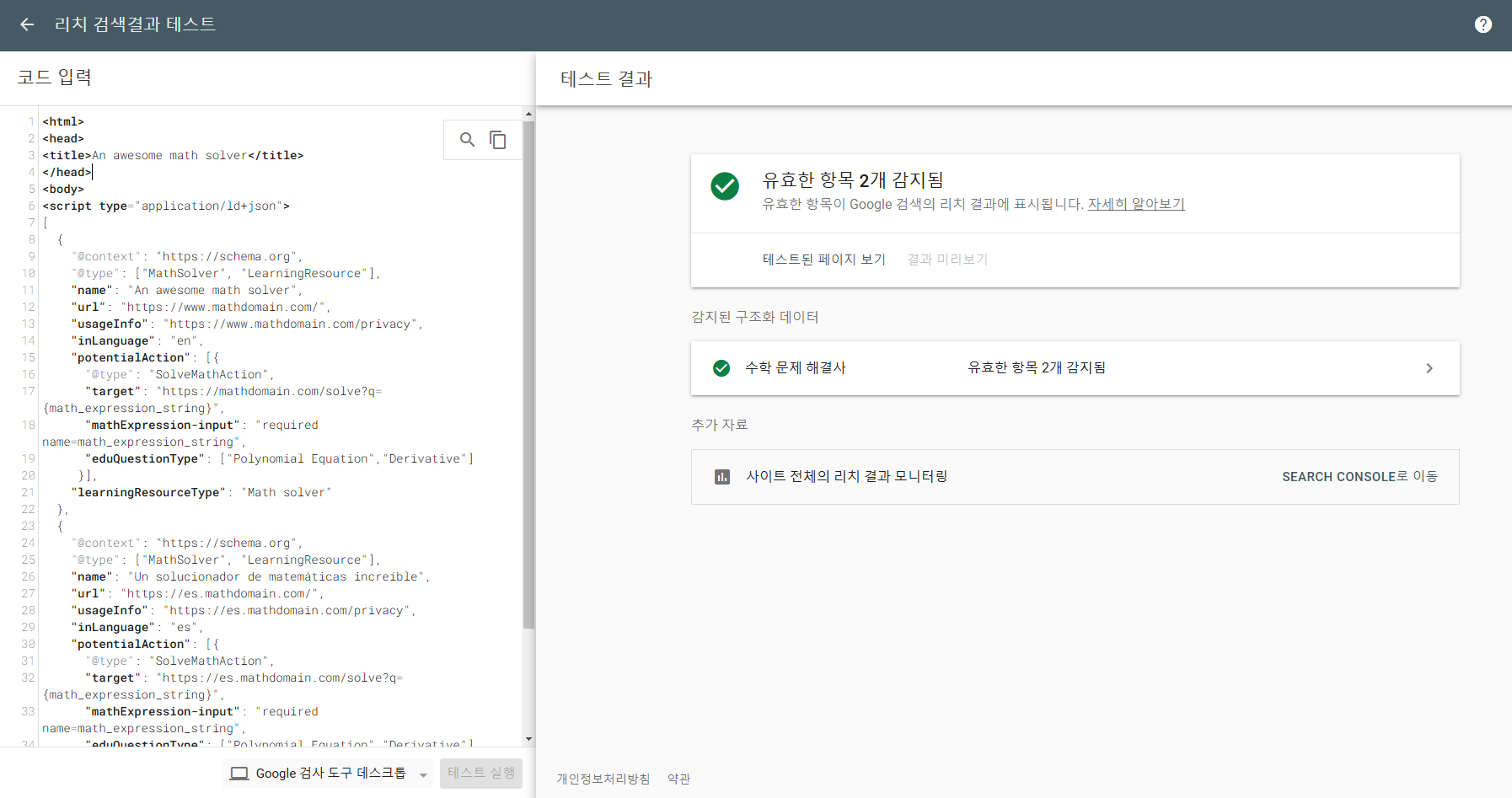
</html>리치 검색 결과 테스트
구글에서 제공하는 구글 리치 검색 결과 테스트를 활용하여, 우리 웹사이트에 적용할 혹은 적용된 구조화된 데이터 마크업을 테스트 할 수 있다.
출처 및 참고자료
