Week 3 | Seminar Discussion
-
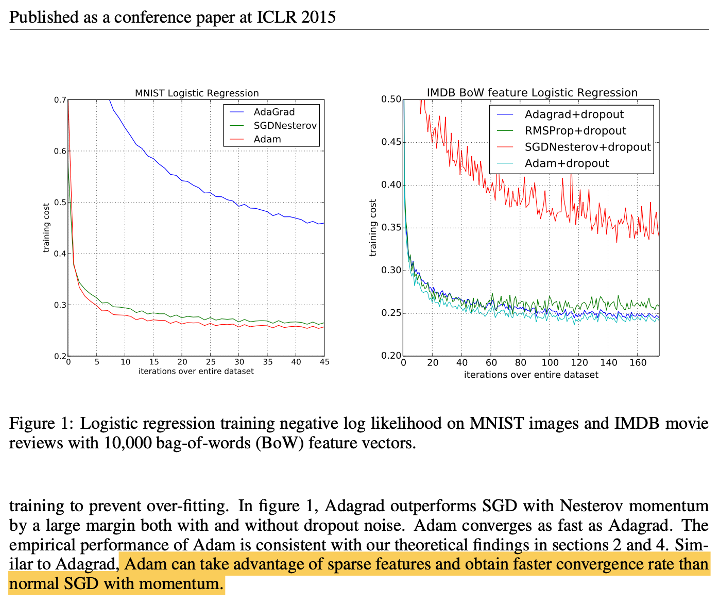
Adam papaer에서 Adam Optimization의 성능이 momentum보다 훨씬 빠른 속도로 수렴한다는 emirical performance를 보였다고 작성이 되어있는데,
하지만 이는 경험적인 것이기 때문에 아무도 모른다- 보통 momentum이 default로 사용되긴 한다.
- 또한 Adam은 빠른 학습 속도를 보여주기도 하지만, 반대로 학습 후기로 갈수록 accuracy가 떨어지지 않는 모습을 보일 때도 있다.
그렇기 때문에 여러 optimization 방법을 hyperparameter로서 optional하게 test하여 선택해야 한다.
-
Batch Normalization의 의도 및 효과는?
BN paper의 저자와 강의에서는 검은 고양이, 흰 고양이, 갈색 고양이가 입력으로 들어와도 고양이라고 분류할 수 있어야 한다. 하지만 input feature의 distribution이 달라진다면, 그만큼 model이 학습해야 할 == update해야 할 양이 많아지고, Global Optimum으로의 수렴이 느려질 것이다.
따라서 activation된 값을 에서 을 Normalization하여 들어오는 mini-batch들의 distribution을 일정하게 유지시켜줌으로써 internal covariate shift현상을 막을 수 있다고 한다.- 하지만 BN paper가 나오고 난 후 후기의 반론들이 존재한다.
똑같은 distribution의 mini-batch를 받아도, backprop으로 parameter를 update하는 과정이 있기 때문에 내뱉는 값은 계속 달라진다.
예를 들어서 위의 BN 식에서 와 는 update되는 parameter이다.
따라서 학습이 진행됨에 따라 와 는 계속해서 값이 바뀌기 때문에
mini-batch들의 distribution이 유지된다는 말은 맞지 않는 것이다. - 그럼 만약에 와 를 곱하여 더해주는 과정을 뺀다면 어떤가?
결론은 좋지 않을 것이다.
만약 activation function으로 ReLU를 사용했다면, 를 곱해주는 것은 scale을 조정하는 것이기 때문에 상관없지만, ReLU를 사용했기 때문에 음수인 부분의 data는 모두 날아가는 것이다.
즉 절반의 정보가 날라가는 것이다.
따라서 를 통해 평행이동을 해줌으로써 양수의 분포를 늘려 더욱 의미있는 정보가 유지되어 를 사용하는 것이 좋다고 할 수 있다. - 따라서 와 를 사용하는 이유로 sigmoid의 linear region을 피하기 위함이라고 하면, 잘못된 설명이다.
ReLU는 0에서 확 꺾여버리는 nonlinear성이 강하기 때문에 ReLU activation function에 대해서는 맞지 않는 설명이기 때문이다.결론적으로 BN paper에서 언급된 BN의 의도와 직접적인 효과가 많은 반론을 통해 맞지 않다고 결론이 나고 있다.
또한 BN에 대한 정확한 효과에 대해서는 많은 의견이 있기 때문에 현재로서는 정확한 의도와 효과에 대해서 설명할 수 없다.
하지만 분명한 것은 BN을 사용함으로써 학습이 매우 잘 된다는 점이다.
- 하지만 BN paper가 나오고 난 후 후기의 반론들이 존재한다.
-
Neural Network에서 마지막 layer가 내뱉는 값. 즉, 을
logit이라고 한다. -
TensorFlow : cost계산이 forwardprop
GradientTape()이 backward를 자동으로 == auto differentiation(BN, 미분 등을 자동으로)해주는 함수이다. -
현재 살아남은 framework로는 TensorFlow, PyTorch가 있다.
과거에는 TensorFlow가 독점하다시피 했었다.
그래서 Google과 과거서부터 지금까지 TensorFlow를 사용하는 몇몇 산업체들은 TensorFlow를 사용한다.
하지만 거의 대부분의 사람들은, 특히 논문을 쓸 때 활용하는 framework는 99%가 PyTorch이다.
따라서 둘 다 다룰줄 알아야 한다.
