
⚠️ 해당 포스팅은 인프런 공룡책 강의를 듣고 개인적으로 정리하는 글입니다. 정확하지 않은 정보가 있을 수 있으니 주의를 요합니다.
Section 11
Chapter 10 Virtual Memory
Background
- 프로그램이 실행되기 위해서는 메모리에 적재되어야 한다.
- 프로그램의 용량이 메모리 용량보다 클 때는 어떤식으로 실행되어야 할까?
Virtual Memory
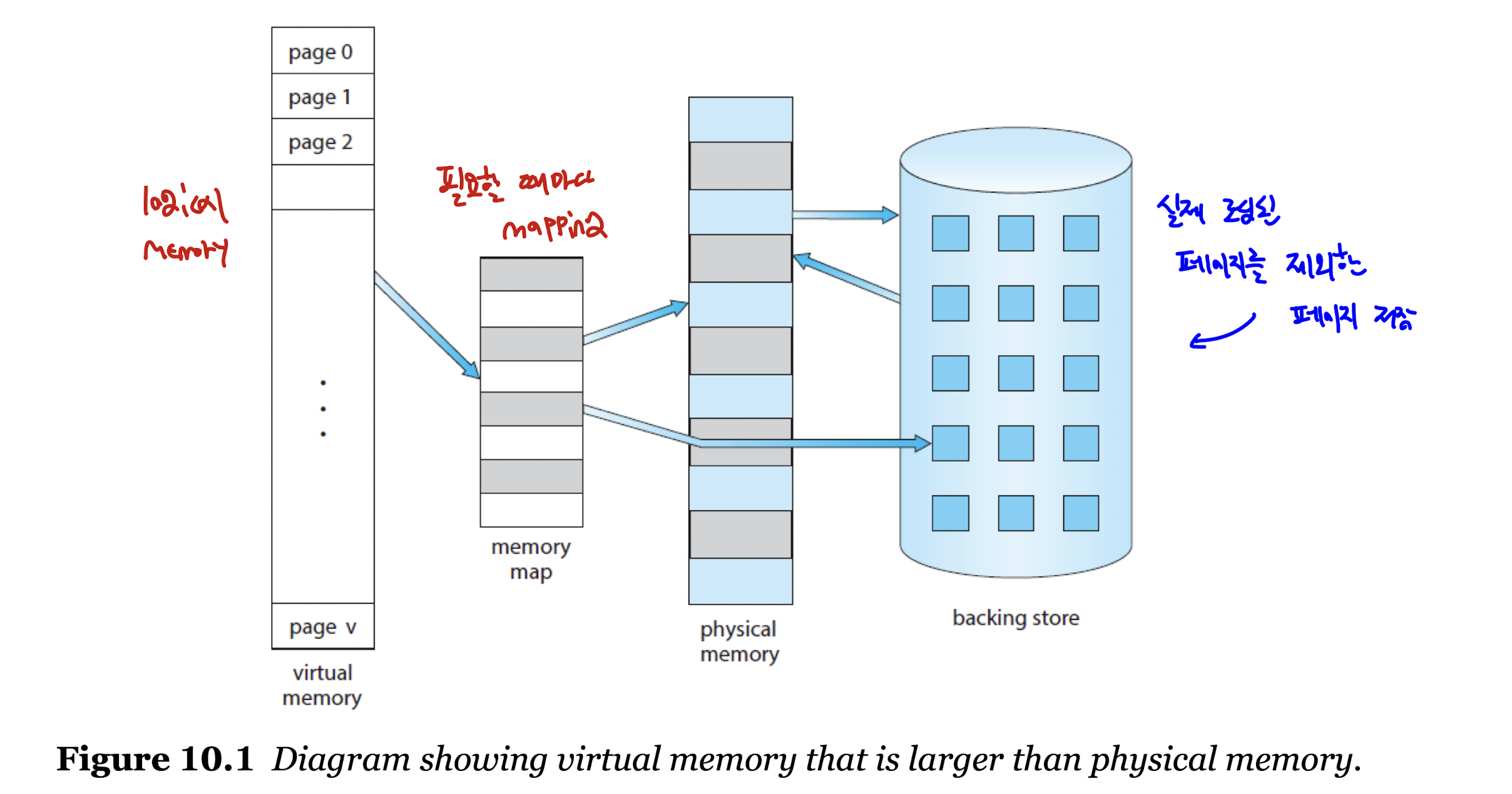
- 가상 메모리는 메모리 내에 완전히 적재되지 않아도 프로세스가 실행이 가능하다.
- 즉, 프로그램이 물리 메모리보다 커도 실행이 가능하다는 이야기이다.
- 메인 메모리를 매우 큰 가장의 저장소로 추상화, 즉 논리적(가상) 메모리로 둔다.
- 실행이 필요한 부분만 실제 물리적 메모리에 옮겨 담는다.
- 위 방법을 통해 논리 메모리와 물리 메모리의 완전한 분리가 가능하다.
- 파일, 라이브러리 공유 및 프로세스 생성에 효과적인 기술이다.
Virtual Address Space
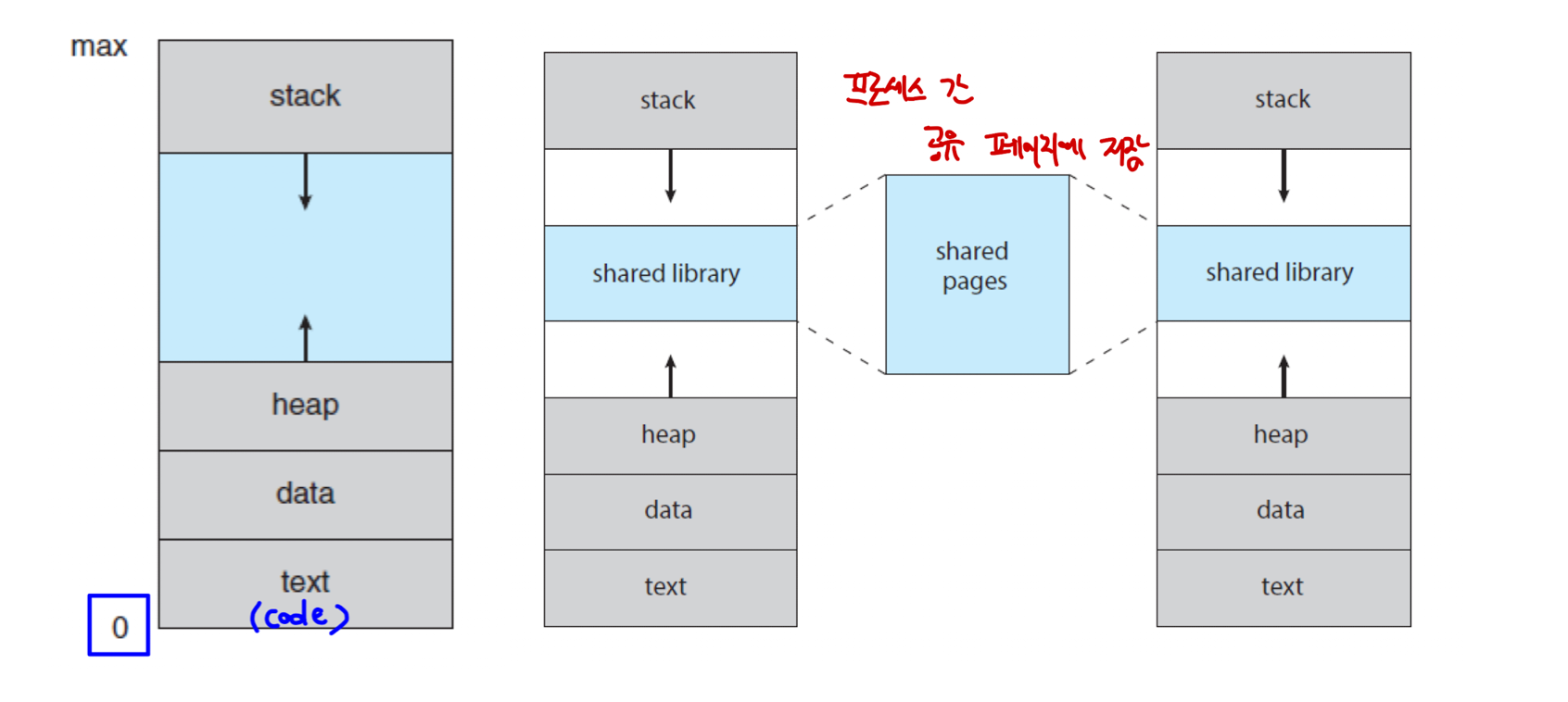
- 프로세스가 메모리에 저장되는 방법이 담긴 논리적(가상) 뷰를 의미한다.
- 보통 주소는 0으로 시작되며, 연속 메모리에 존재한다.
stack,heap은 고정 크기가 아니며, 함수를 호출하면stack영역이 늘어나고, 동적 메모리 할당 시heap영역이 늘어난다.
: 이 부분을 성긴(Sparse) 주소 공간이라고 한다.stack,heap공간 사이에shared library가 위치해 있고,shared pages를 통해 2개 혹은 더 많은 프로세스끼리 파일, 메모리를 공유할 수 있다.
Demand Paging
- 위에서 얘기했듯이, 프로그램은 보조 기억 장치에서 메모리로 적재되어야 실행된다.
- 그러나, 전체 프로그램을 물리 메모리에 로드하면 용량이 부족해지는 경우도 있기 때문에, 대안이 필요하다.
- 이 대안으로 나온 것이 바로 요청 페이징(Demand Paging)이다.
- 요청 페이징은 말 그대로 실행 중에 요청이 들어올 때만 필요한 페이지를 로드한다.
- 가상 메모리에서 주로 사용하는 기법으로, 중요한 개념이다.
Basic Concepts
- 프로세스가 실행 중일 때 페이지는 메모리에 있거나 보조 기억 장치에 위치해 있다.
- 그럼 페이지가 어디에 위치해 있는지 알기 위해선 어떻게 해야 할까?
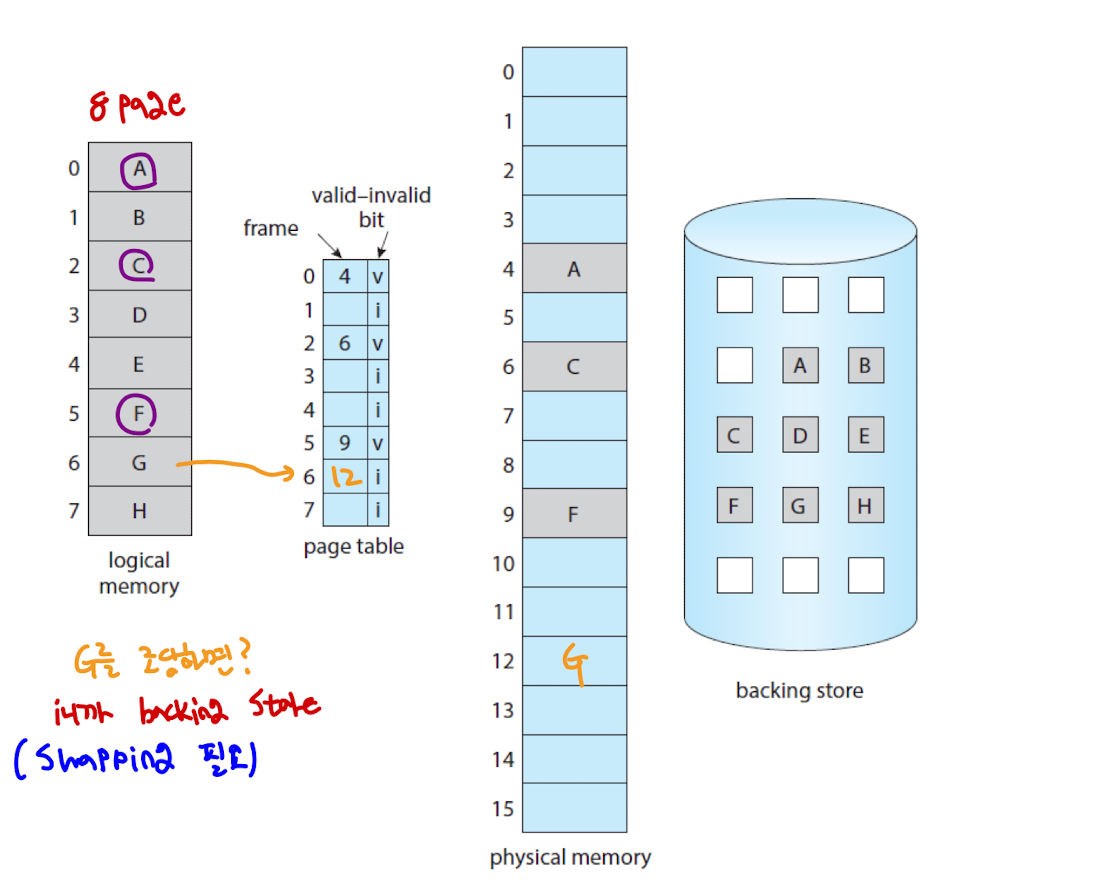
- 이전에 이야기했던 유효 - 무효 비트(valid-invalid bit) 를 사용해 이를 구분한다.
: 유효(valid) : 페이지가 유효하고 메모리 내에 위치해있음.
: 무효(invalid) : 페이지가 유효하지 않거나 보조 기억 장치에 위치해있음.
Page Fault
- 페이지 결함(Page fault)은 메인 메모리에 없는 페이지에 접근할 때 발생하는 O/S의 트랩을 의미한다.
- 페이지 결함이 일어났을 때 해결 절차는 아래와 같다.
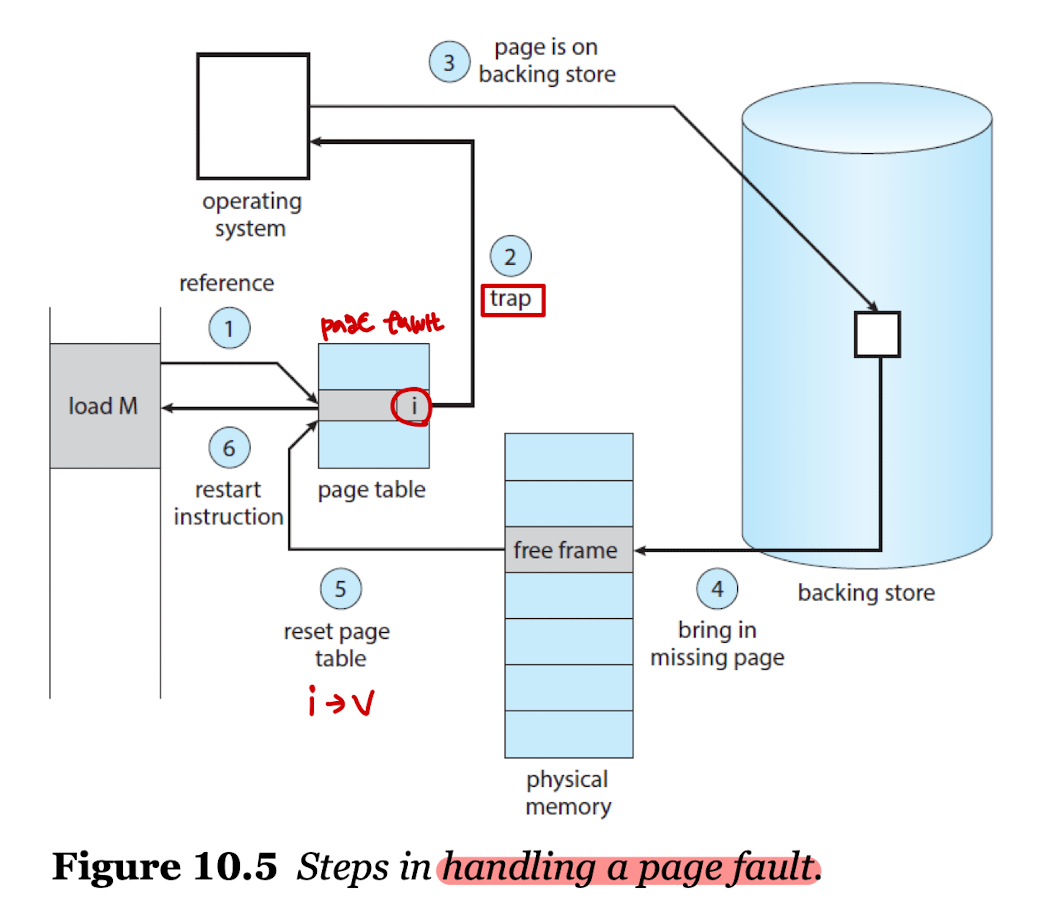
- 페이지 테이블을 확인하여 참고 비트가 유효한지, 아닌지 확인한다.
- 프로세스가 종료됐거나 무효 비트일 경우, 혹은 유효하지만 페이지 결함이 일어나면 페이지 인을 시작한다.
- 비어있는 프레임이 있는지 탐색한다.
(비어있는 프레임의 목록은 O/S가 관리한다.) - 보조 기억 장치를 스케줄링하여 필요한 페이지를 새로 할당된 프레임으로 이동시킨다.
- 이동 완료시 페이지 테이블을 변경하여 페이지가 메모리에 저장되었음을 표시한다.
(invalid -> valid) - O/S 트랩에 의해 중단된 명령을 재시작한다.
Pure Demand Paging
- 순수 요청 페이징은 요청이 없으면 절대 메모리에 적재시키지 않는 방법이다.
- 순수 요청 페이징을 전략을 사용하면, 처음 프로세스를 시작할 때 단 하나의 페이지 로딩 없이 시작할 수도 있다.
- 그렇게 되면 첫 시작부터 바로 페이지 결함이 발생한다.
- 정말 필요할 때만 페이지를 로드하기 때문에, 속도가 상당히 느리나 메모리가 절약되는 장점이 있다.
- 많이 사용하는 방법은 아니며, 보통 프로세스의 일부를 미리 로드하고 시작하는 경우가 많다.
Locality of References
- 이론적으로 프로그램은 실행 시 많은 페이지에 접근한다.
- 명령의 경우 한 페이지, 데이터의 경우 여러 페이지에 접근하며 많은 페이지 결함이 발생할 수 있다.
- 다행스럽게도 프로세스는 참조 지역성(Locality of Referneces)의 특성을 가지고 있어 이를 방지할 수 있다.
- 참조 지역성이란 어떤 데이터가 참조되면, 참조된 그 지역 혹은 시간 근처에서 다시 참조될 가능성이 높은 원칙을 의미한다.
: 시간적 지역성 - 한 번 참조된 지역은 가까운 미래에 계속해서 참조될 가능성이 높다.(반복문, 서브루틴, 스택)
: 공간적 지역성 - 참조된 지역의 근처에 있는 기억장소는 참조될 가능성이 높다.(명령어, 배열 내 요소)
: 순차 지역성 - 프로그램의 명령이 보통 순차적으로 구성되어 있는 것에 기인하여 데이터가 순차적으로 접근할 가능성이 높다.
Hardware Support to Demand Paging
- 요청 페이징 처리를 위해 하드웨어의 지원이 발생한다.
- 페이지 테이블의 경우 위에서 이야기했듯이 페이지가 유효한지, 무효한지 체크한다.
- 보조 기억 장치에서는 메인 메모리에 존재하지 않는 페이지를 보관 및 유지해준다.
Instruction Restart
- 요구 페이징의 중요 조건으로, 페이지 결함이 발생하면 프로세스는 O/S 트랩에 의해
Wait Queue로 이동되고, 페이지 스왑이 완료되면 다시 프로세스를 깨운다. - 즉 컨텍스트 스위칭의 과정이 일어나다가 프로세스가 다시 시작되면 페이지 테이블 보호를 위해 같은 장소, 같은 상태로 시작되게끔 유도해야 한다.
다른 프로세스도 실행 도중 페이지 결함이 발생하면 컨텍스트 스위칭이 일어나는데, 그 때 페이지 테이블로 동시에 접근하는 것을 막기 위함이다. - 명령을 가져오던 중 페이지 결함이 발생하면 다시 명령을 가져와서 재시작해야 하고, 연산 도중 페이지 결함이 발생하면 연산 명령을 가져와 디코딩 한 후 다시 연산을 시작해야 한다.
ADD A, B, C의 경우를 생각해보자.
1.ADD명령을 디코딩하고 가져온다.A변수를 가져온다.B변수를 가져온다.A와B를 더한다.C변수에 결과를 저장한다.
- 이 상황에서 1번이든, 3번이든, 4번이든 어떤 과정 속에서 페이지 결함이 시작되면 페이지 테이블 보호를 위해 1번부터 다시 시작해야 한다.
Free Frame List
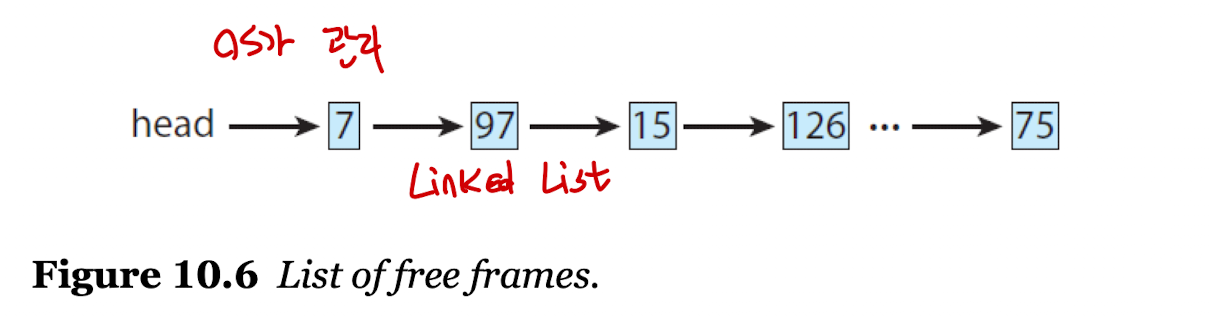
Linked List로 프레임을 관리하는 풀(Pool)로, 페이지 결함을 해결하기 위해 존재한다.- 페이지 결함이 발생하여 보조 기억 장치에서 메모리로 스와핑이 일어날 때 비어있는 프레임 리스트로 접근한다.
- O/S에서 이 리스트를 유지 및 관리하고 있으며, 반드시
stack혹은heap세그먼트로 할당되어야 한다.
Performance of Demand Paging
Effective Access Time
-
요구 페이징에 대한 유효 접근 시간 계산법은 아래와 같다.
: 메모리 액세스 시간을 나타내기 위해ma를 지정한다.
: 페이지 결함이 나타날 확률을 나타내기 위해p를 지정한다. -
EAT=(1 - p) X ma + p X (page fault time)
: 예시 - 페이지 결함을 처리 시간이 8ms, 메모리 접근 시간이 200ns 라고 가정, 페이지 결함이 1000번에 1번(p = 0.001)나타난다고 가정
->EAT= (1 -p) X 200 +pX 8,000,000
->EAT= 200 + 7,999,800 Xp
->EAT= 200 + 7999.8 = 8199.8ns
->EAT= 8.2ms -
페아지 결함 처리를 할 때 많은 시간을 차지하는 주요 작업은 아래와 같다.
: 페이지 결함 인터럽트 처리
: 페이지를 읽어들이는 과정(가장 많은 시간 차지)
: 프로세스 재시작
Copy-on-Write
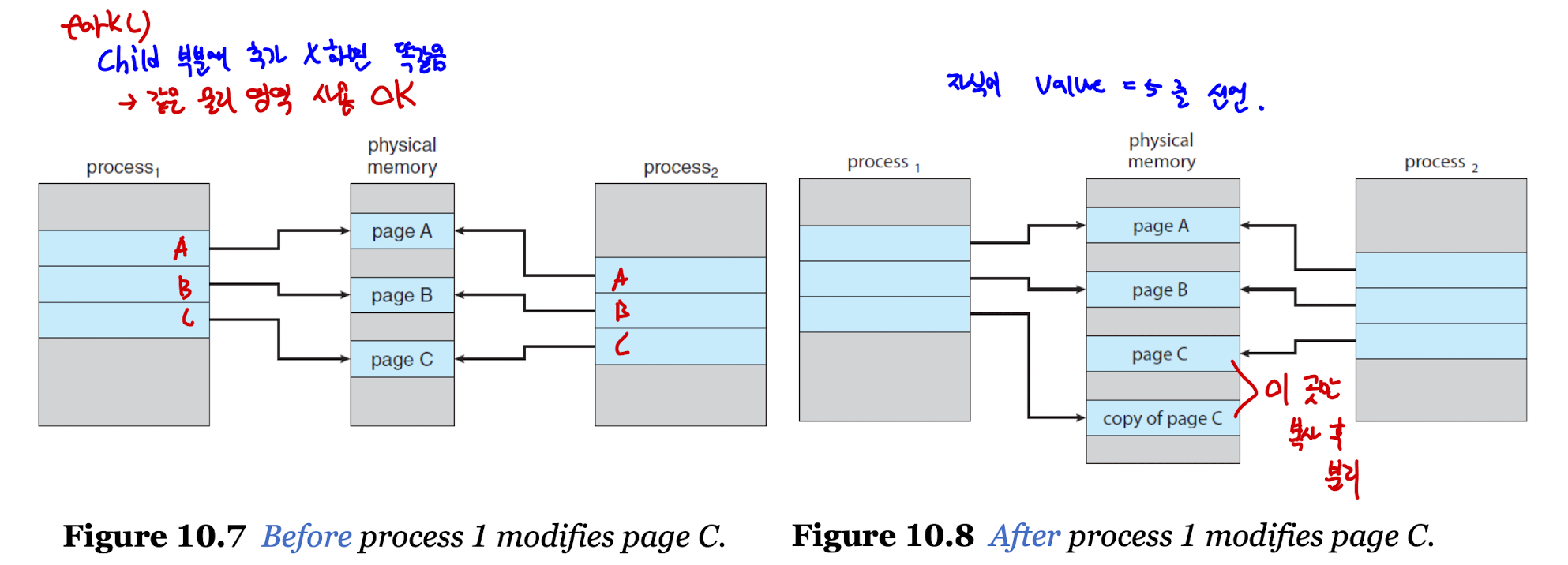
- 프로세스가 공유 페이지를 작성 혹은 수정할 경우 공유 페이지를 따로 복사하는 것을 의미한다.
- 공유 페이지를 변경하면 다른 프로세스가 영향을 받을 수 있기 때문에 이를 방지하기 위해 사용한다.
fork()를 사용할 때의 상황을 생각해보면 이해가 쉽다.- 자식 프로세스가 공유 페이지 일부를 변경
- 변경이 일어나기 전 해당 페이지를 복사
- 부모 프로세스는 복사한 공유 페이지에 포인터를 이동
- 자식 프로세스는 사용하던 공유 페이지 그대로 사용
- 변경이 일어나면 위의 과정 반복
- 요구 페이징을 구현할 때 고민해봐야 할 점은 아래와 같다.
- 어떤 프로세스에 몇 개의 프레임을 할당할지(Frame-allocation algorithm)
- 빈 리스트가 없을 때 어떤 프레임을 희생시킬지(Page-replacement algorithm)
- 기본적으로 보조 기억 장치의 I/O 작업은 시간이 오래 소요되므로, 페이지 결함을 줄임으로서 I/O 작업을 줄인다면 시스템 퍼포먼스를 크게 향상시킬 수 있다.
Page Replacement
- 페이지를 할당해야 하는 상황에서, 빈 프레임 리스트가 없으면 어떻게 해야할까?
- 기존 프레임에 있는 페이지 중 하나를 선정해 스왑 영역으로 이동시키고, 현재 사용해야 할 페이지를 메모리 내에 이동시켜야 한다.
Page Fault Service include Page Replacement
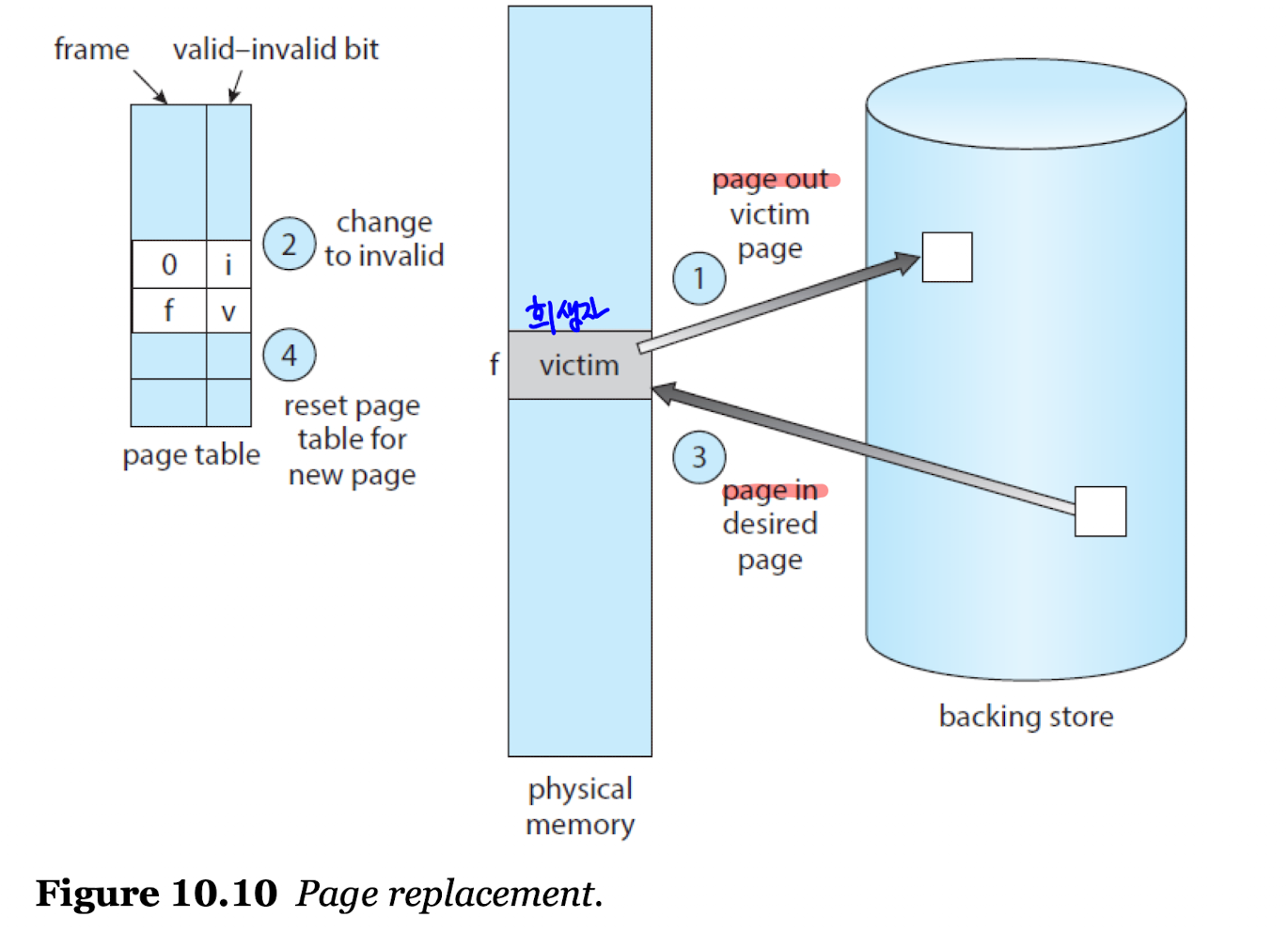
- 페이지 교체와 함께 하는 페이지 결함 처리 서비스는 아래와 같이 진행된다.
- 보조 기억 장치에서 할당할 페이지의 위치를 찾는다.
- 빈 프레임 리스트를 찾는다.
-> 빈 프레임이 있을 경우 그대로 사용한다.
-> 빈 프레임이 없으면 PR 알고리즘을 통해 희생시킬 프레임을 선정한다. - 희생자로 선정된 프레임을 보조 기억 장치로 이동시키고, 페이지 테이블의 정보를 변경한다.
- 할당할 페이지를 새롭게 희생시키고 남은 빈 프레임에 할당시킨다.
- 페이지 결함의 나머지 서비스를 진행한다.
Evaluation of Page Replacement Algorithms
- PR 알고리즘의 최종 목표는 페이지 결함 발생을 최대한 줄이는 것이다.
- 프레임의 수가 많아질수록 페이지 결함 역시 줄어든다.
- 여러 페이지 변경 알고리즘이 존재한다.
- 비교를 위해 기준은 아래와 같이 선정한다.
: 참조 문자열 -7 - 0 - 1 - 2 - 0 - 3 - 0 - 4 - 2 - 3 - 0 - 3 - 0 - 3 - 2 - 1 - 2 - 0 - 1 - 7 - 0 - 1
: 메모리 안에는 3개의 프레임이 들어갈 수 있다.
FIFO Page Replacement
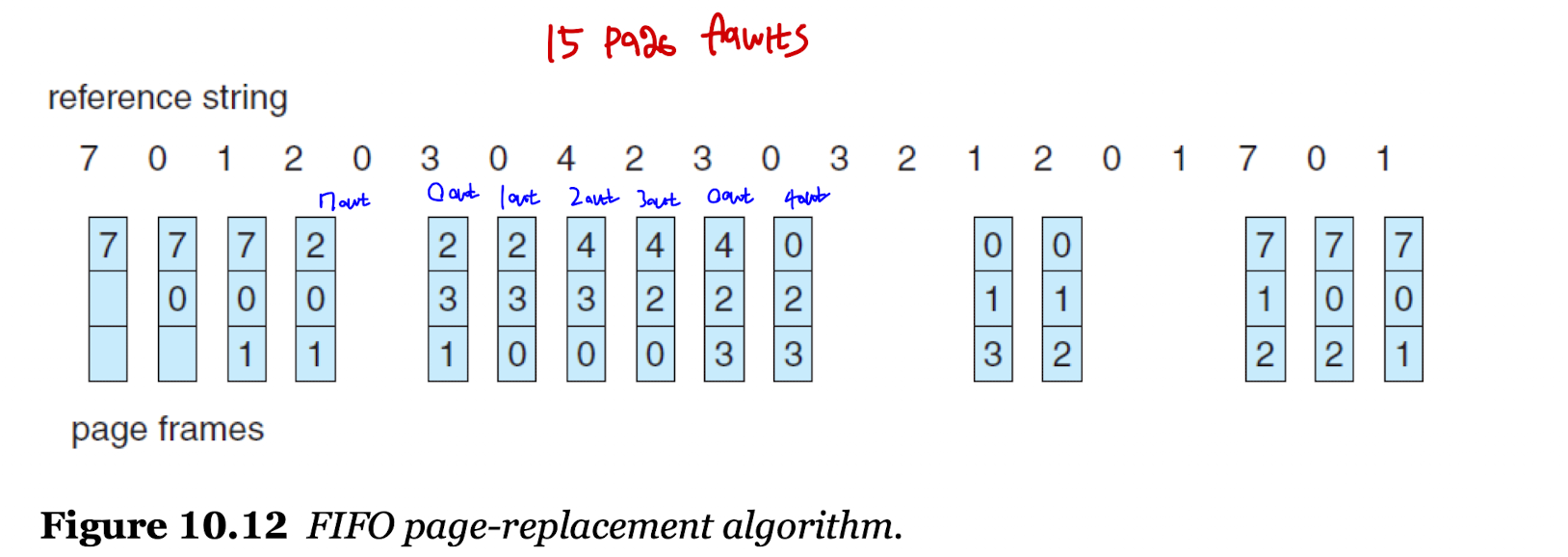
- 먼저 들어온 프레임을 먼저 희생자로 선정하는 가장 간단한 알고리즘이다.
- 기준에 맞춰 페이지 교체를 실시하면 15번의 페이지 결함이 일어난다.
- 벨라디의 모순(Belady's Anomaly)이 발생한다.
벨라디의 모순
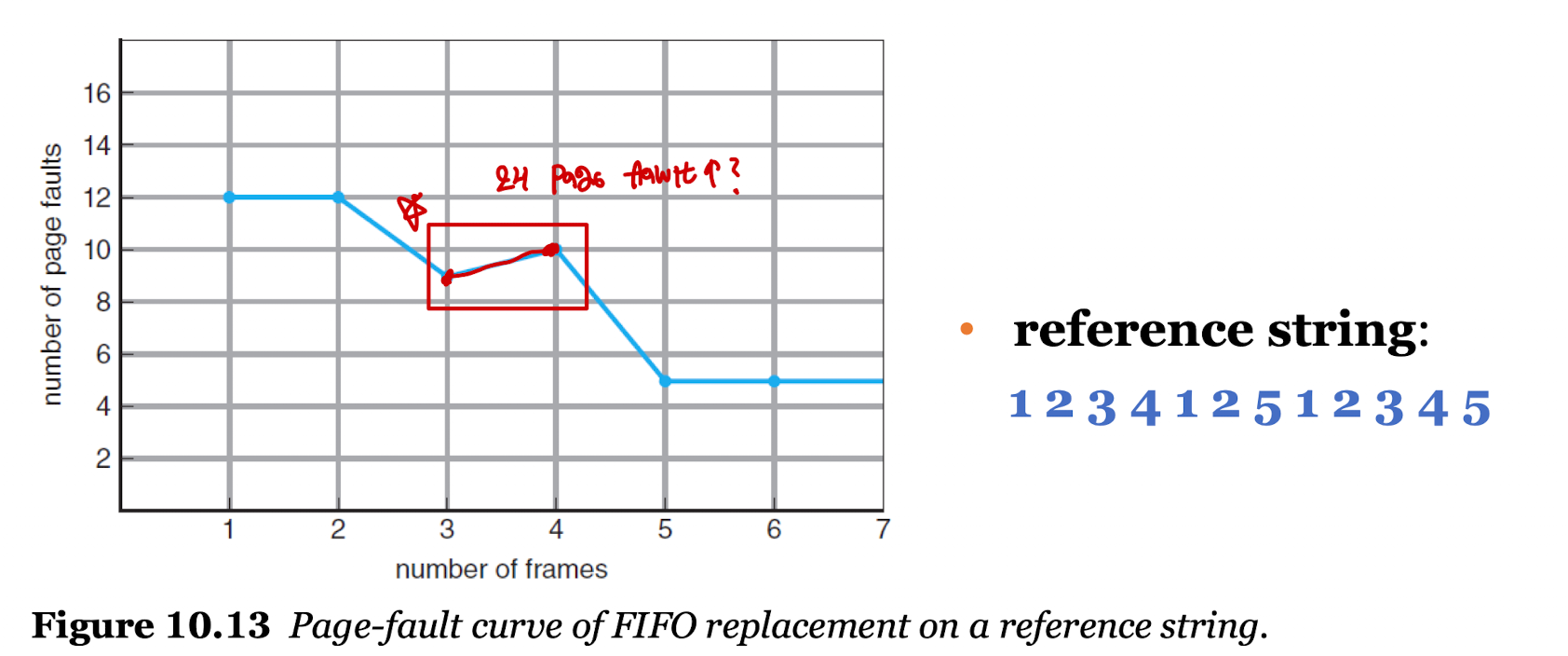
- 원래 프레임의 수가 많아지면 페이지 결함 발생의 수가 적어져야 정상이다.
- 하지만 원칙에 맞지 않게 프레임의 수가 많아졌음에도 페이지 결함의 발생 수가 늘어나는 현상을 의미한다.
Optimal Page Replacement
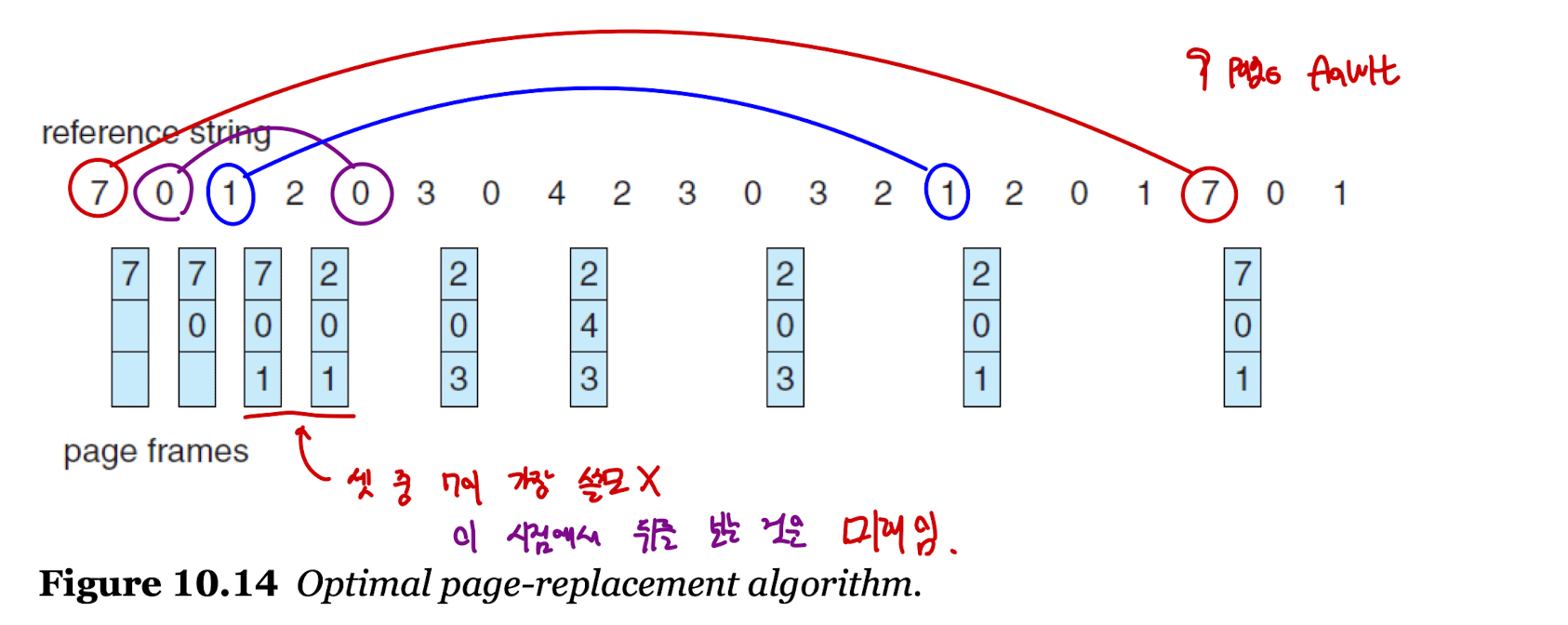
- 가장 최적의 알고리즘으로, 앞으로 가장 오랫동안 사용하지 "않을" 프레임을 희생자로 선정하는 알고리즘이다.
- 페이지 결함이 가장 적게 발생하는 알고리즘이며 벨라디의 모순을 걱정하지 않아도 된다.
- 기준에 맞춰 페이지 교체를 실시하면 9번의 페이지 결함이 일어난다.
- 그러나, 실행되는 시점에서는 미래에 어떤 페이지가 올지 알 수 없기 때문에 실질적으로 적용할 수 없는 알고리즘이다.
- 때문에, 주로 비교 연구에 사용한다.
LRU Page Replacement
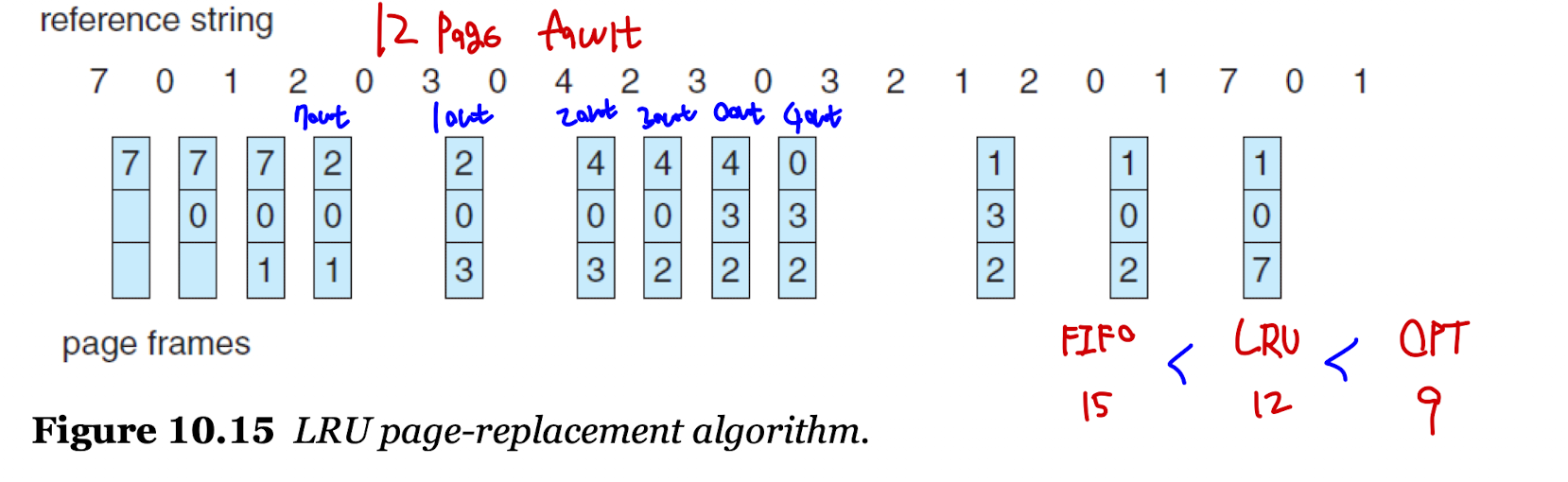
- LRU : Least Recently Used
- 가장 오랫동안 사용하지 "않은" 프레임을 희생자로 선정하는 알고리즘이다.
- 최적 알고리즘 방식과 비슷한 성능을 내기 위해 고안한 알고리즘이다.
- 앞으로 사용할 페이지를 "예측"하여 희생자를 선정하는 방법으로, 과거에 오랫동안 사용하지 않았다면 미래에도 많이 사용하지 않을 것이라고 예측하는 것이다.
- 기준에 맞춰 페이지 교체를 실시하면 12번의 페이지 결함이 일어난다.
- 성능이 높아 실제 자주 사용하고, 벨라디의 모순을 걱정하지 않아도 된다.
Two Implementation methods for the LRU
- LRU 알고리즘을 구현하기 위해서는 프레임이 언제 마지막으로 사용됐는지에 대한 정보를 저장해야 하고, 이를 위해 하드웨어의 지원을 받는 두 가지 구현 방법이 있다.
- Counter 를 이용한 구현법
: 페이지 참조가 발생할 때마다 시간을 체크하는 방법으로, 페이지 변경이 일어나야 하는 경우 가장 시간이 오래된 프레임을 희생자로 선정한다.
: 페이지 변경이 필요할 때 페이지 테이블에서 가장 오래된 것을 찾아야 하고, 페이지 테이블이 변경될 때마다 페이지의 시간도 함께 변경해야 하는 단점이 있다.
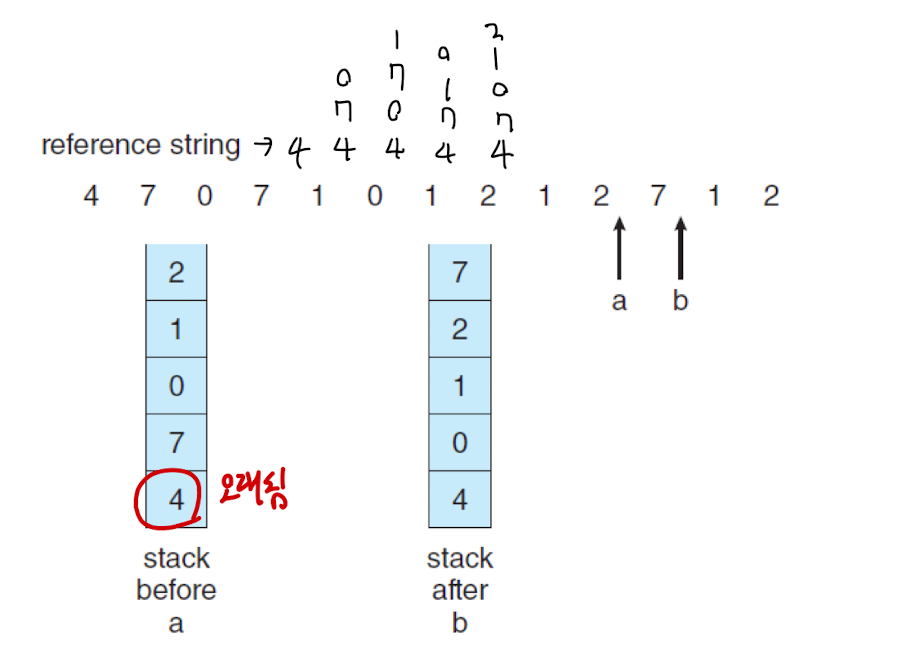
- Stack 을 이용한 구현법
: 페이지 참조가 발생할 때마다 스택에 페이지 넘버를 저장하는 방법이다.
: 기존 스택과 차이점은 스택 안에 똑같은 페이지 넘버가 있을 경우 이를 제거하고 다시 맨 위에 페이지 넘버를 등록한다.
: 결과적으로, 가장 오래된 페이지는 가장 아래에 위치해있기 때문에 희생자로 선정하면 된다.
LRU-Approximation Page Replacement
-
기본적으로 LRU 알고리즘은 하드웨어의 지원을 받아야만 구현이 가능했으나, 참조 비트(Reference bit)를 사용하면 하드웨어의 지원을 받지 않고 LRU 알고리즘을 구현할 수 있다.
-
참조 비트
: 기본적으로 비트의 값은 0이며, 각 페이지에 할당된다.
: 페이지가 참조되면 값을 1로 설정한다.
: 비트의 값이 0인 페이지를 희생자로 선정한다.
Second-Chance Algorithm
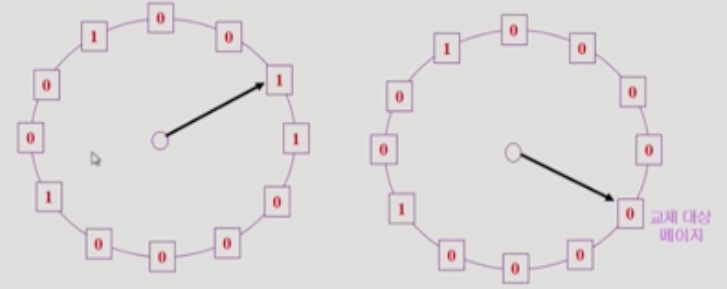
- FIFO 페이지 교체 알고리즘을 보완해서 만든 알고리즘이다.
- 페이지 교체가 필요하면 먼저 들어온 페이지의 참조 비트부터 검색한다.
: 만약 값이 0이면, 그대로 교체를 진행한다.
: 그러나 값이 1이면, 비트의 값을 0으로 설정하고 다음 페이지로 넘어간다. - 다음번에도 검색했을 때 값이 1이라면, 자주 참조되는 페이지임을 의미하므로, 교체하지 않을 것이다.
- 마지막으로 모든 비트가 1로 설정된다면 먼저 들어온 것부터 페이지 교체를 진행한다.
Allocation of Frames
- 어떤 프로세스에게 얼마만큼의 프레임을 할당하는 것이 좋을까?
- 프로세스가 당장 수행해야 할 부분에 대해 최소한의 프레임을 할당하는 것이 효율이 좋을 것이다.
- 이를 고민하며 만들어진 여러 프레임 할당 전략이 존재한다.
The strategies for frame allocation
-
동일하게? 비례하게?
: 동일 할당 - 모든 프로세스에게 같은 프레임을 할당해주는 것을 의미한다.
: 비례 할당 - 프로세스의 크기에 비례하여 프레임을 할당해주는 것을 의미한다. -
희생자 선정을 어디서 할건지?
: 지역 교체 - 프로세스 내부에서 희생자 프레임을 선정하는 방법이다.
: 전역 교체 - 시스템 내의 모든 프로세스에서 희생자 프레임을 선정하는 방법이다.
Thrashing
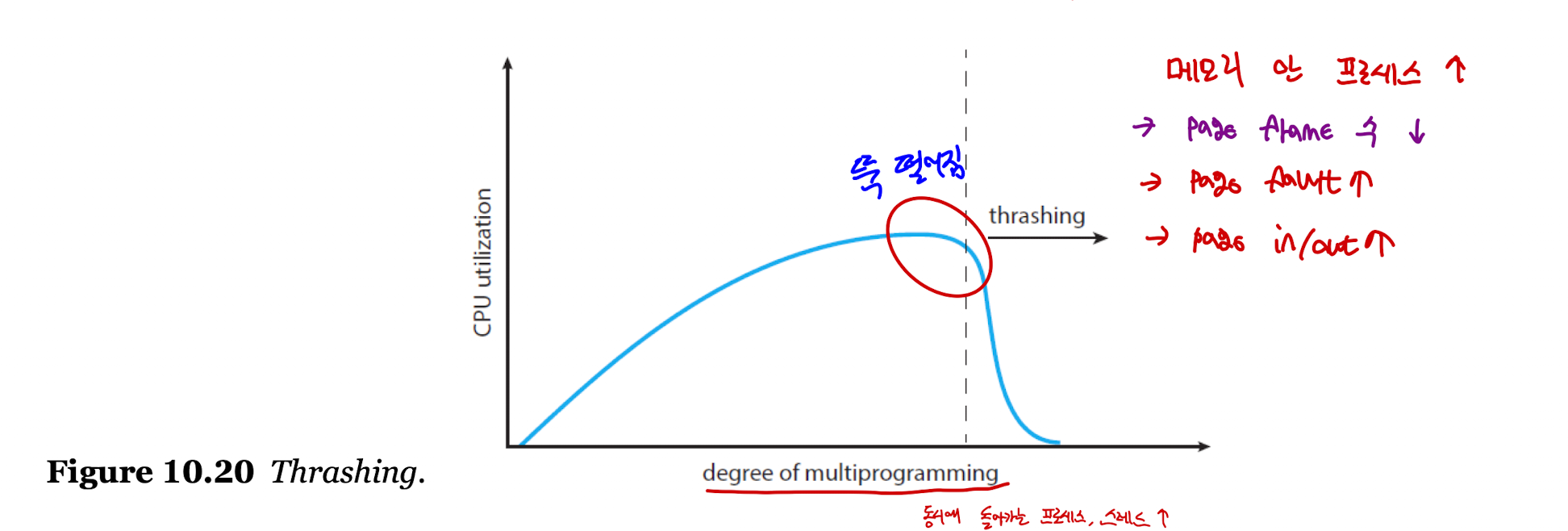
- 프로세스의 실제 작업 수행 시간보다 페이지를 스와핑하는 시간이 더 오래 걸리는 현상을 의미한다.
- 원리
- 멀티프로그래밍의 빈도가 늘어날 수록, 즉 프로세스를 많이 실행할 수록 프로세스에게 할당되는 프레임의 양은 줄어들 것이다.
- 프로세스에 충분한 프레임이 할당되지 않는다면, 빈 프레임 리스트의 크기가 줄어들 것이다.
- 그렇다면 페이지 결함의 발생이 늘어나 페이지를 스와핑하는 시간이 길어질 것이며, 실제 작업 수행 시간은 줄어들 것이다.
- 이로 인해 CPU의 효율은 급격하게 떨어질 것이다.
- CPU 효율이 감소되면 O/S는 효율을 높이기 위해 또 다른 프로세스를 실행하게 된다.
- 악순환이 반복되어 나중에는 CPU가 다운된다.
- 이를 방지하기 위해 시스템에 올라가는 프로세스의 양을 조절해야 할 필요가 있다.
- 위에서 이야기했던 참조 지역성을 다시 떠올려보면, 해결의 실마리가 될 수 있다.
: 프로세스는 특정 시간동안 일정 지역을 집중적으로 참조한다.
: 집중적으로 참조되는 페이지 집합을 지역 집합(Locality set) 이라고 한다.
Working-Set Model
- 프로세스가 일정 시간동안 원활하게 수행되기 위해 한꺼번에 메모리에 올라와 있어야 하는 페이지들의 집합을 Working-set 이라고 한다.
- 프로세스의 워킹셋 전체가 메모리에 올라와 있지 않다면 실행 자체를 하지 않고 모든 프레임을 반납한 후 스스로 스왑 아웃한다.
- 일부 프로세스가 스왑 아웃되면 나머지 프로세스의 워킹셋은 충족할 수 있을 것이고, 모두 실행할 수 있게 된다.
- 나머지 프로세스의 실행이 모두 종료되고 스왑 아웃되었던 프로세스의 워킹셋을 충족할 수 있게 된다면 그 때 프레임을 할당하고 스왑 아웃된 프로세스를 실행한다.
- 프로세스의 실행 기준을 높였으므로, 시스템에 올라가는 프로세스의 양은 자연스럽게 조절될 것이고, 그럼으로서 스레싱을 방지한다.

- 워킹셋의 크기 할당은 워킹셋 윈도우(working-set window)를 통해 결정한다.
- 워킹셋 윈도우의 크기를 10으로 정하고, 현재 시점을
t1이라고 가정해보자.
:t1의 시점에서 이전 10개의 페이지를 보았을 때 워킹셋은{1,2,5,6,7}이다.
: 시스템에서 프로세스에게 5개의 프레임을 할당해주면, 프로세스를 실행한다.
: 그러나 5개 이상을 할당해주지 못한다면 프로세스는 모든 프레임을 반납 후 스왑 아웃한다.
- 워킹셋 윈도우의 크기를 너무 적게 지정하면 지역 집합을 모두 수용하지 못할 수 있다.
- 그렇다고 너무 많은 크기를 지정하면 여러 지역 집합이 모여 효율이 떨어질 수 있다.
- 적절하게 워킹셋 윈도우의 크기를 지정하는 것이 중요하다.
참고 및 출처
기억 장치 계층 구조
LRU(Least-recently-used) Page Replacement
이화여자대학교 운영체제 강의 - 반효경 교수님
