
⚠️ 해당 포스팅은 인프런 공룡책 강의를 듣고 개인적으로 정리하는 글입니다. 정확하지 않은 정보가 있을 수 있으니 주의를 요합니다.
Section 10
Chapter 9 Main Memory
Background
- 프로세스는 실행 중인 프로그램, 즉 메인 메모리에 명령어 모음이 로드되어 있는 것을 의미한다.
- 메모리는, 대량의
byte배열로 구성되어 있고, 각각 독자적인 주소를 가지고 있다. - CPU는 주소가 저장되어 있는 프로그램 카운터를 이용해 명령어 모음을 가져오고, 해당 명령어 모음은 메모리에 로드되거나 저장될 수 있다.
- 일단, 각 프로세스에 별도의 메모리 공간이 있는지 확인이 필요하다.
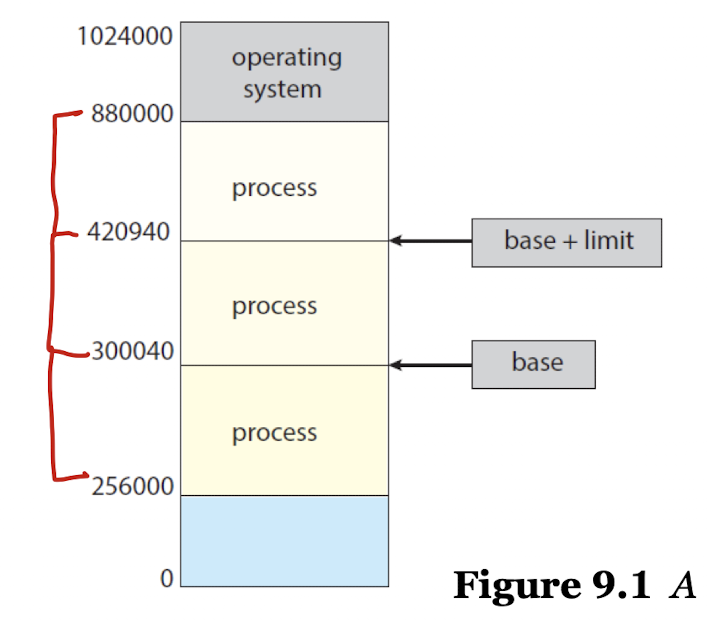
- 이를 위해 베이스 레지스터(Base Register)와 리미트 레지스터(Limit Register)를 사용하는데, 이 두 레지스터를 이용해 정규 주소의 범위를 결정한다.
- 만약 이 범위를 벗어나면 흔히 보는 에러인
Segmentation Fault가 발생한다.
- 그렇다면, 메모리 공간을 보호하기 위해서는 어떻게 해야할까?
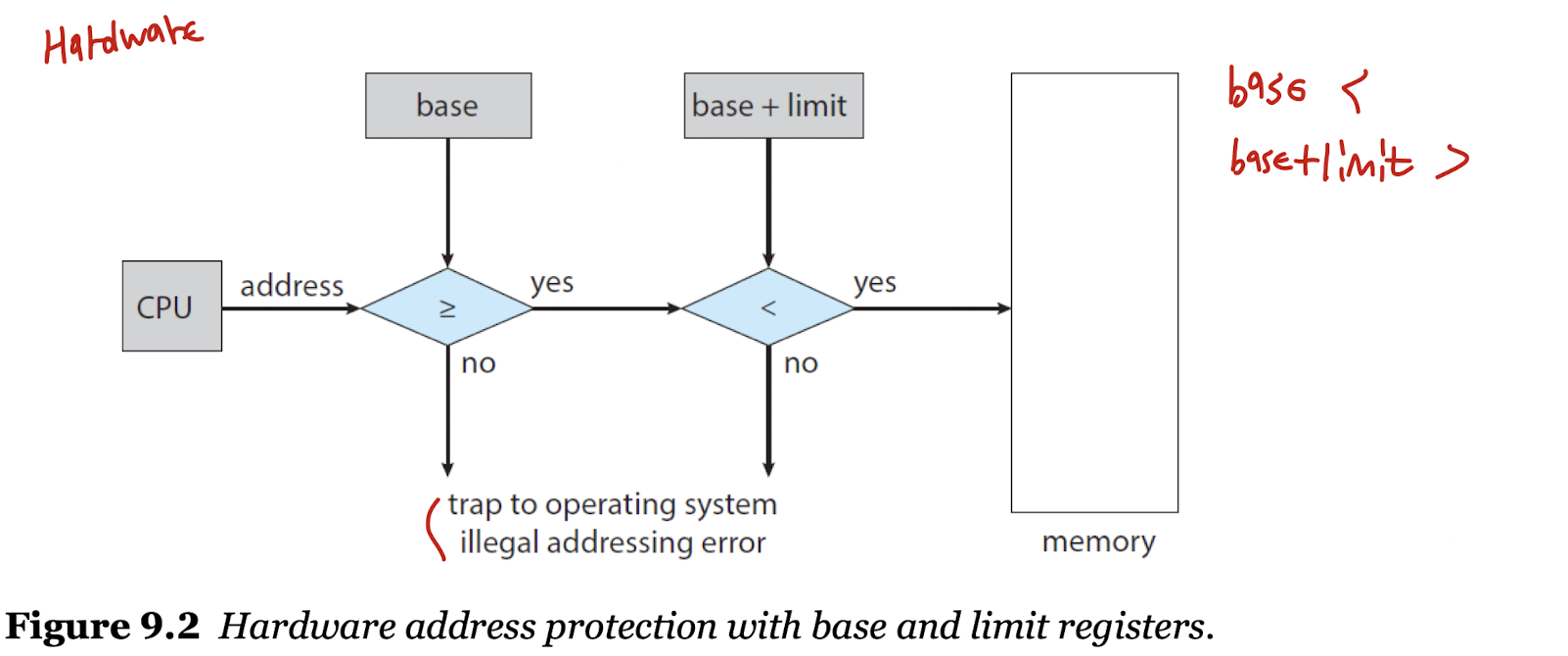
- 이는 CPU 하드웨어를 통해 보호되는데, 하드웨어가 사용자 모드에서 생성된 모든 주소를 레지스터와 비교하고, 범위를 벗어나면 인터럽트를 발생시켜 잘못된 접근임을 유저에게 알린다.
Address Binding
- 기본적으로 프로그램은 실행되기 전에는 그저 바이너리 실행 파일로서 디스크에 위치한다.
- 그리고, 프로그램 실행을 위해 메인 메모리에 올라가는 순간 프로세스가 된다.
- 실행된 프로세스의 초기 주소는
00000000으로 시작되지 않는다.
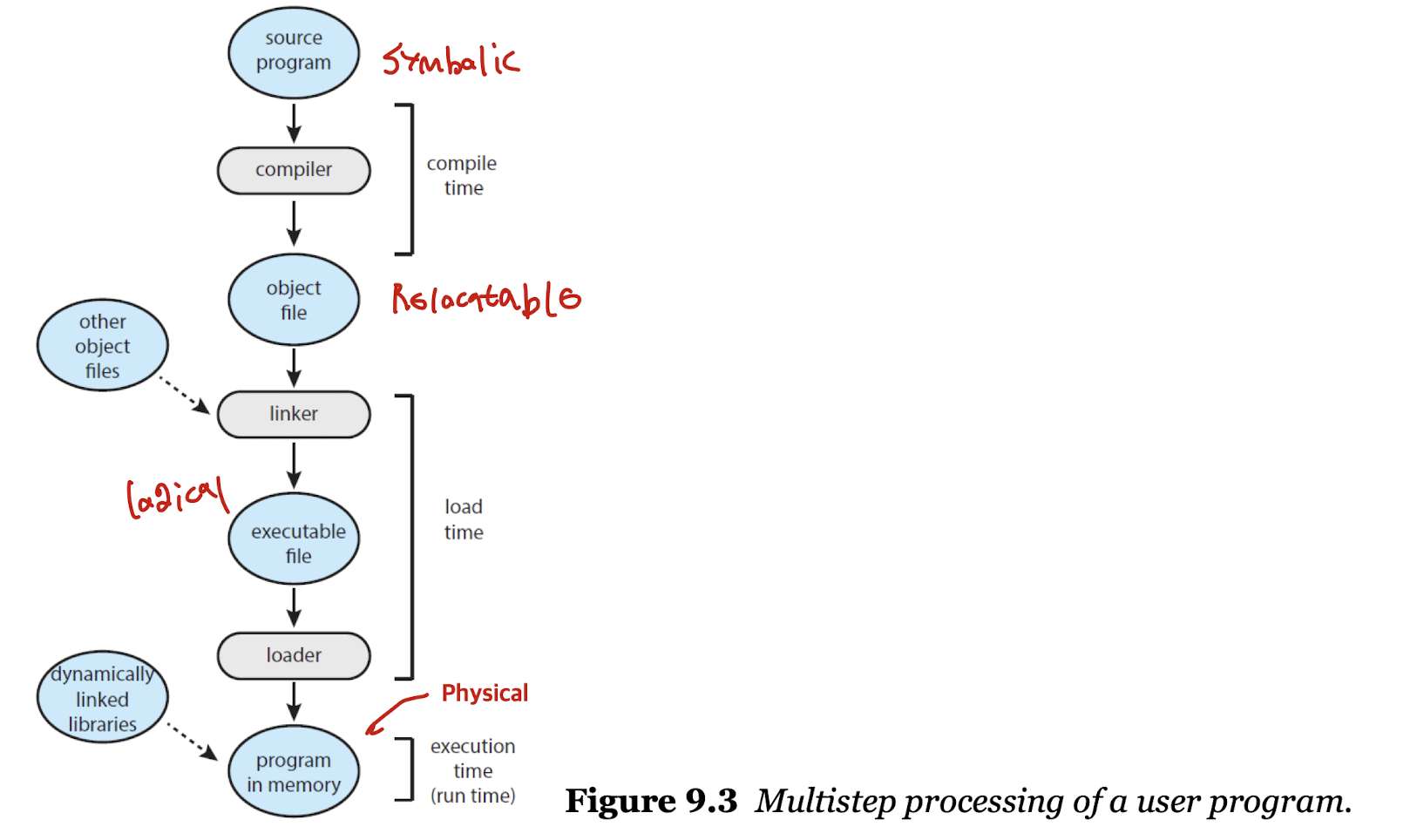
- 초기 소스 코드는 심볼릭한 상태이다.
(int a = 5) - 이후 컴파일러를 거치며 소스 코드의 주소를 재배치(relocatable) 가능한 주소에 바인딩한다.
- 링커를 거치면 논리적(logical) 주소로 바인딩되고, 로더(loader)를 거쳐 절대적(absolute) 주소로 바인딩된다.
- 즉, 매 단계마다 다른 주소 바인딩이 일어난다.
Logical vs Physical Address Space
- 논리적 주소 : CPU에 의해 생성된 주소를 일컫는다.
- 물리적 주소 : 메모리 주소 레지스터에 로드된, 즉 실제 하드웨어 상의 주소를 일컫는다.
- 논리적 주소를 물리적 주소에 매핑할 땐 서로간에 관계가 전혀 없는, 분리된 상태여야 한다.
MMU(Memory Management Unit)
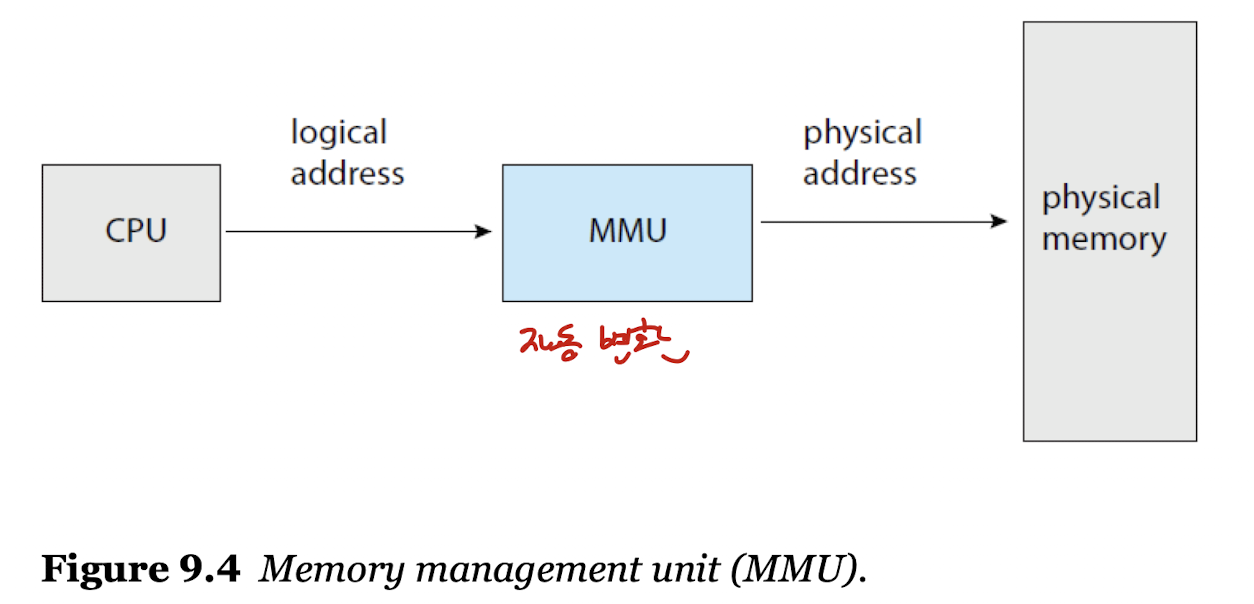
- 논리적 주소를 물리적 주소에 매핑하기 위해 사용하는 하드웨어이다.
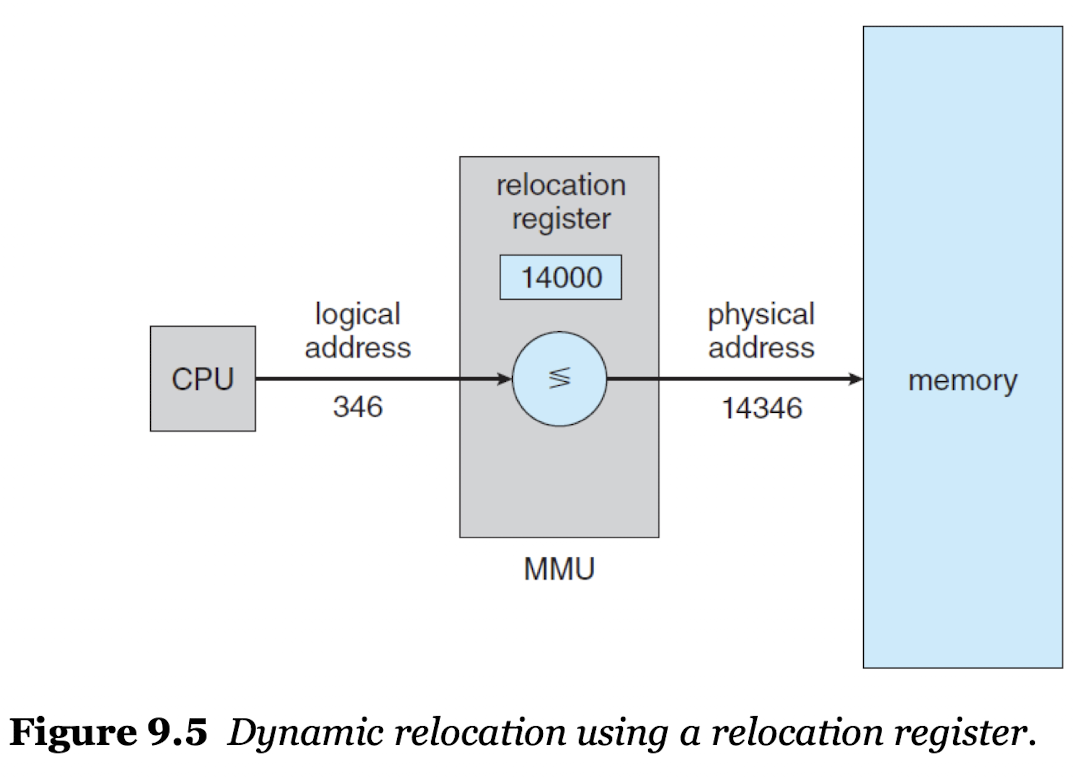
- Relocation Register : MMU의 베이스 레지스터로, CPU에서 전달받은 논리적 주소를 특정 규칙에 맞춰 물리적 주소에 매핑해준다.
Dynamic Loading
- 프로그램, 데이터 전체를 물리 메모리 공간에 저장한다면, 효율이 떨어질 것이다.
- 이 때 동적 로딩을 이용하는데, 이 동적 로딩은 모든 루틴을 한번에 로드하지 않음으로서 메모리 공간의 효율적 사용을 도와준다.
- 즉, 오로지 필요할 때만 루틴을 로드하는 것이다.
Dynamic Linking and Shared Libraries
- DLLs : Dynamically Linked Libraries
: 프로그램 실행 도중 사용자 프로그램에 링킹될 수 있는 라이브러리를 의미한다. - 정적 링킹(Static Linking)은 시스템 라이브러리가 다른 오브젝트 모듈과 마찬가지로 로더에 의해 바이너리 프로그램 코드로 합쳐지는 것을 의미한다.
:코드에 시스템 라이브러리를 함께 담는 것이다. - 동적 링킹은 실행 시간에 링킹을 실행하는 것을 의미한다.
: 실행 중DLL파일을 원하면 메인 메모리 내의DLL인스턴스에 접근하여 사용하고, 본래의 코드 흐름으로 돌아오는 것이다.
: 메인 메모리에DLL인스턴스가 있으니, 당연히 여러 프로세스간 공유가 가능하다.
Contigious Memory Allocation
- 효율적으로 메인 메모리를 할당하는 방법 중 하나로, 연속 메모리 할당을 고려해볼만 하다.
- 우선, 메모리는 통상적으로 두 개의 파티션으로 분리된다.
: 운영체제용 파티션
: 유저 프로세스용 파티션 - 여러 유저 프로세스는 메모리에 동시에 머무를 수 있어야 하기 때문에, 사용 가능한 메모리를 어떻게 할당할지 결정해야 한다.
- 연속 메모리 할당은 프로세스를 여러 구역이 아니라 단일 구역에 할당한다. 즉 연속적으로 할당한다.
Memory Protection
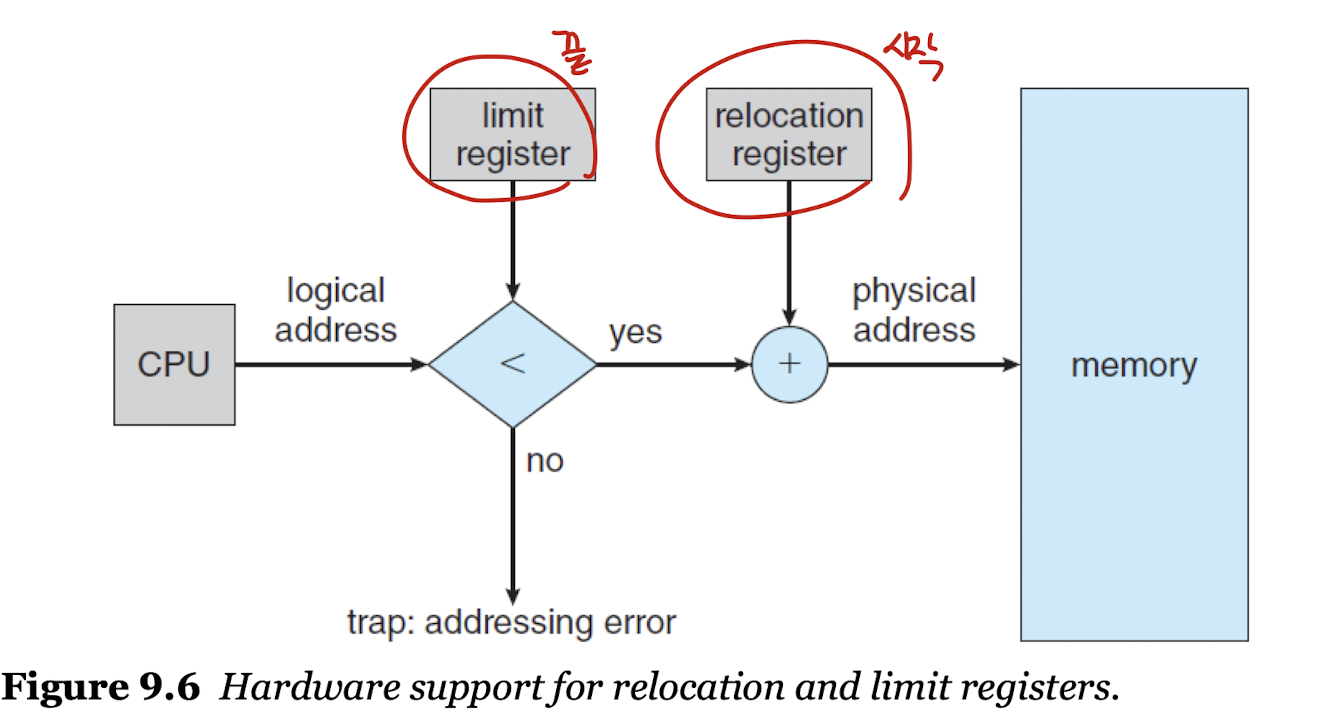
- 연속 메모리 할당에서 메모리를 보호하기 위해서, 재배치 레지스터와 리미트 레지스터 사이에서만 프로세스가 할당될 수 있게 한다.
Memory Allocation
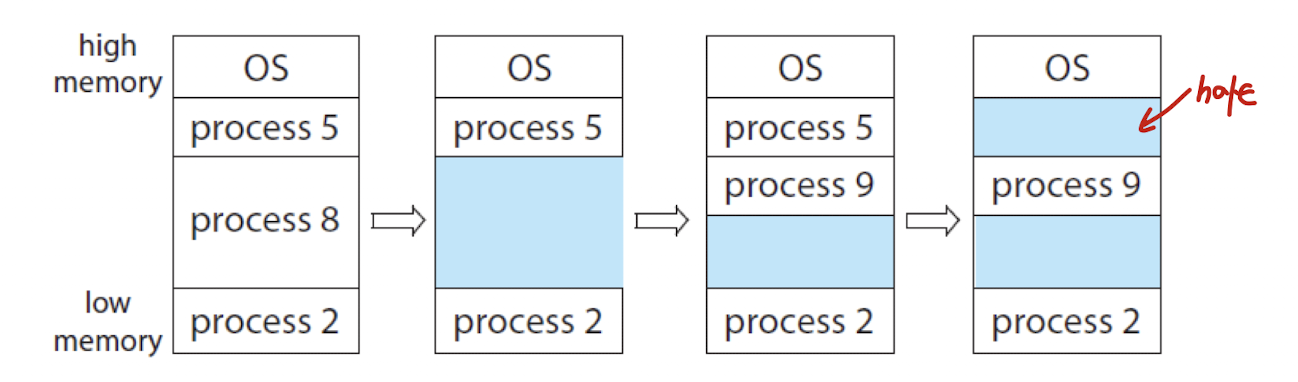
- 메모리 할당을 위해 사용하는 방법 중 하나로 가변 파티션(Variable-Partition) 방식이 있다.
- 메모리에 할당되는 프로그램의 크기에 따라 분할의 크기 혹은 수가 계속해서 변하는 방식이다.
- 그리고 사용 가능한 블럭을 홀(hole)이라고 칭한다.
: 프로세스가 도착하면, 공간이 넉넉한 홀을 할당하는 것이다. - 이 홀에 프로세스를 할당하는 만큼, 홀을 잘 관리해야 메모리를 효율적으로 사용할 수 있을 것이다.
: 이를 판단하기 위해 도와주는 방법이 세 개 있다.
: First-Fit : 할당할 수 있는, 즉 크기가 맞는 홀이 보이면 바로 할당하는 방법
: Best-Fit : 할당할 수 있는 가장 작은 홀에 할당하는 방법
: Worst-Fit : 할당할 수 있는 가장 큰 홀에 할당하는 방법
Fragmentation
- 연속 메모리 할당을 진행하다보면, 메모리가 존재하지만 사용 불가능한, 즉 단편화의 문제가 발생한다.
- 외부 단편화(external fragmentation)
: 메모리 공간이 작은 홀로 나뉘어져 있어 충분한 메모리 공간이 있음에도 할당을 받을 수 없는 상태를 의미한다.
50MB가 할당이 가능한 상태에서, 3MB의 메모리 할당 요청이 들어와도 2MB로 메모리가 나뉘어져 있어 할당을 받지 못한다.
: 이를 해결하기 위해서는 사용중인 메모리 영역을 한 곳으로 몰고 홀들도 한 곳으로 합쳐 큰 메모리 공간을 만드는, 즉 압축으로 해결한다. - 내부 단편화(internal fragmentation)
: 프로세스가 필요로 하는 양보다 더 크게 메모리를 할당해 공간이 낭비되는 상태를 의미한다.
Paging
- 연속 메모리 할당과는 반대로, 프로세스의 물리적 주소 공간을 연속적이지 않게 배치하는 방법이다.
- 외부 단편화 문제와 압축 문제를 해결할 수 있는 방법이다.
- 운영체제와 컴퓨터 하드웨어의 도움을 받아 구현할 수 있다.
- 페이징의 기본적인 방법
: 물리적 메모리를 고정된 크기로 잘라 프레임(frames)으로 나눈다.
: 논리적 메모리를 프레임과 같은 크기, 즉 고정된 크기로 잘라 페이지(page)로 나눈다.
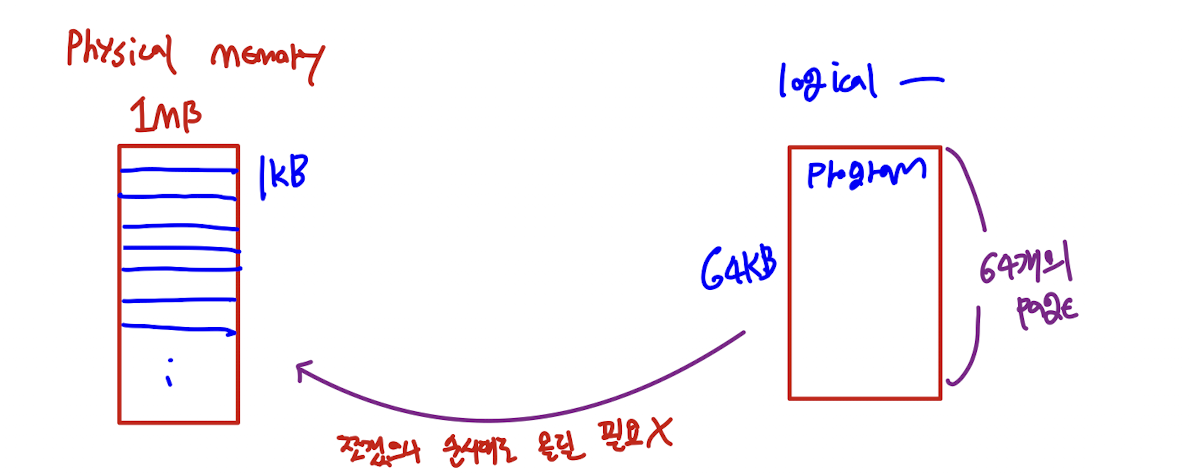
- 연속 메모리 할당 때처럼 프로그램 전체를 한번에 올릴 필요 없이, 조각을 물리적 메모리의 위치에 맞게 할당시키면 된다.
- 논리적 주소 공간과 물리적 주소 공간이 완전히 분리되어 물리적 주소 공간을 크게 고려하지 않아도 되고, 이 둘 사이의 매핑은 운영체제가 알아서 진행해준다.
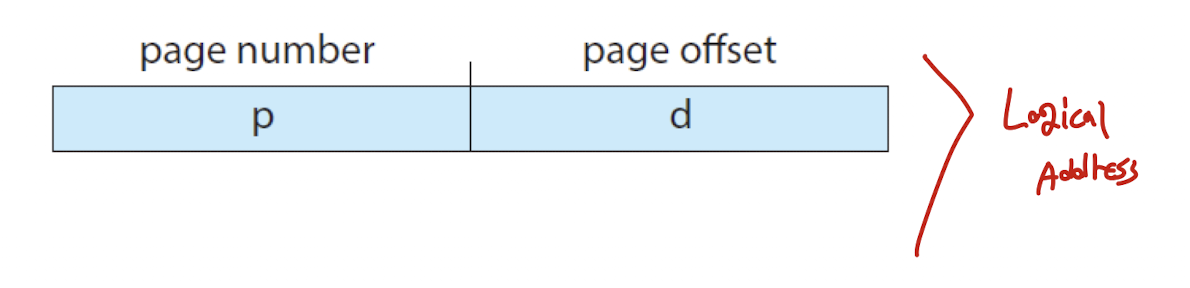
- CPU에 의해 생성되는, 즉 논리적 주소는 두 파트로 분류된다.
- 페이지 넘버와 페이지 간격으로 분류되는데, 이는 하나의 프로세스라도 한번에 물리적 메모리 공간에 올리는 것이 아니라, 페이지 단위로 물리적 메모리에 올리는 위치가 모두 다르기 때문에 위의 두 파트를 이용하는 것이다.
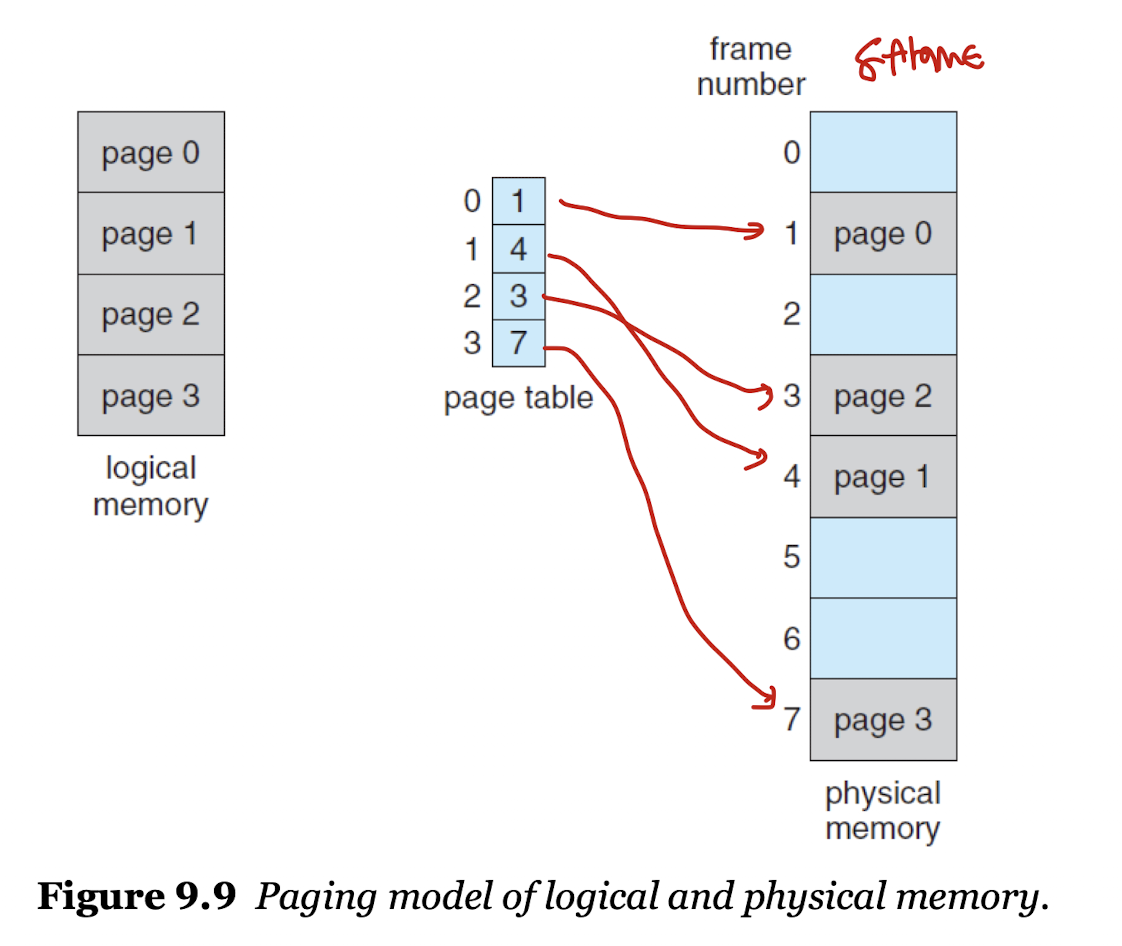
- 두 파트를 이용하여 어떤 프로세스의 몇 번째 페이지가 물리적 메모리의 어느 공간에 위치해 있는지 알 수 있다.
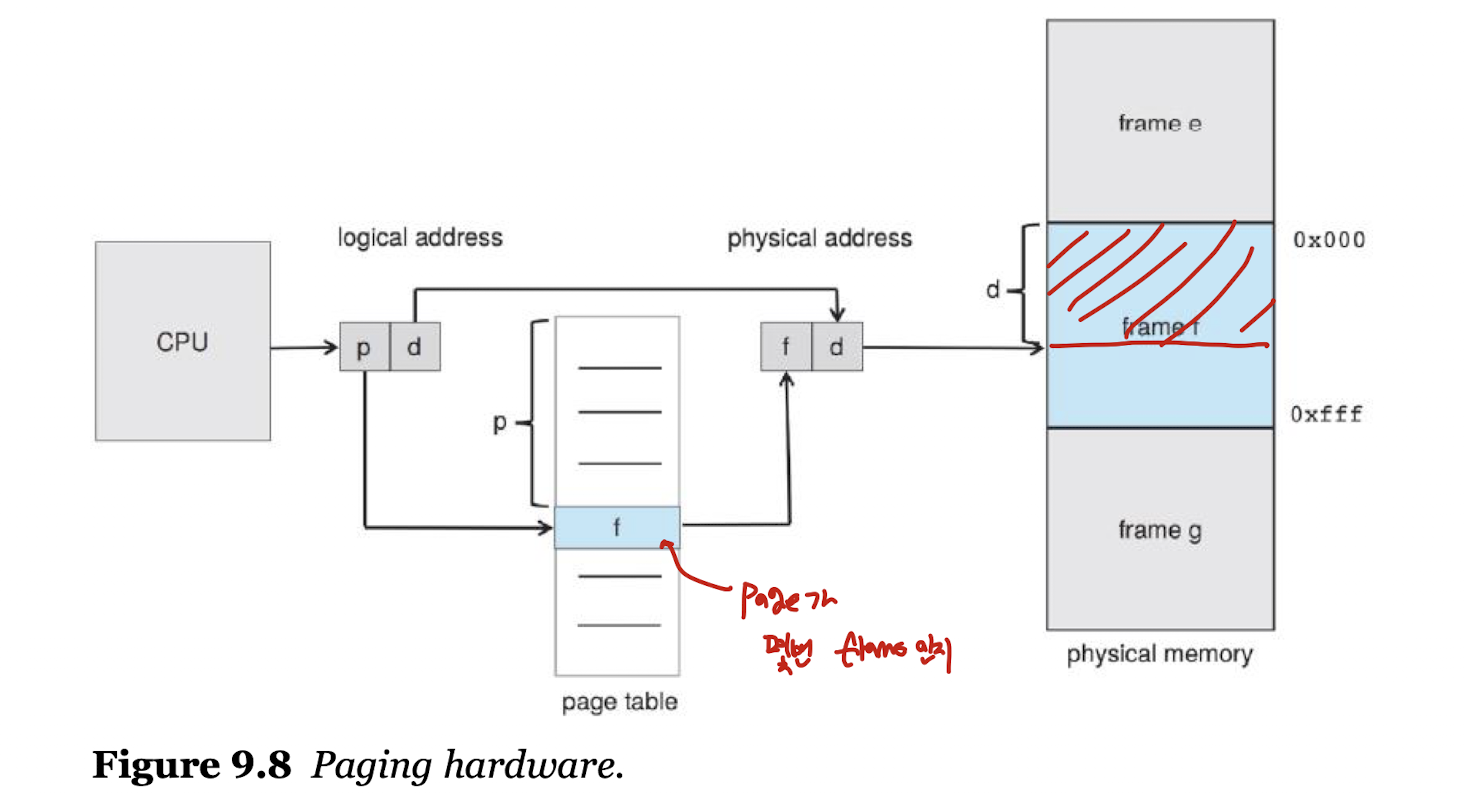
- 모든 프로세스는 주소 변환을 위해 페이지 테이블을 가진다.
- 페이지 넘버는 프로세스별 페이지 테이블의 인덱스값으로 사용된다.
프로세스 1의 페이지, 프로세스 3의 페이지가 섞이면 안되니, 페이지 테이블을 통해 프로세스의 페이지들이 연달아 실행될 수 있도록 하는 것이다.
- CPU 실행의 순서
- 페이지 번호 P를 추출하여 페이지 테이블의 인덱스로 사용한다.
- 페이지 테이블에서 대응하는 프레임 번호 F를 추출한다.
- 페이지 번호 P를 프레임 번호 F로 바꾼다.
- 그렇다면, 페이지 사이즈는 어떤 식으로 정해지는 걸까?
- 이는 하드웨어에 의해 정해지는데, 기본적으로 2의 배수여야 하고 사이즈는 보통 4KB에서 1GB 정도 차지한다.
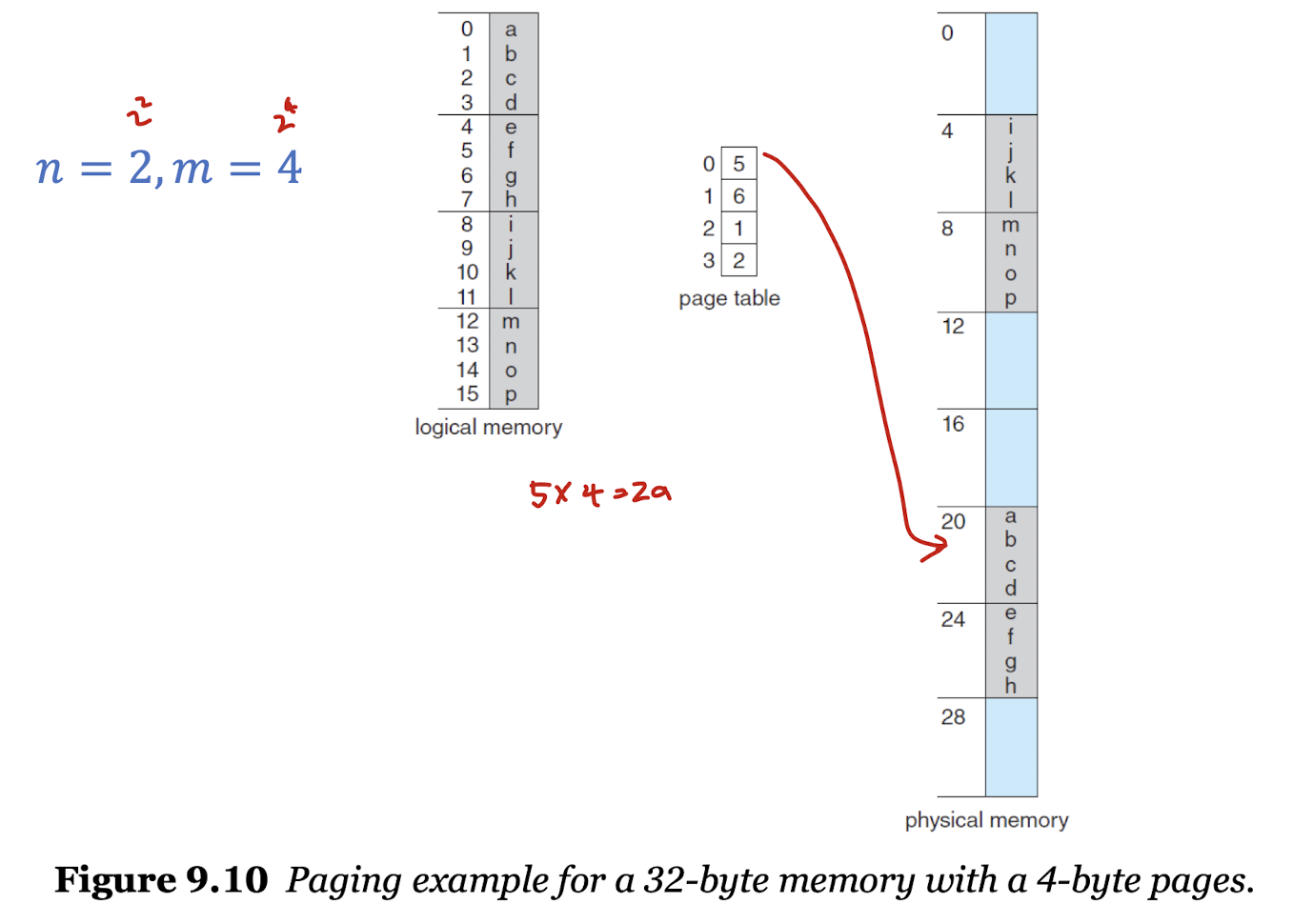
- 논리 주소 공간의 크기가 2^m 이고 페이지 크기가 2^n일 때, 페이지 넘버는 m - n, 페이지 간격은 n이 된다.
2^4 = 16, 2^2 = 4
페이지 넘버 = 4 - 2, 2^2 = 4
페이지 간격 = 2, 2^2 = 4
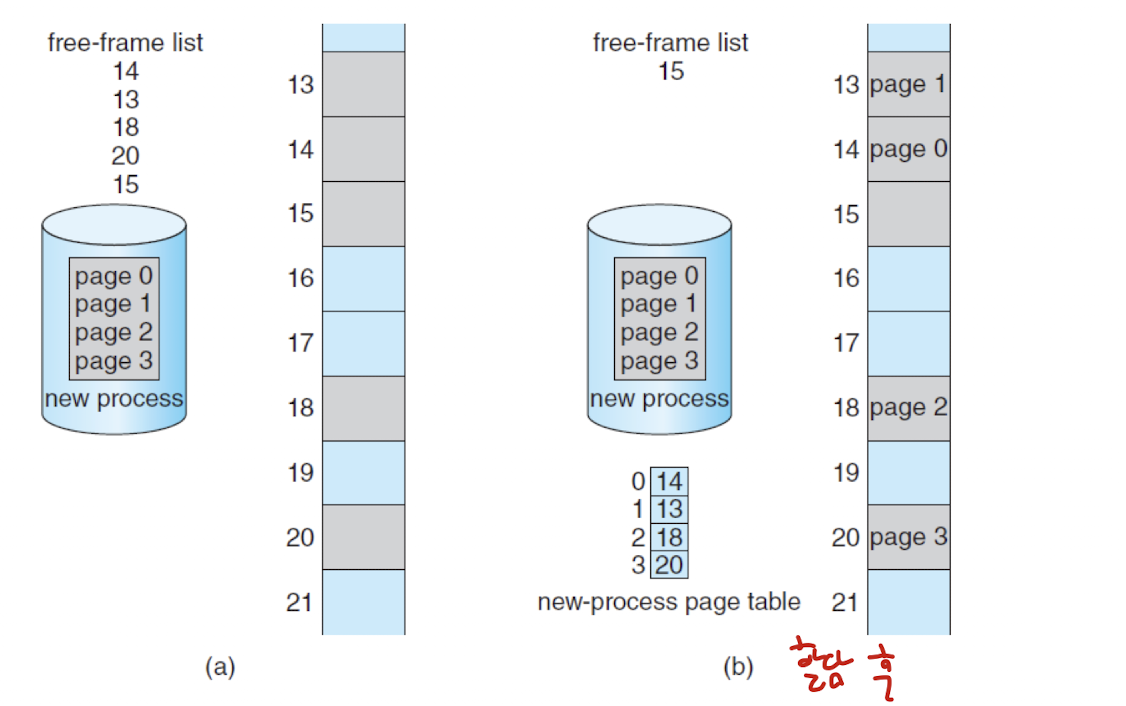
- 할당되지 않은 프레임들은 리스트로 관리되다가, 프로세스가 실행될 때 순차적으로 페이지를 메모리에 할당한다.
PTBR(page-table base register)
- 페이지 테이블의 크기가 갈수록 무거워지고 다양해지면서, 하드웨어만으로 페이지 테이블을 관리하는 것이 힘들어졌다.
- PTBR은 메인 메모리에 있는 페이지 테이블의 시작 번지를 가리킨다.
- 컨텍스트 스위칭의 속도는 빨라졌지만, 여전히 메모리 접근 시간은 느린데, 그 이유는 두 번이나 메모리 접근을 실행하기 때문이다.
: 메인 메모리에 있는 페이지 테이블에 접근
: 페이지 테이블 내에 있는 실제 데이터에 접근
TLB(Translation Look-aside Buffer)
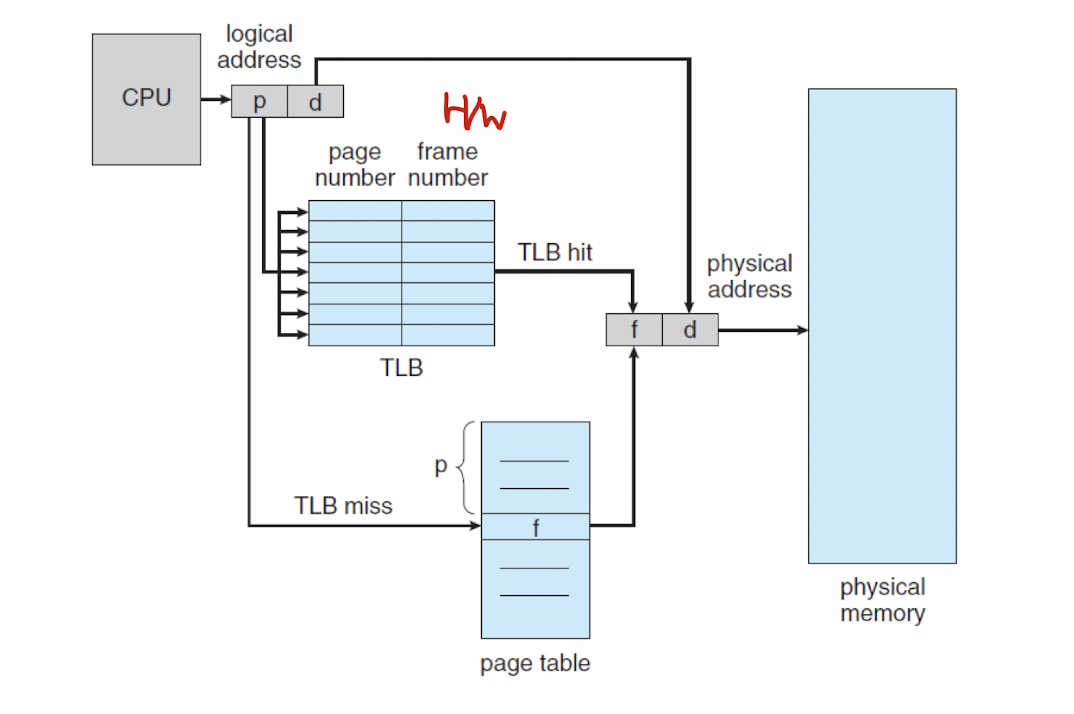
- 그래서, 메모리 접근 시간도 향상시키기 위해 캐시 메모리, 즉 TLB를 거쳐서 페이지 테이블에 접근하는 방식이 나오게 된다.
캐시 메모리 : 메인 메모리에서 빈번하게 사용하는 데이터를 캐시에 저장해 CPU에 더 빨리 접근할 수 있게 해주는 하드웨어이다. - TLB에는 빈번하게 사용되는 페이지 테이블 일부를 저장하고 있고, CPU에서 메인 메모리의 페이지 테이블에 접근하기 전에 TLB에 접근하여 페이지 정보가 있다면 곧바로 주소 변환이 이루어진다.
: TLB hit : TLB 안에 포함되어 있는 페이지 넘버
: TLB miss : TLB 안에 포함되어 있지 않은 페이지 넘버
: hit radio : TLB hit 발생률, 이에 따라 EAT(Effective Memory-Access Time)이 조정된다. - 시스템의 메모리 접근 시간이 10ns 일 때 계산 방법
: 80% hit radio 의 EAT : 0.80 X 10 + 0.20 X 20 = 12ns
: 99% hit radio 의 EAT : 0.99 X 10 + 0.01 X 20 = 10.1ns
Memory Protection with Paging
- 페이징에서의 메모리 보호는 각 프레임에 관련된 보호 비트에 의해 이루어진다.
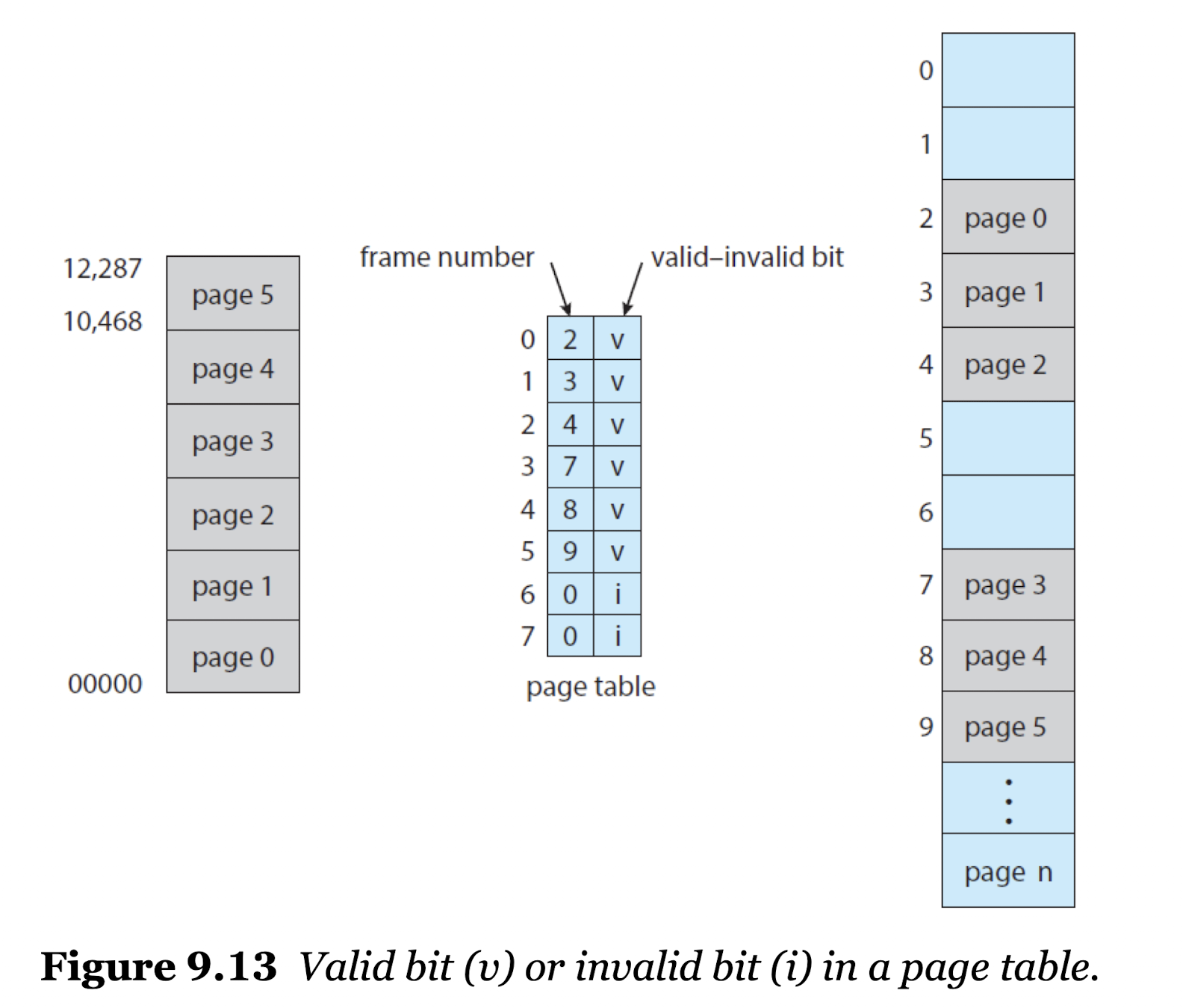
- 유효-무효 비트(valid-invalid bit)는 각 페이지 테이블에 모두 첨부되어 있다.
: 비트가 유효한 경우 - 해당 페이지가 프로세스의 논리적 주소 공간에 포함되어 있다는 의미
: 비트가 무효할 경우 - 논리적 주소 공간에 포함되어 있지 않은 페이지,
즉 프로세스가 주소 부분을 사용하지 않거나 백킹 스토어에 접근하여 권한이 없는 경우
: 불법 주소가 들어오면 유효-무효 비트를 이용해 인터럽트를 건다.
Shared Pages
- 위에서 이야기한
DLL과 비슷한 개념, 페이징의 장점 중 하나로 공통 코드를 공유할 수 있다. - 이는 멀티 프로그래밍 환경에서 큰 장점으로 작용될 수 있다.
- 예를 들어 C에서
libc라이브러리를 각 프로세스가 복사해서 로드한다면 매우 비효율적이므로 재입력 코드(Reentrant Code), 즉 실행 중에 변할 일이 없는 코드는 프로세스끼리 공유하는 것이 효율적이다.
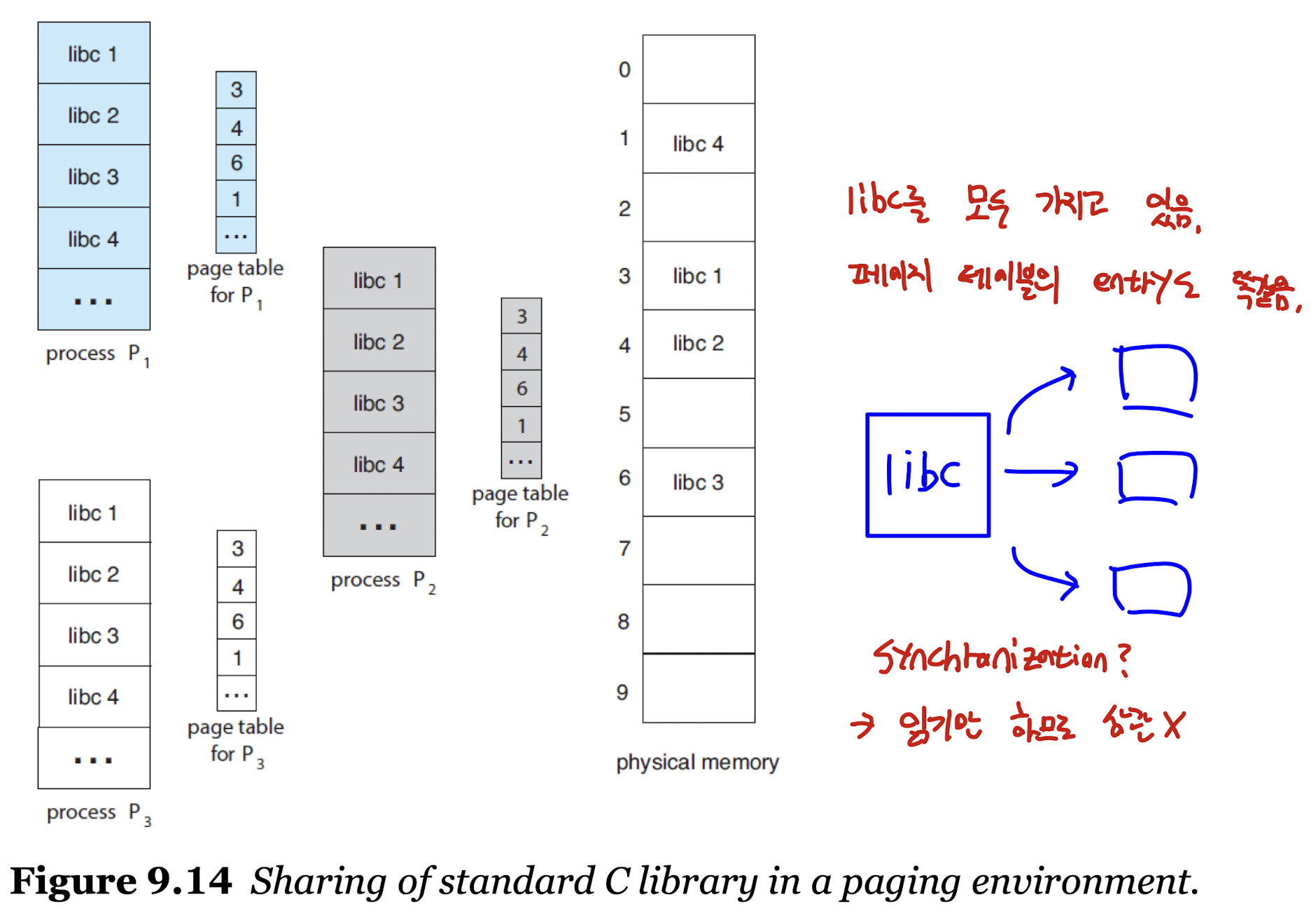
- 하나의 물리 메모리를 공유한 모습을 확인할 수 있다.
- 프로세스들은 읽기만 하고 있으므로 동기화 문제 역시 발생하지 않는다.
Structure of the Page Table
- 논리적 주소 공간이 커질수록 페이지 테이블 역시 지나치게 커지므로, 이에 맞춰 페이지 테이블을 효율적으로 구조화 할 필요가 있다.
Hierachical Paging
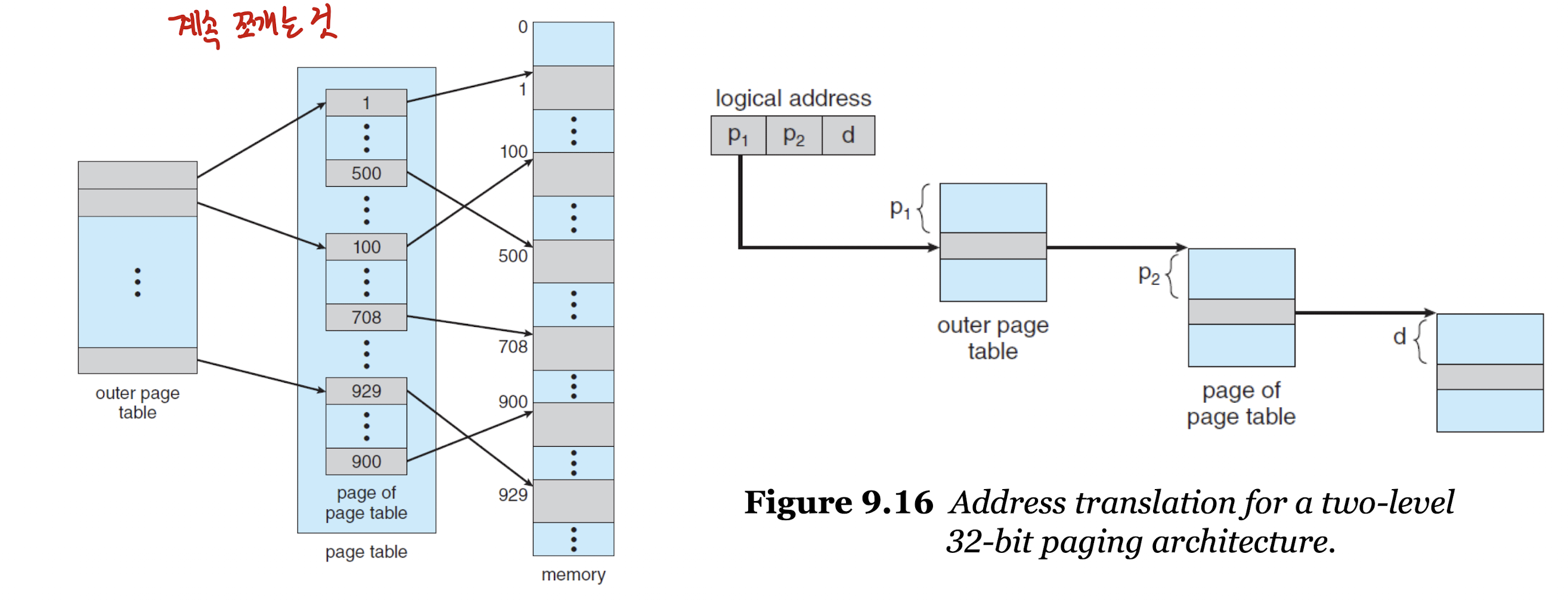
- 계층적 페이징은 페이지 테이블의 페이지 테이블을 만드는, 즉 페이지 테이블을 쪼개는 방법이다.
- 페이지 테이블 자체가 너무 커질 때 사용하는 방법으로, 외부 페이지 테이블과 내부 페이지 테이블을 사용하는 방법이다.
- 페이지 단계 수가 증가할 수록 메모리 접근 횟수도 많아져 적절하게 사용해야 한다.
Hashed Page Tables
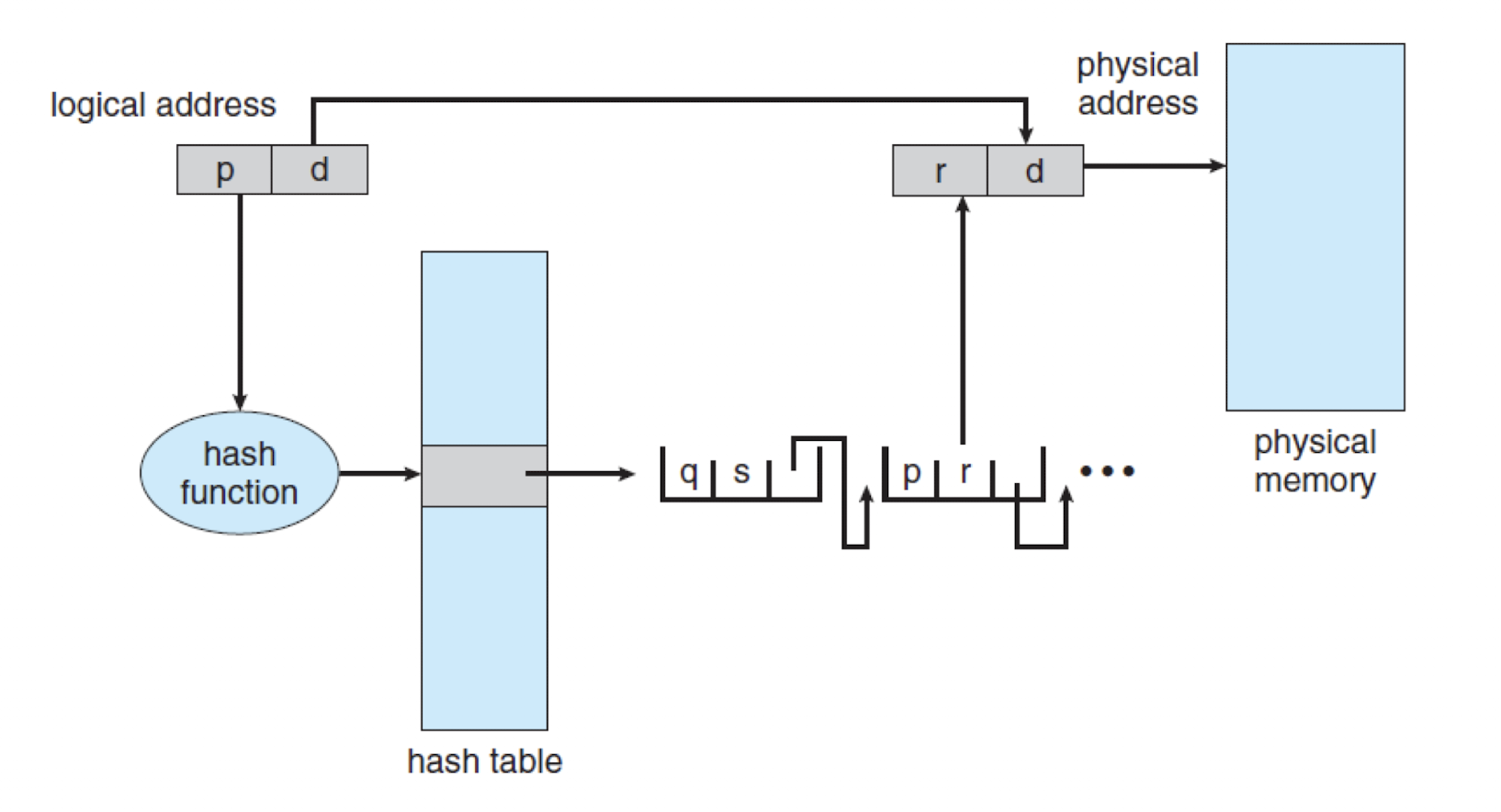
- 해시 자료구조가 낮은 시간 복잡도를 가지고 있음을 이용하는 방법이다.
- 32 bit 이상의 주소 공간을 제어할 때 주로 사용하는 구조이다.
Inverted Page Tables
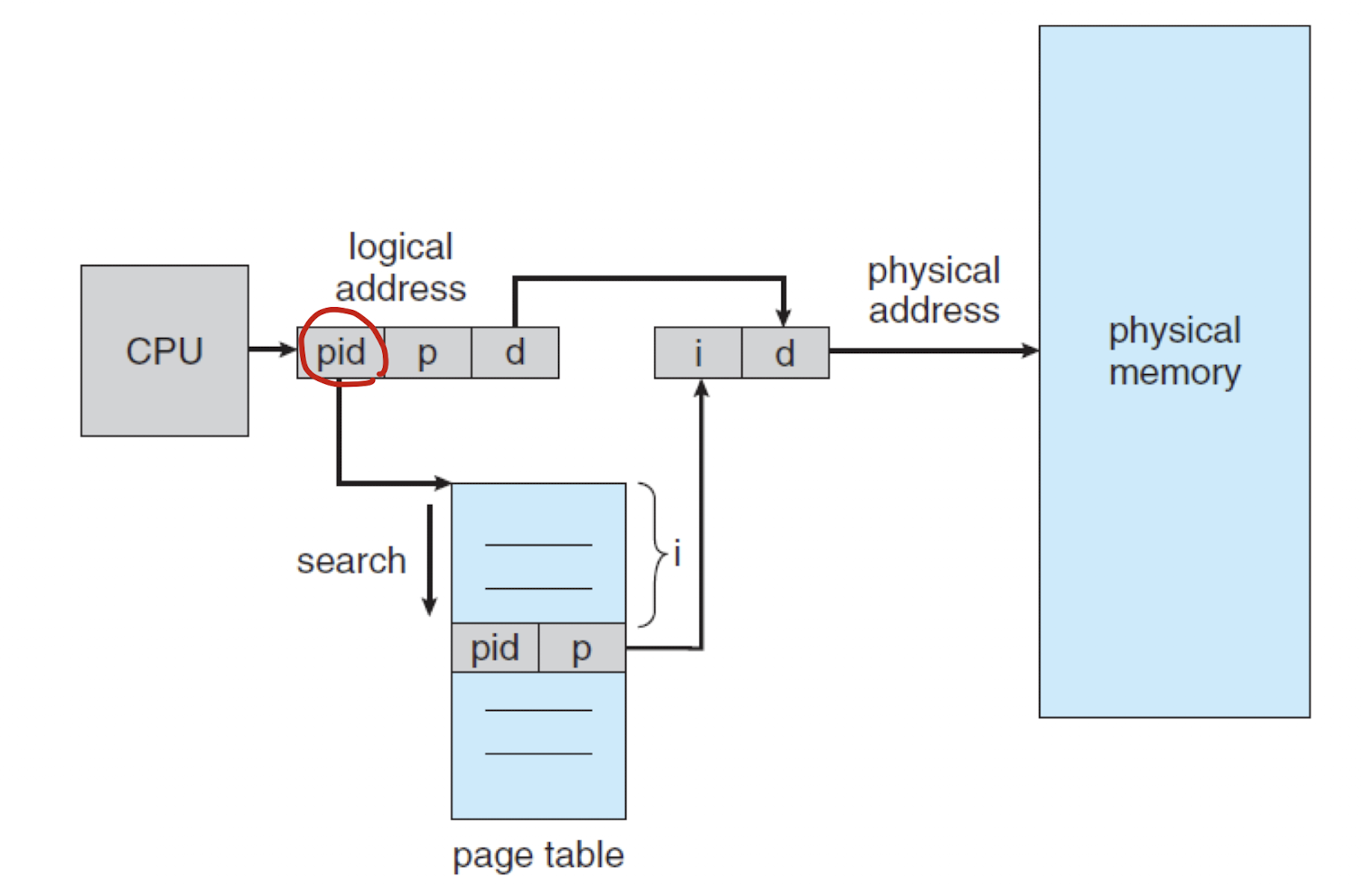
- 어떤 프로세스가 어떤 페이지를 가지고 있는지 역으로 체크하는 방법이다.
- 페이지 테이블에 프로세스의 id를 추가하여 해당 프로세스의 페이지를 추적한다.
Swapping
- 실제 물리적 주소 공간보다 더 큰 프로세스를 실행하기 위해 사용한다.
- 시스템 멀티 프로그래밍의 빈도를 조절하는, 즉 메모리상의 프로세스의 수를 조절할 수 있다.
- 프로세스의 명령어와 데이터는 메모리에 올라와 있어야 실행이 가능한데, 메모리가 부족한 경우 프로세스 혹은 프로세스의 일부를 메모리에서 백킹 스토어로 일시적으로 스왑한다.
- 필요하면 백킹 스토어에서 다시 가져와 실행한다.
Standard Swapping
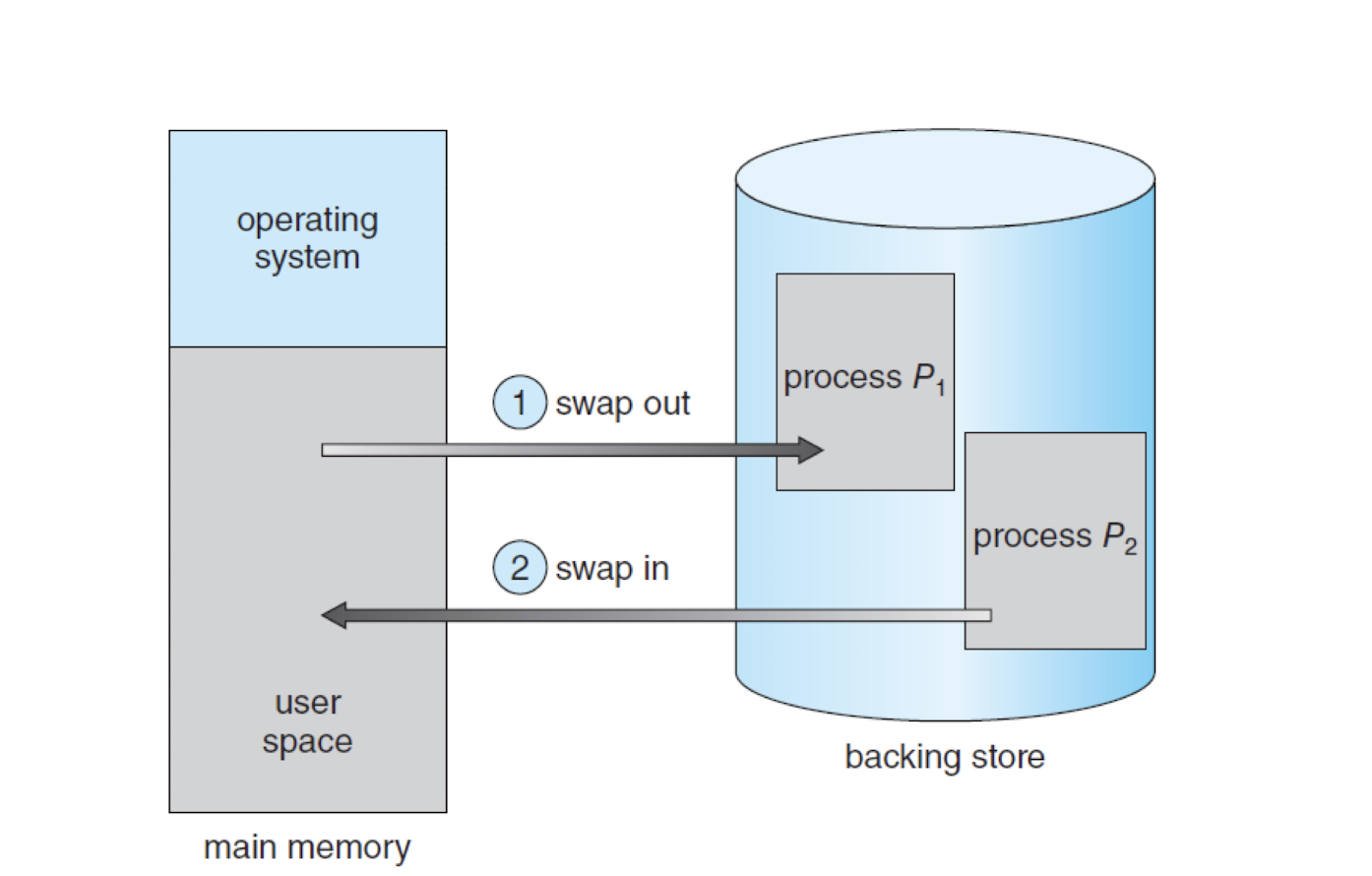
- 전체 프로세스가 백킹 스토어와 메인 메모리 사이를 스왑하는 것을 말한다.
- 전체 프로세스 스왑은 코스트가 커 시스템에 부담을 줄 수 있다.
Swapping with Paging
- 전체 프로세스를 스왑하는 대신 프로세스의 페이지를 스왑하는 방법이다.
- 물리적 메모리와 논리적 메모리를 분리할 수 있다.
- 아주 작은 단위의 페이지도 스왑할 수 있다.
- 오늘날에는 페이징이라는 말은 스와핑 가능한 페이징을 일컫는다.
: page out : 메모리에서 백킹 스토어로 페이지가 이동
: page in : 백킹 스토어에서 메모리로 페이지가 이동 - 이 방법은 가상 메모리에서 큰 위력을 발휘한다.

즐겁게 하자 🤭