CAPTUM
⊙ facebook이 개발한 오픈소스 라이브러리
⊙ Pytorch 기반
⊙ NLP모델이나 컴퓨터 비전 모델의 예측 결과를 이해하도록 도움
⊙ 입력이미지의 어떤 부분을 바라보고 예측을 내놓는 지 활성화 되는 부분을 시각화 해줌
Captum 사용 예시
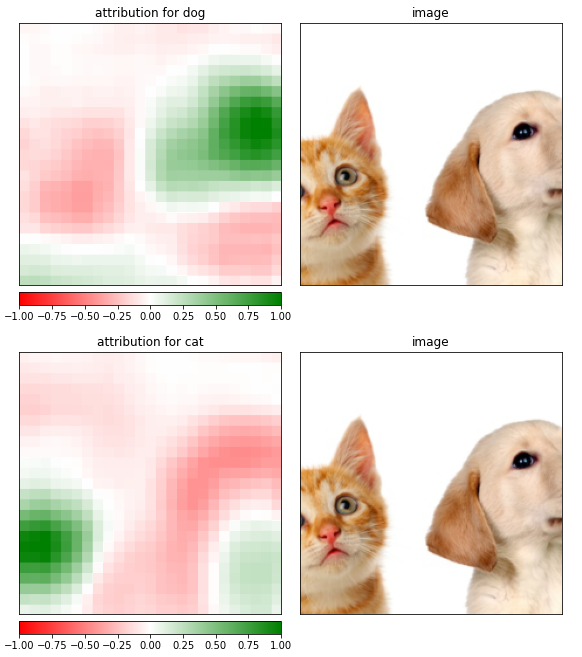
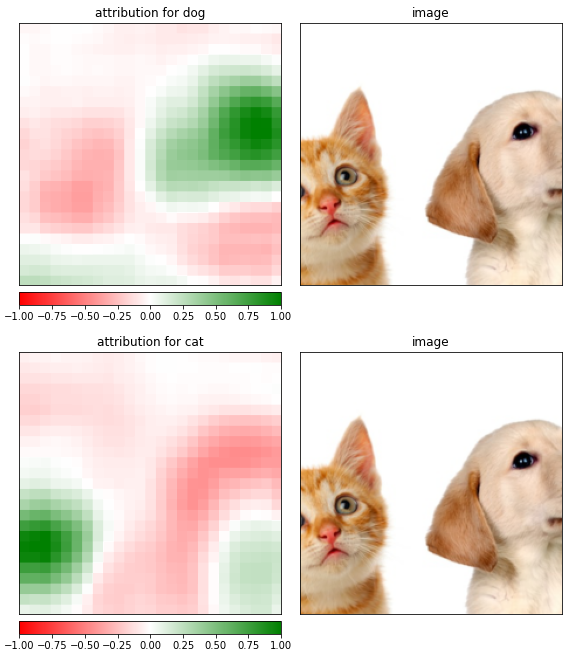
강아지 예측 시 입력 이미지의 오른쪽 부분이 활성화가 되고 고양이 예측 시 입력 이미지의 왼쪽 부분이 활성화 되는 것을 확인 할 수 있다.
샘플 이미지의 어떤 부분이 특정한 예측에 도움을 주는지 보여주는 셈이다.
사용된 transforms 옵션 정리
transforms.ToTensor() - 이미지 데이터를 tensor로 바꿔준다.
transforms.Normalize(mean, std, inplace=False) - 이미지를 정규화한다.
transforms.Resize(size) - 이미지 사이즈를 size로 변경한다.
transforms.CenterCrop(size) - 가운데 부분을 size 크기로 자른다.
import torchvision
from torchvision import transforms
from PIL import Image
import requests
from io import BytesIO
model = torchvision.models.resnet18(pretrained=True).eval()
response = requests.get("https://image.freepik.com/free-photo/two-beautiful-puppies-cat-dog_58409-6024.jpg")
img = Image.open(BytesIO(response.content))
center_crop = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
])
normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
input_img = normalize(center_crop(img)).unsqueeze(0)속성 계산
Captum의 Occlusion알고리즘을 사용하여 각 예측을 입력의 해당 부분에 표시.
속성 종류: Occlusion, Integrated Gradients, Deconvolution, GuidedBackprop, Guided GradCam, DeepLift, GradientShap
from captum.attr import Occlusion
occlusion = Occlusion(model)
strides = (3, 9, 9)
target=208,
sliding_window_shapes=(3,45, 45)
baselines = 0
attribution_dog = occlusion.attribute(input_img,
strides = strides,
target=target,
sliding_window_shapes=sliding_window_shapes,
baselines=baselines)
target=283,
attribution_cat = occlusion.attribute(input_img,
strides = strides,
target=target,
sliding_window_shapes=sliding_window_shapes,
baselines=0)결과 시각화
import numpy as np
from captum.attr import visualization as viz
attribution_dog = np.transpose(attribution_dog.squeeze().cpu().detach().numpy(), (1,2,0))
vis_types = ["heat_map", "original_image"]
vis_signs = ["all", "all"]
_ = viz.visualize_image_attr_multiple(attribution_dog,
np.array(center_crop(img)),
vis_types,
vis_signs,
["attribution for dog", "image"],
show_colorbar = True
)
attribution_cat = np.transpose(attribution_cat.squeeze().cpu().detach().numpy(), (1,2,0))
_ = viz.visualize_image_attr_multiple(attribution_cat,
np.array(center_crop(img)),
["heat_map", "original_image"],
["all", "all"],
["attribution for cat", "image"],
show_colorbar = True
)
자료 출처: https://pytorch.org/tutorials/recipes/recipes/Captum_Recipe.html
