
현재 우테코 프로젝트로 운영 중인 바톤 서비스에서 무중단 배포를 하게되었습니다.
지금까지는 서버를 종료시킨 후에 새로 업데이트된 서버를 순차적으로 가동하는 방식으로 운영했습니다.

그림과 같이 V1이 종료된 후부터 V2가 정상 작동 되기까지 서버를 다운시켰습니다.
이 다운되어있는 시간은 다운 타임 이라고 합니다. 저희 서비스는 다운 타임이 약 3분이었는데요. 이 3분동안 유저가 서비스를 이용하지 못하면 불편하겠죠...?
그래서 중단 배포에서 무중단 배포로 방식을 교체하여 제로 다운 타임을 만들어 유저의 불편을 줄였습니다.
무중단 배포?
중단 배포와 다르게 서버가 다운되어있는 시간 없이 새로운 버전으로 교체하는 배포 방법을 뜻합니다.
무중단 배포 전략으로 크게 3가지가 있는데요. 한 번 알아보겠습니다.
Rolling update 배포
로드밸런서로 연결되어있는 서버들을 순차적으로 하나씩 새로운 버전으로 변환시키는 방식입니다. 배포되어있는 서버를 하나씩 교체하는 방식이라고 생각하시면 편합니다!
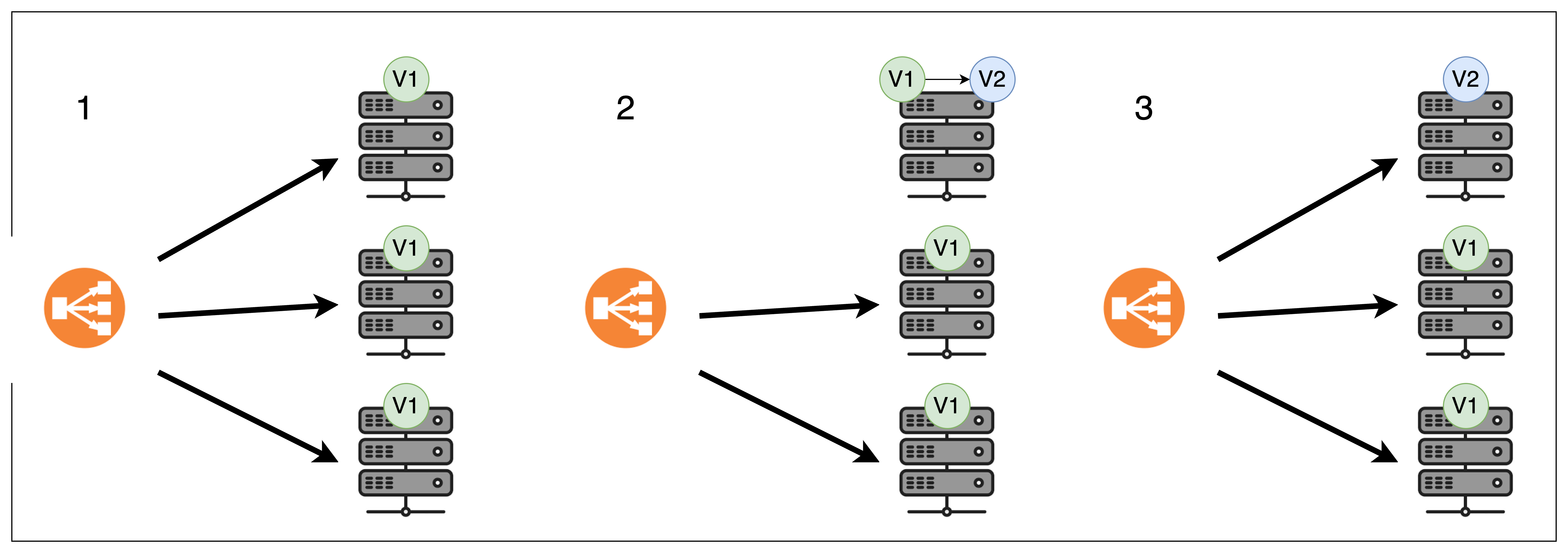
연결되어있는 서버를 하나씩 멈추고 새로운 버전을 교체하고 있습니다. 부가적인 서버 자원을 사용하지 않고도 배포할 수 있다는 장점이 있지만 배포되는 동안에는 평소보다 트래픽 부하가 더 걸린다는 단점이 있습니다.
윗 그림의 롤링 방식은 추가적인 서버 자원을 사용하지 않고 배포 동안에 트래픽 부하를 더 주는 방식이지만 반대의 방식도 존재합니다. 추가 서버를 하나 더 띄우고, 업데이트를 위해 정지해놓은 서버 때문에 추가적인 트래픽 부하가 걸리지 않도록 하는 방법입니다.
추가적인 서버 비용이 걱정되는 경우에는 전자를, 트래픽 부하가 걱정되는 경우에는 후자를 선택하면 좋을 것 같습니다.
또, 롤링 배포 방식에서는 기존 버전(V1)과 새로운 버전(V2)의 인스턴스가 동시에 실행될 수 있기 때문에 두 버전 간의 호환성이 매우 중요합니다.
예를 들어 "GET /articles" API가 V1에서 사용되고 있는데, V2에서 해당 API가 제거되었다면, 이는 큰 문제가 될 수 있습니다. 왜냐하면 V2로의 업데이트 과정 중에는 V1과 V2 서버가 동시에 존재하게 되고, 이 때 유저가 "GET /articles" API를 호출하면 일부는 오류 응답을 받게 될 것입니다.
이러한 호환성 문제는 API 엔드포인트뿐만 아니라 데이터베이스 스키마 등 여러 계층에서 발생할 수 있습니다! 따라서, 롤링 배포 전략을 수행할 때는 호환성 문제를 미리 고려하여 배포 전에 꼼꼼히 테스트를 수행해야 합니다.
Blue-Green 배포
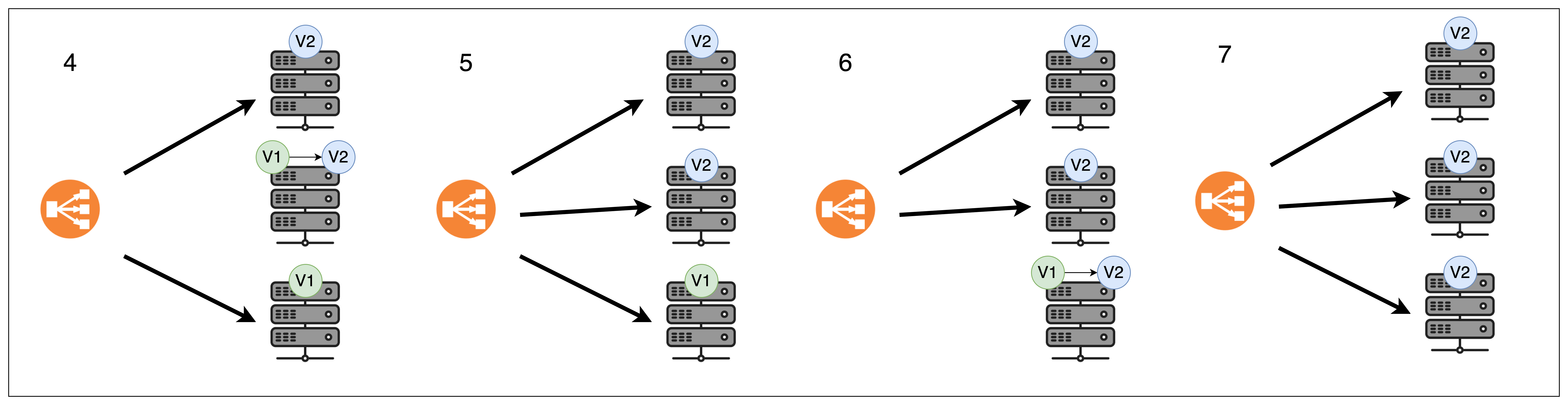
Blue-Green 배포는 두 개의 독립적인 환경 Blue 환경과 Green 환경을 가지고 진행되는 배포 전략입니다. 여기서 Blue는 현재 운영중인 환경을 나타내며, Green은 새로운 버전의 환경을 의미합니다. Green의 배포 준비가 완료되면 Blue 환경에서 Green 환경으로 한 번에 전환합니다.
V2가 배포된 순간부터 로드 밸런서는 V2로 모든 트래픽을 이동시키고, V1은 마지막 트래픽의 작업이 끝나면 종료됩니다. 정말 찰나의 순간 V1과 V2 서버가 동시에 켜져있다고 생각하시면 됩니다!
롤링 배포와 다르게 한 번에 버전을 바꾸기 때문에 버전 호환에 대한 문제가 발생하지 않습니다. 또, 만약 새로운 버전에 문제가 발생하면 트래픽을 다시 Blue 환경으로 전환하여 이전 버전으로 빠르게 롤백할 수 있습니다.
단점 또한 존재하는데요. 짧은 시간이지만 두 버전이 동시에 실행되고 있는 시간도 있기 때문에 추가적인 서버 비용이 발생합니다.
Canary 배포
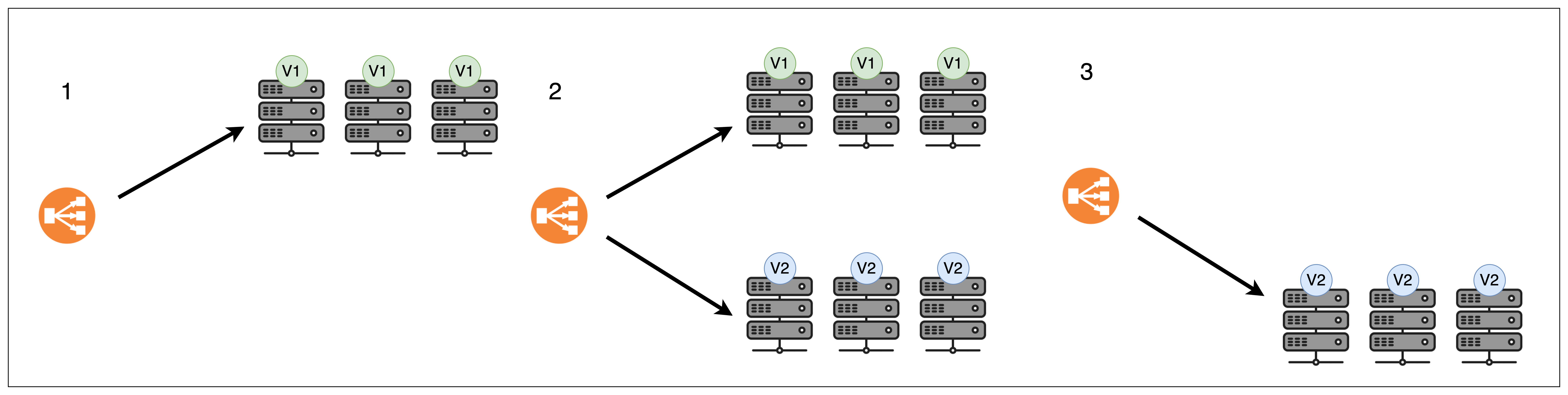
카나리 배포 전략은 서비스의 새로운 버전을 모든 사용자에게 바로 제공하는 것이 아니라, 먼저 일부 사용자에게 제공하여 새로운 버전의 안정성과 성능을 검증하는 배포 전략입니다. 광산에서 독가스를 감지하기 위해 캐나리 새를 사용한 것에서 유래되었다고 합니다!
절차
- 평가 단계: 먼저 새로운 버전(
V2)를 제한된 사용자 그룹에 배포합니다. 이 사용자 그룹을 "카나리" 그룹이라고 합니다. - 모니터링 단계: 카나리 그룹의 피드백과 시스템의 메트릭을 모니터링하여
V2의 문제점을 파악합니다. - 확장 배포 단계: 앞선 단계에서 문제가 없었다면
V2사용자 그룹을 점진적으로 확대합니다. - 전체 배포 단계:
V2를 100% 배포합니다.
카나리 배포의 경우 새로운 버전으로 업데이트하면서 발생하는 문제점들을 초기에 확인할 수 있기 때문에 빠른 롤백이 가능합니다. 또, 초기 단계에서 사용자 피드백을 받아 빠르게 수정 및 개선할 수 있습니다.
하지만, 롤링과 블루-그린 배포 전략에 비해 비용이 많이 발생한다는 단점이 있습니다.
배포 전략 선택
저희 팀은 Blue-Green 전략을 선택했습니다.
우선 rolling 방식을 사용했을 때는 빠르게 롤백할 수 있는 역량이 부족하다고 판단했습니다. 롤백하는 시간 때문에 몇몇 사용자들은 장시간 에러 페이지를 만날 수 있다는 생각에 Blue-Green 방식을 선택했습니다.
카나리 방식은 사용자가 많아야 의미 있는 전략이라고 생각합니다. 저희는 사용자가 100명대인 작은 서비스이기 때문에 카나리 전략은 생각하지 않았습니다.
추가적인 서버 리소스가 드는 단점이 있지만, 구동 중인 어플리케이션의 수가 2개 밖에 안되기 때문에 비용 체감이 작을 것이라고 생각하여 큰 단점이라고 생각하진 않았습니다.
사실, 서버가 단일 어플리케이션 환경으로 구성되어있기 때문에 rolling, Blue-Green, Canary 모두 같은 의미가 됩니다. 하지만 Blue-Green에 어울린다고 생각해 Blue-Green 전략을 선택했다고 언급한 것입니다.
구현 과정
하나의 nginx에 spring application이 하나 연결된 상태라고 가정하겠습니다.
초기 환경
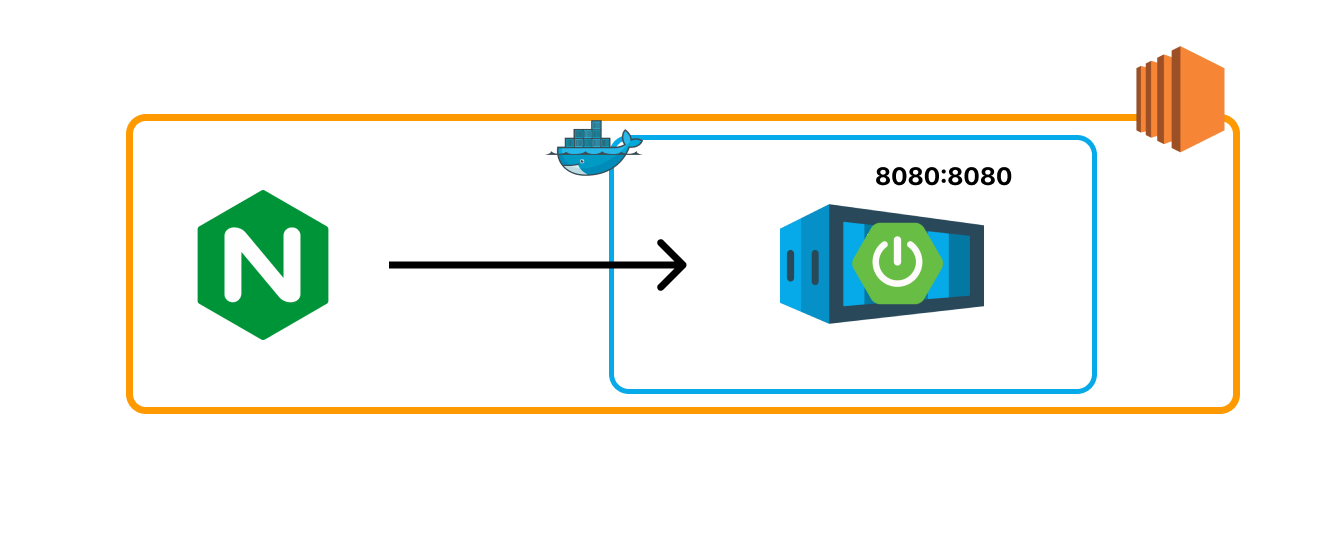
Nginx의 리버스 프록시로 연결된 스프링 서버 컨테이너가 있습니다.
그리고 github actios를 이용하여 CI/CD를 진행합니다. ssh 연결이 사설 ip에서만 가능하기 때문에 배포는 self-hosted runner를 사용했습니다.
docker-compose 생성
컨테이너를 빌드하기 위해 docker-compose를 이용했습니다.
version: '3.9'
services:
dev1:
container_name: spring-baton1
image: '{계정 명}/{이미지명}:{태그 이름}'
ports:
- '8080:8080'
environment:
- TZ=Asia/Seoul
networks:
- baton
dev2:
container_name: spring-baton2
image: '{계정 명}/{이미지명}:{태그 이름}'
ports:
- '8081:8080'
environment:
- TZ=Asia/Seoul
networks:
- baton
networks:
baton:
external: truedev1이 구동중인 경우에는 dev2가 새로운 버전으로 배포되고, dev2가 구동중인 경우에는 dev1이 새로운 버전으로 배포되는 방식을 선택했습니다.
dev1과 dev2의 다른점은 8080 포트냐, 8081 포트냐 입니다.
스프링 컨테이너와 데이터베이스 컨테이너가 baton 네트워크로 묶여 있어 추가적인 네트워크 설정도 해주었습니다. 만약 네트워크 설정을 따로 하시지 않았다면 networks 부분은 제거하셔도 됩니다.
nginx 파일 수정
/etc/nginx/nginx.dev1.conf 파일과 /etc/nginx/nginx.dev2.conf 를 만들어 컨테이너를 가리키는 포트만 다르게 두었습니다. 새로운 nginx.dev1.conf와 nginx.dev2.conf 파일은 nginx.conf에서 복제하였습니다.
보안을 위해 바뀐 부분만 보여드리겠습니다.
...
location /api {
...
proxy_pass http://127.0.0.1:8080;
...
}
...nginx.dev1.conf에서는 proxy_pass를 8080 포트로 두었고, nginx.dev2.conf에서는 8081로 두었습니다!
만약 sites-enabled 나 sites-available 경로의 파일에 서버 포트를 설정하셨다면 해당 파일을 2개로 나누면 됩니다.
배포 스크립트 작성
#!/bin/bash
IS_DEV1=$(docker ps | grep spring-baton1)
DEFAULT_CONF=" /etc/nginx/nginx.conf"
MAX_RETRIES=20
check_service() {
local RETRIES=0
local URL=$1
while [ $RETRIES -lt $MAX_RETRIES ]; do
echo "Checking service at $URL... (attempt: $((RETRIES+1)))"
sleep 3
REQUEST=$(curl $URL)
if [ -n "$REQUEST" ]; then
echo "health check success"
return 0
fi
RETRIES=$((RETRIES+1))
done;
echo "Failed to check service after $MAX_RETRIES attempts."
return 1
}
if [ -z "$IS_DEV1" ];then
echo "### DEV2 => DEV1 ###"
echo "1. DEV1 이미지 받기"
docker-compose pull dev1
echo "2. DEV1 컨테이너 실행"
docker-compose up -d dev1
echo "3. health check"
if ! check_service "http://127.0.0.1:8080"; then
echo "DEV1 health check 가 실패했습니다."
exit 1
fi
echo "4. nginx 재실행"
sudo cp /etc/nginx/nginx.dev1.conf /etc/nginx/nginx.conf
sudo nginx -s reload
echo "5. DEV2 컨테이너 내리기"
docker-compose stop dev2
docker-compose rm -f dev2
else
echo "### DEV1 => DEV2 ###"
echo "1. DEV2 이미지 받기"
docker-compose pull dev2
echo "2. DEV2 컨테이너 실행"
docker-compose up -d dev2
echo "3. health check"
if ! check_service "http://127.0.0.1:8081"; then
echo "DEV1 health check 가 실패했습니다."
exit 1
fi
echo "4. nginx 재실행"
sudo cp /etc/nginx/nginx.dev2.conf /etc/nginx/nginx.conf
sudo nginx -s reload
echo "5. DEV1 컨테이너 내리기"
docker-compose stop dev1
docker-compose rm -f dev2
fi코드 순서대로 알아보겠습니다.
- 현재 실행중인 컨테이너가
spring-baton1인지 확인합니다. if [ -z "$IS_DEV1" ]에서 만약 $IS_DEV1 이 비어있다면 참을 반환하는데, 그 경우는 dev2가 실행중인 경우이기 때문에 dev1을 새로 배포시키는 로직을 수행시킵니다. (if와 else 부분의 로직은 같기 때문에 if 부분의 로직만 작성하겠습니다.)- 이미지를 pull 받습니다.
- 컨테이너를 실행시킵니다.
- dev1 서비스가 정상적으로 실행되는지 확인합니다.
5-1.check_service()함수에서 3초에 한 번씩 서비스 상태를 확인합니다.
5-2. 만약 서비스가 구동중이지 않다면 계속해서 서비스 상태를 확인하는데, 20번이 넘어가면 실패를 반환합니다.
5-3. 서비스가 20번 안에 구동된다면 성공을 반환합니다.
5-4. 함수가 실패한다면 곧바로 스크립트를 오류 상태로 종료시킵니다. - 이전에 작성한 nginx.dev1.conf 파일은 nginx.conf 파일로 복사해서 nginx가 바라보는 포트를 바꿉니다. 그 후에 reload합니다.
- 운영중이던 구 버전의 dev2를 종료시킵니다.
의문 1
다른 블로그들을 참고하여 쉘 스크립트를 작성했는데요. 코드에 의문점이 있었습니다. 기존 프로세스에 아직 많은 트래픽이 남았는데, nginx가 새로운 프로세스를 시작하게 되면 기존 프로세스의 남아있는 트래픽은 처리되지 않지 않을까? 하는 걱정이 있었습니다.
우려했던 점에 대해 검색하고 나서 nginx reload에 대해 몰랐던 점을 하나 배웠는데요. nginx -s reload는 nginx를 재배포하는 것이 아닌 설정을 다시 읽어들이는 방법이라고 합니다. reload 시에 다음과 같은 과정으로 실행됩니다!
- nginx는 새로운 worker 프로세스를 시작하여 새로운 설정으로 실행합니다.
- 모든 새로운 트래픽은 이 새로운 worker 프로세스에 의해 처리됩니다.
- 기존의 worker 프로세스는 현재 활성화된 트래픽들을 계속 처리하다가, 그 트래픽들이 종료되면 자동으로 종료됩니다.
nginx가 이런 부분도 신경써주고 있어서 놀랐습니다.
의문 2
비슷한 다른 의문도 있었는데요. 이번에는 어플리케이션 쪽에서 아직 연산이 끝나지 않은 경우에 컨테이너가 내려가면 어떡하지 걱정되었습니다. 현재 상황에서는 종료 명령이 2가지가 있습니다. docker stop과 스프링 어플리케이션의 종료입니다.
스프링 어플리케이션의 종료부터 알아보겠습니다. 스프링부트 2.3 버전부터 Graceful Shutdown을 지원한다고 합니다. 따라서 application 파일에 server.shutdown=graceful를 두면 Hard Shutdown으로 종료되지 않고 모든 요청을 완료한 후에 어플리케이션이 종료됩니다.
그래서 어플리케이션 파일에 graceful shutdown을 설정해주었습니다!
이제 docker stop 에 대해 알아보겠습니다. docker stop 명령이 들어오면 docker는 컨테이너의 주 프로세스에 SIGTERM 신호를 전송합니다. 만약 10초 안에 프로세스가 종료되지 않는다면 SIGKILL 신호를 전송합니다.
여기서 SIGTERM 은 프로세스에게 종료 명령을 내리는 것이고, SIGKILL은 강제 종료의 명령입니다.
자 그러면 도커와 어플리케이션이 종료되는 순서는 아래와 같겠네요.
- 도커가 스프링부트 어플리케이션에 종료 명령
- 명령을 받은 스프링부트는 shutdown을 실행 (graceful shutdown으로 설정해놓았기 때문에 graceful shutdown)
- 만약 10초가 지나도 스프링부트가 종료되지 않으면 어플리케이션 강제 종료
무서운건 가장 마지막 부분인데요. 상황에 따라서 10초안에 모든 요청의 로직이 끝나지 않을 수도 있습니다. 그런 경우에는 docker-compose 파일에 stop_grace_period: 60s와 같이 SIGKILL 까지의 시간을 명시하여 종료까지 시간을 더 넉넉하게 줄 수도 있습니다.
결과
지금까지 잘 동작하는지 실험해보겠습니다.
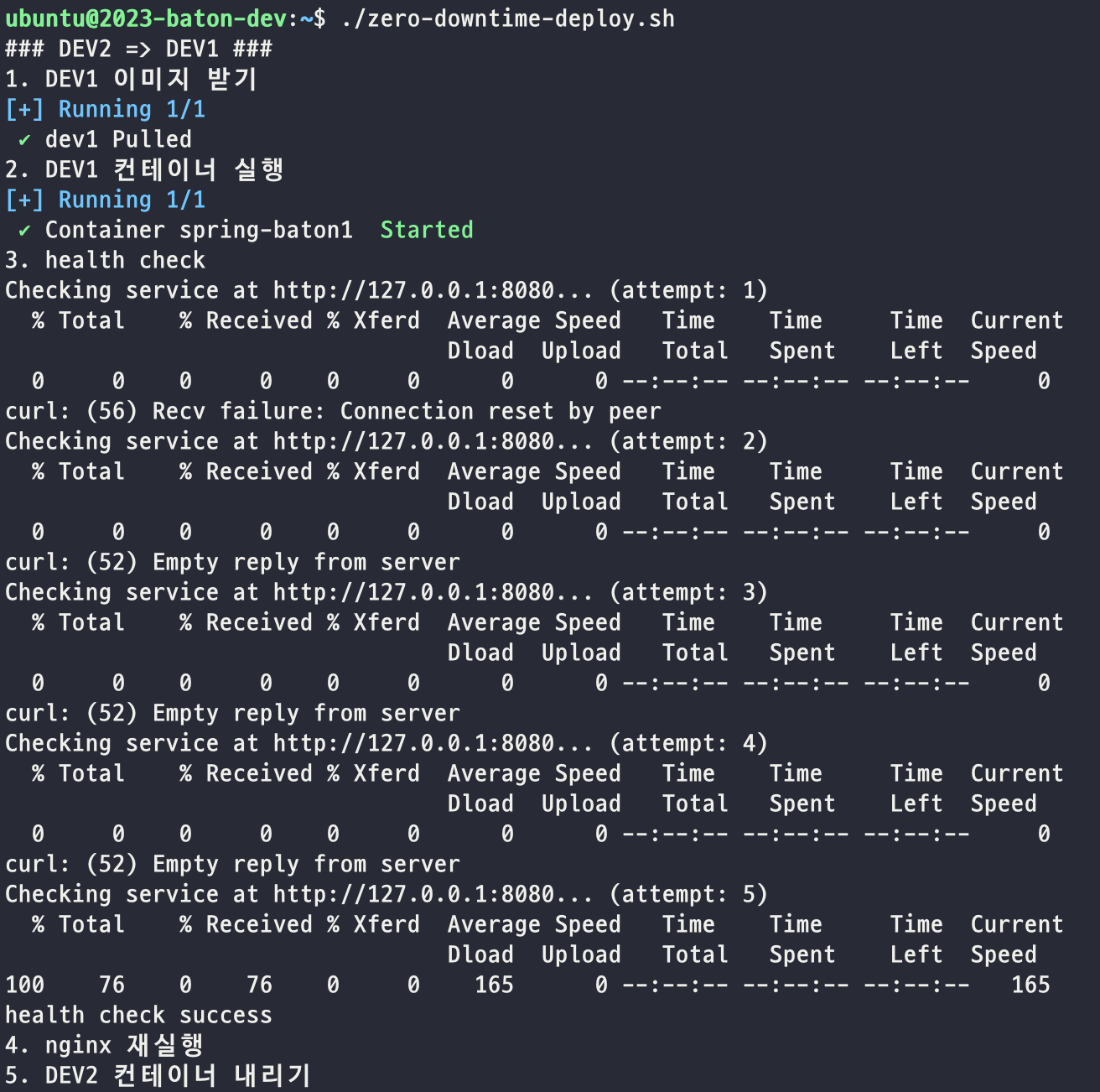
스크립트는 잘 실행되었습니다.

도커 컨테이너도 잘 올라가있군요.
이번엔 반대 방향으로의 배포도 확인해보겠습니다.
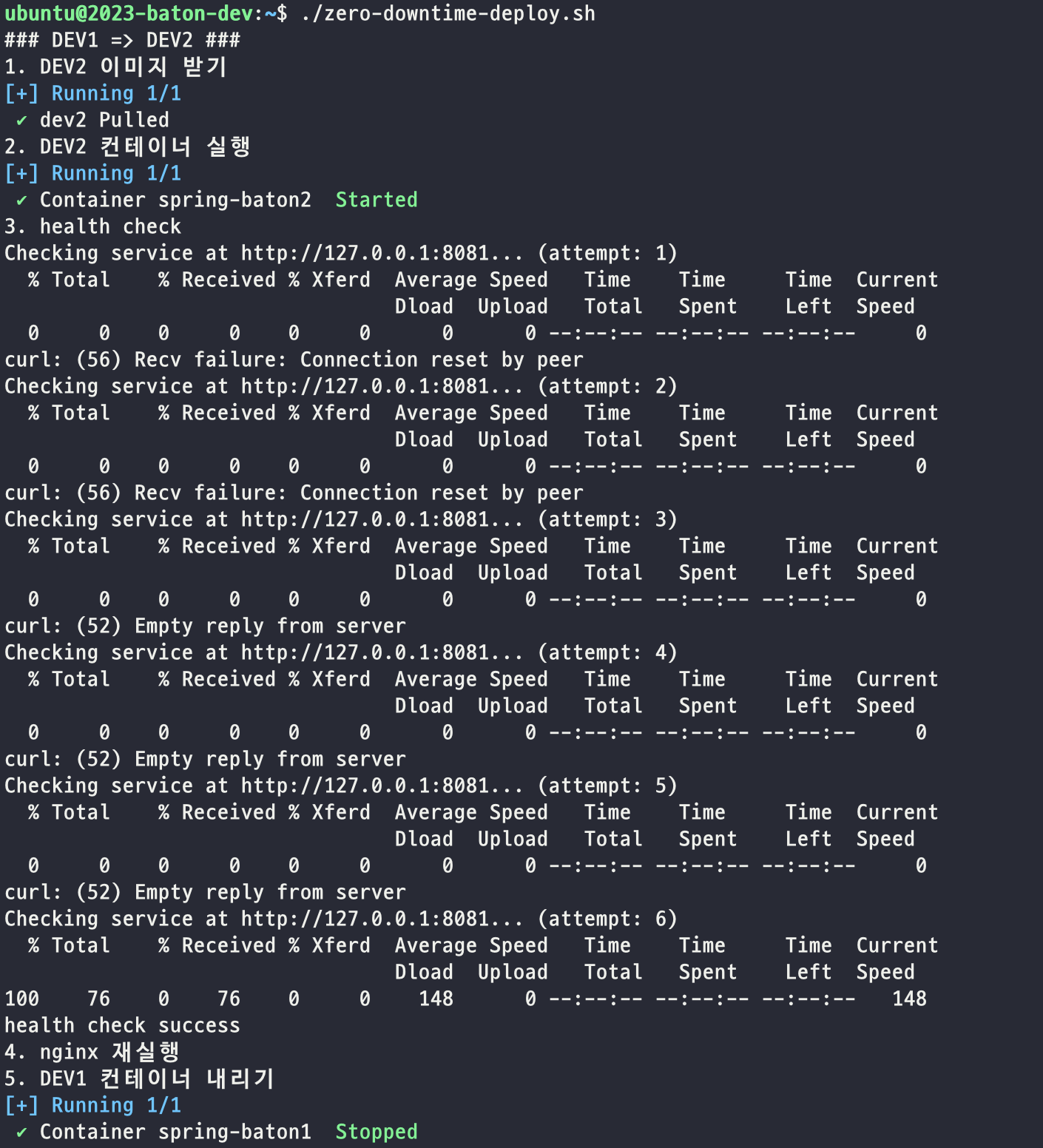

잘 동작하는 것을 확인했습니다.
github actions
배포 스크립트가 잘 동작하는 것을 확인했으니 이번에는 CD 파일을 작성해보겠습니다.
이전 글에서 CI/CD 배포 방법을 살펴보아서 깊게 다루지 않겠습니다. 해당 게시글의 cd 부분만 조금 수정했습니다.
수정된 부분은 아래와 같습니다.
deploy:
runs-on: [ self-hosted, Linux, ARM64, dev ]
needs: build
steps:
- name: Pull Latest Docker Image
run: |
sudo docker login --username ${{ secrets.DOCKERHUB_DEV_USERNAME }} --password ${{ secrets.DOCKERHUB_DEV_TOKEN }}
sudo docker pull 2023baton/2023baton:latest
- name: Docker Compose
run: |
/home/ubuntu/zero-downtime-deploy.sh
sudo docker image prune -afself-hosted runner로 서버 내에서 코드를 실행시킵니다. 도커에 로그인 한 후에 이미지를 pull 받습니다. 그 후에 위에서 작성한 무중단 배포 파일을 실행하고 필요없는 이미지를 삭제합니다.
마무리
완벽한 무중단 배포 과정은 아닙니다. 배포된 것을 확인하는 부분에서 단순히 root endpoint인 127.0.0.1을 확인했는데, 이건 "스프링이 켜지긴 했다." 라는 뜻입니다. 데이터베이스 연결 상태, 외부 서비스와의 통신 상태 등 필요한 부분을 health check하는 과정이 필요합니다. 그래야 정말 안정적이라고 할 수 있으니까요.
actuator 의존성을 추가해 health check 하는 것을 생각해보았지만, actuator를 설정하는 순간 해커에게 노출되는 부분이 많습니다. 최근 저희 서비스에 "/actuator/health" 요청을 보낸 해커가 있더라고요... 보안에 대한 학습이 부족한 탓에 조금은 아쉽지만 curl http://127.0.0.1:8080으로 배포 상태를 확인해보기로 했습니다.
참고
